MOFA Video
1.0.0
ใน การประชุมยุโรปเรื่องวิสัยทัศน์คอมพิวเตอร์ (ECCV) 2024
(2024.08.07) เราได้เปิดตัวสคริปต์การอนุมานสำหรับภาพเคลื่อนไหวภาพใบหน้าที่ใช้กุญแจ! โปรดดูที่นี่สำหรับคำแนะนำเพิ่มเติม
(2024.07.15) เราได้เปิดตัวรหัสการฝึกอบรมสำหรับภาพเคลื่อนไหวรูปภาพที่ใช้วิถี! โปรดดูที่นี่สำหรับคำแนะนำเพิ่มเติม
Mofa-Video จะปรากฏใน ECCV 2024! -
เราได้เปิดตัวรหัสการอนุมาน Gradio และจุดตรวจสำหรับการควบคุม ไฮบริด ! โปรดดูที่นี่สำหรับคำแนะนำเพิ่มเติม
ฟรีการสาธิตออนไลน์ผ่านช่องว่าง HuggingFace จะมาเร็ว ๆ นี้!
หากคุณพบว่างานนี้น่าสนใจโปรดอย่าลังเลที่จะให้!
 |  |  |
| วิถี + การควบคุมสถานที่สำคัญ | ||
 |  |  |  |
| การควบคุมวิถี | |||
 |  |  |  |  |
| การควบคุมสถานที่สำคัญ | ||||
เราแนะนำ Mofa-Video ซึ่งเป็นวิธีการที่ออกแบบมาเพื่อปรับการเคลื่อนไหวจากโดเมนที่แตกต่างกันไปยังรูปแบบการแพร่กระจายวิดีโอแช่แข็ง ด้วยการใช้การสร้างการเคลื่อนไหวแบบกระจัดกระจาย (S2D) และการปรับการเคลื่อนไหวแบบไหลออกมา MOFA-Video สามารถทำให้ภาพเดียวมีประสิทธิภาพโดยใช้สัญญาณควบคุมประเภทต่างๆได้อย่างมีประสิทธิภาพรวมถึงวิถีการเคลื่อนที่ลำดับคีย์พอยท์และชุดค่าผสมของพวกเขา
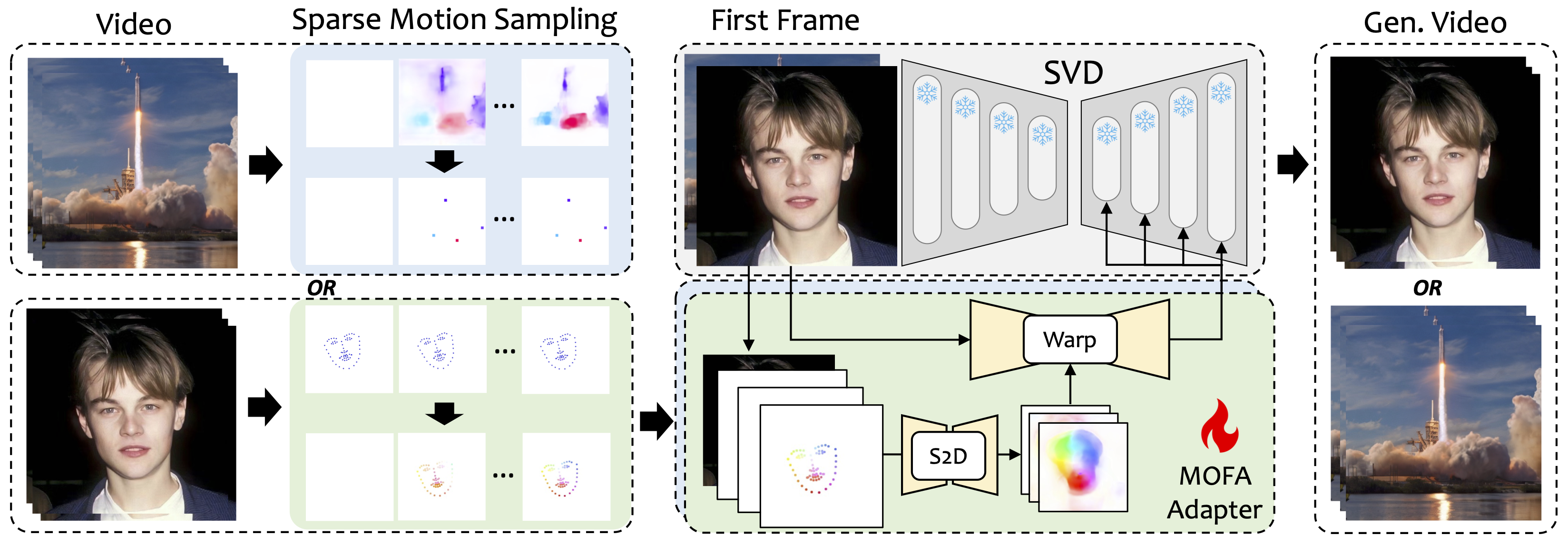
ในระหว่างขั้นตอนการฝึกอบรมเราสร้างสัญญาณการควบคุมที่กระจัดกระจายผ่านการสุ่มตัวอย่างการเคลื่อนไหวแบบเบาบางจากนั้นฝึกอบรม MOFA-adapters ที่แตกต่างกันเพื่อสร้างวิดีโอผ่าน SVD ที่ผ่านการฝึกอบรมมาก่อน ในระหว่างขั้นตอนการอนุมาน MOFA-adapters ที่แตกต่างกันสามารถรวมกันเพื่อควบคุม SVD แช่แข็งร่วมกัน
git clone https://github.com/MyNiuuu/MOFA-Video.git
cd ./MOFA-Video
การสาธิตได้รับการทดสอบในรุ่น CUDA ที่ 11.7
cd ./MOFA-Video-Hybrid
conda create -n mofa python==3.10
conda activate mofa
pip install -r requirements.txt
pip install opencv-python-headless
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
สำคัญ:requirements.txt ควรติดตามอย่างเคร่งครัดเนื่องจากเวอร์ชันอื่นอาจทำให้เกิดข้อผิดพลาด
ดาวน์โหลดจุดตรวจของ CMP จากที่นี่และใส่ลงใน ./MOFA-Video-Hybrid/models/cmp/experiments/semiauto_annot/resnet50_vip+mpii_liteflow/checkpoints mofa-video-hybrid/models/cmp/experiments/Semiauto_annot/resnet50_vip+mpii_liteflow/checkpoints
ดาวน์โหลดโฟลเดอร์ ckpts จาก repo huggingface ซึ่งมีจุดตรวจสอบที่จำเป็นและวางไว้ใต้ ./MOFA-Video-Hybrid mofa-Video-Hybrid คุณสามารถใช้ git lfs เพื่อดาวน์โหลดโฟลเดอร์ ckpts ทั้งหมด :
git lfs จาก https://git-lfs.github.com มันมักจะใช้สำหรับการโคลนที่เก็บด้วยจุดตรวจขนาดใหญ่บน HuggingFacegit clone https://huggingface.co/MyNiuuu/MOFA-Video-Hybrid เพื่อดาวน์โหลดที่เก็บ HuggingFace ที่สมบูรณ์ซึ่งปัจจุบันรวมถึงโฟลเดอร์ ckpts เท่านั้นckpts ไปยังที่เก็บ GitHub หมายเหตุ: หากคุณพบข้อผิดพลาด git: 'lfs' is not a git command บน Linux คุณสามารถลองโซลูชันนี้ที่ทำงานได้ดีสำหรับกรณีของฉัน
ในที่สุดจุดตรวจควรได้รับการจัดเรียงเป็น ./MOFA-Video-Hybrid/ckpt_tree.md
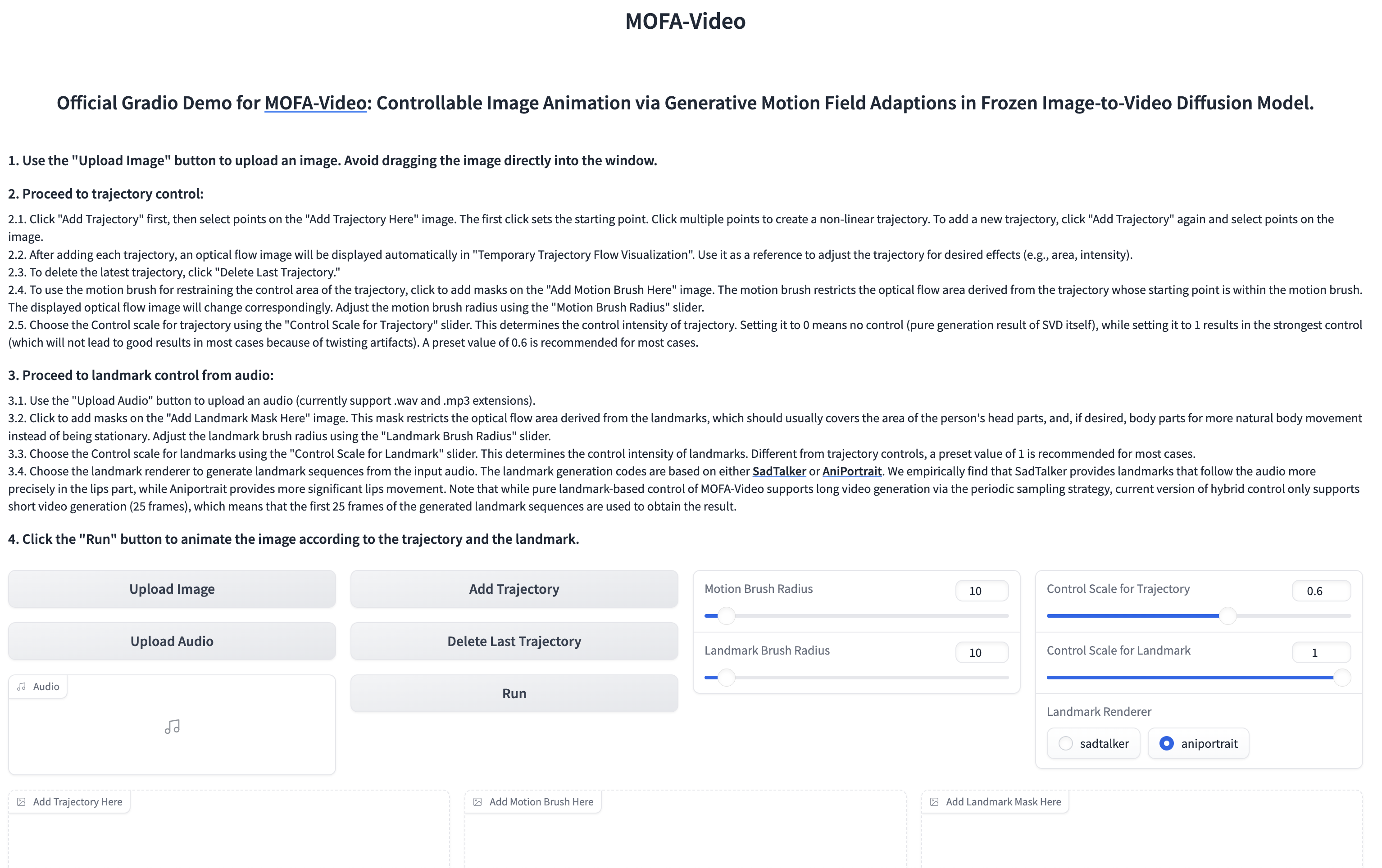
ใช้เสียงเพื่อเคลื่อนไหวส่วนใบหน้า
cd ./MOFA-Video-Hybrid
python run_gradio_audio_driven.py
- อินเทอร์เฟซ gradio จะปรากฏขึ้นด้านล่าง โปรดดูคำแนะนำเกี่ยวกับอินเทอร์เฟซ Gradio ในระหว่างกระบวนการอนุมาน!
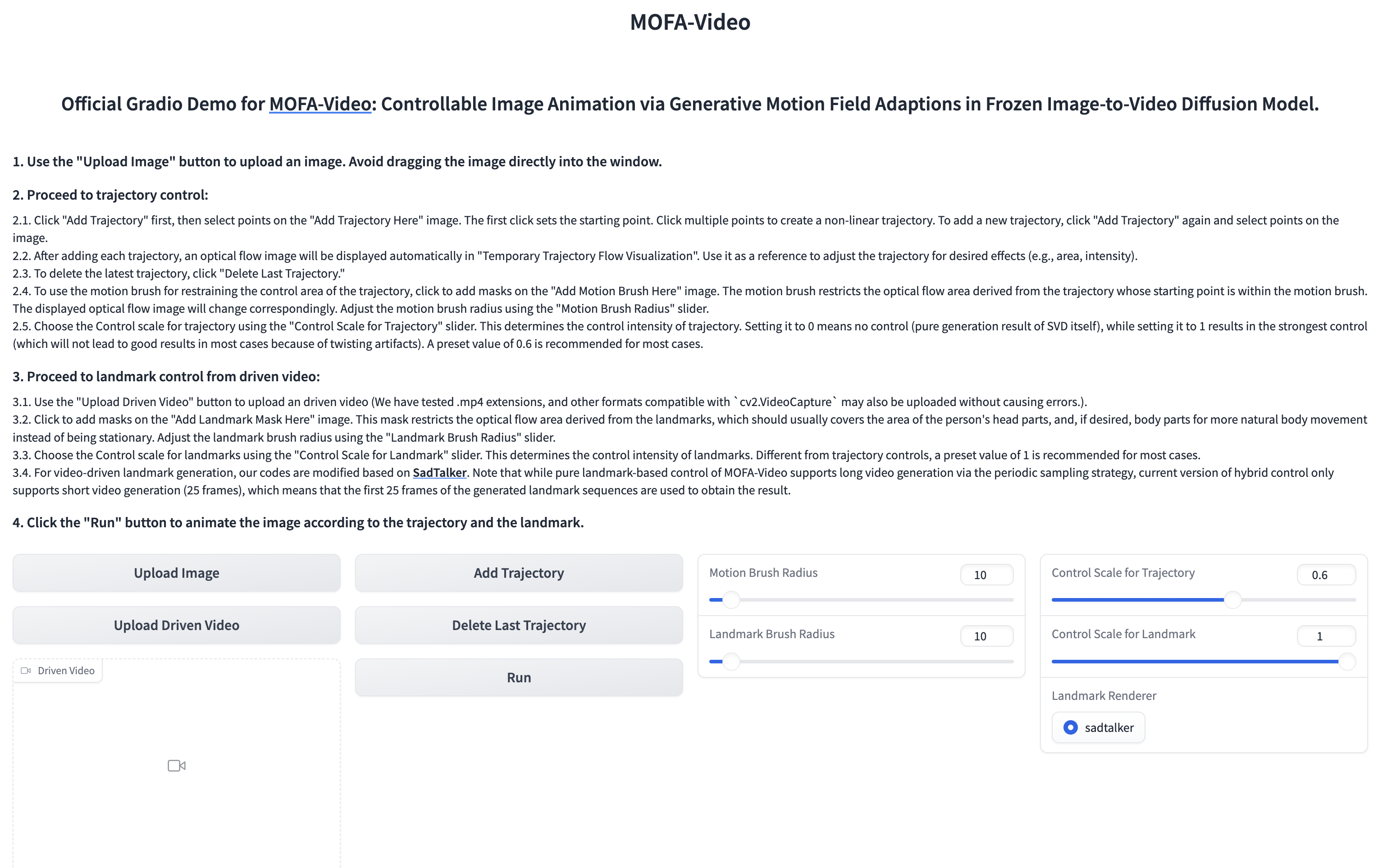
การใช้วิดีโออ้างอิงเพื่อเคลื่อนไหวส่วนใบหน้า
cd ./MOFA-Video-Hybrid
python run_gradio_video_driven.py
- อินเทอร์เฟซ gradio จะปรากฏขึ้นด้านล่าง โปรดดูคำแนะนำเกี่ยวกับอินเทอร์เฟซ Gradio ในระหว่างกระบวนการอนุมาน!
โปรดดูคำแนะนำที่นี่
โปรดดูที่นี่สำหรับคำแนะนำเพิ่มเติม
@article{niu2024mofa,
title={MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model},
author={Niu, Muyao and Cun, Xiaodong and Wang, Xintao and Zhang, Yong and Shan, Ying and Zheng, Yinqiang},
journal={arXiv preprint arXiv:2405.20222},
year={2024}
}
เราขอขอบคุณอย่างจริงใจในการเปิดตัวรหัสของโครงการต่อไปนี้: Dragnuwa, Sadtalker, Aniportrait, diffusers, SVD_XTEND, การตั้งค่าการเคลื่อนไหวตามเงื่อนไขและ unimatch


