MOFA Video
1.0.0
En la Conferencia Europea sobre Visión Computadora (ECCV) 2024
(2024.08.07) ¡Hemos lanzado el script de inferencia para la animación de imagen facial basada en KeyPoint! Consulte aquí para obtener más instrucciones.
(2024.07.15) ¡Hemos lanzado el código de entrenamiento para la animación de imágenes basada en trayectoria! Consulte aquí para obtener más instrucciones.
¡Mofa-Video aparecerá en ECCV 2024! ??????
¡Hemos lanzado el código de inferencia de Gradio y los puntos de control para los controles híbridos ! Consulte aquí para obtener más instrucciones.
¡Próximamente la demostración en línea gratuita a través de Huggingface Spaces llegará pronto!
Si encuentra interesante este trabajo, ¡no dude en darle un!
 |  |  |
| Trayectoria + control histórico | ||
 |  |  |  |
| Control de trayectoria | |||
 |  |  |  |  |
| Control de referencia | ||||
Introducimos a Mofa-Video, un método diseñado para adaptar los movimientos de diferentes dominios al modelo de difusión de video congelado. Al emplear la generación de movimiento de forma escasa a densa (S2D) y la adaptación de movimiento basada en el flujo, el MOFA-Video puede animar efectivamente una sola imagen utilizando varios tipos de señales de control, incluidas trayectorias, secuencias de punto clave y sus combinaciones.
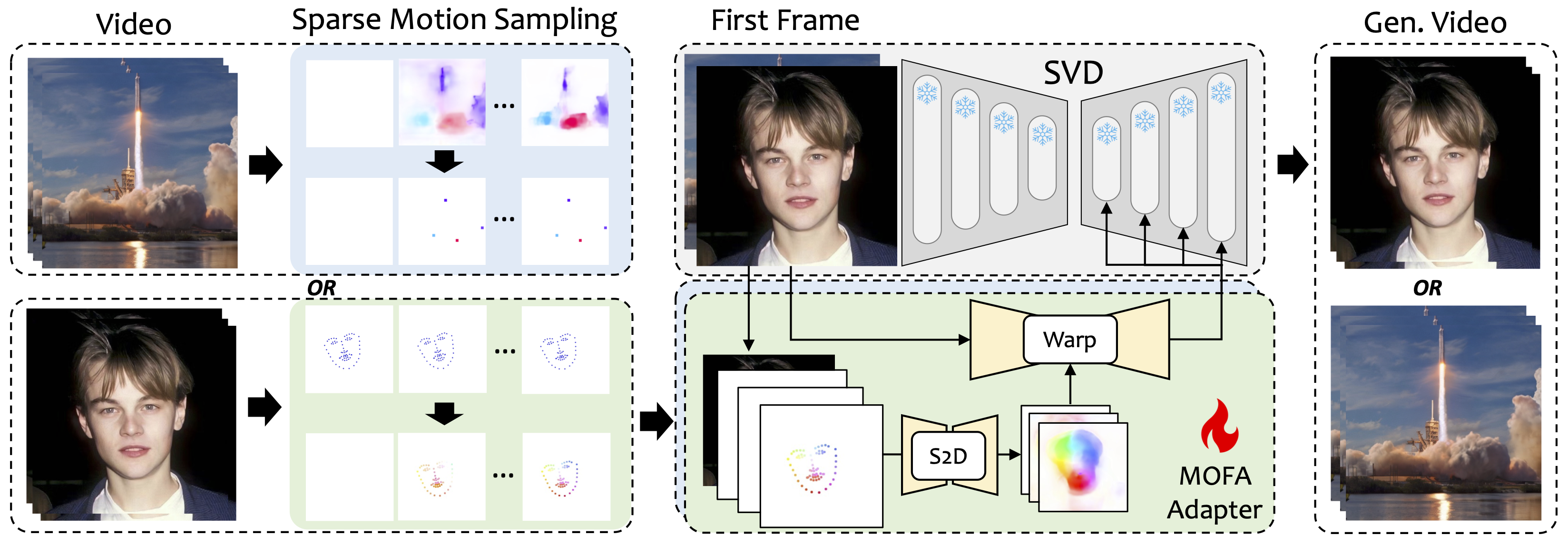
Durante la etapa de entrenamiento, generamos señales de control dispersas a través de un muestreo de movimiento disperso y luego entrenamos diferentes adaptadores MOFA para generar videos a través de SVD previamente capacitado. Durante la etapa de inferencia, se pueden combinar diferentes adaptadores MOFA para controlar conjuntamente el SVD congelado.
git clone https://github.com/MyNiuuu/MOFA-Video.git
cd ./MOFA-Video
La demostración ha sido probada en la versión CUDA de 11.7.
cd ./MOFA-Video-Hybrid
conda create -n mofa python==3.10
conda activate mofa
pip install -r requirements.txt
pip install opencv-python-headless
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
IMPORTANTE:requirements.txt TXT debe seguirse estrictamente ya que otras versiones pueden causar errores.
Descargue el punto de control de CMP desde aquí y póngalo en ./MOFA-Video-Hybrid/models/cmp/experiments/semiauto_annot/resnet50_vip+mpii_liteflow/checkpoints .
Descargue la carpeta ckpts desde el repositorio de Huggingface que contiene los puntos de control previos a la petrada y colóquela en ./MOFA-Video-Hybrid Video-Hybrid. Puede usar git lfs para descargar toda la carpeta ckpts :
git lfs de https://git-lfs.github.com. Se usa comúnmente para clonar repositorios con grandes puntos de control de modelo en Huggingface.git clone https://huggingface.co/MyNiuuu/MOFA-Video-Hybrid para descargar el repositorio completo de Huggingface, que actualmente solo incluye la carpeta ckpts .ckpts al repositorio de GitHub. Nota: Si encuentra el error git: 'lfs' is not a git command en Linux, puede probar esta solución que ha funcionado bien para mi caso.
Finalmente, los puntos de control deben ser orgnizados como ./MOFA-Video-Hybrid/ckpt_tree.md .
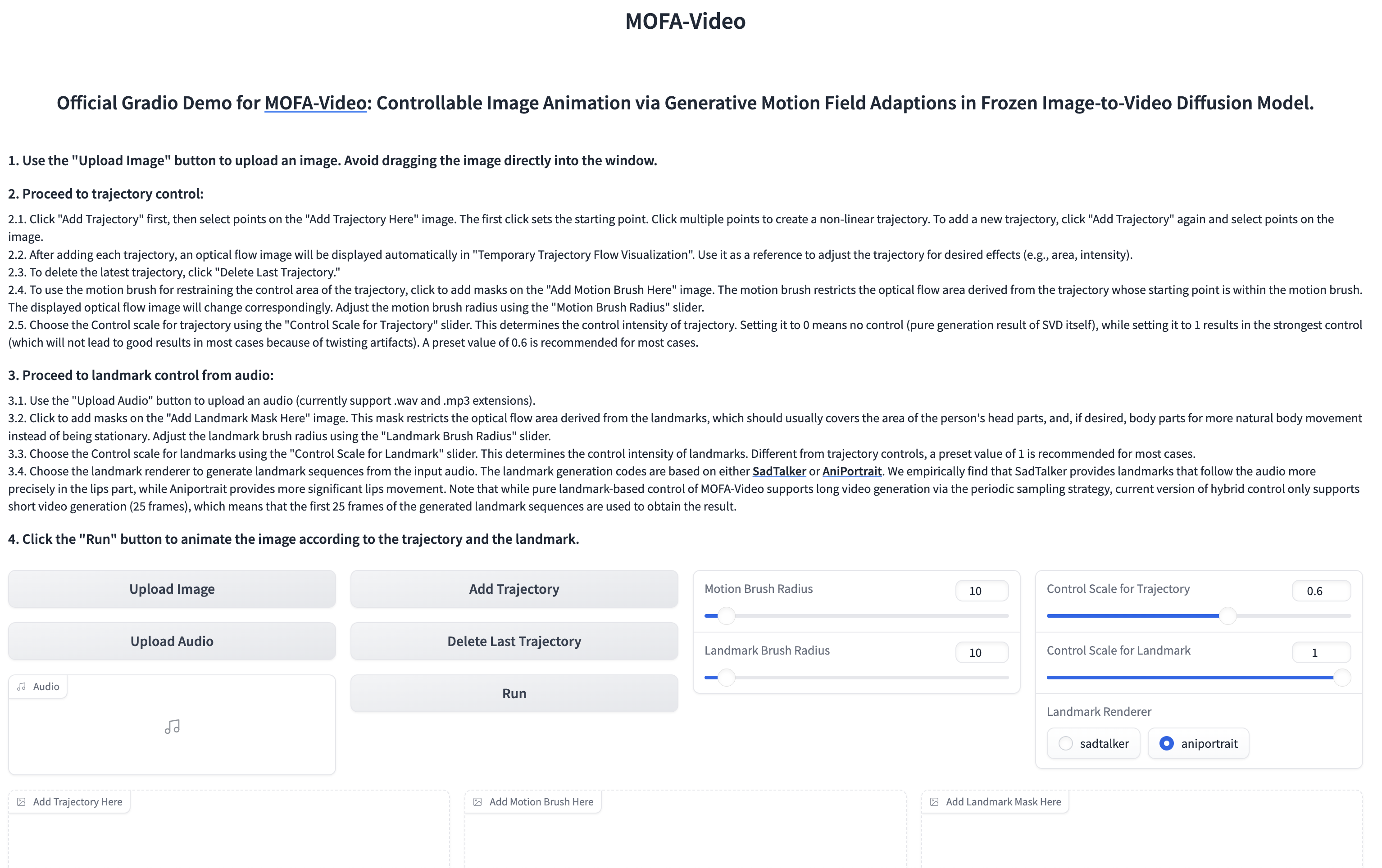
Usar audio para animar la parte facial
cd ./MOFA-Video-Hybrid
python run_gradio_audio_driven.py
???? La interfaz Gradio se muestra a continuación. ¡Consulte las instrucciones en la interfaz de Gradio durante el proceso de inferencia!
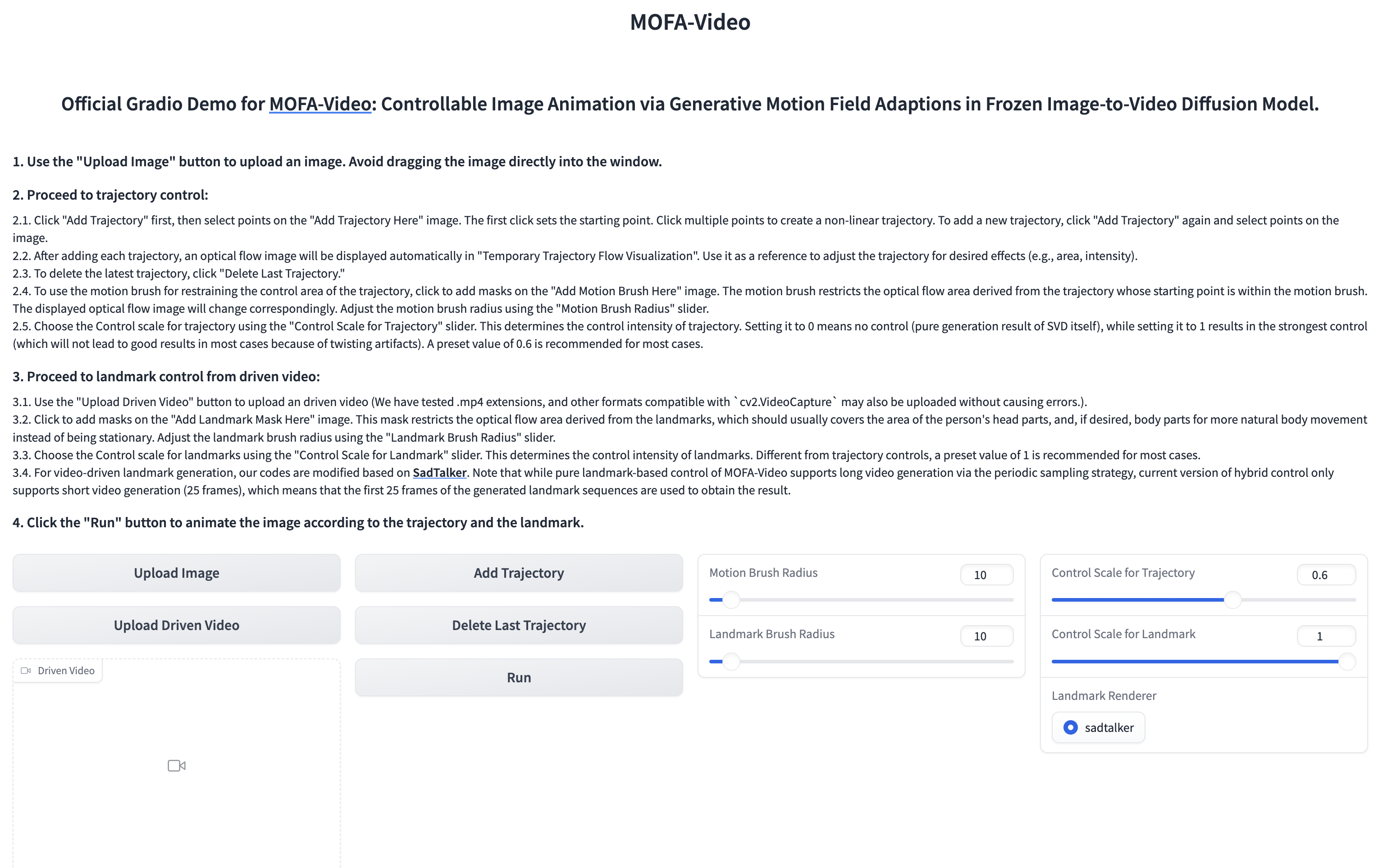
Usando un video de referencia para animar la parte facial
cd ./MOFA-Video-Hybrid
python run_gradio_video_driven.py
???? La interfaz Gradio se muestra a continuación. ¡Consulte las instrucciones en la interfaz de Gradio durante el proceso de inferencia!
Consulte aquí para obtener instrucciones.
Consulte aquí para obtener más instrucciones.
@article{niu2024mofa,
title={MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model},
author={Niu, Muyao and Cun, Xiaodong and Wang, Xintao and Zhang, Yong and Shan, Ying and Zheng, Yinqiang},
journal={arXiv preprint arXiv:2405.20222},
year={2024}
}
Apreciamos sinceramente el lanzamiento del código de los siguientes proyectos: Dragnuwa, Sadtalker, Aniportrait, Diffusers, SVD_XTEND, Propagation condicional-movimiento y Unimatch.


