KaHIP
v3.17
Der Grafik -Partitionierungsrahmen Kahip - Karlsruhe hochwertige Partitionierung.
Das Graph -Partitionierungsproblem bittet um eine Teilung des Knotens eines Diagramms, die in k gleich große Blöcke eingestellt sind, so dass die Anzahl der zwischen den Blöcken verlaufenden Kanten minimiert wird. Kahip ist eine Familie von Graph -Partitionierungsprogrammen. Es umfasst Kaffpa (Karlsruhe Fast Flow Partitioner), ein mehrstufiger Graph -Partitionierungsalgorithmus, in seinen Varianten stark, öko und schnell, kaffpae (kaffpaevolutionary). Darüber hinaus sind spezielle Techniken in Partition Road Networks (Buffoon) einbezogen, um ein Scheitelpunktabscheider von einer bestimmten Partition sowie Techniken auszugeben, die auf die effiziente Partitionierung sozialer Netzwerke ausgerichtet sind. Hier ist ein Überblick über unseren Rahmen:
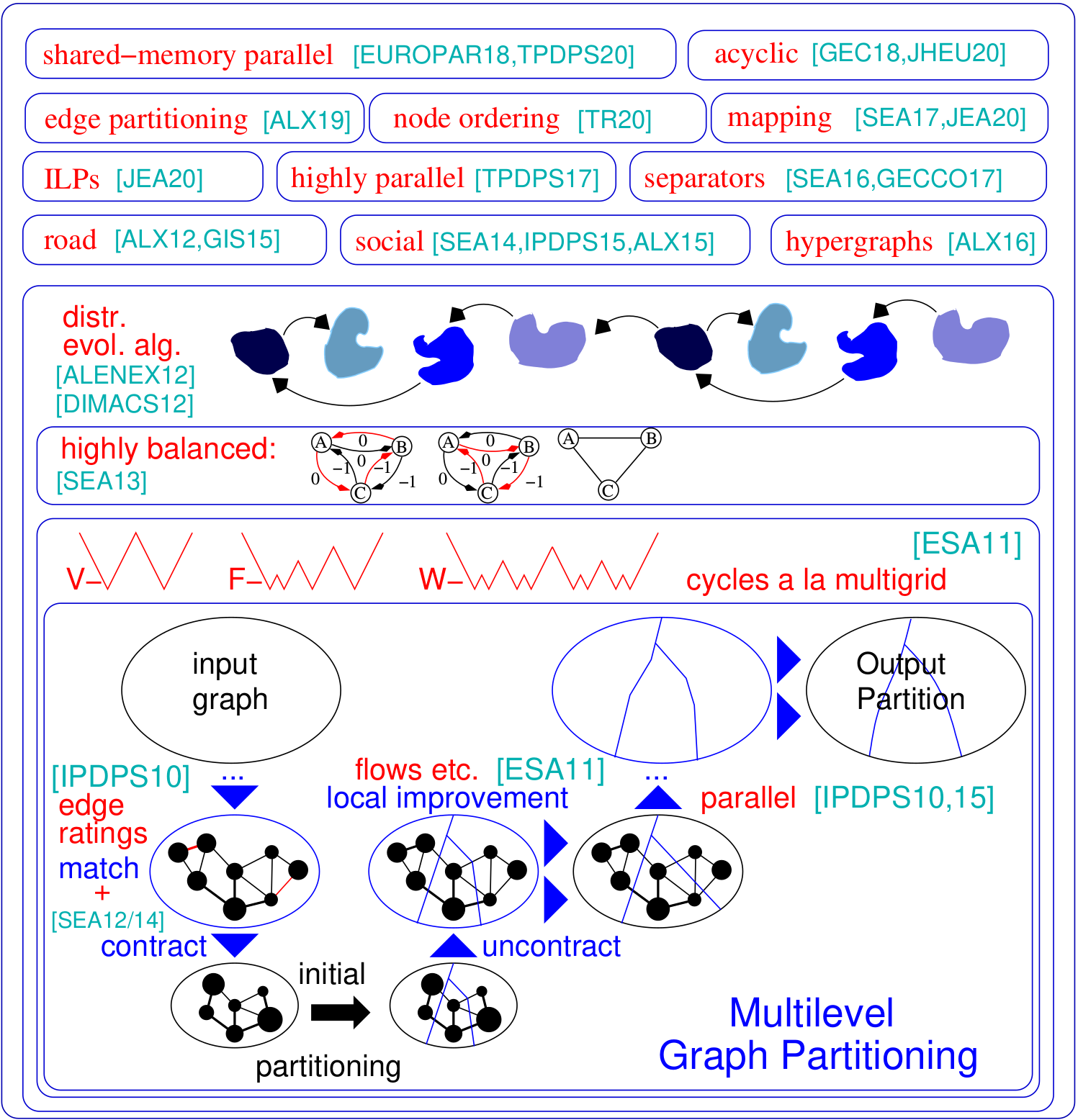
Unterstützung für Python : Kahip kann jetzt auch in Python verwendet werden. Siehe unten, wie das geht.
Hierarchische Partitionierungen : Kahip kann hierarchiale Partitionierungen berechnen. Alles, was Sie tun müssen, ist, die Hierarchie anzugeben und Kahip bereit ist, die Multisektion wie Sie angegeben zu haben.
Knotenbestellalgorithmen : Viele Anwendungen stützen sich auf zeitintensive Matrixoperationen wie Faktorisierung, die für große spärliche Matrizen erheblich angezeigt werden können, indem die Matrix als spärlichem Diagramm interpretiert und eine Knotenbestellung berechnet wird, die das sogenannte Einfüllen minimiert. Hier haben wir neue Algorithmen hinzugefügt, um reduzierte Aufträge in Grafiken zu berechnen.
ILPs für noch höhere Qualität : ILPs skalieren normalerweise nicht auf große Instanzen. Wir passen sie an eine bestimmte Partition an, um heuristisch zu verbessern. Wir tun dies, indem wir ein viel kleineres Modell definieren, das es uns ermöglicht, Symmetriebrechung und andere Techniken zu verwenden, die den Ansatz skalierbar machen. Wir schließen ILPs ein, die als Nachbearbeitungsschritt verwendet werden können, um hochwertige Partitionen noch weiter zu verbessern. Die Codes sind jetzt in Kahip enthalten.
TCMALLOC: Wir haben die Möglichkeit hinzugefügt, mit TCMALLOC zu verknüpfen. Abhängig von Ihrem System kann dies insgesamt einen schnelleren Algorithmus ergeben, da es einen schnelleren Malloc -Betrieb bietet.
Schnelleres IO : Wir haben KAFFPA (Option -mmap_io) eine Option hinzugefügt, die die IO von Textdateien erheblich beschleunigt -manchmal um eine Größenordnung.
Unterstützung für Scheitelpunkte und Kantengewichte in Parhip hinzugefügt : Wir haben die IO -Funktionalität von Parhip erweitert, um gewichtete Graphen im Metis -Format zu lesen.
Globale Multisection-Mapping : Wir haben globale Multisektions-N-zu-1-Prozesszuordnungsalgorithmen hinzugefügt. Dies berechnet eine bessere Prozesszuordnung für parallele Anwendungen, wenn Informationen über die Systemhierarchie/Architektur bekannt sind.
Determinismus in der Parhip : Wir haben die Option hinzugefügt, Parhomy Deterministisch auszuführen. Er dh zwei Läufe der Parheide mit demselben Saatgut werden immer das gleiche Ergebnis zurückgegeben.
Versionsflag : Wir haben die Option hinzugefügt, um die Version, die Sie derzeit verwenden, die Option -Version der Programme zu verwenden.
Parallel (parallele hochwertige Partitionierung): Unsere verteilten Speicher -Parallel -Partitionierungstechniken sind so konzipiert, dass sie hierarchisch strukturierte Netzwerke wie Webgraphen oder soziale Netzwerke partitionieren.
Mapping -Algorithmen: Unsere neuen Algorithmen, um die Blöcke den Prozessoren zuzuordnen, um die Gesamtkommunikationszeit basierend auf hierarchischen Partitionierungen des Task -Diagramms und schnellen lokalen Suchalgorithmen zu minimieren.
Edge -Partitionierungsalgorithmen: Unsere neuen Algorithmen zur Berechnung der Kantenpartitionierungen von Graphen.
https://kahip.github.io
Sie können Kahip mit der folgenden Befehlszeile herunterladen:
git clone https://github.com/KaHIP/KaHIP Bevor Sie beginnen, müssen Sie die folgenden Softwarepakete installieren:
Sobald Sie die Pakete installiert haben, geben Sie einfach ein
./compile_withcmake.sh In diesem Fall befinden sich alle Binärdateien, Bibliotheken und Header im Ordner ./deploy/
Beachten Sie, dass dieses Skript die Anzahl der verfügbaren Kerne auf Ihrer Maschine erkennt und alle für den Kompilierungsprozess verwendet. Wenn Sie das nicht wollen, stellen Sie die variablen NCores auf die Anzahl der Kerne ein, die Sie zur Zusammenstellung verwenden möchten.
Verwenden Sie alternativ den Standard -CMake -Build -Prozess:
mkdir build
cd build
cmake ../ -DCMAKE_BUILD_TYPE=Release
make
cd ..In diesem Fall befinden sich die Binärdateien, Bibliotheken und Header im Ordner ./build sowie ./build/parallel/parallel_src/
Wir bieten auch die Option, mit TCMALLOC zu verlinken. Wenn Sie es installiert haben, führen Sie CMAKE mit der zusätzlichen Option -DUSE_TCMALLOC = ON aus.
Standardmäßig werden Knotenbestellprogramme kompiliert. Wenn Sie Metis installiert haben, erstellt das Build -Skript auch ein schnelleres Knoten -Bestellprogramm, das Reduktionen verwendet, bevor er Metis ND aufgerufen hat. Beachten Sie, dass Metis GKLIB (https://github.com/karypislab/gklib) benötigt.
Wenn Sie die Option -DUSE_ILP = ON verwenden und Gurobi installiert haben, erstellt das Build -Skript die ILP -Programme, um eine bestimmte Partition ILP_Improve und einen exakten Solver ILP_EXACT zu verbessern. Alternativ können Sie diese Optionen auch an ./Compile_withmake.sh übergeben, zum Beispiel:
./compile_withcmake -DUSE_ILP=OnWir bieten auch eine Option zur Unterstützung von 64 Bitkanten. Um dies zu verwenden, kompilieren Sie Kahip mit der Option -d64bitmode = on.
Zuletzt bieten wir eine Option für den Determinismus in der Parhips, z. B. zwei läuft mit demselben Samen. Beachten Sie jedoch, dass diese Option die Qualität von Partitionen verringern kann, da anfängliche Partitionierungsalgorithmen keine ausgefeilten memetischen Algorithmen verwenden, sondern nur Multilevel -Algorithmen zur Berechnung von anfänglichen Partitionierungen. Verwenden Sie diese Option nur, wenn Sie Parhy als Tool verwenden. Verwenden Sie diese Option nicht, wenn Sie Qualitätsvergleiche mit Parhip vornehmen möchten. Um diese Option zu nutzen, führen Sie aus
./compile_withcmake -DDETERMINISTIC_PARHIP=OnFür eine Beschreibung des Graph -Formats (und eine umfangreiche Beschreibung aller anderen Programme) schauen Sie sich bitte das Handbuch an. Wir geben hier kurze Beispiele.
Diese Programme und Konfigurationen nehmen ein Diagramm an und partitionieren Sie es mehr oder weniger nacheinander. Wir listen hier Kaffpa und Kaffpae (das evolutionäre Framework) und deren Konfigurationen auf. Im Allgemeinen sind die Konfigurationen so, dass Sie mit dem memetischen Algorithmus viel Zeit in die Lösungsqualität investieren können. Der memetische Algorithmus kann auch parallel unter Verwendung von MPI ausgeführt werden. Je mehr Zeit und Ressourcen Sie investieren, desto besser wird die Qualität Ihrer Partition. Wir haben viele Kompromisse, kontaktieren Sie uns, wenn Sie sich nicht sicher sind, was für Ihre Bewerbung am besten geeignet ist. Eine Beschreibung des Algorithmus finden Sie in den Referenzen, die wir im Handbuch auflisten.
| Anwendungsfall | Eingang | Programme |
|---|---|---|
| Grafikformat | Graph_Checker | |
| Partitionen bewerten | Bewerter | |
| Schnelle Partitionierung | Maschen | Kaffpa -Vorkonfiguration auf schnell eingestellt |
| Gute Partitionierung | Maschen | KAFFPA -Vorkonfiguration auf ECO eingestellt |
| Sehr gute Partitionierung | Maschen | Kaffpa -Vorkonfiguration auf stark eingestellt |
| Höchste Qualität | Maschen | Kaffpae, Mirun, große Zeitgrenze verwenden |
| Schnelle Partitionierung | Sozial | KAFFPA -Vorkonfiguration auf fSocial eingestellt |
| Gute Partitionierung | Sozial | KAFFPA -Vorkonfiguration auf esoziale Konfiguration |
| Sehr gute Partitionierung | Sozial | KAFFPA -Vorkonfiguration auf ssocial eingestellt |
| Höchste Qualität | Sozial | Kaffpae, Mirun, große Zeitgrenze, Vorkonfiguration Ssocial verwenden |
| Noch höhere Qualität | Kaffpae, verwenden |
./deploy/graph_checker ./examples/rgg_n_2_15_s0.graph ./deploy/kaffpa ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=strong mpirun -n 24 ./deploy/kaffpaE ./examples/rgg_n_2_15_s0.graph --k 4 --time_limit=3600 --mh_enable_tabu_search --mh_enable_kabapE Ein großer Teil des Projekts sind parallele Speicheralgorithmen für Netzwerke mit einer hierarchischen Clusterstruktur wie Webgraphen oder sozialen Netzwerken. Leider funktionieren frühere Parallelgrafikpartitioner, die ursprünglich für regelmäßigere meshähnliche Netzwerke entwickelt wurden, für komplexe Netzwerke nicht gut. Hier befassen wir uns mit diesem Problem, indem wir die ursprünglich für das Graphenclustering entwickelte Etikettvermutzungstechnik parallelisieren und anpassen. Durch die Einführung von Größenbeschränkungen wird die Beschriftungsausbreitung sowohl für die Verhandlung als auch für die Verfeinerungsphase der Multilevel -Graph -Partitionierung anwendbar. Auf diese Weise nutzen wir die hierarchische Clusterstruktur, die in vielen komplexen Netzwerken vorhanden ist. Wir erhalten eine sehr hohe Qualität, indem wir einen hoch parallelen evolutionären Algorithmus auf das koarsste Diagramm anwenden. Das resultierende System ist sowohl skalierbarer als auch eine höhere Qualität als hochmoderne Systeme wie Parrmetis oder Pt-Scotch.
Unser verteilter Speicher -Parallel -Algorithmus kann Binärdateien sowie Standard -Dateien mit Metis -Graph -Format -Format -Dateien lesen. Binärdateien sind im Allgemeinen viel skalierbarer als das Lesen von Textdateien in parallelen Anwendungen. Der Weg hierher besteht darin, die Metis -Datei zuerst in eine Binärdatei (Ende .bgf) umzuwandeln und diese dann zu laden.
| Anwendungsfall | Programme |
|---|---|
| Parallele Partitionierung | Parhip, Graph2Binary, Graph2Binary_external, Toolbox |
| Verteilte Speicher parallel, Netz | Parhy |
| Verteilter Speicher parallel, sozial | Parhomy mit ökosozialen, schnellen, ultrasiklialen Vorkonfigurien |
| Metis in binär konvertieren | Graph2Binary, Graph2Binary_external |
| Partitionen bewerten und konvertieren | Werkzeugkasten |
./deploy/graph2binary examples/rgg_n_2_15_s0.graph examples/rgg_n_2_15_s0.bgf mpirun -n 24 ./deploy/parhip ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=fastmesh mpirun -n 24 ./deploy/parhip ./examples/rgg_n_2_15_s0.bgf --k 4 --preconfiguration=fastmeshDas Problem des Knotenabscheiders fordert die Aufteilung des Knotensatzes eines Diagramms in drei Mengen A, B und S auf, so dass das Entfernen von S abtrennt A und B. Wir verwenden fließbasierte und lokalisierte lokale Suchalgorithmen innerhalb eines mehrstufigen Frameworks, um Knotenabscheider zu berechnen. Kahip kann auch Knotenabscheider berechnen. Dies kann dies mit einem Standardknotenabscheider (2-Wege) tun, kann aber auch K-Way-Knotenabscheider berechnen.
| Anwendungsfall | Programme |
|---|---|
| 2-Wege-Separatoren | node_separator |
| Kway -Separatoren | Verwenden Sie KAFFPA, um K-Partition zu erstellen, und dann partition_to_vertex_separator, um einen Separator zu erstellen |
./deploy/node_separator examples/rgg_n_2_15_s0.graphAnwendungen wie die Faktorisierung können für große spärliche Matrizen erheblich angezeigt werden, indem die Matrix als spärlicher Diagramm interpretiert und eine Knotenreihenfolge berechnet wird, die das sogenannte Füllen minimiert. Durch die umfassende Anwendung neuer und vorhandener Datenreduzierungsregeln vor der verschachtelten Dissektion erhalten wir eine verbesserte Qualität und gleichzeitig große Verbesserungen der Laufzeit in verschiedenen Fällen. Wenn Metis installiert ist, kompiliert das Build -Skript auch das Programm Fast_node_ordering, in dem Reduktionen ausgeführt werden, bevor Metis ausgeführt wird, um eine Bestellung zu berechnen. Die Programme sind auch über die Bibliothek erhältlich.
| Anwendungsfall | Programme |
|---|---|
| Knotenbestellung | node_ordering (mit unterschiedlichen Vorkonfigurationen) |
| Schnelle Knotenbestellung | fast_node_ordering |
./deploy/node_ordering examples/rgg_n_2_15_s0.graph ./deploy/fast_node_ordering examples/rgg_n_2_15_s0.graphVerteilte Berechnungen mit Kanten zentriertes sind als neuere Technik zur Verbesserung der Mängel von Denk- wie--Verstex-Algorithmen in großgradigfreien Netzwerken. Um die Parallelität dieses Modells zu erhöhen, hat sich die Edge-Partitionierung-die Teilung von Kanten in ungefähr gleich große Blöcke-als Alternative zur traditionellen (knotenbasierten) Grafikpartitionierung herausgestellt. Wir enthalten einen schnellen parallelen und sequentiellen Algorithmus mit Split-and-Connect-Graph-Konstruktion, der auf skalierbare Weise qualitativ hochwertige Randpartitionen liefert. Unsere Technik skaliert auf Netzwerke mit Milliarden von Kanten und läuft effizient auf Tausenden von PES.
| Anwendungsfall | Programme |
|---|---|
| Randpartitionierung | Edge_Partitioning, Distributed_Edge_Partitioning |
./deploy/edge_partitioning ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=fast mpirun -n 4 ./deploy/distributed_edge_partitioning ./examples/rgg_n_2_15_s0.bgf --k 4 --preconfiguration=fastsocial Die Verfahrenskarte für Kommunikation und Topologie ist ein leistungsstarker Ansatz, um die Kommunikationszeit in parallelen Anwendungen mit bekannten Kommunikationsmustern auf großen, verteilten Speichersystemen zu verkürzen. Wir befassen uns mit dem Problem als quadratischer Zuordnungsproblem (QAP) und enthalten Algorithmen zum Erstellen von anfänglichen Zuordnungen von Prozessen an Prozessoren sowie schnelle lokale Suchalgorithmen, um die Zuordnungen weiter zu verbessern. Durch die Ausbeutung von Annahmen, die typischerweise für Anwendungen und moderne Supercomputersysteme wie spärliche Kommunikationsmuster und hierarchisch organisierte Kommunikationssysteme gilt, erreichen wir für diese speziellen QAPs erheblich leistungsstärkere Algorithmen. Unsere mehrstufigen Konstruktionsalgorithmen verwenden perfekt ausbalancierte Grafik -Partitionierungstechniken und nutzen die angegebene Hierarchie des Kommunikationssystems übermäßig aus. Seit v3.0 haben wir globale Multisektionsalgorithmen aufgenommen, die das Eingabenetzwerk direkt entlang der angegebenen Hierarchie verteilt, um eine N-zu-1-Zuordnung zu erhalten, und rufen Sie später 1-zu-1-Mapping-Algorithmen auf, um die Zuordnung noch weiter zu verbessern.
| Anwendungsfall | Programme |
|---|---|
| Mapping in Prozessoretzwerke | KAFFPA und verwenden Sie die Option "Enable_Mapping" mit resp. Perkonfigurationen |
| Globale Multisektion | global_multisection mit resp. Perkonfigurationen |
./deploy/kaffpa examples/rgg_n_2_15_s0.graph --k 256 --preconfiguration=eco --enable_mapping --hierarchy_parameter_string=4:8:8 --distance_parameter_string=1:10:100 ./deploy/global_multisection examples/rgg_n_2_15_s0.graph --preconfiguration=eco --hierarchy_parameter_string=4:3:3:3 --distance_parameter_string=1:10:100:200Wir bieten ein ILP sowie eine ILP zur Verbesserung einer bestimmten Partition. Wir erweitern die Nachbarschaft des Kombinationsproblems für mehrere lokale Suchanfragen, indem wir eine integer lineare Programmierung einsetzen. Dies ermöglicht es uns, noch komplexere Kombinationen zu finden und damit Lösungen weiter zu verbessern. Die ILPs für das Problem sind jedoch in der Regel nicht auf große Eingänge skaliert, insbesondere weil das Problem der Graph -Partitionierung eine sehr große Menge an Symmetrie aufweist - angesichts einer Partition des Graphen liefert jede Permutation der Block -IDs eine Lösung mit demselben Objektiv und Gleichgewicht. Wir definieren ein viel kleineres Diagramm, das als Modell bezeichnet wird, und lösen das Graph -Partitionierungsproblem des Modells für die Optimalität durch das ganzzahlige lineare Programm. Neben anderen Dingen ermöglicht dieses Modell die Verwendung von Symmetrieunterbrechungen, die es uns ermöglichen, auf viel größere Eingänge zu skalieren. Um diese Programme zu kompilieren, müssen Sie CMake im obigen Build -Prozess als CMAKE ausführen.
| Anwendungsfall | Programme |
|---|---|
| Exakter Löser | ILP_EXACT |
| Verbesserung über ILP | ILP_IMPOVE |
./deploy/ilp_improve ./examples/rgg_n_2_15_s0.graph --k 4 --input_partition=tmppartition4 ./deploy/ilp_exact ./examples/example_weighted.graph --k 3Kahip bietet auch Bibliotheken und Schnittstellen an, um die Algorithmen direkt mit Ihrem Code zu verknüpfen. Wir erläutern die Details der Schnittstelle im Handbuch. Im Folgenden werden ein Beispielprogramm aufgeführt, das die Kahip -Bibliothek verlinkt. Dieses Beispiel kann auch in Misc/Beispiel_Library_Call/gefunden werden.
# include < iostream >
# include < sstream >
# include " kaHIP_interface.h "
int main ( int argn, char **argv) {
std::cout << " partitioning graph from the manual " << std::endl;
int n = 5 ;
int * xadj = new int [ 6 ];
xadj[ 0 ] = 0 ; xadj[ 1 ] = 2 ; xadj[ 2 ] = 5 ; xadj[ 3 ] = 7 ; xadj[ 4 ] = 9 ; xadj[ 5 ] = 12 ;
int * adjncy = new int [ 12 ];
adjncy[ 0 ] = 1 ; adjncy[ 1 ] = 4 ; adjncy[ 2 ] = 0 ; adjncy[ 3 ] = 2 ; adjncy[ 4 ] = 4 ; adjncy[ 5 ] = 1 ;
adjncy[ 6 ] = 3 ; adjncy[ 7 ] = 2 ; adjncy[ 8 ] = 4 ; adjncy[ 9 ] = 0 ; adjncy[ 10 ] = 1 ; adjncy[ 11 ] = 3 ;
double imbalance = 0.03 ;
int * part = new int [n];
int edge_cut = 0 ;
int nparts = 2 ;
int * vwgt = NULL ;
int * adjcwgt = NULL ;
kaffpa (&n, vwgt, xadj, adjcwgt, adjncy, &nparts, &imbalance, false , 0 , ECO, & edge_cut, part);
std::cout << " edge cut " << edge_cut << std::endl;
}Kahip kann auch in Python verwendet werden. Wenn Sie es in Python First Run verwenden möchten
python3 -m pip install pybind11
Dann rennen
./compile_withcmake.sh BUILDPYTHONMODULEUm das Python -Modell zu erstellen. Dadurch wird das Python -Modul erstellt und auch ein Beispiel Callkahipfrompython.py in den Bereitstellungsordner eingerichtet. Sie können dies ausführen, indem Sie Folgendes im Ordner Bereitstellen eingeben:
python3 callkahipfrompython.py Beachten Sie, dass wir nur vorläufige Unterstützung bieten, dh Sie müssen möglicherweise einige Wege in Python in der Datei compile_withcMake ändern. Ein Beispiel finden Sie auch unten:
import kahip ;
#build adjacency array representation of the graph
xadj = [ 0 , 2 , 5 , 7 , 9 , 12 ];
adjncy = [ 1 , 4 , 0 , 2 , 4 , 1 , 3 , 2 , 4 , 0 , 1 , 3 ];
vwgt = [ 1 , 1 , 1 , 1 , 1 ]
adjcwgt = [ 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ]
supress_output = 0
imbalance = 0.03
nblocks = 2
seed = 0
# set mode
#const int FAST = 0;
#const int ECO = 1;
#const int STRONG = 2;
#const int FASTSOCIAL = 3;
#const int ECOSOCIAL = 4;
#const int STRONGSOCIAL = 5;
mode = 0
edgecut , blocks = kahip . kaffpa ( vwgt , xadj , adjcwgt ,
adjncy , nblocks , imbalance ,
supress_output , seed , mode )
print ( edgecut )
print ( blocks )Das Programm ist unter MIT -Lizenz lizenziert. Wenn Sie Ergebnisse mit unseren Algorithmen veröffentlichen, bestätigen Sie bitte unsere Arbeit, indem Sie das folgende Papier zitieren:
@inproceedings{sandersschulz2013,
AUTHOR = {Sanders, Peter and Schulz, Christian},
TITLE = {{Think Locally, Act Globally: Highly Balanced Graph Partitioning}},
BOOKTITLE = {Proceedings of the 12th International Symposium on Experimental Algorithms (SEA'13)},
SERIES = {LNCS},
PUBLISHER = {Springer},
YEAR = {2013},
VOLUME = {7933},
PAGES = {164--175}
}
Wenn Sie unseren Parallel Partitioner Parhip verwenden, geben Sie bitte auch das folgende Papier an:
@inproceedings{meyerhenkesandersschulz2017,
AUTHOR = {Meyerhenke, Henning and Sanders, Peter and Schulz, Christian},
TITLE = {{Parallel Graph Partitioning for Complex Networks}},
JOURNAL = {IEEE Transactions on Parallel and Distributed Systems (TPDS)},
VOLUME = {28},
NUMBER = {9},
PAGES = {2625--2638},
YEAR = {2017}
}
Wenn Sie den Mapping -Algorithmus verwenden, zitieren Sie bitte auch das folgende Papier:
@inproceedings{schulztraeff2017,
AUTHOR = {Schulz, Christian and Träff, Jesper Larsson},
TITLE = {{Better Process Mapping and Sparse Quadratic Assignment}},
BOOKTITLE = {Proceedings of the 16th International Symposium on Experimental Algorithms (SEA'17)},
PUBLISHER = {Schloss Dagstuhl - Leibniz-Zentrum fuer Informatik},
VOLUME = {75},
SERIES = {LIPIcs},
PAGES = {4:1--4:15},
YEAR = {2017}
}
Wenn Sie Edge Partitioning -Algorithmen verwenden, geben Sie bitte auch das folgende Papier an:
@inproceedings{edgepartitioning2019,
AUTHOR = {Schlag, Sebastian and Schulz, Christian and Seemaier, Daniel and Strash, Darren},
TITLE = {{Scalable Edge Partitioning}},
BOOKTITLE = {Proceedings of the 21th Workshop on Algorithm Engineering and Experimentation (ALENEX)},
PUBLISHER = {SIAM},
PAGES = {211--225},
YEAR = {2019}
}
Wenn Sie Knotenbestellalgorithmen verwenden, zitieren Sie bitte auch das folgende Papier:
@article{DBLP:journals/corr/abs-2004-11315,
author = {Wolfgang Ost and
Christian Schulz and
Darren Strash},
title = {Engineering Data Reduction for Nested Dissection},
journal = {CoRR},
volume = {abs/2004.11315},
year = {2020},
url = {https://arxiv.org/abs/2004.11315},
archivePrefix = {arXiv},
eprint = {2004.11315},
timestamp = {Tue, 28 Apr 2020 16:10:02 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2004-11315.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Wenn Sie ILP -Algorithmen verwenden, um eine Partition zu verbessern, zitieren Sie bitte auch das folgende Papier:
@inproceedings{DBLP:conf/wea/HenzingerN018,
author = {Alexandra Henzinger and
Alexander Noe and
Christian Schulz},
title = {ILP-based Local Search for Graph Partitioning},
booktitle = {17th International Symposium on Experimental Algorithms, {SEA} 2018},
pages = {4:1--4:15},
year = {2018},
url = {https://doi.org/10.4230/LIPIcs.SEA.2018.4},
doi = {10.4230/LIPIcs.SEA.2018.4},
series = {LIPIcs},
volume = {103},
publisher = {Schloss Dagstuhl - Leibniz-Zentrum f{"{u}}r Informatik}
}
Yaroslaw akhremtsev
Adil Chhabra
Marcelo Fonseca Faraj
Roland Glantz
Alexandra Henzinger
Dennis Luxen
Henning Meyerhenke
Alexander Noe
Mark Olesen
Lara ost
Ilya Safro
Peter Sanders
Hayk Sargsyan
Sebastian Schlag
Christian Schulz (Betreuer)
Daniel Seemaier
Darren Strash
Jesper Larsson Träff


