ConvRe
1.0.0
? Data |? Kode |? Papan peringkat pelukan |? Kertas |

? Convre ? adalah tolok ukur yang diusulkan dalam makalah konferensi utama EMNLP 2023 kami: Investigasi ketidakefisienan LLMS dalam memahami konvensional . Ini bertujuan untuk mengevaluasi kemampuan LLMS dalam memahami hubungan yang sebaliknya. Hubungan Converse didefinisikan sebagai kebalikan dari hubungan semantik sambil menjaga bentuk permukaan tiga tidak berubah. Misalnya, triple (x, has part, y) ditafsirkan sebagai "x memiliki bagian yang disebut y" dalam hubungan normal, sedangkan "y memiliki bagian yang disebut x" dalam hubungan yang lebih tinggi?
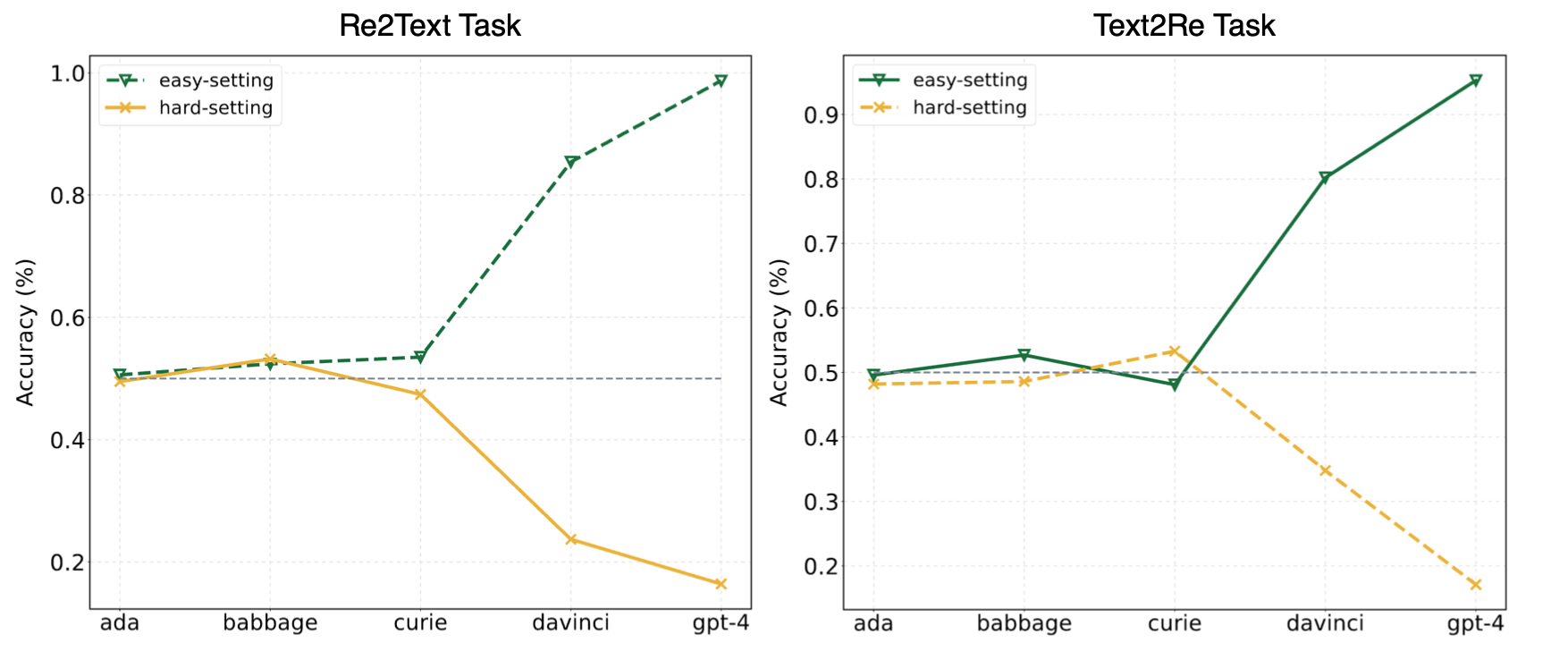
Eksperimen dalam makalah kami menyarankan agar LLM sering menggunakan pembelajaran pendek (atau korelasi superfisial) dan masih menghadapi tantangan di? Convre? Benchmark bahkan untuk model yang kuat seperti GPT-4. Gambar berikut ini menunjukkan kinerja model GPT di bawah pengaturan mudah/keras Zero-shot di tolok ukur kami. Dapat diamati bahwa baik dalam tugas Re2Text dan Text2Re , model GPT menunjukkan tren penskalaan positif di bawah pengaturan yang mudah, dan tren penskalaan terbalik di bawah pengaturan keras. Silakan periksa kertas kami? atau huggingface leaderboard? untuk hasil yang lebih rinci dan komprehensif.
Baca ini di 中文.
Benchmark Convre terdiri dari 17 hubungan dan 1240 tiga kali lipat dari lima dataset grafik pengetahuan yang banyak digunakan: WN18RR, FB15K-237, Nell-One, Wikidata5m, ICEWS14, ConceptNet5. Jumlah rinci tiga kali lipat untuk setiap hubungan dalam tolok ukur tercantum di bawah ini.
| Hubungan | # Tiga kali lipat | Sumber |
|---|---|---|
| hypernym | 80 | WN18RR |
| memiliki bagian | 78 | WN18RR |
| organisasi, hubungan organisasi, anak | 75 | FB15K-237 |
| lokasi, lokasi, sebagian berisi | 77 | FB15K-237 |
| Atlet mengalahkan atlet | 80 | Nell-one |
| induk dari | 145 | Nell-One & Wikidata5m |
| diwakili oleh | 79 | Wikidata5m |
| efek samping | 8 | Wikidata5m |
| memiliki fasilitas | 62 | Wikidata5m |
| dipengaruhi oleh | 65 | Wikidata5m |
| dimiliki oleh | 51 | Wikidata5m |
| berkonsultasi | 73 | Icews14 |
| pujian atau mendukung | 78 | Icews14 |
| terbuat dari | 80 | ConceptNet5 |
| digunakan | 79 | ConceptNet5 |
| memiliki properti | 55 | ConceptNet5 |
| memiliki subevent | 75 | ConceptNet5 |
| Total | 1240 |
File dataset dapat ditemukan di direktori data . Berikut ini deskripsi setiap file.
re2text_relations.json : Definisi relasi normal dan konvers dan pilihan yang sesuai dari setiap hubungan untuk tugas re2text .re2text_examples.json : Beberapa contoh bidikan tugas re2text , termasuk pengaturan prompt normal dan pengaturan hint+cot .text2re_relations : Definisi relasi normal dan konvers dan pilihan yang sesuai dari setiap hubungan untuk tugas text2re .text2re_examples.json : Beberapa contoh bidikan dari tugas re2text , termasuk pengaturan prompt normal dan pengaturan hint+cot .triple_dataset : Dataset lengkap tolok ukur, termasuk tiga kali lipat dan jawaban yang benar.triple_subset : Subset yang kami gunakan dalam makalah kami, berisi 328 tiga kali lipat dan jawaban yang benar yang sesuai. Model yang tercantum di bawah ini diuji dan dapat dijalankan secara langsung menggunakan skrip dalam inferensi.
Model teks GPT
Model Claude
Model Flan-T5
Model obrolan llama2
Model obrolan qwen
Model internlm
Benchmark kami tersedia di Huggingface? (link). Anda dapat dengan mudah menjalankan inferensi dengan menggunakan main_hf.py dan menentukan tiga argumen berikut.
model_name : Nama model bahasa besar, lihat daftar model yang didukung kami.task : Subtask of Convre Benchmark: text2re atau re2text .setting : Pengaturan Prompt untuk Jalankan Saat Ini (Prompt1-Prompt 12), silakan merujuk ke makalah kami (tautan) untuk detail lebih lanjut dari setiap pengaturan.Contoh
Berikut adalah skrip untuk menjalankan prompt4 dari tugas re2text pada text-davinci-003 ?
python3 main_hf.py --model_name text-davinci-003 --task re2text --setting prompt4Kami juga memberikan cara yang lebih fleksibel untuk menjalankan eksperimen. Ada argumen John yang perlu Anda tentukan.
model_name : Nama model bahasa besar yang ingin Anda gunakan, lihat daftar model yang didukung kami.task : Subtask of Convre Benchmark: text2re atau re2text .data_dir : Direktori tempat dataset disimpan.prompt : Jenis prompt untuk digunakan dalam percobaan: normal , hint atau hint+cot .relation : Jenis hubungan yang akan digunakan dalam percobaan: normal untuk hubungan normal dan converse untuk hubungan yang berkaitan.n_shot : beberapa nomor shot, pilih angka di [0, 1, 2, 3, 4, 5, 6].example_type : Jenis contoh beberapa tembakan, hard atau regular .text_type : Jenis teks yang akan digunakan dalam percobaan, regular atau hard .Pengaturan argumen untuk masing -masing dari 12 prompt yang digunakan dalam makalah kami tercantum di bawah ini.
| ID Prompt | mengingatkan | hubungan | n_shot | example_type | text_type |
|---|---|---|---|---|---|
| Re2Text 1# | normal | normal | 0 | biasa | biasa |
| text2re 1# | normal | normal | 0 | biasa | keras |
| Re2Text 2# | normal | normal | 0 | biasa | keras |
| text2re 2# | normal | normal | 0 | biasa | biasa |
| Re2Text 3# | normal | berbicara | 0 | biasa | biasa |
| text2re 3# | normal | berbicara | 0 | biasa | keras |
| Re2Text 4# | normal | berbicara | 0 | biasa | keras |
| text2re 4# | normal | berbicara | 0 | biasa | biasa |
| Re2Text 5# | petunjuk | berbicara | 0 | biasa | biasa |
| text2re 5# | petunjuk | berbicara | 0 | biasa | keras |
| Re2Text 6# | petunjuk | berbicara | 0 | biasa | keras |
| text2re 6# | petunjuk | berbicara | 0 | biasa | biasa |
| 7# | normal | berbicara | 3 | keras | keras |
| 8# | Petunjuk+Cot | berbicara | 3 | keras | keras |
| 9# | normal | berbicara | 6 | keras | keras |
| 10# | normal | berbicara | 3 | biasa | keras |
| 11# | Petunjuk+Cot | berbicara | 3 | biasa | keras |
| 12# | normal | berbicara | 6 | biasa | keras |
Contoh
Berikut adalah skrip untuk menjalankan prompt3 dari text2re Task di gpt-3.5-turbo-0301 ?
python3 main.py --model_name gpt-3.5-turbo-0301 --task text2re --data_dir data --prompt normal --relation converse --n_shot 0 --example_type regular --text_type hardAda tiga argumen yang perlu ditentukan saat menjalankan skrip evaluasi.
file_path : path dari file hasil ?.model_family : Keluarga model file hasil, yang digunakan untuk memilih evaluator yang sesuai. Anda harus memilih dari flan-t5 , claude , gpt-text , gpt-chat , llama2 , qwen , internlm .mode : Kami menyediakan dua mode evaluasi: strict dan auto . Mode strict akan meningkatkan kesalahan jika jawaban model tidak konsisten dengan apa yang kita inginkan. Dalam hal ini, Anda harus memeriksa jawaban model secara manual. Mode auto hanya akan mengabaikan jawaban yang tidak konsisten. Kinerja yang dihitung dalam mode auto mungkin lebih rendah dari mode strict , tetapi sangat nyaman dan tidak memerlukan dukungan manusia. Kemampuan untuk menyelaraskan dengan permintaan pengguna juga merupakan indikator yang sangat penting dari kemampuan LLMS. Pertama, Anda harus membuat kelas baru yang mewarisi LanguageModels di llms_interface.py , dan kemudian mengimplementasikan metode completion sesuai dengan karakteristik (seperti struktur API model baru) dari model Anda.
Setelah mendapatkan hasilnya, Anda harus membuat kelas baru yang mewarisi BaseEvaluator di llms_evaluator.py , dan kemudian mengimplementasikan metode evaluate sesuai dengan pola jawaban model Anda.
Untuk menambahkan hubungan baru dalam tolok ukur, Anda harus terlebih dahulu memeriksa apakah hubungan tersebut memenuhi persyaratan di Section 2.5 dari makalah kami. Maka Anda harus menulis prompt yang sesuai untuk tugas Re2Text dan Text2Re .
Re2text
Catatan: Dalam tugas ini, semua pertanyaan meminta entitas kepala.
normal : Instruksi normal dari hubungan.converse : Instruksi converse dari Relaiton.normal-regular : Deskripsi regular untuk pertanyaan di bawah hubungan normal .normal-hard : Deskripsi hard untuk pertanyaan di bawah hubungan normal .converse-regular : Deskripsi regular untuk pertanyaan di bawah hubungan converse .converse-hard : Deskripsi hard untuk pertanyaan di bawah hubungan converse .Text2re
normal : Instruksi normal dari hubungan.converse : Instruksi converse dari Relaton.hard : Deskripsi hard pertanyaan.regular : Deskripsi regular pertanyaan.normal-correct : Pilihan correct di bawah hubungan normal .normal-wrong : Pilihan wrong di bawah hubungan normal .converse-correct : Pilihan correct di bawah hubungan converse .converse-wrong : Pilihan wrong di bawah hubungan converse .Jangan ragu untuk menambahkan model dan hubungan baru ke tolok ukur kami?
@misc{qi2023investigation,
title={An Investigation of LLMs' Inefficacy in Understanding Converse Relations},
author={Chengwen Qi and Bowen Li and Binyuan Hui and Bailin Wang and Jinyang Li and Jinwang Wu and Yuanjun Laili},
year={2023},
eprint={2310.05163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


