KaHIP
v3.17
إطار تقسيم الرسم البياني Kahip - Karlsruhe التقسيم عالي الجودة.
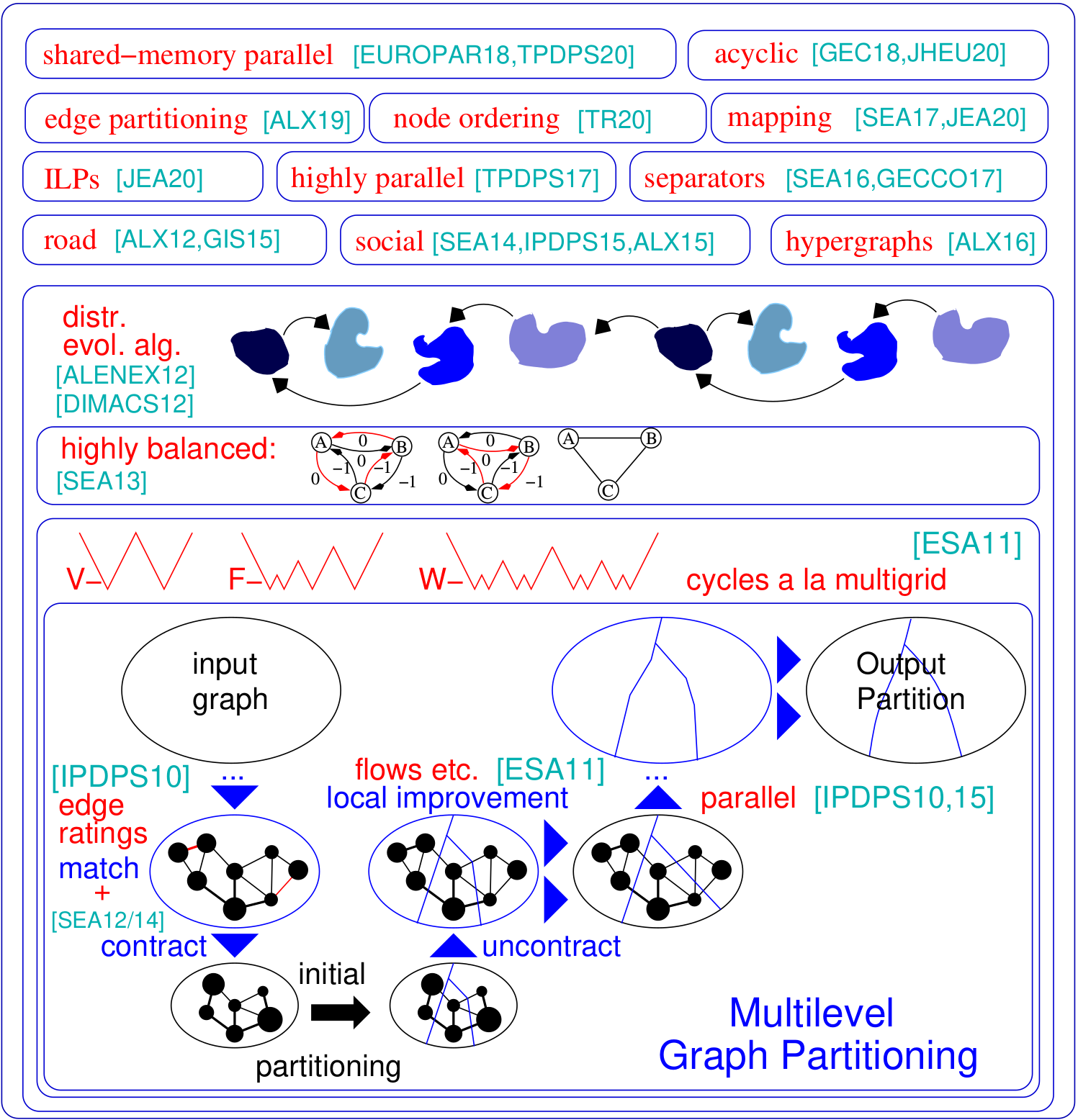
تسأل مشكلة تقسيم الرسم البياني عن تقسيم عقدة الرسم البياني في كتل K على قدم المساواة بحيث يتم تقليل عدد الحواف التي يتم تشغيلها بين الكتل. Kahip هي عائلة من برامج تقسيم الرسوم البيانية. ويشمل Kaffpa (Karlsruhe Fast Flow Partitioner) ، وهو خوارزمية تقسيم الرسم البياني متعدد المستويات ، في المتغيرات القوية ، والبيئة والسريعة ، والكافباي (Kaffpaevolution) ، وهي خوارزمية تطور موازية التي تستخدم Kaffpa لتوفير الجمع والطفرات ، وكذلك Kabape التي تمتد. علاوة على ذلك ، يتم تضمين التقنيات المتخصصة في تقسيم شبكات الطرق (Buffoon) ، لإخراج فاصل قمة الرأس من قسم معين بالإضافة إلى تقنيات موجهة نحو التقسيم الفعال للشبكات الاجتماعية. فيما يلي نظرة عامة على إطار عملنا:
دعم Python : يمكن الآن استخدام Kahip في Python. انظر أدناه كيفية القيام بذلك.
أقسام هرمية : يمكن لـ Kahip حساب الأقسام الهرمية. كل ما عليك فعله هو تحديد التسلسل الهرمي و Kahip جاهز للذهاب والقيام بالتعدد كما هو محدد.
خوارزميات ترتيب العقدة : تعتمد العديد من التطبيقات على عمليات المصفوفة المكثفة الزمنية ، مثل العوامل ، والتي يمكن أن تتفرج بشكل كبير من المصفوفات المتفرقة الكبيرة عن طريق تفسير المصفوفة كرسوم بيانية متناثرة وحساب عقدة تقلل من ما يسمى بالملء. هنا ، أضفنا خوارزميات جديدة لحساب الطلبات المخفضة في التعبئة في الرسوم البيانية.
ILPs لجودة أعلى : ILPs عادة لا تتوسع إلى مثيلات كبيرة. نحن نتكيف معهم مع تحسين قسم معين. نحن نفعل ذلك من خلال تحديد نموذج أصغر بكثير يسمح لنا باستخدام كسر التناظر وغيرها من التقنيات التي تجعل النهج قابلاً للتطوير. نحن ندرج ILPs التي يمكن استخدامها كخطوة ما بعد المعالجة لتحسين أقسام عالية الجودة إلى أبعد من ذلك. يتم تضمين الرموز الآن في كاهيب.
TCMALLOC: أضفنا إمكانية الارتباط مع TCMALLOC. اعتمادًا على نظامك ، يمكن أن ينتج عن ذلك خوارزمية أسرع بشكل عام لأنه يوفر عمليات Malloc أسرع.
أسرع من IO : لقد أضفنا خيارًا إلى Kaffpa (الخيار -mmap_io) الذي يسرع في io من الملفات النصية بشكل كبير -أحيانًا بترتيب من حيث الحجم.
دعم إضافي لأوزان Vertex و Edge في Parryph : قمنا بتوسيع وظيفة IO من Parryp لقراءة الرسوم البيانية الموزونة بتنسيق METIS.
رسم الخرائط المتعددة العالمية : لقد أضفنا خوارزميات تعيين العمليات العالمية المتعددة إلى 1. هذا يحسب تعيين عملية أفضل للتطبيقات المتوازية إذا كانت معلومات حول التسلسل الهرمي/المعماري المعروف.
الحتمية في Parryph : لقد أضفنا خيارًا لتشغيل Parryber بشكل حتمي ، أي شوطين من parryph باستخدام نفس البذور سيعود دائمًا نفس النتيجة.
علامة الإصدار : أضفنا خيارًا لإخراج الإصدار الذي تستخدمه حاليًا ، واستخدم خيار version للبرامج.
Parryp (تقسيم عالي الجودة): تم تصميم تقنيات التقسيم الموازية للذاكرة الموزعة لدينا لتقسيم الشبكات منظمة هرمية مثل الرسوم البيانية على شبكة الإنترنت أو الشبكات الاجتماعية.
خوارزميات رسم الخرائط: خوارزمياتنا الجديدة لتعيين الكتل على المعالجات لتقليل وقت الاتصال العام بناءً على الأقسام الهرمية للرسم البياني المهمة وخوارزميات البحث المحلية السريعة.
خوارزميات تقسيم الحافة: خوارزمياتنا الجديدة لحساب أقسام الحافة من الرسوم البيانية.
https://kahip.github.io
يمكنك تنزيل Kahip مع سطر الأوامر التالي:
git clone https://github.com/KaHIP/KaHIP قبل أن تتمكن من البدء ، تحتاج إلى تثبيت حزم البرامج التالية:
بمجرد تثبيت الحزم ، اكتب فقط
./compile_withcmake.sh في هذه الحالة ، توجد جميع الثنائيات والمكتبات والرؤوس في المجلد ./deploy/
لاحظ أن هذا البرنامج النصي يكتشف مقدار النوى المتاحة على جهازك ويستخدمها جميعًا لعملية التجميع. إذا كنت لا تريد ذلك ، فقم بتعيين المتغير NCORES على عدد النوى التي ترغب في استخدامها للتجميع.
بدلاً من ذلك ، استخدم عملية بناء Cmake القياسية:
mkdir build
cd build
cmake ../ -DCMAKE_BUILD_TYPE=Release
make
cd ..في هذه الحالة ، توجد الثنائيات والمكتبات والرؤوس في المجلد.
نقدم أيضًا خيار الارتباط مع TCMALLOC. إذا قمت بتثبيتها ، فتشغيل Cmake مع الخيار الإضافي -duse_tcmalloc = ON.
بشكل افتراضي ، يتم تجميع برامج طلب العقدة. إذا قمت بتثبيت METIS ، فإن برنامج Build Script يقوم أيضًا بتجميع برنامج طلب عقدة أسرع يستخدم التخفيضات قبل استدعاء Metis nd. لاحظ أن metis يتطلب gklib (https://github.com/karypislab/gklib).
إذا كنت تستخدم الخيار -duse_ilp = ON وكنت قد قمت بتثبيت GUROBI ، فإن برنامج Build Script يقوم بتجميع برامج ILP لتحسين قسم معين ILP_IMPROVE و SOLVER ILP_EXACT دقيق. بدلاً من ذلك ، يمكنك أيضًا تمرير هذه الخيارات إلى ./compile_withmake.sh على سبيل المثال:
./compile_withcmake -DUSE_ILP=Onنقدم أيضًا خيارًا لدعم حواف 64 بت. من أجل استخدام هذا ، قم بتجميع kahip مع الخيار -D64BitMode = ON.
أخيرًا ، نقدم خيارًا للحتمية في Parryph ، على سبيل المثال ، سيمنحك شوطان مع نفس البذرة نفس النتيجة. ومع ذلك ، لاحظ أن هذا الخيار يمكن أن يقلل من جودة الأقسام ، حيث لا تستخدم خوارزميات التقسيم الأولية خوارزميات متطورة ، ولكن فقط خوارزميات متعددة المستويات لحساب الأقسام الأولية. استخدم هذا الخيار فقط إذا كنت تستخدم Parryp كأداة. لا تستخدم هذا الخيار إذا كنت ترغب في إجراء مقارنات الجودة مقابل Parryp. للاستفادة من هذا الخيار ، قم بتشغيل
./compile_withcmake -DDETERMINISTIC_PARHIP=Onللحصول على وصف لتنسيق الرسم البياني (ووصفًا مكثفًا لجميع البرامج الأخرى) ، يرجى إلقاء نظرة على الدليل. نعطي أمثلة قصيرة هنا.
تأخذ هذه البرامج والتكوينات رسم بياني وتقسيمه بشكل متتابع أكثر أو أقل. ندرج هنا Kaffpa و Kaffpae (الإطار التطوري) وتكويناتها. بشكل عام ، فإن التكوينات بحيث يمكنك استثمار الكثير من الوقت في جودة الحلول باستخدام خوارزمية memetic. يمكن أيضًا تشغيل خوارزمية memetic بالتوازي باستخدام MPI. بشكل عام ، كلما زاد الوقت والموارد التي تستثمرها ، سيكون أفضل جودة التقسيم الخاص بك. لدينا الكثير من المقايضات ، اتصل بنا إذا لم تكن متأكدًا من ما هو أفضل لتطبيقك. للحصول على وصف للخوارزمية ، ألق نظرة على المراجع التي ندرجها في الدليل.
| استخدام الحالة | مدخل | البرامج |
|---|---|---|
| تنسيق الرسم البياني | graph_checker | |
| تقييم الأقسام | المقيِّم | |
| التقسيم السريع | شبكات | تم تعيين التكوين المسبق Kaffpa إلى الصيام |
| تقسيم جيد | شبكات | تم تعيين التكوين المسبق Kaffpa إلى Eco |
| تقسيم جيد جدا | شبكات | تم تعيين التكوين المسبق Kaffpa إلى قوي |
| أعلى جودة | شبكات | kaffpae ، استخدم mpirun ، حد زمني كبير |
| التقسيم السريع | اجتماعي | تم تعيين التكوين المسبق Kaffpa على fsocial |
| تقسيم جيد | اجتماعي | تم تعيين التكوين المسبق Kaffpa إلى esocial |
| تقسيم جيد جدا | اجتماعي | تم تعيين التكوين المسبق Kaffpa على ssocial |
| أعلى جودة | اجتماعي | kaffpae ، استخدم mpirun ، حد زمني كبير ، التكوين المسبق ssocial |
| جودة أعلى | kaffpae ، استخدم mpirun ، حد زمني كبير ، استخدم الخيارات -mh_enable_tabu_search ، -mh_enable_kabape |
./deploy/graph_checker ./examples/rgg_n_2_15_s0.graph ./deploy/kaffpa ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=strong mpirun -n 24 ./deploy/kaffpaE ./examples/rgg_n_2_15_s0.graph --k 4 --time_limit=3600 --mh_enable_tabu_search --mh_enable_kabapE جزء كبير من المشروع هو خوارزميات موازية للذاكرة المصممة للشبكات التي لها بنية كتلة هرمية مثل الرسوم البيانية على شبكة الإنترنت أو الشبكات الاجتماعية. لسوء الحظ ، لا يعمل أجهزة الرسم البياني السابق السابق الذي تم تطويره في الأصل للحصول على شبكات شبيهة بالشبكات بشكل منتظم بشكل جيد للشبكات المعقدة. هنا نعالج هذه المشكلة من خلال موازاة وتكييف تقنية انتشار الملصقات التي تم تطويرها أصلاً لتجميع الرسم البياني. من خلال إدخال قيود الحجم ، يصبح انتشار الملصقات قابلاً للتطبيق على كل من مرحلة التحسين والتقسيم الرسم البياني متعدد المستويات. وبهذه الطريقة ، نستغل بنية الكتلة الهرمية الموجودة في العديد من الشبكات المعقدة. نحصل على جودة عالية جدًا من خلال تطبيق خوارزمية تطورية متوازية للغاية على الرسم البياني الأكثر خشونة. النظام الناتج أكثر قابلية للتطوير ويحقق جودة أعلى من الأنظمة الحديثة مثل parmetis أو pt-scotch.
يمكن لخوارزمية موازية الذاكرة الموزعة لدينا قراءة الملفات الثنائية بالإضافة إلى ملفات تنسيق الرسم البياني METIS القياسي. الملفات الثنائية ، بشكل عام ، أكثر قابلية للتطوير من قراءة الملفات النصية في تطبيقات متوازية. الطريق للذهاب إلى هنا هو تحويل ملف metis إلى ملف ثنائي أولاً (إنهاء .bgf) ثم تحميل هذا.
| استخدام الحالة | البرامج |
|---|---|
| تقسيم موازي | parryph ، graph2binary ، graph2binary_external ، toolbox |
| موزع الذاكرة الموازية ، شبكة | parryph مع preconfigs ecomesh ، fastmesh ، ultrafastmesh |
| الذاكرة الموزعة موازية ، اجتماعية | parryph مع preconfigs ecosocial ، fastsocial ، فائق الخثارة |
| تحويل metis إلى ثنائي | graph2binary ، graph2binary_external |
| تقييم الأقسام وتحويلها | أدوات |
./deploy/graph2binary examples/rgg_n_2_15_s0.graph examples/rgg_n_2_15_s0.bgf mpirun -n 24 ./deploy/parhip ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=fastmesh mpirun -n 24 ./deploy/parhip ./examples/rgg_n_2_15_s0.bgf --k 4 --preconfiguration=fastmeshتطلب مشكلة فاصل العقدة تقسيم مجموعة العقدة من الرسم البياني إلى ثلاث مجموعات A و B و S بحيث يتم إزالة S و B. نستخدم خوارزميات البحث المحلية المستندة إلى التدفق داخل إطار عمل متعدد المستويات لحساب فاصل العقدة. يمكن أن يحسب Kahip أيضًا فواصل العقدة. يمكن أن تفعل ذلك مع فاصل عقدة قياسي (في اتجاهين) ، ولكن يمكن أيضًا حساب فاصل عقدة K-Way.
| استخدام الحالة | البرامج |
|---|---|
| فواصل 2 اتجاه | node_separator |
| فواصل Kway | استخدم kaffpa لإنشاء k-partition ، ثم partition_to_vertex_separator لإنشاء فاصل |
./deploy/node_separator examples/rgg_n_2_15_s0.graphيمكن أن يتم تسليط التطبيقات مثل العوامل بشكل كبير للمصفوفات الكبيرة المتناثرة من خلال تفسير المصفوفة كرسوم بيانية متناثرة وحساب عقدة يقلل من ما يسمى بالملء. من خلال تطبيق كل من قواعد تخفيض البيانات الجديدة والحالية بشكل شامل قبل التشريح المتداخل ، نحصل على جودة محسّنة وفي نفس الوقت تحسينات كبيرة في وقت التشغيل في مجموعة متنوعة من الحالات. إذا تم تثبيت METIS ، فإن برنامج Build Script يقوم أيضًا بتجميع برنامج Fast_node_ordering ، والذي يعمل على تشغيل التخفيضات قبل تشغيل Metis لحساب الطلب. البرامج متاحة أيضا من خلال المكتبة.
| استخدام الحالة | البرامج |
|---|---|
| ترتيب العقدة | node_ordering (مع عمليات مسبقة مختلفة) |
| ترتيب العقدة السريعة | fast_node_ordering |
./deploy/node_ordering examples/rgg_n_2_15_s0.graph ./deploy/fast_node_ordering examples/rgg_n_2_15_s0.graphظهرت الحسابات الموزعة المتمحورة حول الحافة كتقنية حديثة لتحسين أوجه القصور في خوارزميات الفكر مثل الفكر على الشبكات الخالية من النطاق. من أجل زيادة التوازي في هذا النموذج ، ظهر تقسيم الحافة-تقسيم الحواف إلى كتل بحجم تقريبًا-كبديل لتقسيم الرسم البياني التقليدي (القائم على العقدة). نحن ندرج خوارزمية بناء الرسم البياني والتوصيل السريع والتوصيل السريع التي تعطي أقسام حافة عالية الجودة بطريقة قابلة للتطوير. تقارن تقنيتنا إلى الشبكات التي تحتوي على مليارات الحواف ، ويعمل بكفاءة على الآلاف من PEs.
| استخدام الحالة | البرامج |
|---|---|
| تقسيم الحافة | edge_partitioning ، distributed_edge_partitioning |
./deploy/edge_partitioning ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=fast mpirun -n 4 ./deploy/distributed_edge_partitioning ./examples/rgg_n_2_15_s0.bgf --k 4 --preconfiguration=fastsocial يعد تعيين عملية التواصل والطوبولوجيا طريقة قوية لتقليل وقت الاتصال في التطبيقات الموازية مع أنماط اتصال معروفة على أنظمة الذاكرة الكبيرة الموزعة. نحن نتصدى للمشكلة كمشكلة تعيين تربيعية (QAP) ، وتضمين خوارزميات لبناء تعيينات أولية للعمليات للمعالجات وكذلك خوارزميات البحث المحلية السريعة لزيادة تحسين التعيينات. من خلال استغلال الافتراضات التي عادة ما تتمسك بالتطبيقات وأنظمة الحاسبات الفائقة الحديثة مثل أنماط الاتصال المتفرقة وأنظمة الاتصالات المنظمة هرمية ، نصل إلى خوارزميات أكثر قوة لهذه QAPs الخاصة. تستخدم خوارزميات البناء متعددة المستويات تقنيات تقسيم الرسوم البيانية المتوازنة تمامًا واستغلال التسلسل الهرمي لنظام الاتصالات المفرط. منذ V3.0 ، قمنا بتضمين خوارزميات Global Multissection التي تقوم مباشرة بتقسيم شبكة الإدخال على طول التسلسل الهرمي المحدد للحصول على رسم خرائط N-to-1 وبعد ذلك استدعاء خوارزميات رسم الخرائط من 1 إلى 1 لزيادة تحسين التعيين.
| استخدام الحالة | البرامج |
|---|---|
| رسم الخرائط لشبكات المعالج | kaffpa ، واستخدم خيار enable_mapping مع resp. perconfigurations |
| متعددة العالمية | global_multisection مع resp. perconfigurations |
./deploy/kaffpa examples/rgg_n_2_15_s0.graph --k 256 --preconfiguration=eco --enable_mapping --hierarchy_parameter_string=4:8:8 --distance_parameter_string=1:10:100 ./deploy/global_multisection examples/rgg_n_2_15_s0.graph --preconfiguration=eco --hierarchy_parameter_string=4:3:3:3 --distance_parameter_string=1:10:100:200نحن نقدم ILP وكذلك ILP لتحسين قسم معين. نقوم بتوسيع حي مشكلة التركيب لعمليات البحث المحلية المتعددة من خلال استخدام البرمجة الخطية الصحيحة. وهذا يمكّننا من إيجاد مجموعات أكثر تعقيدًا وبالتالي لتحسين الحلول. ومع ذلك ، من خارج المربع ، فإن ILPs للمشكلة عادة لا تتوسع في المدخلات الكبيرة ، خاصة لأن مشكلة تقسيم الرسم البياني لها قدر كبير جدًا من التماثل - بالنظر إلى قسم من الرسم البياني ، فإن كل تقليب معرفات الكتلة يعطي حلًا له نفس الهدف والتوازن. نحدد رسمًا بيانيًا أصغر بكثير ، يسمى النموذج ، وحل مشكلة تقسيم الرسم البياني على النموذج إلى الأمثلية من خلال البرنامج الخطي الصحيح. إلى جانب أشياء أخرى ، يمكّننا هذا النموذج من استخدام كسر التناظر ، مما يسمح لنا بالتوسيع إلى مدخلات أكبر بكثير. من أجل تجميع هذه البرامج ، تحتاج إلى تشغيل cmake في عملية الإنشاء أعلاه كـ cmake ../ -dcmake_build_type = release -duse_ilp = on or run ./compile_withcmake -duse_ilp = on.
| استخدام الحالة | البرامج |
|---|---|
| حلال دقيق | ILP_EXACT |
| تحسين عبر ILP | ilp_improve |
./deploy/ilp_improve ./examples/rgg_n_2_15_s0.graph --k 4 --input_partition=tmppartition4 ./deploy/ilp_exact ./examples/example_weighted.graph --k 3تقدم Kahip أيضًا المكتبات والواجهات لربط الخوارزميات مباشرة برمزك. نوضح تفاصيل الواجهة في الدليل. ندرج أدناه برنامج مثال يربط مكتبة Kahip. يمكن العثور على هذا المثال أيضًا في MISC/example_library_call/.
# include < iostream >
# include < sstream >
# include " kaHIP_interface.h "
int main ( int argn, char **argv) {
std::cout << " partitioning graph from the manual " << std::endl;
int n = 5 ;
int * xadj = new int [ 6 ];
xadj[ 0 ] = 0 ; xadj[ 1 ] = 2 ; xadj[ 2 ] = 5 ; xadj[ 3 ] = 7 ; xadj[ 4 ] = 9 ; xadj[ 5 ] = 12 ;
int * adjncy = new int [ 12 ];
adjncy[ 0 ] = 1 ; adjncy[ 1 ] = 4 ; adjncy[ 2 ] = 0 ; adjncy[ 3 ] = 2 ; adjncy[ 4 ] = 4 ; adjncy[ 5 ] = 1 ;
adjncy[ 6 ] = 3 ; adjncy[ 7 ] = 2 ; adjncy[ 8 ] = 4 ; adjncy[ 9 ] = 0 ; adjncy[ 10 ] = 1 ; adjncy[ 11 ] = 3 ;
double imbalance = 0.03 ;
int * part = new int [n];
int edge_cut = 0 ;
int nparts = 2 ;
int * vwgt = NULL ;
int * adjcwgt = NULL ;
kaffpa (&n, vwgt, xadj, adjcwgt, adjncy, &nparts, &imbalance, false , 0 , ECO, & edge_cut, part);
std::cout << " edge cut " << edge_cut << std::endl;
}يمكن أيضًا استخدام كاهيب في بيثون. إذا كنت ترغب في استخدامه في Python First Run
python3 -m pip install pybind11
ثم ركض
./compile_withcmake.sh BUILDPYTHONMODULEلبناء نموذج بيثون. سيؤدي ذلك إلى بناء وحدة Python ويضع أيضًا مثالًا على Callkahipfrompython.py في مجلد النشر. يمكنك تشغيل هذا عن طريق كتابة ما يلي في مجلد النشر:
python3 callkahipfrompython.py لاحظ أننا نقدم الدعم الأولي فقط ، أي قد تحتاج إلى تغيير بعض المسارات إلى Python داخل ملف Compile_WithCmake. يمكن أيضًا العثور على مثال أدناه:
import kahip ;
#build adjacency array representation of the graph
xadj = [ 0 , 2 , 5 , 7 , 9 , 12 ];
adjncy = [ 1 , 4 , 0 , 2 , 4 , 1 , 3 , 2 , 4 , 0 , 1 , 3 ];
vwgt = [ 1 , 1 , 1 , 1 , 1 ]
adjcwgt = [ 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ]
supress_output = 0
imbalance = 0.03
nblocks = 2
seed = 0
# set mode
#const int FAST = 0;
#const int ECO = 1;
#const int STRONG = 2;
#const int FASTSOCIAL = 3;
#const int ECOSOCIAL = 4;
#const int STRONGSOCIAL = 5;
mode = 0
edgecut , blocks = kahip . kaffpa ( vwgt , xadj , adjcwgt ,
adjncy , nblocks , imbalance ,
supress_output , seed , mode )
print ( edgecut )
print ( blocks )البرنامج مرخص بموجب ترخيص معهد ماساتشوستس للتكنولوجيا. إذا قمت بنشر نتائج باستخدام خوارزمياتنا ، فيرجى الاعتراف بعملنا من خلال الاقتباس من الورقة التالية:
@inproceedings{sandersschulz2013,
AUTHOR = {Sanders, Peter and Schulz, Christian},
TITLE = {{Think Locally, Act Globally: Highly Balanced Graph Partitioning}},
BOOKTITLE = {Proceedings of the 12th International Symposium on Experimental Algorithms (SEA'13)},
SERIES = {LNCS},
PUBLISHER = {Springer},
YEAR = {2013},
VOLUME = {7933},
PAGES = {164--175}
}
إذا كنت تستخدم PARTITIONER PARIPER المتوازي ، فيرجى الاستشهاد أيضًا بالورقة التالية:
@inproceedings{meyerhenkesandersschulz2017,
AUTHOR = {Meyerhenke, Henning and Sanders, Peter and Schulz, Christian},
TITLE = {{Parallel Graph Partitioning for Complex Networks}},
JOURNAL = {IEEE Transactions on Parallel and Distributed Systems (TPDS)},
VOLUME = {28},
NUMBER = {9},
PAGES = {2625--2638},
YEAR = {2017}
}
إذا كنت تستخدم خوارزمية رسم الخرائط ، فيرجى الاستشهاد أيضًا بالورقة التالية:
@inproceedings{schulztraeff2017,
AUTHOR = {Schulz, Christian and Träff, Jesper Larsson},
TITLE = {{Better Process Mapping and Sparse Quadratic Assignment}},
BOOKTITLE = {Proceedings of the 16th International Symposium on Experimental Algorithms (SEA'17)},
PUBLISHER = {Schloss Dagstuhl - Leibniz-Zentrum fuer Informatik},
VOLUME = {75},
SERIES = {LIPIcs},
PAGES = {4:1--4:15},
YEAR = {2017}
}
إذا كنت تستخدم خوارزميات تقسيم الحافة ، يرجى أيضًا الاستشهاد بالورقة التالية:
@inproceedings{edgepartitioning2019,
AUTHOR = {Schlag, Sebastian and Schulz, Christian and Seemaier, Daniel and Strash, Darren},
TITLE = {{Scalable Edge Partitioning}},
BOOKTITLE = {Proceedings of the 21th Workshop on Algorithm Engineering and Experimentation (ALENEX)},
PUBLISHER = {SIAM},
PAGES = {211--225},
YEAR = {2019}
}
إذا كنت تستخدم خوارزميات طلب العقدة ، فيرجى الاستشهاد أيضًا بالورقة التالية:
@article{DBLP:journals/corr/abs-2004-11315,
author = {Wolfgang Ost and
Christian Schulz and
Darren Strash},
title = {Engineering Data Reduction for Nested Dissection},
journal = {CoRR},
volume = {abs/2004.11315},
year = {2020},
url = {https://arxiv.org/abs/2004.11315},
archivePrefix = {arXiv},
eprint = {2004.11315},
timestamp = {Tue, 28 Apr 2020 16:10:02 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2004-11315.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
إذا كنت تستخدم خوارزميات ILP لتحسين قسم ما ، فيرجى الاستشهاد أيضًا بالورقة التالية:
@inproceedings{DBLP:conf/wea/HenzingerN018,
author = {Alexandra Henzinger and
Alexander Noe and
Christian Schulz},
title = {ILP-based Local Search for Graph Partitioning},
booktitle = {17th International Symposium on Experimental Algorithms, {SEA} 2018},
pages = {4:1--4:15},
year = {2018},
url = {https://doi.org/10.4230/LIPIcs.SEA.2018.4},
doi = {10.4230/LIPIcs.SEA.2018.4},
series = {LIPIcs},
volume = {103},
publisher = {Schloss Dagstuhl - Leibniz-Zentrum f{"{u}}r Informatik}
}
Yaroslav Akhremtsev
عادل تشابرا
مارسيلو فونسيكا فاراج
رولاند غلانتز
ألكسندرا هنزينجر
دينيس لوكن
هينينغ مايرهينك
ألكساندر نوي
مارك أوليسن
لارا أوست
إيليا سافرو
بيتر ساندرز
Hayk Sargsyan
سيباستيان شلاج
كريستيان شولز (المشرف)
دانييل ساياير
دارين ستراش
جيسبر لارسون تراف


