KaHIP
v3.17
グラフパーティションフレームワークKahip -Karlsruhe高品質のパーティション。
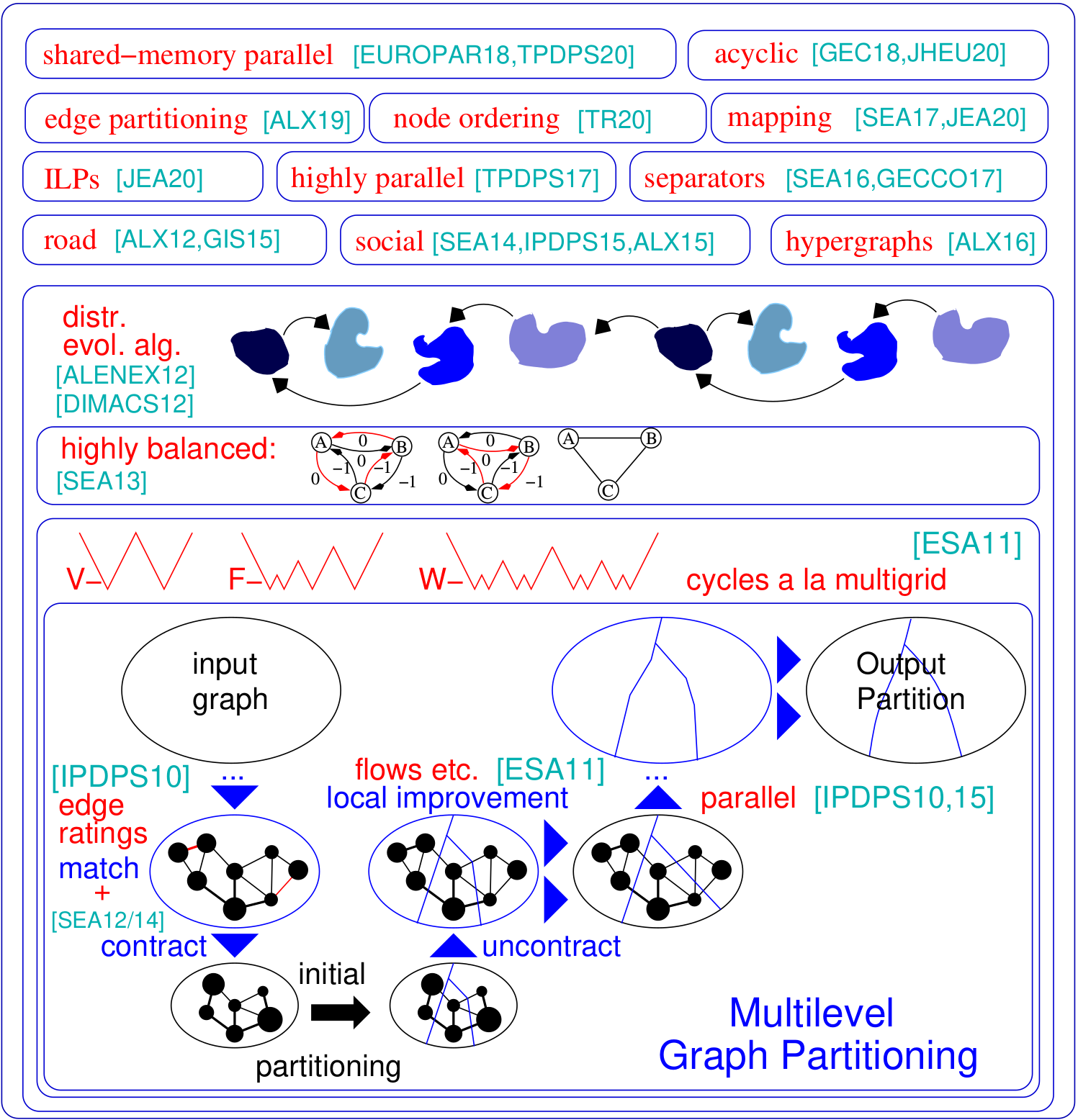
グラフパーティションの問題は、ブロック間で実行されるエッジの数が最小化されるように、k同等のサイズのブロックに設定されたグラフのノードの分割を要求します。 Kahipは、グラフパーティションプログラムの家族です。カフパ(Karlsruhe Fast Flow Partitioner)が含まれています。これは、強力でエコおよびファストのカフペ(Kaffpaevolutionaly)のバリエーションであるマルチレベルグラフパーティションアルゴリズムです。さらに、パーティションロードネットワーク(Buffoon)には専門的な手法が含まれ、特定のパーティションから頂点分離器を出力し、ソーシャルネットワークの効率的なパーティション化を対象とした手法が含まれています。これが私たちのフレームワークの概要です:
Pythonのサポート:KahipもPythonで使用できるようになりました。それを行う方法を以下に参照してください。
階層分割:Kahipは階層分割を計算できます。あなたがしなければならないのは、階層を指定することだけで、Kahipは準備ができており、指定したとおりにマルチセクションを行います。
ノード順序付けアルゴリズム:多くのアプリケーションは、マトリックスをスパースグラフとして解釈し、いわゆる塗りつぶしを最小限に抑えるノード順序を計算することで、大きなスパースマトリックスで大幅に上昇する可能性のある、要因化などの時間集約型マトリックス操作に依存しています。ここでは、グラフの記入済み注文を計算するために新しいアルゴリズムを追加しました。
さらに高品質のILP :ILPは通常、大規模なインスタンスにスケーリングしません。それらを特定のパーティションを強盗的に改善するように適応します。これを行うと、対称性の破壊とアプローチをスケーラブルにする他の手法を使用できるはるかに小さなモデルを定義します。高品質のパーティションをさらに改善するための後処理ステップとして使用できるILPを含めます。コードは現在Kahipに含まれています。
TCMALLOC: Tcmallocに対してリンクする可能性を追加しました。システムに応じて、Malloc操作が高速で提供されるため、全体的に高速なアルゴリズムを生成できます。
より高速なIO :TextファイルのIOを大幅に高速化するKaffpa(オプション-MMAP_IO)にオプションを追加しました。
意字の頂点とエッジウェイトのサポートを追加しました:領域のIO機能を拡張して、メティス形式で加重グラフを読み取りました。
グローバルマルチセクションマッピング:グローバルマルチセクションN-to-1プロセスマッピングアルゴリズムを追加しました。これにより、システム階層/アーキテクチャに関する情報がわかっている場合、並列アプリケーションのより良いプロセスマッピングを計算します。
所長の決定論:決定論的に並外れて並べるオプションを追加しました。つまり、同じ種子を使用して2つの並べ替えが常に同じ結果を返します。
バージョンフラグ:現在使用しているバージョンを出力するオプションを追加しました。プログラムの-versionオプションを使用します。
Parhip(並列高品質のパーティション化):分散メモリ並列パーティション技術は、Webグラフやソーシャルネットワークなどの階層的に構造化されたネットワークをパーティション化するように設計されています。
マッピングアルゴリズム:ブロックをプロセッサにマッピングして、タスクグラフの階層分割と高速ローカル検索アルゴリズムに基づいて、全体的な通信時間を最小限に抑える新しいアルゴリズム。
エッジパーティションアルゴリズム:グラフのエッジパーティションを計算するための新しいアルゴリズム。
https://kahip.github.io
次のコマンドラインでKahipをダウンロードできます。
git clone https://github.com/KaHIP/KaHIP 開始する前に、次のソフトウェアパッケージをインストールする必要があります。
パッケージをインストールしたら、入力するだけです
./compile_withcmake.sh この場合、すべてのバイナリ、ライブラリ、ヘッダーがフォルダーにあります。/deploy/
このスクリプトは、マシンで利用可能なコアの量を検出し、それらすべてをコンパイルプロセスに使用することに注意してください。それを望まない場合は、コンパイルに使用したいコアの数に可変nCoresを設定します。
または、標準のcmakeビルドプロセスを使用します。
mkdir build
cd build
cmake ../ -DCMAKE_BUILD_TYPE=Release
make
cd ..この場合、バイナリ、ライブラリ、ヘッダーはフォルダーにあります。/build/build/parallel/parallel_src/
また、tcmallocに対してリンクするオプションも提供します。インストールしている場合は、追加のオプション-duse_tcmalloc = onでcmakeを実行します。
デフォルトでは、ノード注文プログラムもコンパイルされます。 Metisがインストールされている場合、Build Scriptは、Metis NDを呼び出す前に削減を使用するより高速なノード順序付けプログラムもコンパイルします。 Metisにはgklib(https://github.com/karypislab/gklib)が必要であることに注意してください。
オプション-duse_ilp = onを使用してGurobiをインストールした場合、ビルドスクリプトはILPプログラムをコンパイルして、特定のパーティションILP_IMPROVEと正確なソルバーILP_EXACTを改善します。または、これらのオプションを./compile_withmake.shに渡すこともできます。
./compile_withcmake -DUSE_ILP=Onまた、64ビットのエッジをサポートするオプションも提供します。これを使用するには、option -d64bitmode = onでkahipをコンパイルします。
最後に、私たちは並べ替えの決定論のオプションを提供します。たとえば、同じシードを持つ2つの実行があなたに同じ結果をもたらします。ただし、初期のパーティションアルゴリズムは洗練されたミームアルゴリズムを使用せず、初期パーティションを計算するためのマルチレベルアルゴリズムのみを使用するため、このオプションはパーティションの品質を低下させることができることに注意してください。このオプションをツールとして使用する場合にのみ使用してください。このオプションを使用しないでください。このオプションを使用するには、実行します
./compile_withcmake -DDETERMINISTIC_PARHIP=Onグラフ形式の説明(および他のすべてのプログラムの広範な説明)については、マニュアルをご覧ください。ここで簡単な例を示します。
これらのプログラムと構成は、グラフを取り、多かれ少なかれ順番に分割します。ここには、KaffpaとKaffpae(進化の枠組み)とその構成をリストします。一般に、構成は、Memetic Algorithmを使用してソリューション品質に多くの時間を投資できるようなものです。 MPIを使用して、Memetic Algorithmを並行して実行することもできます。一般に、投資する時間とリソースが多ければ多いほど、パーティションの品質が向上します。トレードオフがたくさんあります。アプリケーションに最適なことがわからない場合はお問い合わせください。アルゴリズムの説明については、マニュアルにリストした参照を見てください。
| 使用事例 | 入力 | プログラム |
|---|---|---|
| グラフ形式 | graph_checker | |
| パーティションを評価します | 評価者 | |
| 高速パーティション | メッシュ | kaffpa preconfigurationは速く設定されています |
| 良い分割 | メッシュ | kaffpa preconfiguration set in eco |
| 非常に良い分割 | メッシュ | Kaffpa Preconfigurationは強く設定されています |
| 最高品質 | メッシュ | Kaffpae、Mpirunを使用して、大きな時間制限 |
| 高速パーティション | 社交 | fsocialに設定されたKaffpa preconfiguration |
| 良い分割 | 社交 | Kaffpa PreconfigurationはeSocialに設定されています |
| 非常に良い分割 | 社交 | kaffpa preconfigurationはssocialに設定されています |
| 最高品質 | 社交 | Kaffpae、Mpirun、大きな時間制限、事前設定Ssocialを使用します |
| さらに高品質 | kaffpae、mpirunを使用し、大きな時間制限、オプションを使用します-MH_ENABLE_TABU_SEARCH、-MH_ENABLE_KABAPE |
./deploy/graph_checker ./examples/rgg_n_2_15_s0.graph ./deploy/kaffpa ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=strong mpirun -n 24 ./deploy/kaffpaE ./examples/rgg_n_2_15_s0.graph --k 4 --time_limit=3600 --mh_enable_tabu_search --mh_enable_kabapE プロジェクトの大部分は、Webグラフやソーシャルネットワークなどの階層的クラスター構造を持つネットワーク向けに設計された分散メモリ並列アルゴリズムです。残念ながら、以前の並列グラフパーティショナーは、より通常のメッシュのようなネットワーク向けに開発されたもので、複雑なネットワークではうまく機能しません。ここでは、もともとグラフクラスタリング用に開発されたラベル伝播手法を並列化および適応させることにより、この問題に対処します。サイズの制約を導入することにより、ラベルの伝播は、マルチレベルグラフパーティションの粗大化と改良段階の両方に適用されます。このようにして、多くの複雑なネットワークに存在する階層クラスター構造を活用します。非常に並行して進化的アルゴリズムを最も粗いグラフに適用することにより、非常に高品質を獲得します。結果のシステムはどちらもよりスケーラブルであり、ParmetisやPt-Scotchなどの最先端のシステムよりも高い品質を達成します。
分散メモリパラレルアルゴリズムは、バイナリファイルと標準のMetisグラフ形式ファイルを読み取ることができます。一般に、バイナリファイルは、並列アプリケーションでテキストファイルを読み取るよりもはるかにスケーラブルです。ここに行く方法は、Metisファイルを最初にバイナリファイル(.bgf)に変換し、次にこれをロードすることです。
| 使用事例 | プログラム |
|---|---|
| 並列パーティション | Parhip、graph2binary、graph2binary_external、ツールボックス |
| 分散メモリの平行、メッシュ | preconfigs ecomesh、fastmesh、ultrafastmeshとの並べ替え |
| 分散メモリパラレル、ソーシャル | ecosocial、fastsocial、ultrafastsocialのpre prepigsとの親子 |
| メチをバイナリに変換します | graph2binary、graph2binary_external |
| パーティションを評価して変換します | ツールボックス |
./deploy/graph2binary examples/rgg_n_2_15_s0.graph examples/rgg_n_2_15_s0.bgf mpirun -n 24 ./deploy/parhip ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=fastmesh mpirun -n 24 ./deploy/parhip ./examples/rgg_n_2_15_s0.bgf --k 4 --preconfiguration=fastmeshノードセパレーターの問題は、グラフのノードセットを3セットA、B、およびSの削除を分割するように要求します。これにより、Sの削除がAとBが切断されます。マルチレベルフレームワーク内でフローベースのローカライズされたローカル検索アルゴリズムを使用して、ノードセパレータを計算します。 Kahipは、ノードセパレーターを計算することもできます。標準のノードセパレーター(2ウェイ)でこれを行うことができますが、K-wayノードセパレーターを計算することもできます。
| 使用事例 | プログラム |
|---|---|
| 2ウェイセパレーター | node_separator |
| Kwayセパレーター | Kaffpaを使用してKパーティションを作成し、Partition_to_vertex_separatorを作成してセパレーターを作成します |
./deploy/node_separator examples/rgg_n_2_15_s0.graphマトリックスをスパースグラフとして解釈し、いわゆるフィルインを最小限に抑えるノード順序を計算することにより、因数分解などのアプリケーションを大幅にスパースマトリックスで大幅に増やすことができます。ネストされた解剖の前に、新しいデータ削減ルールと既存のデータ削減ルールの両方を徹底的に適用することにより、品質が向上し、同時にさまざまなインスタンスで実行時間が大幅に改善されます。 Metisがインストールされている場合、ビルドスクリプトはFAST_NODE_ORDERINGプログラムもコンパイルします。これは、メティスを実行する前に削減を実行して注文を計算します。プログラムはライブラリからも利用できます。
| 使用事例 | プログラム |
|---|---|
| ノード順序付け | node_ordering(異なる先入観を伴う) |
| 高速ノード注文 | fast_node_ordering |
./deploy/node_ordering examples/rgg_n_2_15_s0.graph ./deploy/fast_node_ordering examples/rgg_n_2_15_s0.graphエッジ中心の分散計算は、大規模なネットワーク上のThink-A-vertexアルゴリズムの欠点を改善するための最近の手法として登場しました。このモデルの並列性を高めるために、エッジパーティション化 - エッジをほぼ等しくサイズのブロックに分割する - は、従来の(ノードベースの)グラフパーティションの代替として登場しました。高品質のエッジパーティションをスケーラブルな方法で生成する高速並列およびシーケンシャルのスプリットアンドコネクトグラフ構造アルゴリズムを含めます。私たちのテクニックは、数十億のエッジを備えたネットワークに拡大し、数千のPEで効率的に動作します。
| 使用事例 | プログラム |
|---|---|
| エッジパーティション化 | edge_partitioning、distributed_edge_partitioning |
./deploy/edge_partitioning ./examples/rgg_n_2_15_s0.graph --k 4 --preconfiguration=fast mpirun -n 4 ./deploy/distributed_edge_partitioning ./examples/rgg_n_2_15_s0.bgf --k 4 --preconfiguration=fastsocial コミュニケーションとトポロジ認識プロセスマッピングは、大規模な分散メモリシステム上の既知の通信パターンを備えた並行アプリケーションでの通信時間を短縮する強力なアプローチです。問題に2次割り当ての問題(QAP)として対処し、プロセスの初期マッピングを構築するアルゴリズムと、マッピングをさらに改善するための高速ローカル検索アルゴリズムを含めます。スパース通信パターンや階層的に組織化された通信システムなどのアプリケーションや最新のスーパーコンピューターシステムに通常保持される仮定を活用することにより、これらの特別なQAPの非常に強力なアルゴリズムに到達します。当社のマルチレベル構造アルゴリズムは、完全にバランスの取れたグラフパーティション化手法を採用し、特定の通信システム階層を過度に活用しています。 v3.0以降、指定された階層に沿って入力ネットワークを直接分割するグローバルマルチセクションアルゴリズムを含めて、N-to-1マッピングを取得し、その後1対1マッピングアルゴリズムを呼び出してマッピングをさらに改善します。
| 使用事例 | プログラム |
|---|---|
| プロセッサネットワークへのマッピング | kaffpa、およびrepでenable_mappingオプションを使用します。パースコンフィグ |
| グローバルマルチセクション | respとglobal_multisection。パースコンフィグ |
./deploy/kaffpa examples/rgg_n_2_15_s0.graph --k 256 --preconfiguration=eco --enable_mapping --hierarchy_parameter_string=4:8:8 --distance_parameter_string=1:10:100 ./deploy/global_multisection examples/rgg_n_2_15_s0.graph --preconfiguration=eco --hierarchy_parameter_string=4:3:3:3 --distance_parameter_string=1:10:100:200特定のパーティションを改善するために、ILPとILPを提供します。整数線形プログラミングを採用することにより、複数のローカル検索の組み合わせ問題の近隣を拡張します。これにより、さらに複雑な組み合わせを見つけることができるため、ソリューションをさらに改善できます。ただし、箱から出して、問題のILPは通常、大きな入力にスケーリングしません。特に、グラフパーティションの問題には非常に大量の対称性があるため、グラフのパーティションを考えると、ブロックIDの各順列は同じ目的とバランスを持つソリューションを与えます。モデルと呼ばれるはるかに小さなグラフを定義し、整数線形プログラムによってモデルのグラフパーティション問題を最適性に解決します。他のことに加えて、このモデルにより、対称性破壊を使用できます。これにより、はるかに大きな入力にスケーリングできます。これらのプログラムをコンパイルするには、上記のビルドプロセスでCmakeをcmake ../ -dcmake_build_type = release -duse_ilp = onまたはrun ./compile_withcmake -duse_ilp = onを実行する必要があります。
| 使用事例 | プログラム |
|---|---|
| 正確なソルバー | ILP_EXACT |
| ILPによる改善 | ILP_IMPROVE |
./deploy/ilp_improve ./examples/rgg_n_2_15_s0.graph --k 4 --input_partition=tmppartition4 ./deploy/ilp_exact ./examples/example_weighted.graph --k 3Kahipは、アルゴリズムをコードに直接リンクするライブラリとインターフェイスも提供しています。マニュアルのインターフェイスの詳細について説明します。以下に、Kahip Libraryをリンクするプログラムの例をリストします。この例は、MISC/example_library_call/にもあります。
# include < iostream >
# include < sstream >
# include " kaHIP_interface.h "
int main ( int argn, char **argv) {
std::cout << " partitioning graph from the manual " << std::endl;
int n = 5 ;
int * xadj = new int [ 6 ];
xadj[ 0 ] = 0 ; xadj[ 1 ] = 2 ; xadj[ 2 ] = 5 ; xadj[ 3 ] = 7 ; xadj[ 4 ] = 9 ; xadj[ 5 ] = 12 ;
int * adjncy = new int [ 12 ];
adjncy[ 0 ] = 1 ; adjncy[ 1 ] = 4 ; adjncy[ 2 ] = 0 ; adjncy[ 3 ] = 2 ; adjncy[ 4 ] = 4 ; adjncy[ 5 ] = 1 ;
adjncy[ 6 ] = 3 ; adjncy[ 7 ] = 2 ; adjncy[ 8 ] = 4 ; adjncy[ 9 ] = 0 ; adjncy[ 10 ] = 1 ; adjncy[ 11 ] = 3 ;
double imbalance = 0.03 ;
int * part = new int [n];
int edge_cut = 0 ;
int nparts = 2 ;
int * vwgt = NULL ;
int * adjcwgt = NULL ;
kaffpa (&n, vwgt, xadj, adjcwgt, adjncy, &nparts, &imbalance, false , 0 , ECO, & edge_cut, part);
std::cout << " edge cut " << edge_cut << std::endl;
}KahipはPythonでも使用できます。 Python FirstRunで使用したい場合
python3 -m pip install pybind11
その後、実行します
./compile_withcmake.sh BUILDPYTHONMODULEPythonモデルを構築します。これにより、Pythonモジュールが構築され、callkahipfrompython.pyの例を展開フォルダーに掲載します。これは、デプロイフォルダーで以下を入力することで実行できます。
python3 callkahipfrompython.py 予備サポートのみを提供することに注意してください。つまり、Compile_WithCmakeファイル内のPythonにパスを変更する必要がある場合があります。例を以下に示します。
import kahip ;
#build adjacency array representation of the graph
xadj = [ 0 , 2 , 5 , 7 , 9 , 12 ];
adjncy = [ 1 , 4 , 0 , 2 , 4 , 1 , 3 , 2 , 4 , 0 , 1 , 3 ];
vwgt = [ 1 , 1 , 1 , 1 , 1 ]
adjcwgt = [ 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ]
supress_output = 0
imbalance = 0.03
nblocks = 2
seed = 0
# set mode
#const int FAST = 0;
#const int ECO = 1;
#const int STRONG = 2;
#const int FASTSOCIAL = 3;
#const int ECOSOCIAL = 4;
#const int STRONGSOCIAL = 5;
mode = 0
edgecut , blocks = kahip . kaffpa ( vwgt , xadj , adjcwgt ,
adjncy , nblocks , imbalance ,
supress_output , seed , mode )
print ( edgecut )
print ( blocks )このプログラムは、MITライセンスに基づいてライセンスされています。私たちのアルゴリズムを使用して結果を公開する場合は、次の論文を引用して、私たちの作品を認めてください。
@inproceedings{sandersschulz2013,
AUTHOR = {Sanders, Peter and Schulz, Christian},
TITLE = {{Think Locally, Act Globally: Highly Balanced Graph Partitioning}},
BOOKTITLE = {Proceedings of the 12th International Symposium on Experimental Algorithms (SEA'13)},
SERIES = {LNCS},
PUBLISHER = {Springer},
YEAR = {2013},
VOLUME = {7933},
PAGES = {164--175}
}
並行パーティショナーディアップを使用する場合は、次の論文も引用してください。
@inproceedings{meyerhenkesandersschulz2017,
AUTHOR = {Meyerhenke, Henning and Sanders, Peter and Schulz, Christian},
TITLE = {{Parallel Graph Partitioning for Complex Networks}},
JOURNAL = {IEEE Transactions on Parallel and Distributed Systems (TPDS)},
VOLUME = {28},
NUMBER = {9},
PAGES = {2625--2638},
YEAR = {2017}
}
マッピングアルゴリズムを使用する場合は、次の論文も引用してください。
@inproceedings{schulztraeff2017,
AUTHOR = {Schulz, Christian and Träff, Jesper Larsson},
TITLE = {{Better Process Mapping and Sparse Quadratic Assignment}},
BOOKTITLE = {Proceedings of the 16th International Symposium on Experimental Algorithms (SEA'17)},
PUBLISHER = {Schloss Dagstuhl - Leibniz-Zentrum fuer Informatik},
VOLUME = {75},
SERIES = {LIPIcs},
PAGES = {4:1--4:15},
YEAR = {2017}
}
エッジパーティションアルゴリズムを使用する場合は、次の論文も引用してください。
@inproceedings{edgepartitioning2019,
AUTHOR = {Schlag, Sebastian and Schulz, Christian and Seemaier, Daniel and Strash, Darren},
TITLE = {{Scalable Edge Partitioning}},
BOOKTITLE = {Proceedings of the 21th Workshop on Algorithm Engineering and Experimentation (ALENEX)},
PUBLISHER = {SIAM},
PAGES = {211--225},
YEAR = {2019}
}
ノード注文アルゴリズムを使用する場合は、次の論文も引用してください。
@article{DBLP:journals/corr/abs-2004-11315,
author = {Wolfgang Ost and
Christian Schulz and
Darren Strash},
title = {Engineering Data Reduction for Nested Dissection},
journal = {CoRR},
volume = {abs/2004.11315},
year = {2020},
url = {https://arxiv.org/abs/2004.11315},
archivePrefix = {arXiv},
eprint = {2004.11315},
timestamp = {Tue, 28 Apr 2020 16:10:02 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2004-11315.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
ILPアルゴリズムを使用してパーティションを改善する場合は、次の論文も引用してください。
@inproceedings{DBLP:conf/wea/HenzingerN018,
author = {Alexandra Henzinger and
Alexander Noe and
Christian Schulz},
title = {ILP-based Local Search for Graph Partitioning},
booktitle = {17th International Symposium on Experimental Algorithms, {SEA} 2018},
pages = {4:1--4:15},
year = {2018},
url = {https://doi.org/10.4230/LIPIcs.SEA.2018.4},
doi = {10.4230/LIPIcs.SEA.2018.4},
series = {LIPIcs},
volume = {103},
publisher = {Schloss Dagstuhl - Leibniz-Zentrum f{"{u}}r Informatik}
}
Yaroslav Akhremtsev
Adil Chhabra
マルセロ・フォンセカ・ファラジ
ローランドグランツ
アレクサンドラ・ヘンツィンガー
デニス・ルクセン
ヘニング・マイヤーヘンケ
アレクサンダー・ノー
マーク・オレセン
ララオスト
イリヤ・サフロ
ピーター・サンダース
Hayk Sargsyan
セバスチャン・シュラグ
クリスチャンシュルツ(メンテナー)
ダニエルシーマー
ダレン・ストラッシュ
Jesper LarssonTräff


