MOFA Video
1.0.0
Na Conferência Europeia sobre Visão Computal (ECCV) 2024
(2024.08.07) Lançamos o script de inferência para animação de imagem facial baseada em pontos de chave! Consulte aqui para obter mais instruções.
(2024.07.15) Lançamos o código de treinamento para animação de imagem baseada em trajetória! Consulte aqui para obter mais instruções.
MOFA-Video será aparecido no ECCV 2024! ???????
Lançamos o Código de Inferência do Gradio e os pontos de verificação para controles híbridos ! Consulte aqui para obter mais instruções.
Demoção online gratuita através de espaços Huggingface estará chegando em breve!
Se você achar esse trabalho interessante, não hesite em dar um!
 |  |  |
| Trajetória + controle de referência | ||
 |  |  |  |
| Controle de trajetória | |||
 |  |  |  |  |
| Controle de marcos | ||||
Introduzimos MOFA-Video, um método projetado para adaptar os movimentos de diferentes domínios ao modelo de difusão de vídeo congelado. Ao empregar a geração de movimento esparsa a densa (S2D) e a adaptação de movimento baseada em fluxo, o MOFA-Video pode efetivamente animar uma única imagem usando vários tipos de sinais de controle, incluindo trajetórias, sequências de ponto de chave e suas combinações.
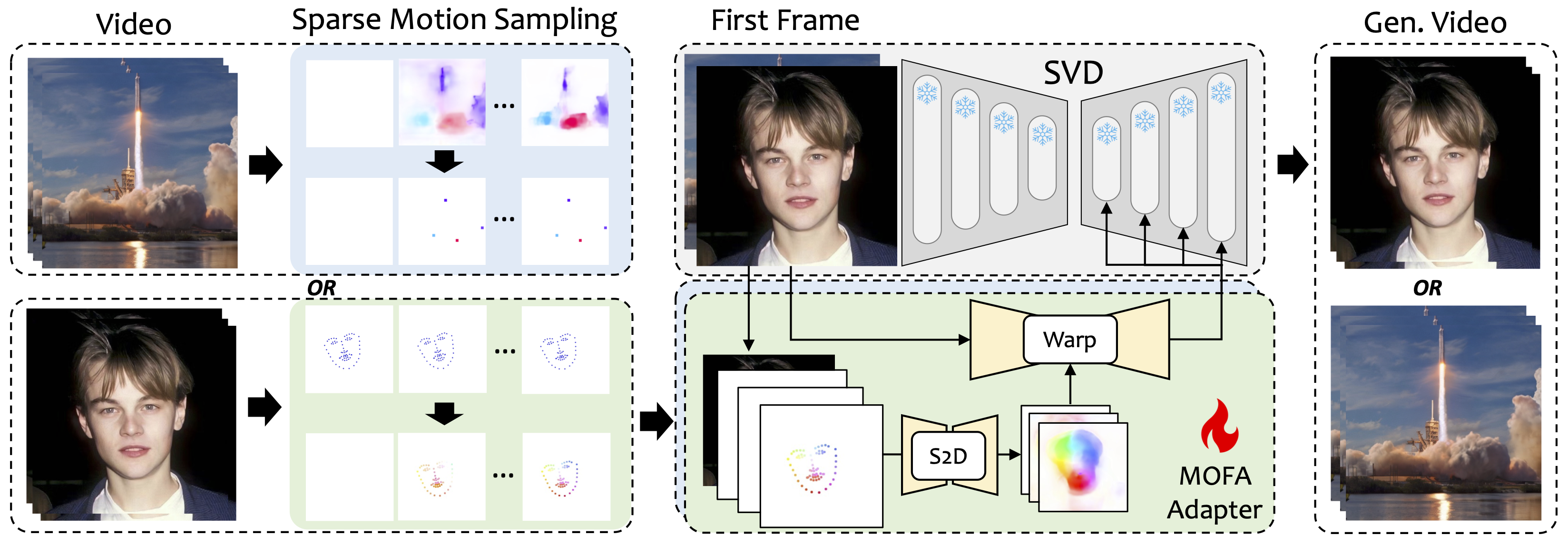
Durante a fase de treinamento, geramos sinais de controle escassos através de amostragem de movimento esparso e, em seguida, treinamos diferentes MOFA-adaptadores para gerar vídeo por meio de SVD pré-treinado. Durante a fase de inferência, diferentes MOFA-AdAptores podem ser combinados para controlar em conjunto o SVD congelado.
git clone https://github.com/MyNiuuu/MOFA-Video.git
cd ./MOFA-Video
A demonstração foi testada na versão CUDA de 11.7.
cd ./MOFA-Video-Hybrid
conda create -n mofa python==3.10
conda activate mofa
pip install -r requirements.txt
pip install opencv-python-headless
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
IMPORTANTE:requirements.txt deve ser seguida estritamente, pois outras versões podem causar erros.
Faça o download do ponto de verificação do CMP aqui e coloque-o em ./MOFA-Video-Hybrid/models/cmp/experiments/semiauto_annot/resnet50_vip+mpii_liteflow/checkpoints .
Faça o download da pasta ckpts do repositório Huggingface, que contém pontos de verificação pré-terem previsto e coloque-o em ./MOFA-Video-Hybrid . Você pode usar git lfs para baixar a pasta ckpts inteira :
git lfs de https://git-lfs.github.com. É comumente usado para repositórios de clonagem com grandes pontos de verificação de modelo no HuggingFace.git clone https://huggingface.co/MyNiuuu/MOFA-Video-Hybrid para baixar o repositório completo do Huggingface, que atualmente inclui apenas a pasta ckpts .ckpts para o repositório do GitHub. NOTA: Se você encontrar o erro git: 'lfs' is not a git command no Linux, você poderá experimentar esta solução que funcionou bem para o meu caso.
Finalmente, os pontos de verificação devem ser organizados como ./MOFA-Video-Hybrid/ckpt_tree.md .
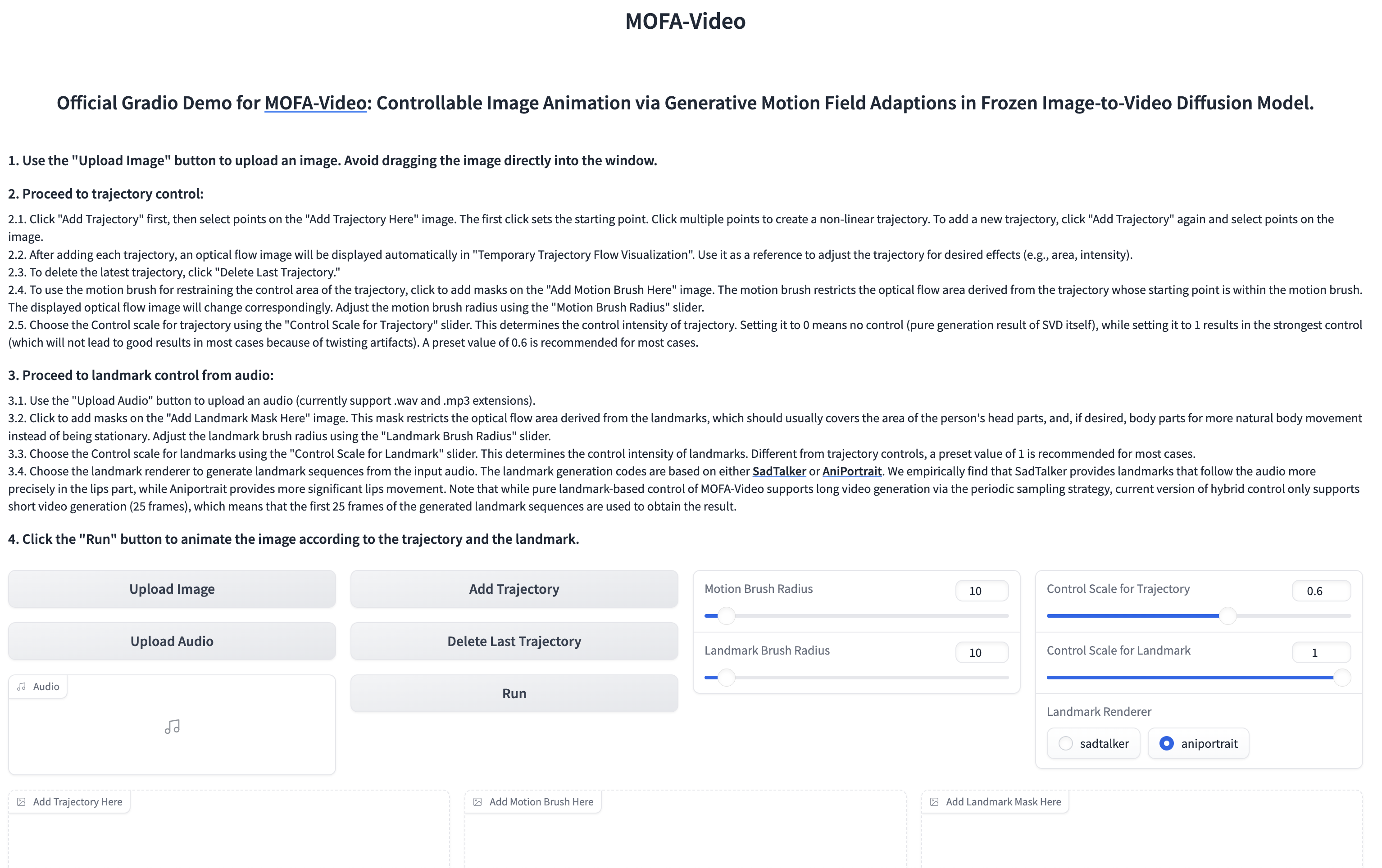
Usando áudio para animar a parte facial
cd ./MOFA-Video-Hybrid
python run_gradio_audio_driven.py
??? A interface gradio é exibida como abaixo. Consulte as instruções na interface Gradio durante o processo de inferência!
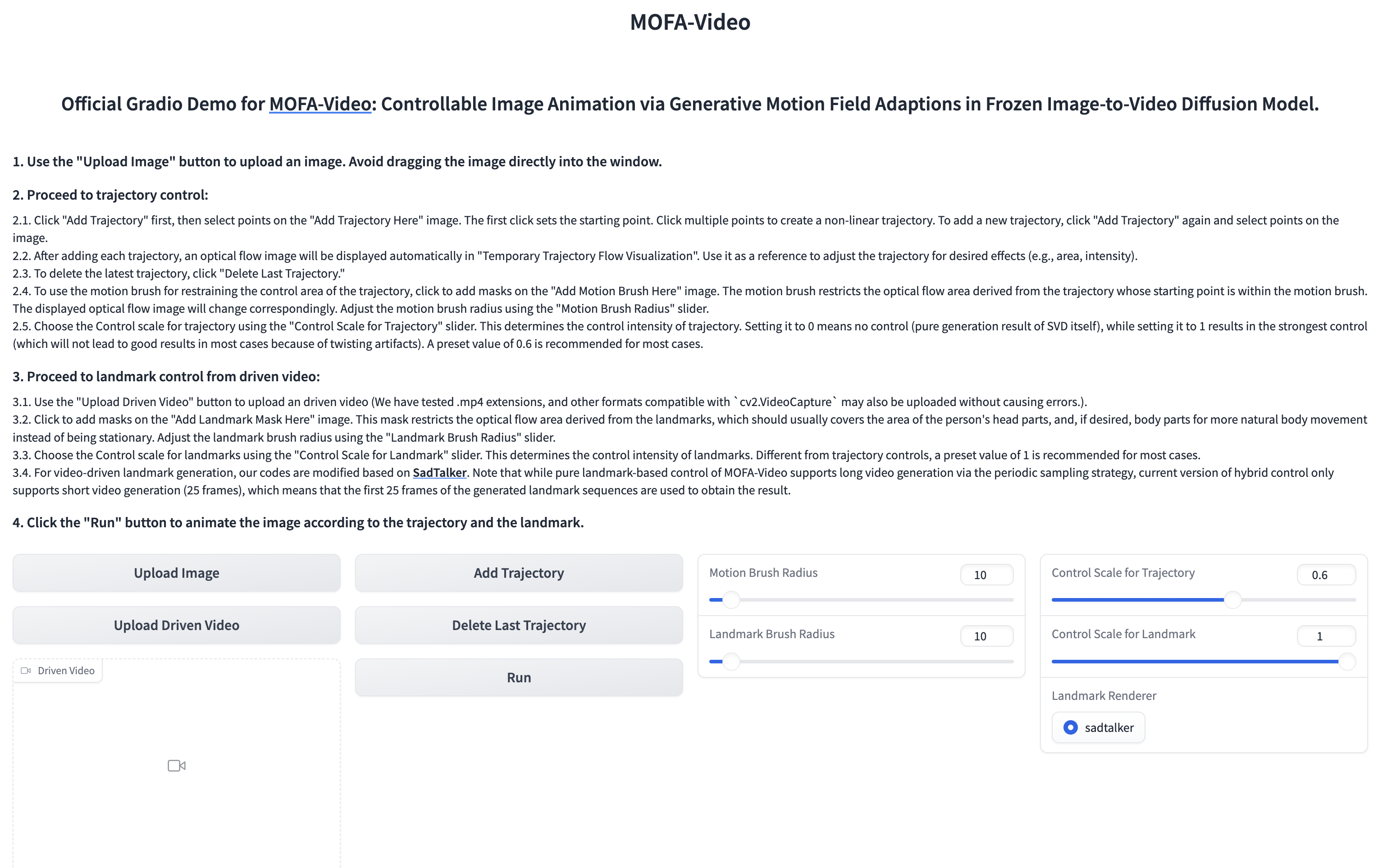
Usando o vídeo de referência para animar a parte facial
cd ./MOFA-Video-Hybrid
python run_gradio_video_driven.py
??? A interface gradio é exibida como abaixo. Consulte as instruções na interface Gradio durante o processo de inferência!
Consulte aqui para obter instruções.
Consulte aqui para obter mais instruções.
@article{niu2024mofa,
title={MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model},
author={Niu, Muyao and Cun, Xiaodong and Wang, Xintao and Zhang, Yong and Shan, Ying and Zheng, Yinqiang},
journal={arXiv preprint arXiv:2405.20222},
year={2024}
}
Apreciamos sinceramente a liberação de código dos seguintes projetos: Dragnuwa, Sadtalker, Aniportrait, difusores, SVD_XTEND, propagação de movimento condicional e Unimatch.


