MOFA Video
1.0.0
Dalam Konferensi Eropa tentang Visi Komputer (ECCV) 2024
(2024.08.07) Kami telah merilis skrip inferensi untuk animasi gambar wajah berbasis keypoint! Silakan merujuk di sini untuk instruksi lebih lanjut.
(2024.07.15) Kami telah merilis kode pelatihan untuk animasi gambar berbasis lintasan! Silakan merujuk di sini untuk instruksi lebih lanjut.
MOFA-Video akan muncul di ECCV 2024! ??????
Kami telah merilis kode inferensi gradio dan pos pemeriksaan untuk kontrol hybrid ! Silakan merujuk di sini untuk instruksi lebih lanjut.
Demo online gratis melalui ruang pelukan akan segera hadir!
Jika Anda menganggap pekerjaan ini menarik, jangan ragu untuk memberikan!
 |  |  |
| Lintasan + Kontrol Landmark | ||
 |  |  |  |
| Kontrol lintasan | |||
 |  |  |  |  |
| Kontrol tengara | ||||
Kami memperkenalkan MOFA-Video, metode yang dirancang untuk mengadaptasi gerakan dari domain yang berbeda ke model difusi video beku. Dengan menggunakan generasi gerak yang jarang (S2D) dan adaptasi gerak berbasis aliran, MOFA-Video dapat secara efektif menghidupkan satu gambar tunggal menggunakan berbagai jenis sinyal kontrol, termasuk lintasan, urutan keypoint, dan kombinasi mereka.
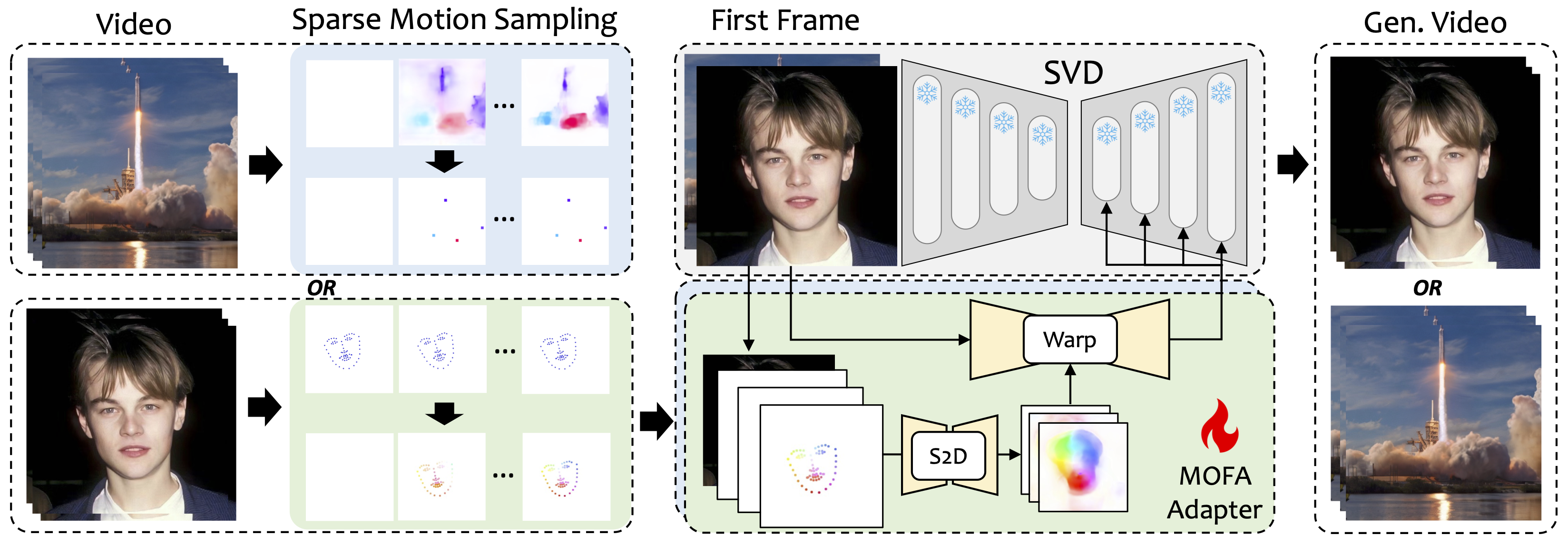
Selama tahap pelatihan, kami menghasilkan sinyal kontrol yang jarang melalui pengambilan sampel gerak yang jarang dan kemudian melatih adapter MOFA yang berbeda untuk menghasilkan video melalui SVD pra-terlatih. Selama tahap inferensi, adapter MOFA yang berbeda dapat digabungkan untuk secara bersama-sama mengontrol SVD beku.
git clone https://github.com/MyNiuuu/MOFA-Video.git
cd ./MOFA-Video
Demo telah diuji pada versi CUDA 11.7.
cd ./MOFA-Video-Hybrid
conda create -n mofa python==3.10
conda activate mofa
pip install -r requirements.txt
pip install opencv-python-headless
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
PENTING:requirements.txt harus diikuti secara ketat karena versi lain dapat menyebabkan kesalahan.
Unduh pos pemeriksaan CMP dari sini dan masukkan ke dalam ./MOFA-Video-Hybrid/models/cmp/experiments/semiauto_annot/resnet50_vip+mpii_liteflow/checkpoints .
Unduh folder ckpts dari Repo Huggingface yang berisi pos pemeriksaan pretrained yang diperlukan dan letakkan di bawah ./MOFA-Video-Hybrid . Anda dapat menggunakan git lfs untuk mengunduh seluruh folder ckpts :
git lfs dari https://git-lfs.github.com. Ini umumnya digunakan untuk kloning repositori dengan pos pemeriksaan model besar di Huggingface.git clone https://huggingface.co/MyNiuuu/MOFA-Video-Hybrid untuk mengunduh repositori pelukan lengkap, yang saat ini hanya menyertakan folder ckpts .ckpts ke repositori GitHub. Catatan: Jika Anda menemukan kesalahan git: 'lfs' is not a git command di Linux, Anda dapat mencoba solusi ini yang telah bekerja dengan baik untuk kasus saya.
Akhirnya, pos pemeriksaan harus diorganisasi sebagai ./MOFA-Video-Hybrid/ckpt_tree.md .
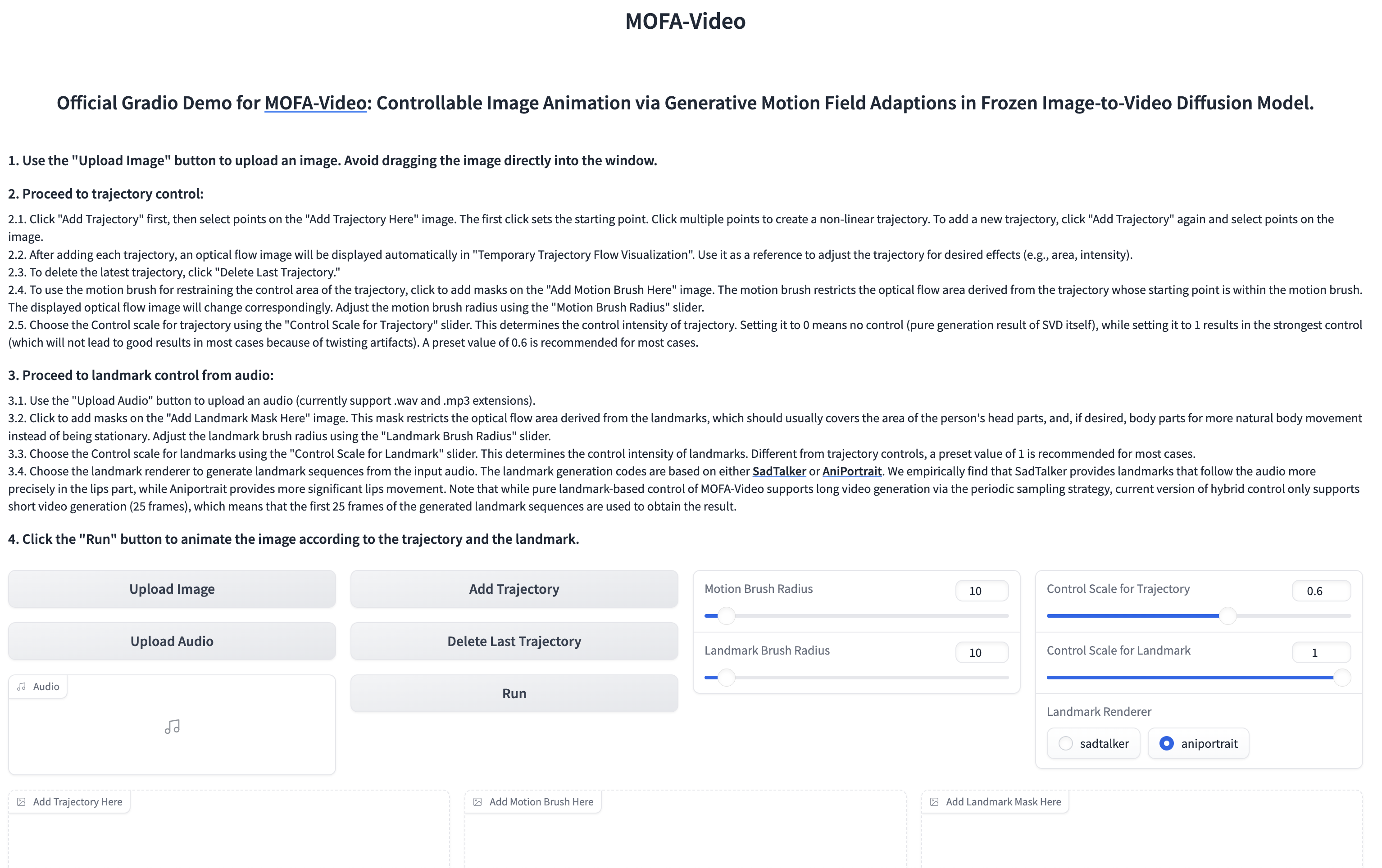
Menggunakan audio untuk menghidupkan bagian wajah
cd ./MOFA-Video-Hybrid
python run_gradio_audio_driven.py
??? Antarmuka gradio ditampilkan seperti di bawah ini. Silakan merujuk pada instruksi di antarmuka clashio selama proses inferensi!
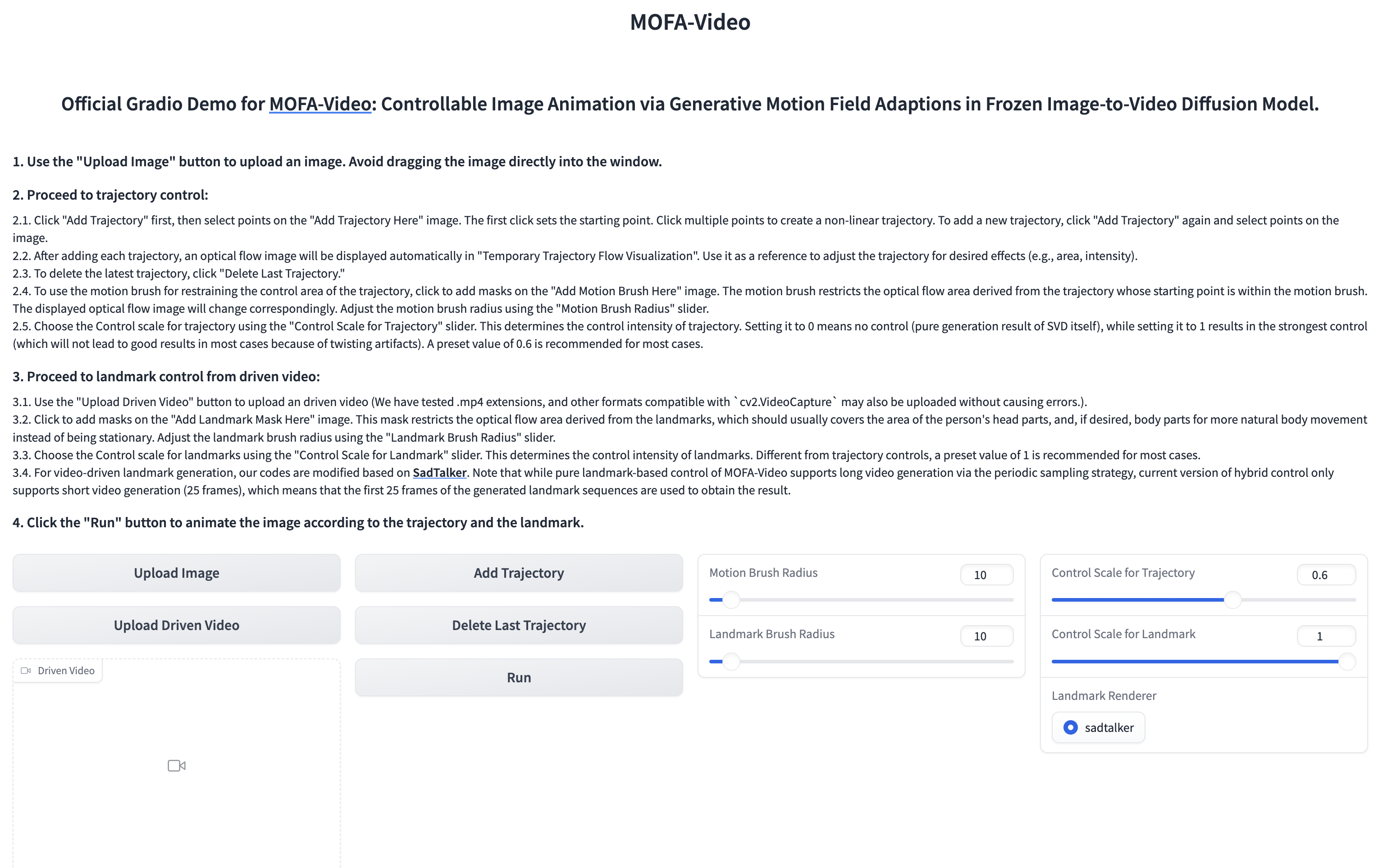
Menggunakan video referensi untuk menghidupkan bagian wajah
cd ./MOFA-Video-Hybrid
python run_gradio_video_driven.py
??? Antarmuka gradio ditampilkan seperti di bawah ini. Silakan merujuk pada instruksi di antarmuka clashio selama proses inferensi!
Silakan merujuk di sini untuk instruksi.
Silakan merujuk di sini untuk instruksi lebih lanjut.
@article{niu2024mofa,
title={MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model},
author={Niu, Muyao and Cun, Xiaodong and Wang, Xintao and Zhang, Yong and Shan, Ying and Zheng, Yinqiang},
journal={arXiv preprint arXiv:2405.20222},
year={2024}
}
Kami dengan tulus menghargai rilis kode dari proyek-proyek berikut: Dragnuwa, Sadtalker, Aniportrait, Diffusers, SVD_XTEND, propagasi-gerak kondisional, dan unimatch.


