gtsystem
1.0.0
แพ็คเกจ Python รหัสต่ำสำหรับการสร้างแอปพลิเคชัน Genai อย่างรวดเร็ว
Genai Techne อยู่ในภารกิจที่จะช่วยให้องค์กรและมืออาชีพเก่งในงานฝีมือของ Generative AI ตรวจสอบ Genai Techne Subthack ที่คุณสามารถอ่านเพิ่มเติมเกี่ยวกับภารกิจของเราอ่านเอกสาร GTSYSTEM เรียนรู้จากแบบฝึกหัดทีละขั้นตอนและมีอิทธิพลต่อแผนงานของ GTSYSTEM สำหรับกรณีการใช้งานของคุณ
เริ่มต้นใช้งานแพ็คเกจ gtsystem ทำตามขั้นตอนเหล่านี้
ขั้นตอนที่ 1. ติดตั้งแพ็คเกจ GTSYSTEM โดยใช้ pip install gtsystem
ขั้นตอนที่ 2 เปิดสมุดบันทึก Jupyter แล้วลองตัวอย่างนี้
from gtsystem import openai , bedrock , anthropic , ollama , instrument
prompt = 'How many faces does a tetrahedron have?'
openai . text ( prompt )
bedrock . text ( prompt )
anthropic . text ( prompt )
ollama . text ( prompt )
instrument . metrics . stats ()หมายเหตุ: ในการติดตั้งการอ้างอิงและตั้งค่า API ของผู้ขายแต่ละรายคุณสามารถอ่านต่อได้ที่นี่
แหล่งแพ็คเกจ gtsystem มีอยู่ในที่เก็บนี้ใน GitHub
คุณสามารถอ่านเพิ่มเติมเกี่ยวกับวิสัยทัศน์ที่อยู่เบื้องหลัง GTSYSTEM บนโพสต์ Substack Genai
คุณสามารถเรียนรู้ gtsystem API โดยทำตามตัวอย่างสมุดบันทึกที่รวมอยู่ใน Repo gtsystem ตัวอย่างนี้มีการบันทึกไว้ใน Genai Techne Sody
รีวิว Model Leadyboard: ใช้ 00-leaderboard.ipynb สำหรับการตรวจสอบ Model Leadyboard, ตัวกรองโดยการจัดอันดับผู้ขายโมเดลในการตัดสินใจว่าจะสำรวจ
ประเมินโมเดลโดยใช้รหัสบรรทัดเดียว: อ้างอิง 01-evaluate.ipynb สำหรับการประเมินผลคำสั่งเดียวในหลายรุ่นรวมถึง OpenAI GPT, Bedrock โฮสต์ Claude หรือ Llama
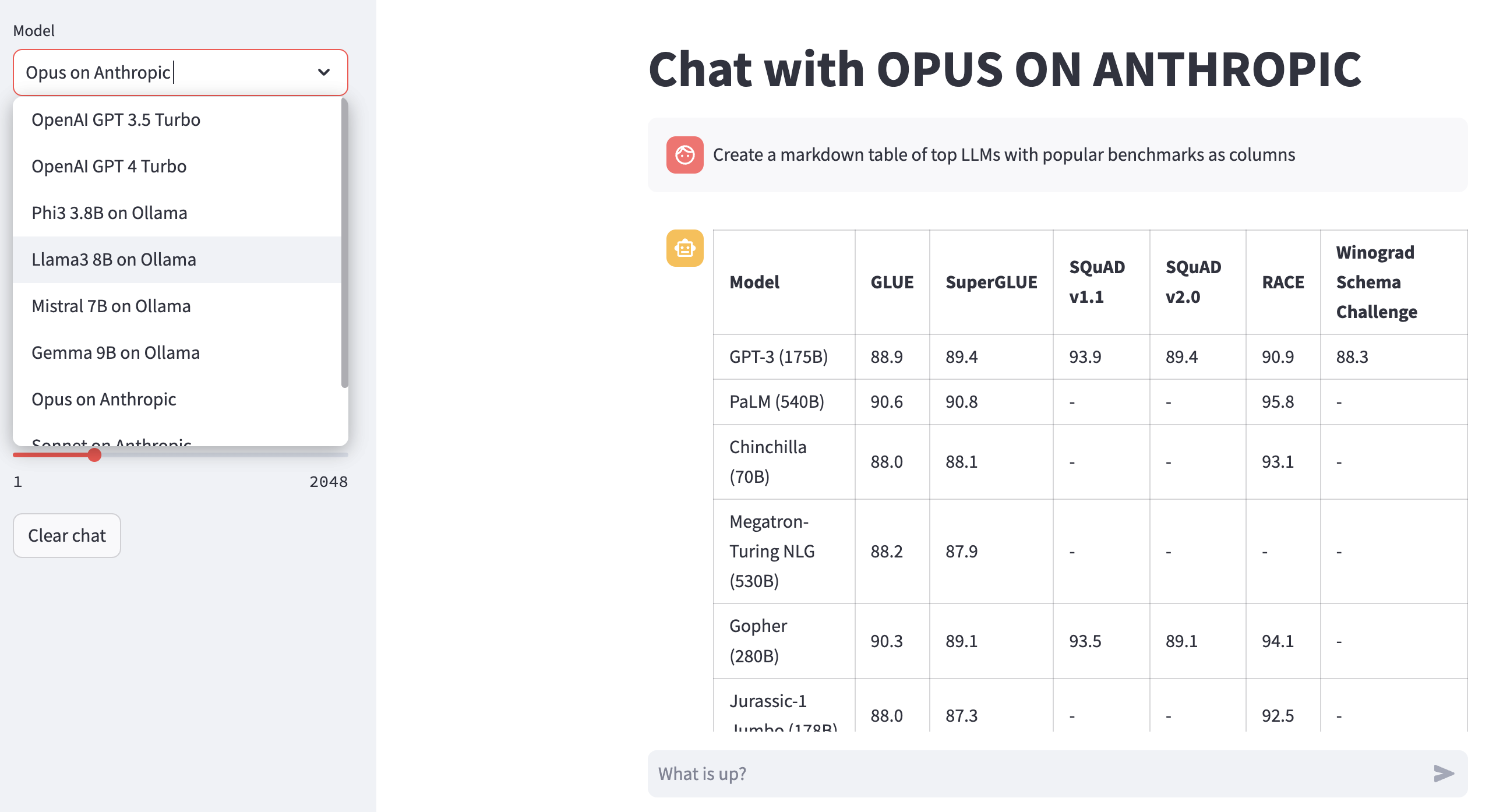
Render LLM Responses: ใช้ 02-render.ipynb สำหรับการแสดงผลที่จัดรูปแบบดีของการตอบสนองแบบจำลองรวมถึงตาราง markdown
งานประเมินผลโหลดจาก Excel: ลอง 03-tasks.ipynb สำหรับงานการประเมินอัตโนมัติ - ค้นหา, รายการ, โหลดพรอมต์โดยงานรวมถึงค่าพารามิเตอร์ที่ดีที่สุดสำหรับอุณหภูมิและ Topp
ความเร็วและขนาดของเครื่องมือ (ค่าใช้จ่าย) ของการตอบสนอง: นำกลับมาใช้ใหม่ 04-instrument.ipynb สำหรับการใช้เครื่องมือและเปรียบเทียบหลายรุ่นในเวลาแฝงและขนาดของการตอบสนอง
คุณภาพของการตอบสนองมาตรฐาน: ใช้ 05-benchmark.ipynb สำหรับการเปรียบเทียบคุณภาพการตอบสนองอัตโนมัติจากรุ่นเช่น Llama และ Claude โดยใช้ GPT-4 เป็นตัวประเมิน LLM
Run Models บนแล็ปท็อปของคุณ: รับ 06-ollama.ipynb เพื่อเรียกใช้โมเดลเช่น Mistral, Llama และ Codellama ในท้องถิ่นบนแล็ปท็อปของคุณและเปรียบเทียบโมเดลที่โฮสต์บนคลาวด์หรือ API รุ่นที่เป็นกรรมสิทธิ์
ตัวอย่างโค้ดต่ำ: ตรวจสอบง่าย 07-low-code-sample.ipynb เพื่อชื่นชมว่าสามารถทำได้มากแค่ไหนด้วย APIs GTSYSTEM ที่เรียบง่าย
เปลี่ยนจากต้นแบบไปจนถึงการผลิต: เริ่มต้นด้วย 08-prototype-to-production.ipynb ไปจากการสร้างต้นแบบโดยใช้รุ่นที่ดีที่สุดจากนั้นสำรวจรุ่นท้องถิ่นบนแล็ปท็อปในที่สุดเปรียบเทียบผู้ขายที่เร็วที่สุดเช่น Groq ในเวิร์กโฟลว์ไร้รอยต่อ
ภาพการแชทบนข้อเท็จจริง: สำรวจ 09-chat-bedrock.ipynb สำหรับการแชทด้วยภาพโดยใช้รุ่นที่เป็นโฮสต์ของ Bedrock
ภาพแชทบนมานุษยวิทยา: สำรวจ 10-chat-anthropic.ipynb สำหรับการแชทด้วยภาพโดยใช้โมเดลโฮสต์มานุษยวิทยา
ภาพแชทบน OpenAI: สำรวจ 11-chat-openai.ipynb สำหรับการแชทด้วยภาพโดยใช้ OpenAI GPT4-Turbo
คุณสามารถติดตั้งการพึ่งพาต่อไปนี้เพื่อทำงานกับ gtsystem ตามความต้องการของคุณ เริ่มต้นด้วย requirements.txt ของเรา txt หรือสร้างของคุณเอง จากนั้นเรียกใช้ pip install -r requirements.txt ภายในสภาพแวดล้อมของคุณ
# Python capabilities
pandas
markdown
openpyxl
# Jupyter notebook
jupyterlab
ipywidgets
# AWS for Bedrock managed models
boto3
awscli
botocore
# OpenAI for GPT models
openai
# Anthropic models
anthropic
# Ollama for LLMs running on your laptop
ollama
# Groq for open models on fast Groq LPUs
groq
หากต้องการใช้โมเดลโฮสต์ของ Amazon Bedrock เช่น Llama และ Claude ทำตามขั้นตอนเหล่านี้
ขั้นตอนที่ 1. ล็อกอินไปยังคอนโซล AWS> เรียกใช้ข้อมูลประจำตัวและการจัดการการเข้าถึง (IAM)> สร้างการเข้าถึงผู้ใช้สำหรับอินเทอร์เฟซบรรทัดคำสั่ง (CLI) อ่านเอกสารเกี่ยวกับข้อเท็จจริงสำหรับรายละเอียดเพิ่มเติม
ขั้นตอนที่ 2. ติดตั้ง AWS CLI> เรียกใช้ aws configure ในเทอร์มินัล> เพิ่มข้อมูลรับรองจากขั้นตอนที่ 1
หากต้องการใช้ Ollama ให้ LLMs ในแล็ปท็อปของคุณทำตามขั้นตอนเหล่านี้
ขั้นตอนที่ 1. ดาวน์โหลด Ollama หมายเหตุข้อกำหนดของหน่วยความจำสำหรับแต่ละรุ่น โดยทั่วไปรุ่น 7B ต้องการ RAM อย่างน้อย 8GB โดยทั่วไปรุ่น 13B ต้องการ RAM อย่างน้อย 16GB โดยทั่วไปรุ่น 70B ต้องการ RAM อย่างน้อย 64GB
ขั้นตอนที่ 2. ค้นหารุ่น Ollama Library> เรียกใช้คำสั่ง ollama pull <model> ในเทอร์มินัลเพื่อดาวน์โหลดรุ่น ปัจจุบัน GTSYSTH รองรับรุ่นยอดนิยมเช่น LLAMA2, Mistral และ LLAVA
หากต้องการใช้โมเดล OpenAI ทำตามขั้นตอนเหล่านี้
ขั้นตอนที่ 1. การลงทะเบียนสำหรับการเข้าถึง OpenAI API และรับรหัส API
ขั้นตอนที่ 2. เพิ่มคีย์ OpenAI API ลงใน ~/.zshrc หรือ ~/.bashrc โดยใช้ export OPENAI_API_KEY="your-key-here"
หากต้องการใช้โมเดลแบบเปิดบน Fast Groq LPUs ทำตามขั้นตอนเหล่านี้
ขั้นตอนที่ 1. การลงทะเบียนสำหรับการเข้าถึง GROQ API และรับรหัส API
ขั้นตอนที่ 2. เพิ่มคีย์ GROQ API ลงใน ~/.zshrc หรือ ~/.bashrc โดยใช้ export GROQ_API_KEY="your-key-here"
หากคุณยังใหม่กับ Python นี่คือวิธีที่คุณสามารถเริ่มต้นได้ตั้งแต่เริ่มต้น
ก่อนอื่นคุณควรใช้งูหลามล่าสุดในระบบของคุณด้วย Python Package Manager ที่อัพเกรดเป็นล่าสุด
python --version
# should return Python 3.10.x or higher as on Jan'23
pip --version
# should return pip 22.3.x or higher as on Jan'23 ทำตามคำแนะนำนี้สำหรับ Mac OS X หากคุณไม่มี Python ล่าสุด หากการติดตั้ง Python เวอร์ชันเฉพาะสำหรับการจัดการการพึ่งพาให้ทำตามเธรดนี้เพื่อติดตั้งโดยใช้ตัวจัดการเวอร์ชัน pyenv Python หากจำเป็นต้องอัปเกรด PIP เป็นล่าสุดโดยใช้คำสั่งต่อไปนี้
pip install --user --upgrade pipตอนนี้เราจะสร้างสภาพแวดล้อมเสมือนจริงสำหรับการตั้งค่า MLOPS ของเราเพื่อให้การพึ่งพาของเราแยกได้และไม่ขัดแย้งกับแพ็คเกจที่ติดตั้งระบบ เราจะทำตามคำแนะนำนี้สำหรับการสร้างและจัดการสภาพแวดล้อมเสมือนจริง การเปลี่ยนแปลงครั้งแรกเป็นไดเรกทอรีที่เราจะพัฒนาแอปพลิเคชันของเรา
python -m venv envหากคุณเรียกใช้ LS Env คุณจะเห็นโฟลเดอร์และไฟล์ที่สร้างขึ้นต่อไปนี้
bin include lib pyvenv.cfgตอนนี้เราสามารถเปิดใช้งานสภาพแวดล้อมเสมือนจริงของเราได้เช่นนั้น คุณจะสังเกตเห็นว่าไดเรกทอรีการพัฒนานำหน้าด้วย (env) เพื่อระบุว่าตอนนี้คุณกำลังทำงานในสภาพแวดล้อมเสมือนจริง
. env/bin/activateคุณสามารถยืนยันได้ว่าคุณไม่ได้ทำงานในสภาพแวดล้อมเสมือนจริงด้วยงูหลามของตัวเอง
which python
# # should return /Users/.../env/bin/pythonเพื่อออกจากสภาพแวดล้อมเสมือนจริงโดยใช้คำสั่งปิดใช้งาน กลับเข้ามาอีกครั้งโดยใช้คำสั่งเดียวกับก่อนหน้านี้


