gtsystem
1.0.0
Ein Python -Paket mit niedrigem Code zum schnellen Erstellen von Genai -Anwendungen
Genai Techne ist auf der Mission, Enterprise und Profis dabei zu helfen, sich im Handwerk der generativen KI zu übertreffen. Schauen Sie sich den Genai Techne-Substack an, bei dem Sie mehr über unsere Mission lesen, GTsystem-Dokumentation lesen, aus Schritt-für-Schritt-Tutorials erfahren und die Roadmap von GTSystem für Ihre Anwendungsfälle beeinflussen können.
Das gtsystem -Paket erschließe diese Schritte aus.
Schritt 1. Installieren Sie das GTsystem -Paket mit pip install gtsystem
Schritt 2. Öffnen Sie ein Jupyter -Notizbuch und probieren Sie dieses Beispiel aus.
from gtsystem import openai , bedrock , anthropic , ollama , instrument
prompt = 'How many faces does a tetrahedron have?'
openai . text ( prompt )
bedrock . text ( prompt )
anthropic . text ( prompt )
ollama . text ( prompt )
instrument . metrics . stats ()Hinweis: Um die Abhängigkeiten zu installieren und die einzelnen Anbieter -APIs einzurichten, können Sie hier weiter lesen.
Die gtsystem -Paketquelle ist in diesem Repository auf GitHub verfügbar.
Sie können mehr über die Vision hinter GTSystem auf dem Genai Techne -Substantestposten lesen.
Sie können gtsystem -API lernen, indem Sie den im gtsystem -Repo enthaltenen Notebook -Beispiele entlang folgen. Diese Proben sind auf dem Genai Techne -Substack dokumentiert.
Bewertungsmodell-Rangliste: Verwenden Sie 00-leaderboard.ipynb zur Überprüfung der Modell- und Filterbohrung, Filter durch Ranking, Anbieter und Modelle, um zu entscheiden, welche erforschen soll.
Bewerten Sie Modelle unter Verwendung einer Codezeile: Siehe 01-evaluate.ipynb für einzelne Anweisungen Eingabeaufforderung in mehreren Modellen, einschließlich OpenAI GPT, Bedrock, Hosted Claude oder LLAMA.
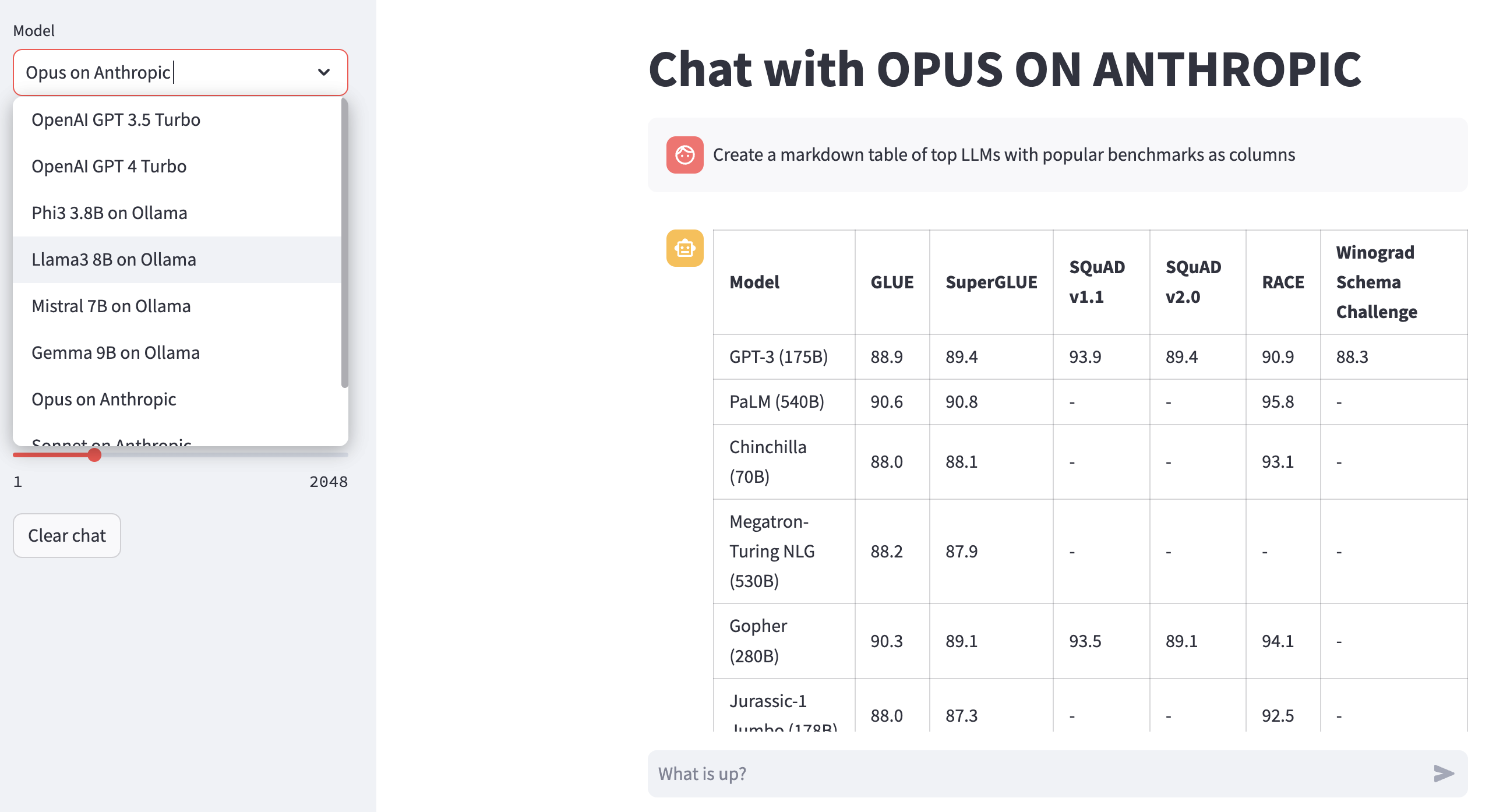
Render LLM-Antworten: Verwenden Sie 02-render.ipynb für gut formatierte Wiedergabe der Modellantworten einschließlich Markdown-Tabellen.
Lastbewertungsaufgaben von Excel: Versuchen Sie es mit 03-tasks.ipynb zur Automatisierung von Bewertungsaufgaben - Finden Sie, listen Sie die Eingabeaufforderungen für Temperaturen und die optimalen Parameterwerte für Temperatur und TOPP.
Instrumentengeschwindigkeit und -größe (Kosten) der Antwort: Wiederverwendung 04-instrument.ipynb zum Instrumentieren und Vergleich mehrerer Modelle über die Latenz und Größe der Antwort.
Benchmark-Qualität der Antwort: Verwenden Sie 05-benchmark.ipynb für automatisierte Benchmarking-Qualität von Antworten von Modellen wie Lama und Claude unter Verwendung von GPT-4 als LLM-Bewerter.
Führen Sie Modelle auf Ihrem Laptop aus: Holen Sie sich 06-ollama.ipynb um Modelle wie Mistral, Llama und Codellama lokal auf Ihrem Laptop auszuführen, und vergleichen Modelle, die auf Cloud- oder proprietären Modell-APIs gehostet werden.
Probe mit niedrigem Code: Schauen Sie sich die einfache 07-low-code-sample.ipynb an.
Wechseln Sie von Prototypen zur Produktion: Beginnen Sie mit 08-prototype-to-production.ipynb
Visueller Chat auf dem Grundgestein: Entdecken Sie 09-chat-bedrock.ipynb für visuelle Chat mit den mit Bedrock gehosteten Modellen.
Visueller Chat über Anthropic: Erforschen Sie 10-chat-anthropic.ipynb für visuellen Chat mithilfe anthropisch gehosteter Modelle.
Visueller Chat auf OpenAI: Entdecken Sie 11-chat-openai.ipynb für visuellen Chat mit OpenAI GPT4-Turbo.
Sie können die folgenden Abhängigkeiten installieren, um mit gtsystem basierend auf Ihren Anforderungen zu arbeiten. Beginnen Sie mit unseren requirements.txt oder erstellen Sie Ihre eigenen. Führen Sie dann pip install -r requirements.txt in Ihrer Umgebung aus.
# Python capabilities
pandas
markdown
openpyxl
# Jupyter notebook
jupyterlab
ipywidgets
# AWS for Bedrock managed models
boto3
awscli
botocore
# OpenAI for GPT models
openai
# Anthropic models
anthropic
# Ollama for LLMs running on your laptop
ollama
# Groq for open models on fast Groq LPUs
groq
Um das Amazon -Grundgestein zu verwenden, verfolgen Sie Modelle wie Lama und Claude diesen Schritten.
Schritt 1. Anmelden Sie sich bei AWS Console> IAM (IAM) Identität und Access Management (IAM)> Erstellen Sie einen Benutzer für die Befehlszeileninterface (CLI). Lesen Sie die Grundgesteinsdokumentation für weitere Details.
Schritt 2. AWS CLI> aws configure ausführen in Terminal> Anmeldeinformationen aus Schritt 1 hinzufügen.
Die Verwendung von OLLAMA, die LLMs lokal auf Ihrem Laptop zur Verfügung gestellt werden, befolgen Sie diese Schritte.
Schritt 1. Download OLLAMA -HINWEIS Die Speicheranforderungen für jedes Modell. 7B -Modelle erfordern im Allgemeinen mindestens 8 GB RAM. 13B -Modelle erfordern im Allgemeinen mindestens 16 GB RAM. 70B -Modelle erfordern im Allgemeinen mindestens 64 GB RAM
Schritt 2. Finden Sie Modell Ollama Library> Befehl ollama pull <model> im Terminal zum Herunterladen des Modells. Derzeit unterstützt GTsystem beliebte Modelle wie Lama2, Mistral und Llava.
Um OpenAI -Modelle zu verwenden, befolgen Sie diese Schritte.
Schritt 1. Anmelden Sie den OpenAI -API -Zugriff und erhalten Sie den API -Schlüssel.
Schritt 2. OpenAI-API-Schlüssel zu Ihrem ~/.zshrc oder ~/.bashrc mit export OPENAI_API_KEY="your-key-here" hinzufügen
Um offene Modelle für schnelle LPUs zu verwenden, folgen Sie diesen Schritten aus.
Schritt 1. Anmelden Sie sich für den API -Zugriff auf den GROQ -API und erhalten Sie die API -Taste.
Schritt 2. Fügen Sie Ihrem ~/.zshrc oder ~/.bashrc mit export GROQ_API_KEY="your-key-here"
Wenn Sie neu in Python sind, können Sie hier von Grund auf anfangen.
Zunächst sollten Sie das neueste Python in Ihrem System ausführen, wobei Python Package Manager auf die neueste Aktion aktualisiert wurde.
python --version
# should return Python 3.10.x or higher as on Jan'23
pip --version
# should return pip 22.3.x or higher as on Jan'23 Befolgen Sie diese Anleitung für Mac OS X, wenn Sie nicht über den neuesten Python verfügen. Wenn Sie die spezifische Version von Python für die Verwaltung von Abhängigkeiten installieren, folgen Sie diesem Thread mithilfe von pyenv Python Version Manager. Bei Bedarf upgrade pip mit dem folgenden Befehl auf die neueste.
pip install --user --upgrade pipWir werden nun eine virtuelle Umgebung für unsere MLOPS -Setup erstellen, damit unsere Abhängigkeiten isoliert sind und nicht mit den Systempaketen in Konflikt stehen. Wir werden diesem Leitfaden zum Erstellen und Verwalten der virtuellen Umgebung folgen. Wechseln Sie zunächst in das Verzeichnis, in dem wir unsere Bewerbung entwickeln.
python -m venv envWenn Sie LS Env ausführen, werden Sie folgende Ordner und Dateien erstellt.
bin include lib pyvenv.cfgJetzt können wir unsere virtuelle Umgebung so aktivieren. Sie werden feststellen, dass das Entwicklungsverzeichnis, das mit der (ENV) vorangestellt ist, um anzuzeigen, dass Sie jetzt in der virtuellen Umgebung laufen.
. env/bin/activateSie können bestätigen, dass Sie nicht mit einer eigenen Python in der virtuellen Umgebung laufen.
which python
# # should return /Users/.../env/bin/pythonUm die virtuelle Umgebung mithilfe des Befehls deaktivieren zu lassen. Nehmen Sie die Verwendung des gleichen Befehls wie früher wieder ein.


