MOFA Video
1.0.0
En conférence européenne sur la vision par ordinateur (ECCV) 2024
(2024.08.07) Nous avons publié le script d'inférence pour l'animation d'image faciale basée sur KeyPoint! Veuillez vous référer à ici pour plus d'instructions.
(2024.07.15) Nous avons publié le code de formation pour l'animation d'image basée sur la trajectoire! Veuillez vous référer à ici pour plus d'instructions.
Mofa-video sera apparu dans ECCV 2024! ??????
Nous avons publié le code d'inférence Gradio et les points de contrôle des contrôles hybrides ! Veuillez vous référer à ici pour plus d'instructions.
La démo en ligne gratuite via des espaces HuggingFace arrivera bientôt!
Si vous trouvez ce travail intéressant, n'hésitez pas à donner un!
 |  |  |
| Trajectoire + contrôle historique | ||
 |  |  |  |
| Contrôle de la trajectoire | |||
 |  |  |  |  |
| Contrôle historique | ||||
Nous introduisons Mofa-video, une méthode conçue pour adapter les mouvements de différents domaines au modèle de diffusion vidéo congelé. En utilisant la génération de mouvement clairsemée (S2D) et l'adaptation de mouvement basée sur le flux, le mofa-video peut animer efficacement une seule image en utilisant divers types de signaux de contrôle, y compris les trajectoires, les séquences de point clés et leurs combinaisons.
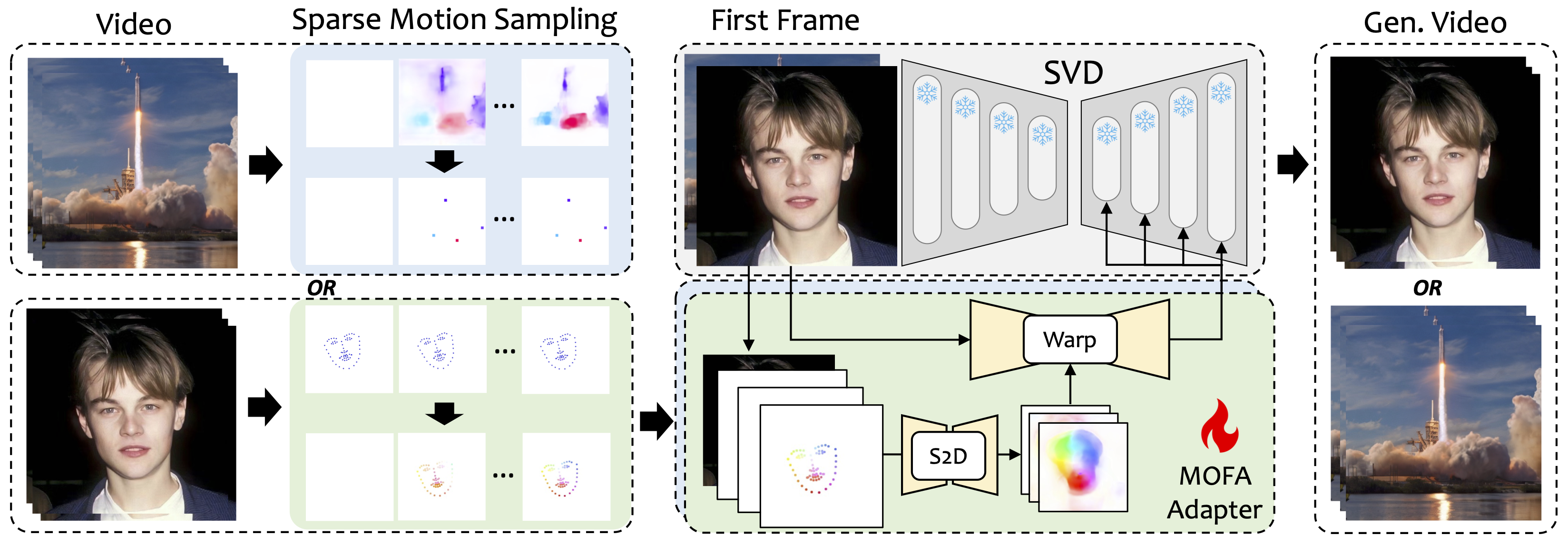
Pendant la phase d'entraînement, nous générons des signaux de contrôle clairsemés grâce à un échantillonnage de mouvement clairsemé, puis entraînons différents adaptateurs de mofa-adaptateurs pour générer une vidéo via un SVD pré-formé. Pendant le stade d'inférence, différentes adaptations MOFA peuvent être combinées pour contrôler conjointement le SVD congelé.
git clone https://github.com/MyNiuuu/MOFA-Video.git
cd ./MOFA-Video
La démo a été testée sur la version CUDA de 11.7.
cd ./MOFA-Video-Hybrid
conda create -n mofa python==3.10
conda activate mofa
pip install -r requirements.txt
pip install opencv-python-headless
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
IMPORTANT:requirements.txt doit être strictement suivie car d'autres versions peuvent provoquer des erreurs.
Téléchargez le point de contrôle de CMP à partir d'ici et mettez-le dans ./MOFA-Video-Hybrid/models/cmp/experiments/semiauto_annot/resnet50_vip+mpii_liteflow/checkpoints .
Téléchargez le dossier ckpts à partir du repo HuggingFace qui contient les points de contrôle pré-entraînés nécessaires et mettez-le sous ./MOFA-Video-Hybrid . Vous pouvez utiliser git lfs pour télécharger l' intégralité du dossier ckpts :
git lfs à partir de https://git-lfs.github.com. Il est couramment utilisé pour le clonage des référentiels avec de grands points de contrôle de modèle sur HuggingFace.git clone https://huggingface.co/MyNiuuu/MOFA-Video-Hybrid pour télécharger le référentiel complet HuggingFace, qui ne comprend actuellement que le dossier ckpts .ckpts vers le référentiel GitHub. Remarque: Si vous rencontrez l'erreur git: 'lfs' is not a git command sur Linux, vous pouvez essayer cette solution qui a bien fonctionné pour mon cas.
Enfin, les points de contrôle doivent être orgnés comme ./MOFA-Video-Hybrid/ckpt_tree.md .
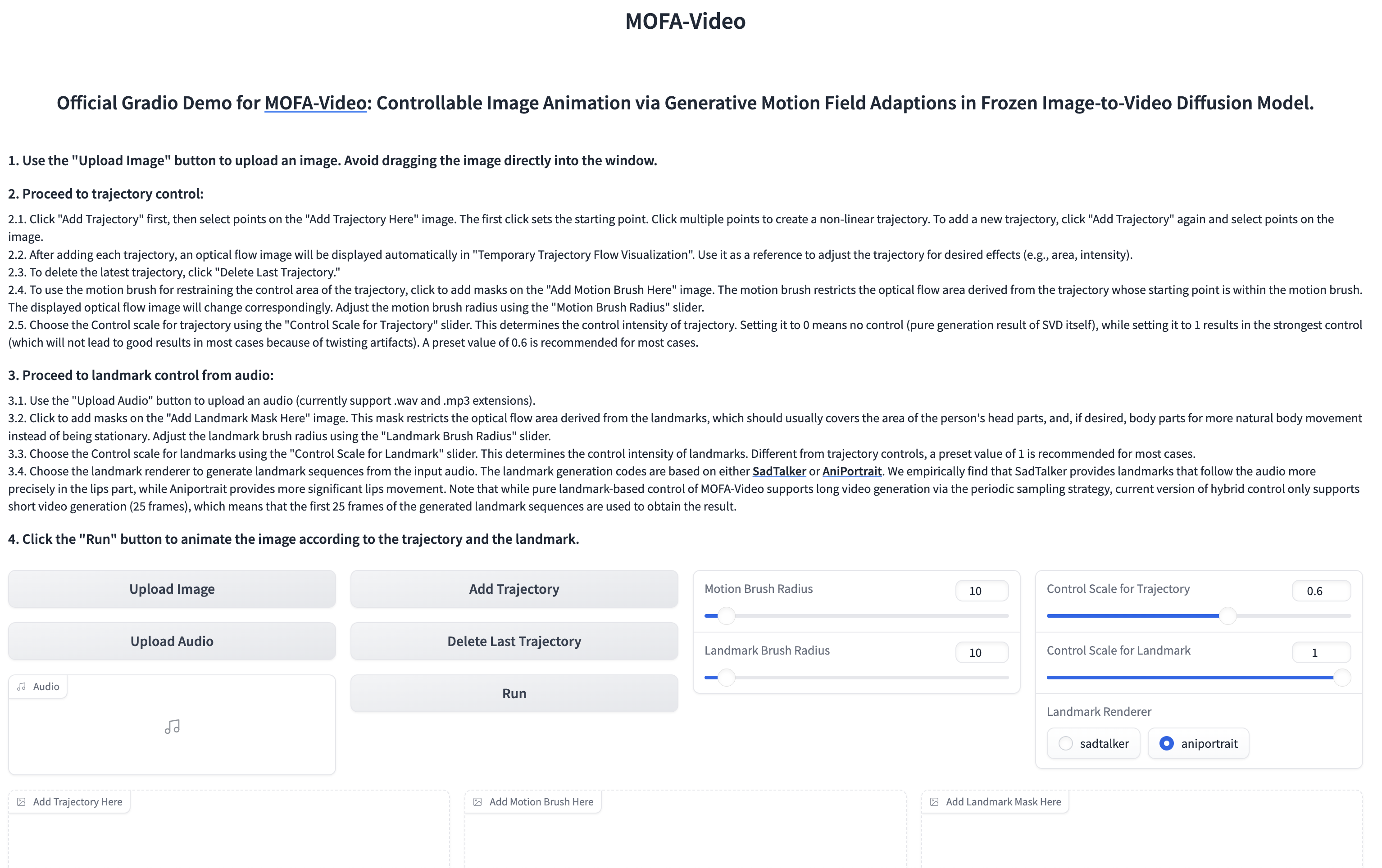
Utilisation de l'audio pour animer la partie faciale
cd ./MOFA-Video-Hybrid
python run_gradio_audio_driven.py
??? L'interface Gradio est affichée comme ci-dessous. Veuillez vous référer aux instructions sur l'interface Gradio pendant le processus d'inférence!
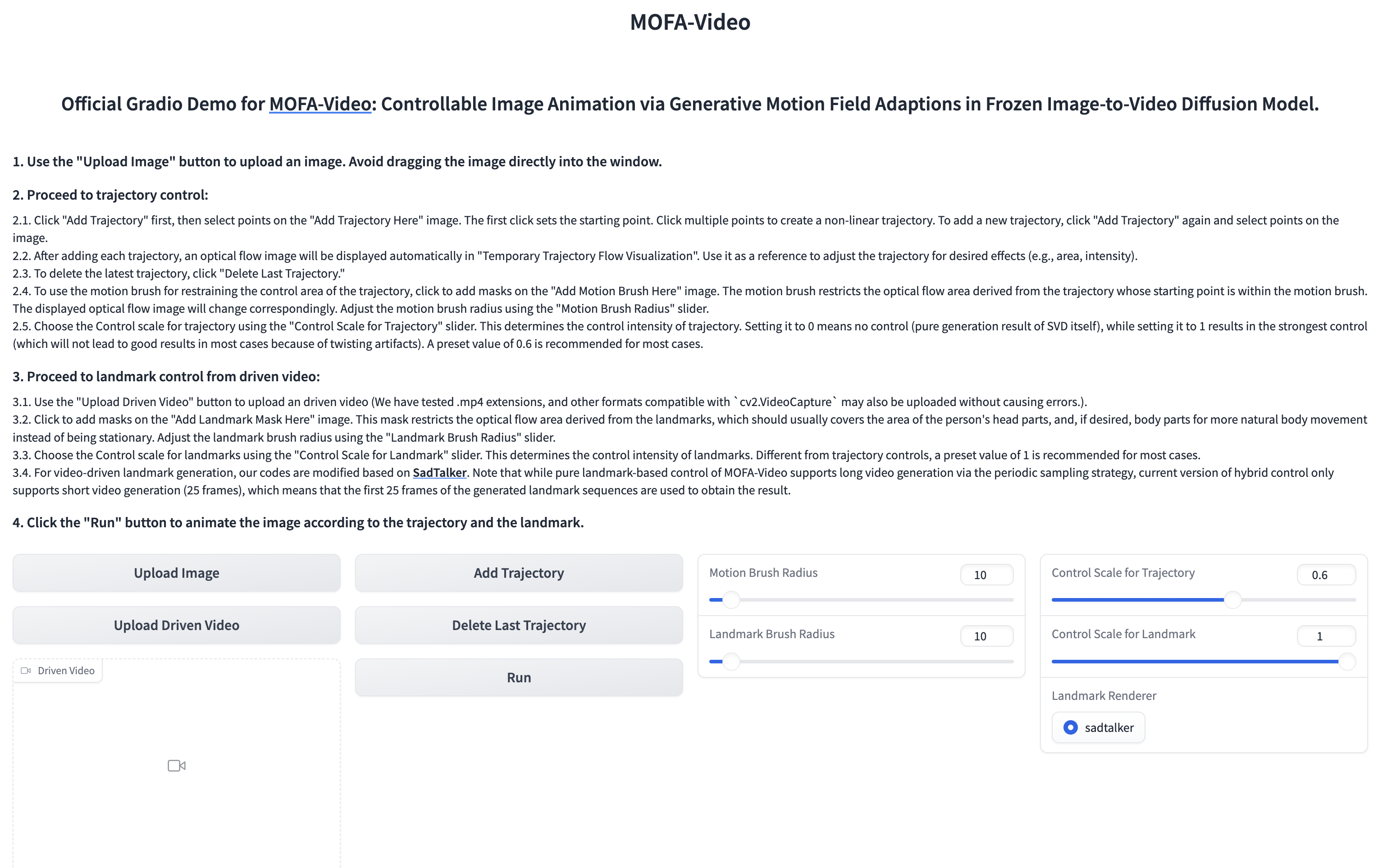
Utilisation de la vidéo de référence pour animer la partie faciale
cd ./MOFA-Video-Hybrid
python run_gradio_video_driven.py
??? L'interface Gradio est affichée comme ci-dessous. Veuillez vous référer aux instructions sur l'interface Gradio pendant le processus d'inférence!
Veuillez vous référer à ici pour des instructions.
Veuillez vous référer à ici pour plus d'instructions.
@article{niu2024mofa,
title={MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model},
author={Niu, Muyao and Cun, Xiaodong and Wang, Xintao and Zhang, Yong and Shan, Ying and Zheng, Yinqiang},
journal={arXiv preprint arXiv:2405.20222},
year={2024}
}
Nous apprécions sincèrement la version du code des projets suivants: dragnuwa, sadtalker, aniportrait, diffuseurs, svd_xtend, propagation conditionnelle-mouvement et unmatch.


