ConvRe
1.0.0
- ข้อมูล |? รหัส |? HuggingFace Loadboard |? กระดาษ |

- ตัว ? เป็นมาตรฐานที่เสนอในรายงานการประชุมหลัก EMNLP 2023 ของเรา: การสอบสวนความไร้ประสิทธิภาพของ LLMS ในการทำความเข้าใจ ความ เชื่อมั่น อีกครั้ง มันมีจุดมุ่งหมายเพื่อประเมินความสามารถของ LLMs ในการทำความเข้าใจความสัมพันธ์แบบสนทนา ความสัมพันธ์แบบสนทนาถูกกำหนดให้เป็นสิ่งที่ตรงกันข้ามกับความสัมพันธ์ทางความหมายในขณะที่รักษารูปแบบพื้นผิวของสามสามไม่เปลี่ยนแปลง ตัวอย่างเช่นสาม (x, has part, y) ถูกตีความว่า "x มีส่วนที่เรียกว่า y" ในความสัมพันธ์ปกติในขณะที่ "y มีส่วนที่เรียกว่า x" ในความสัมพันธ์สนทนา?
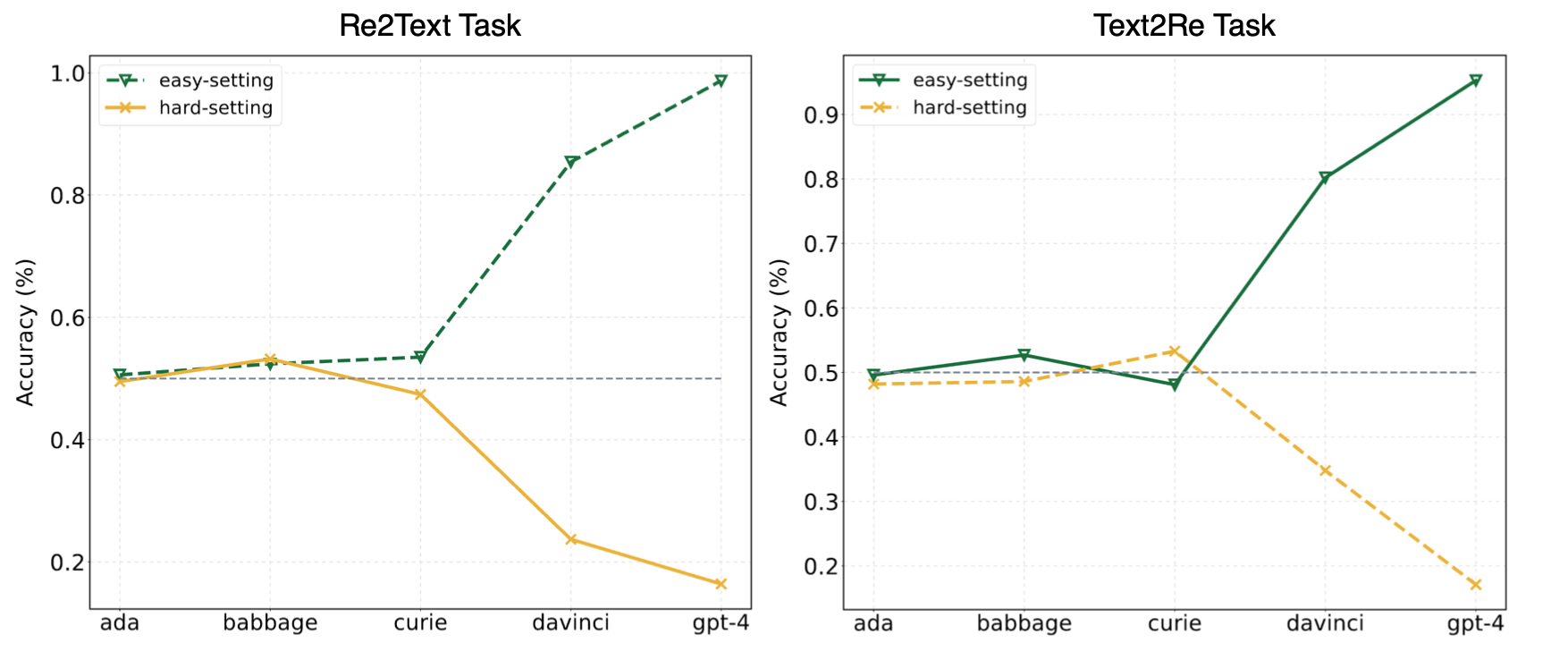
การทดลองในบทความของเราชี้ให้เห็นว่า LLM มักจะหันไปเรียนรู้ทางลัด (หรือสหสัมพันธ์ผิวเผิน) และยังคงเผชิญกับความท้าทายในการควบคุมของเรา? เกณฑ์มาตรฐานแม้สำหรับรุ่นที่ทรงพลังเช่น GPT-4 ภาพต่อไปนี้แสดงการแสดงของรุ่น GPT ภายใต้การตั้งค่าที่ง่าย/ยากบนเกณฑ์มาตรฐานของเรา สามารถสังเกตได้ว่าทั้งในงาน Re2Text และ Text2Re โมเดล GPT แสดงแนวโน้มการปรับขนาดที่เป็นบวกภายใต้การตั้งค่าที่ง่ายและแนวโน้มการปรับสเกลผกผันภายใต้การตั้งค่ายาก กรุณาตรวจสอบกระดาษของเรา? หรือ HuggingFace Lederboard? สำหรับผลลัพธ์ที่ละเอียดและครอบคลุมเพิ่มเติม
อ่านสิ่งนี้ใน中文
เกณฑ์มาตรฐานของ Convre ประกอบด้วย 17 ความสัมพันธ์และ 1240 อเนกประสงค์จากชุดข้อมูลกราฟความรู้ที่ใช้กันอย่างแพร่หลายห้าชุด: WN18RR, FB15K-237, Nell-One, Wikidata5M, ICEWS14, ConceptNet5 จำนวนรายละเอียดจำนวนสามเท่าสำหรับแต่ละความสัมพันธ์ในเกณฑ์มาตรฐานแสดงอยู่ด้านล่าง
| ความสัมพันธ์ | # triples | แหล่งที่มา |
|---|---|---|
| hypernym | 80 | WN18RR |
| มีส่วน | 78 | WN18RR |
| องค์กรความสัมพันธ์ขององค์กรเด็ก | 75 | FB15K-237 |
| สถานที่ตั้งมีบางส่วนมี | 77 | FB15K-237 |
| นักกีฬาเอาชนะนักกีฬา | 80 | เนลล์ |
| ผู้ปกครองของ | 145 | nell-one & wikidata5m |
| แสดงโดย | 79 | Wikidata5m |
| ผลข้างเคียง | 8 | Wikidata5m |
| มีสิ่งอำนวยความสะดวก | 62 | Wikidata5m |
| ได้รับอิทธิพลจาก | 65 | Wikidata5m |
| เป็นของ | 51 | Wikidata5m |
| ปรึกษา | 73 | ICEWS14 |
| สรรเสริญหรือรับรอง | 78 | ICEWS14 |
| ทำจาก | 80 | ConceptNet5 |
| ใช้ | 79 | ConceptNet5 |
| มีทรัพย์สิน | 55 | ConceptNet5 |
| มี subevent | 75 | ConceptNet5 |
| ทั้งหมด | 1240 |
ไฟล์ชุดข้อมูลสามารถพบได้ในไดเรกทอรี data นี่คือคำอธิบายของแต่ละไฟล์
re2text_relations.json : คำจำกัดความความสัมพันธ์ปกติและการสนทนาและตัวเลือกที่สอดคล้องกันของแต่ละความสัมพันธ์สำหรับงาน re2textre2text_examples.json : ตัวอย่างการถ่ายทำสองสามตัวอย่างของงาน re2text รวมถึงการตั้งค่าพรอมต์ normal และการตั้งค่า hint+cottext2re_relations : คำจำกัดความความสัมพันธ์ปกติและการสนทนาและตัวเลือกที่สอดคล้องกันของแต่ละความสัมพันธ์สำหรับงาน text2retext2re_examples.json : ตัวอย่างไม่กี่ตัวอย่างของงาน re2text รวมถึงการตั้งค่าพรอมต์ normal และการตั้งค่า hint+cottriple_dataset : ชุดข้อมูลเต็มรูปแบบของเบนช์มาร์กรวมถึงสามและคำตอบที่ถูกต้องtriple_subset : ชุดย่อยที่เราใช้ในกระดาษของเรามันมี 328 triples และคำตอบที่ถูกต้องที่สอดคล้องกัน โมเดลที่แสดงด้านล่างได้รับการทดสอบและสามารถเรียกใช้โดยตรงโดยใช้สคริปต์ในการอนุมาน
รุ่นข้อความ GPT
Claude Models
รุ่น Flan-T5
Llama2 แชทโมเดล
Qwen Chat Models
โมเดล internlm
เกณฑ์มาตรฐานของเรามีให้ใน HuggingFace หรือไม่? (ลิงก์) คุณสามารถเรียกใช้การอนุมานได้อย่างง่ายดายโดยใช้ main_hf.py และระบุอาร์กิวเมนต์สามข้อต่อไปนี้
model_name : ชื่อของโมเดลภาษาขนาดใหญ่ดูรายการโมเดลที่เรารองรับtask : ภารกิจย่อยของเกณฑ์มาตรฐาน Convre: text2re หรือ re2textsetting : การตั้งค่าพรอมต์สำหรับการรันปัจจุบัน (พรอมต์ 1-prompt 12) โปรดดูที่กระดาษ (ลิงก์) ของเราสำหรับรายละเอียดเพิ่มเติมของการตั้งค่าแต่ละครั้งตัวอย่าง
นี่คือสคริปต์ที่จะเรียกใช้งาน prompt4 ของงาน re2text บน text-davinci-003 ?
python3 main_hf.py --model_name text-davinci-003 --task re2text --setting prompt4นอกจากนี้เรายังให้วิธีที่ยืดหยุ่นมากขึ้นในการทดลองใช้ มีอาร์กิวเมนต์️eightที่คุณต้องระบุ
model_name : ชื่อของโมเดลภาษาขนาดใหญ่ที่คุณต้องการใช้ดูรายการโมเดลที่เรารองรับtask : ภารกิจย่อยของเกณฑ์มาตรฐาน Convre: text2re หรือ re2textdata_dir : ไดเรกทอรีที่ชุดข้อมูลเก็บไว้prompt : ประเภทของพรอมต์ที่จะใช้ในการทดลอง: normal hint หรือ hint+cotrelation : ประเภทความสัมพันธ์ที่จะใช้ในการทดลอง: normal สำหรับความสัมพันธ์ปกติและ converse สำหรับความสัมพันธ์สนทนาn_shot : หมายเลขไม่กี่นัดเลือกตัวเลขใน [0, 1, 2, 3, 4, 5, 6]example_type : ประเภทของตัวอย่างไม่กี่ตัวอย่าง hard หรือ regulartext_type : ประเภทของข้อความที่ใช้ในการทดสอบ regular หรือ hardการตั้งค่าอาร์กิวเมนต์สำหรับพรอมต์ 12 รายการที่ใช้ในกระดาษของเราแสดงอยู่ด้านล่าง
| ID แจ้งเตือน | แจ้ง | ความสัมพันธ์ | n_shot | ตัวอย่าง _type | text_type |
|---|---|---|---|---|---|
| re2text 1# | ปกติ | ปกติ | 0 | ปกติ | ปกติ |
| Text2RE 1# | ปกติ | ปกติ | 0 | ปกติ | แข็ง |
| re2text 2# | ปกติ | ปกติ | 0 | ปกติ | แข็ง |
| Text2RE 2# | ปกติ | ปกติ | 0 | ปกติ | ปกติ |
| re2text 3# | ปกติ | สนทนา | 0 | ปกติ | ปกติ |
| Text2RE 3# | ปกติ | สนทนา | 0 | ปกติ | แข็ง |
| re2text 4# | ปกติ | สนทนา | 0 | ปกติ | แข็ง |
| Text2RE 4# | ปกติ | สนทนา | 0 | ปกติ | ปกติ |
| re2text 5# | คำใบ้ | สนทนา | 0 | ปกติ | ปกติ |
| Text2RE 5# | คำใบ้ | สนทนา | 0 | ปกติ | แข็ง |
| re2text 6# | คำใบ้ | สนทนา | 0 | ปกติ | แข็ง |
| Text2RE 6# | คำใบ้ | สนทนา | 0 | ปกติ | ปกติ |
| 7# | ปกติ | สนทนา | 3 | แข็ง | แข็ง |
| 8# | คำใบ้+เปล | สนทนา | 3 | แข็ง | แข็ง |
| 9# | ปกติ | สนทนา | 6 | แข็ง | แข็ง |
| 10# | ปกติ | สนทนา | 3 | ปกติ | แข็ง |
| 11# | คำใบ้+เปล | สนทนา | 3 | ปกติ | แข็ง |
| 12# | ปกติ | สนทนา | 6 | ปกติ | แข็ง |
ตัวอย่าง
นี่คือสคริปต์ที่จะเรียกใช้งาน prompt3 ของงาน text2re บน gpt-3.5-turbo-0301 ?
python3 main.py --model_name gpt-3.5-turbo-0301 --task text2re --data_dir data --prompt normal --relation converse --n_shot 0 --example_type regular --text_type hardจำเป็นต้องระบุอาร์กิวเมนต์สามข้อเมื่อเรียกใช้สคริปต์การประเมินผล
file_path : path ของไฟล์ผลลัพธ์?model_family : ตระกูลโมเดลของไฟล์ผลลัพธ์ที่ใช้เลือกผู้ประเมินที่เกี่ยวข้อง คุณควรเลือกจาก flan-t5 , claude , gpt-text , gpt-chat , llama2 , qwen , internlmmode : เรามีโหมดการประเมินสองโหมด: strict และ auto โหมด strict จะเพิ่มข้อผิดพลาดหากคำตอบของโมเดลไม่สอดคล้องกับสิ่งที่เราต้องการ ในกรณีนี้คุณควรตรวจสอบคำตอบของโมเดลด้วยตนเอง โหมด auto จะไม่สนใจคำตอบที่ไม่สอดคล้องกัน ประสิทธิภาพที่คำนวณได้ภายใต้โหมด auto อาจต่ำกว่าโหมด strict แต่ก็สะดวกมากและไม่ต้องการการสนับสนุนจากมนุษย์ ความสามารถในการจัดตำแหน่งกับคำขอของผู้ใช้ก็เป็นตัวบ่งชี้ที่สำคัญมากเกี่ยวกับความสามารถของ LLMS ประการแรกคุณควรสร้างคลาสใหม่ที่สืบทอด LanguageModels ใน llms_interface.py จากนั้นใช้วิธี completion ตามลักษณะ (เช่นโครงสร้างของ API ของโมเดลใหม่) ของโมเดลของคุณ
หลังจากได้รับผลลัพธ์คุณควรสร้างคลาสใหม่ที่สืบทอด BaseEvaluator ใน llms_evaluator.py จากนั้นใช้วิธี evaluate ตามรูปแบบของคำตอบของโมเดลของคุณ
ในการเพิ่มความสัมพันธ์ใหม่ในเกณฑ์มาตรฐานคุณควรตรวจสอบก่อนว่าความสัมพันธ์ตรงตามข้อกำหนดใน Section 2.5 ของบทความของเราหรือไม่ จากนั้นคุณควรเขียนพรอมต์ที่เกี่ยวข้องสำหรับงาน Re2Text และ Text2Re
re2text
หมายเหตุ: ในงานนี้คำถามทั้งหมดกำลังขอหัว
normal : คำสั่ง normal ของความสัมพันธ์converse : คำสั่ง converse ของ Relaitonnormal-regular : คำอธิบาย regular สำหรับคำถามภายใต้ความสัมพันธ์ normalnormal-hard : คำอธิบาย hard สำหรับคำถามภายใต้ความสัมพันธ์ normalconverse-regular : คำอธิบาย regular สำหรับคำถามภายใต้ความสัมพันธ์แบบ converseconverse-hard : คำอธิบาย hard สำหรับคำถามภายใต้ความสัมพันธ์แบบ converseText2RE
normal : คำสั่ง normal ของความสัมพันธ์converse : คำสั่ง converse ของ Relonhard : คำอธิบาย hard ของคำถามregular : คำอธิบาย regular ของคำถามnormal-correct : ตัวเลือก correct ภายใต้ความสัมพันธ์ normalnormal-wrong : ตัวเลือก wrong ภายใต้ความสัมพันธ์ normalconverse-correct : ตัวเลือก correct ภายใต้ความสัมพันธ์ converseconverse-wrong : ทางเลือก wrong ภายใต้ความสัมพันธ์แบบ converseอย่าลังเลที่จะเพิ่มโมเดลและความสัมพันธ์ใหม่ให้กับเกณฑ์มาตรฐานของเรา?
@misc{qi2023investigation,
title={An Investigation of LLMs' Inefficacy in Understanding Converse Relations},
author={Chengwen Qi and Bowen Li and Binyuan Hui and Bailin Wang and Jinyang Li and Jinwang Wu and Yuanjun Laili},
year={2023},
eprint={2310.05163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


