ConvRe
1.0.0
? ¿Datos |? Código |? ¿Board de clasificación de la cara de abrazo |? Papel |

? ¿ CONDICIÓN ? es el punto de referencia propuesto en nuestro documento de conferencia principal de EMNLP 2023: una investigación de la ineficacia de LLMS para comprender las convenciones . Su objetivo es evaluar la capacidad de las LLM para comprender las relaciones conversadoras. La relación conversadora se define como lo opuesto a la relación semántica mientras mantiene la forma superficial del triple sin cambios. Por ejemplo, el triple (x, has part, y) se interpreta como "x tiene una parte llamada y" en relación normal, mientras que "y tiene una parte llamada x" en relación converse?
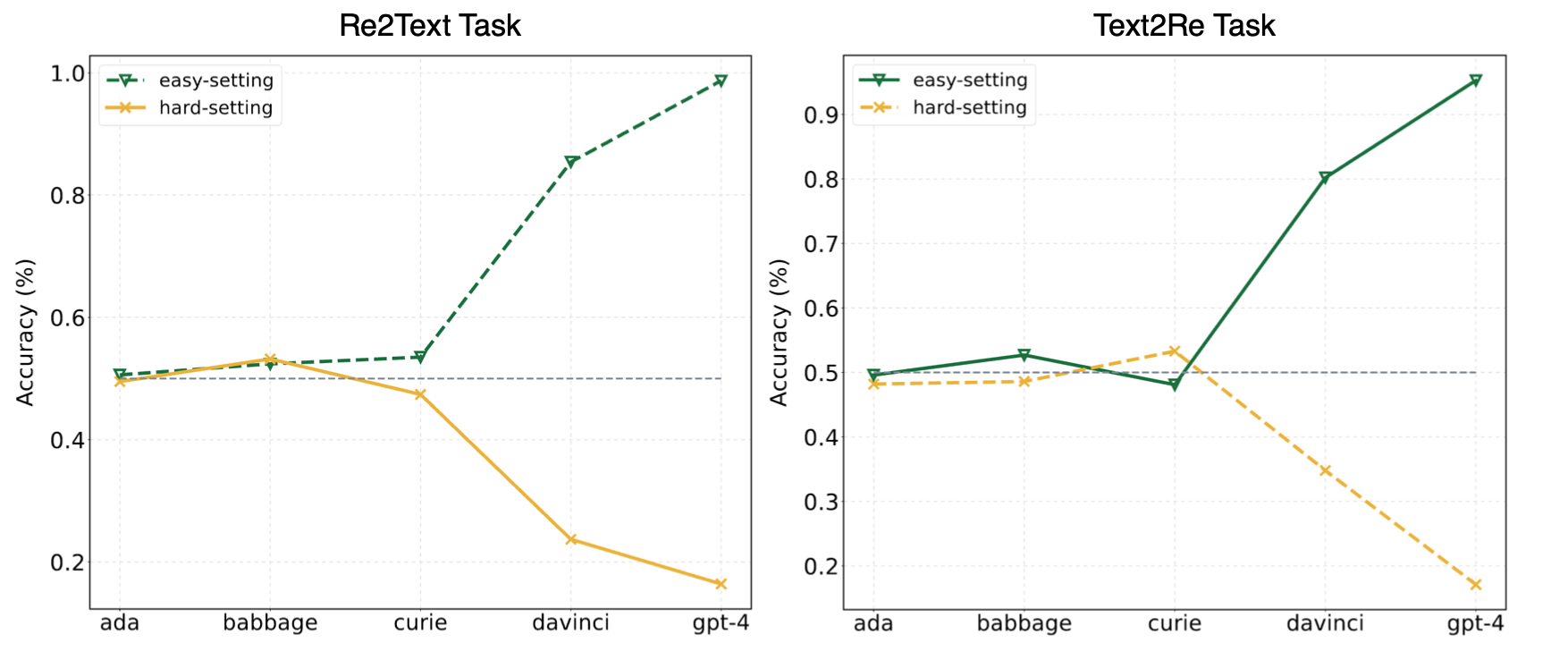
Los experimentos en nuestro artículo sugirieron que los LLM a menudo recurren al aprendizaje de atajos (o correlaciones superficiales) y aún enfrentan desafíos en nuestro? Benchmark incluso para modelos poderosos como GPT-4. La siguiente imagen muestra las actuaciones de los modelos GPT bajo configuraciones fáciles/duras en nuestro punto de referencia. Se puede observar que tanto en las tareas Re2Text y Text2Re , los modelos GPT exhiben una tendencia de escala positiva bajo tendencia de escala fácil y de escala inversa bajo el resumen. Por favor revise nuestro papel? ¿O la tabla de clasificación de la cara de Hugging? Para resultados más detallados e integrales.
Lea esto en 中文.
Benchmark de Convre está compuesto por 17 relaciones y 1240 triples de cinco conjuntos de datos de gráficos de conocimiento ampliamente utilizados: WN18RR, FB15K-237, Nell-One, Wikidata5M, ICEWS14, ConceptNet5. El número detallado de triples para cada relación en el punto de referencia se enumera a continuación.
| Relación | # Triples | Fuente |
|---|---|---|
| hipernym | 80 | WN18RR |
| tiene parte | 78 | WN18RR |
| organización, relación de organización, niño | 75 | FB15K-237 |
| ubicación, ubicación, contiene parcialmente | 77 | FB15K-237 |
| atleta venció al atleta | 80 | Nell-uno |
| padre de | 145 | Nell-one y wikidata5m |
| representado por | 79 | Wikidata5m |
| efecto secundario | 8 | Wikidata5m |
| tiene instalación | 62 | Wikidata5m |
| influenciado por | 65 | Wikidata5m |
| poseído por | 51 | Wikidata5m |
| consultar | 73 | ICEWS14 |
| alabanza o respaldar | 78 | ICEWS14 |
| hecho de | 80 | Conceptnet5 |
| utilizado de | 79 | Conceptnet5 |
| tiene propiedad | 55 | Conceptnet5 |
| tiene subeventamiento | 75 | Conceptnet5 |
| Total | 1240 |
Los archivos del conjunto de datos se pueden encontrar en el directorio data . Aquí está la descripción de cada archivo.
re2text_relations.json : la definición de relación normal y conversadora y las opciones correspondientes de cada relación para la tarea re2text .re2text_examples.json : los pocos ejemplos de tomas de la tarea re2text , incluida la configuración de solicitud normal y la configuración de hint+cot .text2re_relations : la definición de relación normal y conversadora y las opciones correspondientes de cada relación para la tarea text2re .text2re_examples.json : los pocos ejemplos de tomas de la tarea re2text , incluida la configuración de solicitud normal y la configuración de hint+cot .triple_dataset : conjunto de datos completo del punto de referencia, incluidos triples y respuestas correctas.triple_subset : el subconjunto que utilizamos en nuestro artículo, contiene 328 triples y sus respuestas correctas correspondientes. Los modelos enumerados a continuación se prueban y se pueden ejecutar directamente utilizando el script en inferencia.
Modelos de texto GPT
Modelos Claude
Modelos flan-t5
Modelos de chat de Llama2
Modelos de chat de Qwen
Modelos de Internlm
¿Nuestro punto de referencia está disponible en Huggingface? (enlace). Puede ejecutar fácilmente la inferencia usando main_hf.py y especificando los siguientes tres argumentos.
model_name : el nombre del modelo de idioma grande, consulte nuestra lista de modelos compatibles.task : la subtarea de Convre Benchmark: text2re o re2text .setting : Configuración de indicación para la ejecución actual (indic1-prompt 12), consulte nuestro documento (enlace) para obtener más detalles de cada configuración.Ejemplo
¿Aquí está el script para ejecutar la Tarea de prompt4 de re2text en text-davinci-003 ?
python3 main_hf.py --model_name text-davinci-003 --task re2text --setting prompt4También proporcionamos una forma más flexible de ejecutar los experimentos. Hay en cuenta los argumentos que necesita especificar.
model_name : el nombre del modelo de idioma grande que desea usar, consulte nuestra lista de modelos compatibles.task : la subtarea de Convre Benchmark: text2re o re2text .data_dir : el directorio donde se almacenaba el conjunto de datos.prompt : el tipo de indicador que se puede usar en el experimento: normal , hint o hint+cot .relation : el tipo de relación que se usa en el experimento: normal para la relación normal y converse para la relación conversadora.n_shot : pocos números de disparo, elija un número en [0, 1, 2, 3, 4, 5, 6].example_type : el tipo de ejemplos de pocos disparos, hard o regular .text_type : el tipo de texto que se puede usar en el experimento, regular o hard .La configuración del argumento para cada uno de los 12 avisos utilizados en nuestro documento se enumera a continuación.
| ID de inmediato | inmediato | relación | n_shot | Ejemplo_type | text_type |
|---|---|---|---|---|---|
| RE2Text 1# | normal | normal | 0 | regular | regular |
| text2re 1# | normal | normal | 0 | regular | duro |
| RE2Text 2# | normal | normal | 0 | regular | duro |
| text2re 2# | normal | normal | 0 | regular | regular |
| RE2Text 3# | normal | conversar | 0 | regular | regular |
| text2re 3# | normal | conversar | 0 | regular | duro |
| RE2Text 4# | normal | conversar | 0 | regular | duro |
| text2re 4# | normal | conversar | 0 | regular | regular |
| RE2Text 5# | pista | conversar | 0 | regular | regular |
| text2re 5# | pista | conversar | 0 | regular | duro |
| RE2Text 6# | pista | conversar | 0 | regular | duro |
| text2re 6# | pista | conversar | 0 | regular | regular |
| 7# | normal | conversar | 3 | duro | duro |
| 8# | Sugerencia+cuna | conversar | 3 | duro | duro |
| 9# | normal | conversar | 6 | duro | duro |
| 10# | normal | conversar | 3 | regular | duro |
| 11# | Sugerencia+cuna | conversar | 3 | regular | duro |
| 12# | normal | conversar | 6 | regular | duro |
Ejemplo
¿Aquí está el script para ejecutar la Tarea de prompt3 de text2re en gpt-3.5-turbo-0301 ?
python3 main.py --model_name gpt-3.5-turbo-0301 --task text2re --data_dir data --prompt normal --relation converse --n_shot 0 --example_type regular --text_type hardDeben especificarse tres argumentos al ejecutar el script de evaluación.
file_path : ¿la path del archivo de resultados?model_family : la familia modelo del archivo de resultados, utilizado para elegir el evaluador correspondiente. Debe elegir entre flan-t5 , claude , gpt-text , gpt-chat , llama2 , qwen , internlm .mode : Proporcionamos dos modos de evaluación: strict y auto . El modo strict aumentará los errores si la respuesta del modelo no es consistente con lo que queremos. En este caso, debe verificar la respuesta del modelo manualmente. El modo auto solo ignorará las respuestas inconsistentes. El rendimiento calculado en modo auto puede ser más bajo que el modo strict , pero es muy conveniente y no necesita ningún soporte humano. La capacidad de alinearse con la solicitud del usuario también es un indicador muy importante de la capacidad de LLMS. En primer lugar, debe crear una nueva clase que herede LanguageModels en llms_interface.py , y luego implementar el método completion de acuerdo con las características (como la estructura de la API del nuevo modelo) de su modelo.
Después de obtener el resultado, debe crear una nueva clase que herede BaseEvaluator en llms_evaluator.py , y luego implementar el método evaluate de acuerdo con el patrón de la respuesta de su modelo.
Para agregar una nueva relación en el punto de referencia, primero debe verificar si la relación cumple con los requisitos en Section 2.5 de nuestro documento. Luego debe escribir las indicaciones correspondientes para las tareas Re2Text y Text2Re .
RE2Text
Nota: En esta tarea, toda la pregunta es pedir entidad principal.
normal : la instrucción normal de la relación.converse : la instrucción converse del Relaiton.normal-regular : la descripción regular de la pregunta bajo relación normal .normal-hard : la descripción hard de la pregunta bajo relación normal .converse-regular : la descripción regular de la pregunta bajo relación converse .converse-hard : la descripción hard para la pregunta bajo relación converse .Text2re
normal : la instrucción normal de la relación.converse : la instrucción converse del relatón.hard : la descripción hard de la pregunta.regular : la descripción regular de la pregunta.normal-correct : la elección correct bajo relación normal .normal-wrong : la elección wrong bajo relación normal .converse-correct : la elección correct bajo relación converse .converse-wrong : la elección wrong bajo relación converse .¿Siéntase libre de agregar nuevos modelos y relaciones a nuestro punto de referencia?
@misc{qi2023investigation,
title={An Investigation of LLMs' Inefficacy in Understanding Converse Relations},
author={Chengwen Qi and Bowen Li and Binyuan Hui and Bailin Wang and Jinyang Li and Jinwang Wu and Yuanjun Laili},
year={2023},
eprint={2310.05163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


