MOFA Video
1.0.0
In der Europäischen Konferenz über Computer Vision (ECCV) 2024
(2024.08.07) Wir haben das Inferenzskript für Tastoint-basierte Gesichtsbildanimation veröffentlicht! Weitere Anweisungen finden Sie hier.
(2024.07.15) Wir haben den Trainingscode für Trajektorienbasierte Bildanimation veröffentlicht! Weitere Anweisungen finden Sie hier.
Mofa-video tritt in ECCV 2024 auf! ??????
Wir haben den Gradio Inferenzcode und die Checkpoints für Hybridsteuerungen veröffentlicht! Weitere Anweisungen finden Sie hier.
Kostenlose Online -Demo über Huggingface -Räume wird in Kürze kommen!
Wenn Sie diese Arbeit interessant finden, zögern Sie bitte nicht, ein zu geben!
 |  |  |
| Flugbahn + Wahrzeichen Kontrolle | ||
 |  |  |  |
| Trajektorienkontrolle | |||
 |  |  |  |  |
| Wahrzeichen Kontrolle | ||||
Wir stellen Mofa-video ein, eine Methode, um Bewegungen von verschiedenen Domänen an das gefrorene Video-Diffusionsmodell anzupassen. Durch die Verwendung von S2D-Bewegungserzeugung und fließender Bewegungsanpassung (S2D) kann MoFA-video ein einzelnes Bild unter Verwendung verschiedener Arten von Kontrollsignalen, einschließlich Trajektorien, Tastoint-Sequenzen und deren Kombinationen, effektiv animieren.
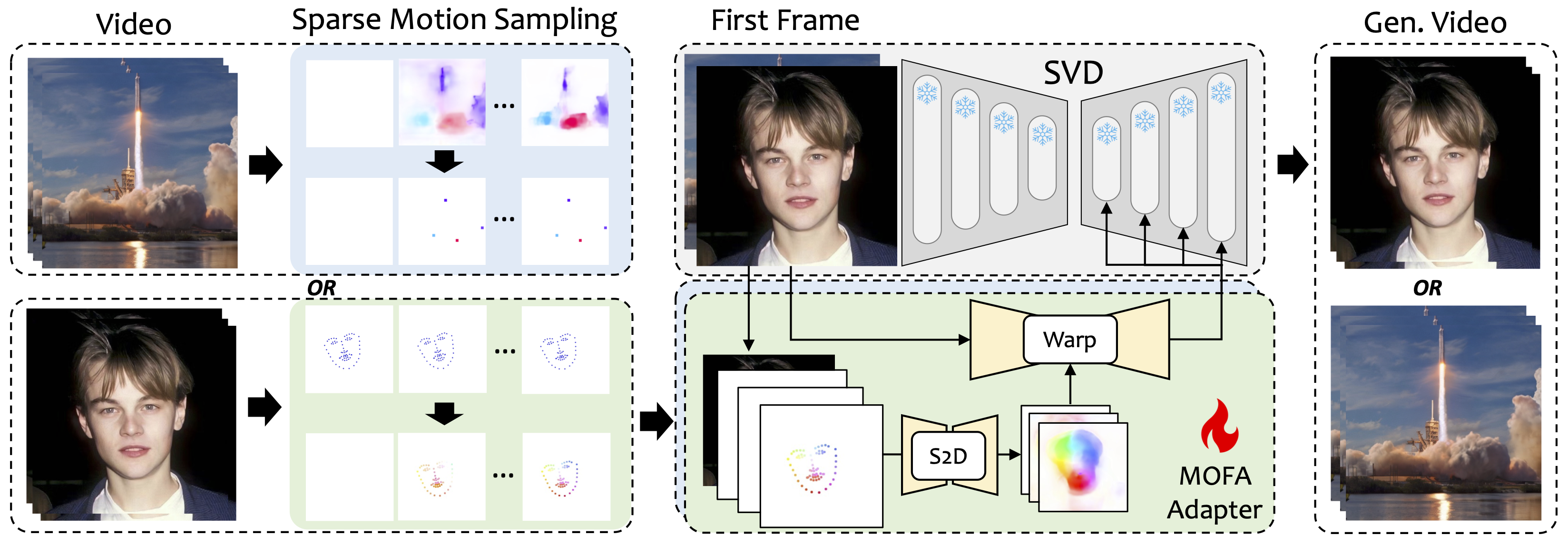
Während der Trainingsphase erzeugen wir spärliche Kontrollsignale durch spärliche Bewegungsproben und schulen dann verschiedene MoFA-Adapter, um über vorgebreitete SVD Video zu generieren. Während des Inferenzstadiums können verschiedene MoFA-Adapter kombiniert werden, um die gefrorene SVD gemeinsam zu kontrollieren.
git clone https://github.com/MyNiuuu/MOFA-Video.git
cd ./MOFA-Video
Die Demo wurde auf der CUDA -Version von 11,7 getestet.
cd ./MOFA-Video-Hybrid
conda create -n mofa python==3.10
conda activate mofa
pip install -r requirements.txt
pip install opencv-python-headless
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
WICHTIG:requirements.txt sollte streng befolgt werden, da andere Versionen Fehler verursachen können.
Laden Sie hier den Kontrollpunkt von CMP herunter und geben Sie ihn in ./MOFA-Video-Hybrid/models/cmp/experiments/semiauto_annot/resnet50_vip+mpii_liteflow/checkpoints ein.
Laden Sie den ckpts Ordner vom Huggingface-Repo herunter, das die erforderlichen vorbereiteten Kontrollpunkte enthält, und setzen Sie ihn unter ./MOFA-Video-Hybrid . Sie können git lfs verwenden, um den gesamten ckpts -Ordner herunterzuladen:
git lfs von https://git-lfs.github.com herunter. Es wird üblicherweise zum Klonieren von Repositories mit großen Modellkontrollpunkten auf dem Umarmungsface verwendet.git clone https://huggingface.co/MyNiuuu/MOFA-Video-Hybrid aus, um das komplette Huggingface-Repository herunterzuladen, das derzeit nur den ckpts Ordner enthält.ckpts -Ordner in das GitHub -Repository. HINWEIS: Wenn Sie auf den Fehler begegnen git: 'lfs' is not a git command unter Linux, können Sie diese Lösung ausprobieren, die für meinen Fall gut funktioniert hat.
Schließlich sollten die Checkpoints organisiert werden wie ./MOFA-Video-Hybrid/ckpt_tree.md .
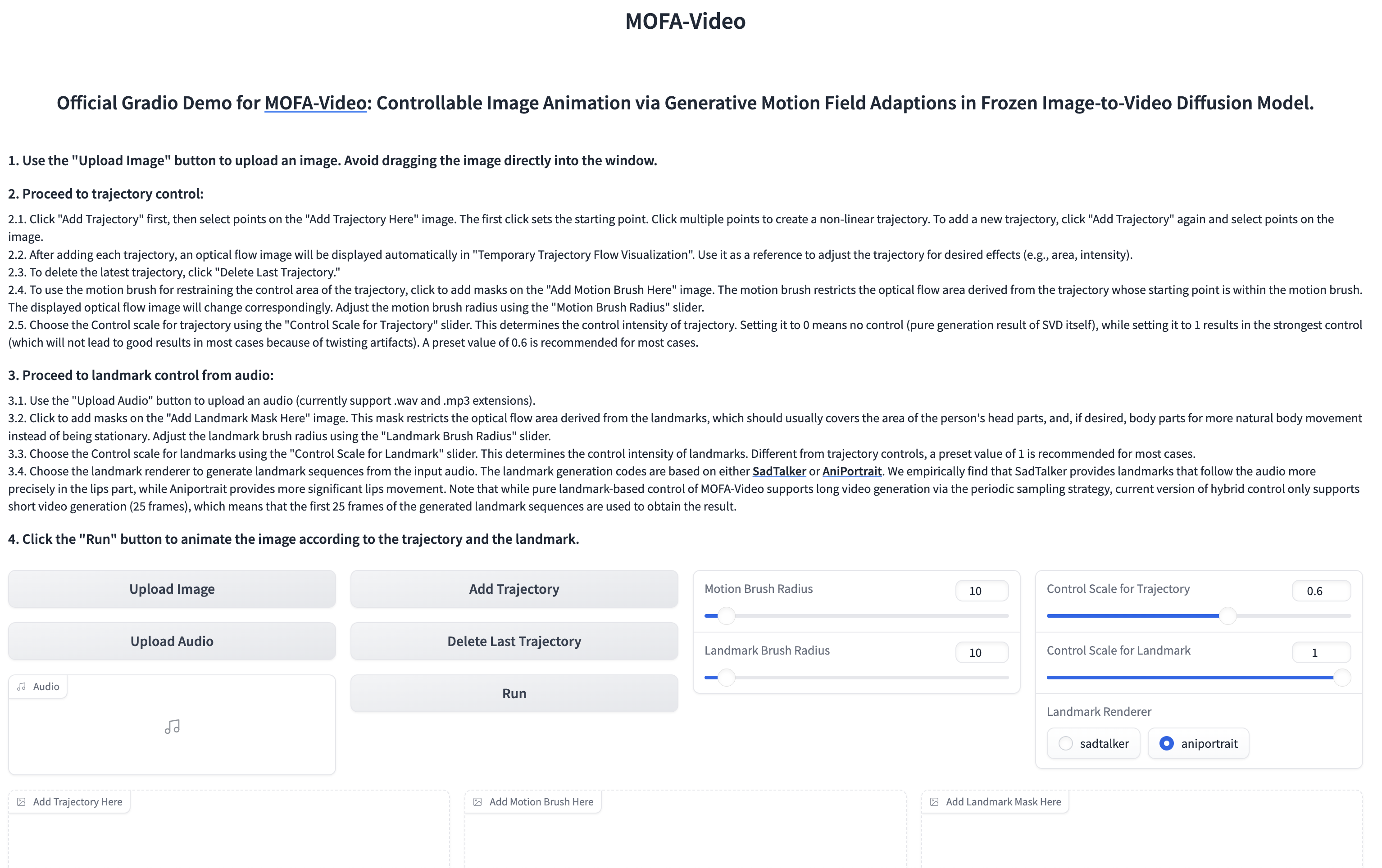
Nutzung von Audio, um den Gesichtsteil zu animieren
cd ./MOFA-Video-Hybrid
python run_gradio_audio_driven.py
??? Die Gradio -Schnittstelle wird wie unten angezeigt. Bitte beachten Sie die Anweisungen zur Gradio -Schnittstelle während des Inferenzprozesses!
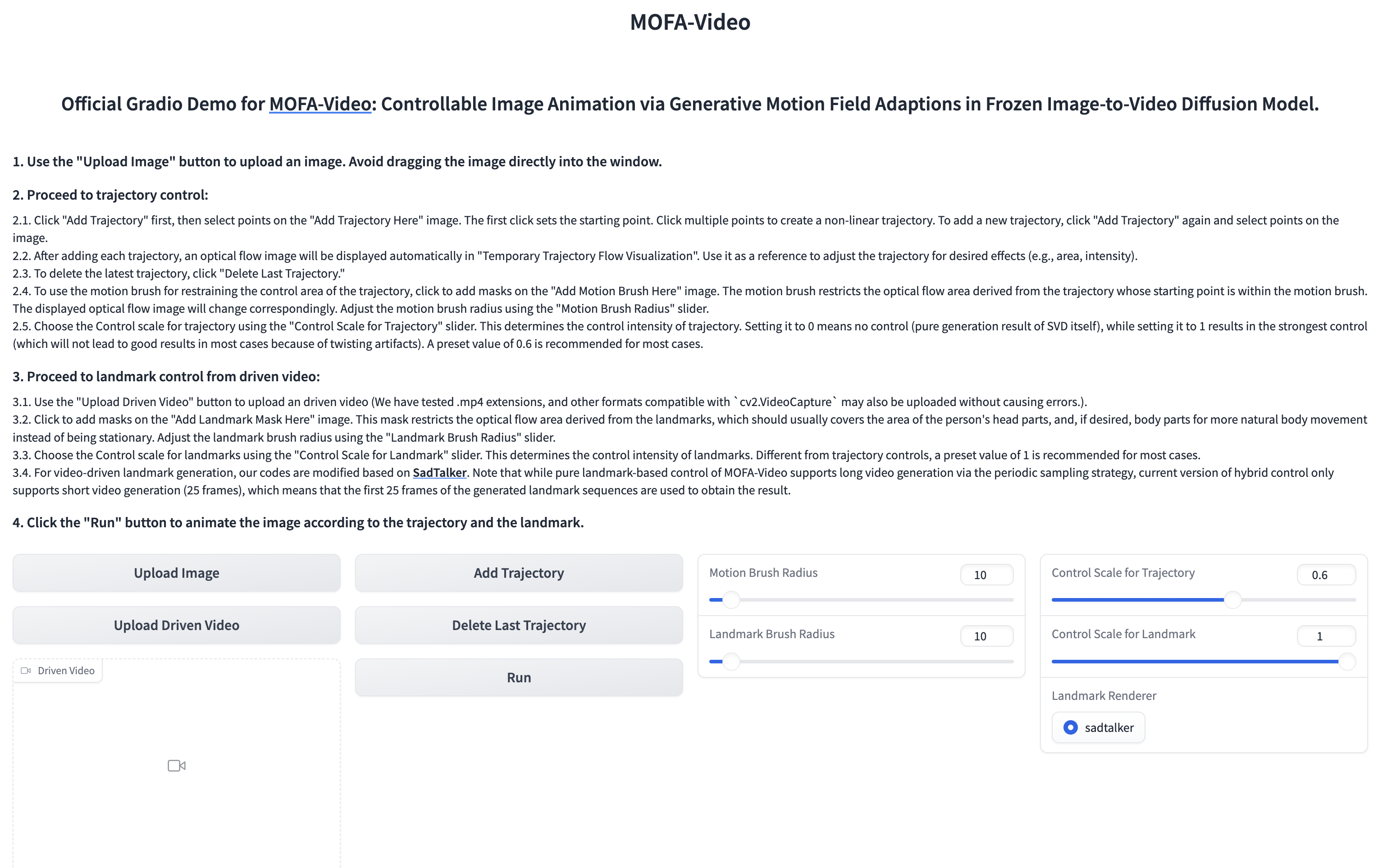
Verwenden von Referenzvideos, um den Gesichtsteil zu animieren
cd ./MOFA-Video-Hybrid
python run_gradio_video_driven.py
??? Die Gradio -Schnittstelle wird wie unten angezeigt. Bitte beachten Sie die Anweisungen zur Gradio -Schnittstelle während des Inferenzprozesses!
Weitere Anweisungen finden Sie hier.
Weitere Anweisungen finden Sie hier.
@article{niu2024mofa,
title={MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model},
author={Niu, Muyao and Cun, Xiaodong and Wang, Xintao and Zhang, Yong and Shan, Ying and Zheng, Yinqiang},
journal={arXiv preprint arXiv:2405.20222},
year={2024}
}
Wir schätzen die Code-Veröffentlichung der folgenden Projekte aufrichtig: Dragnuwa, Sadtalker, Aniportrait, Diffusoren, SVD_xtend, bedingte Motion-Propagation und Unimatch.


