ConvRe
1.0.0
?データ|?コード|? Huggingface Leaderboard |?論文|

?コンベア?私たちのEMNLP 2023メイン会議論文で提案されているベンチマーク:LLMSの非効率性の調査における調査の調査。それは、逆の関係を理解するためのLLMSの能力を評価することを目指しています。逆の関係は、トリプルの表面形式を変更せずに保持しながら、意味関係の反対として定義されます。たとえば、トリプル(x, has part, y)は「xにはyと呼ばれる部分があります」と解釈されますが、「yにはxと呼ばれる部分がxと呼ばれています」。
私たちの論文の実験は、LLMがしばしばショートカット学習(または表面的な相関)に頼り、私たちの条約に依然として課題に直面していることを示唆しました。 GPT-4などの強力なモデルでもベンチマーク。次の写真は、ベンチマークのゼロショットEasy/ハード設定の下でのGPTモデルのパフォーマンスを示しています。 Re2TextおよびText2Reタスクの両方で、GPTモデルは、簡単な設定下で正のスケーリング傾向を示すことが観察できます。私たちの論文をチェックしてください?またはハグFaceリーダーボード?より詳細かつ包括的な結果。
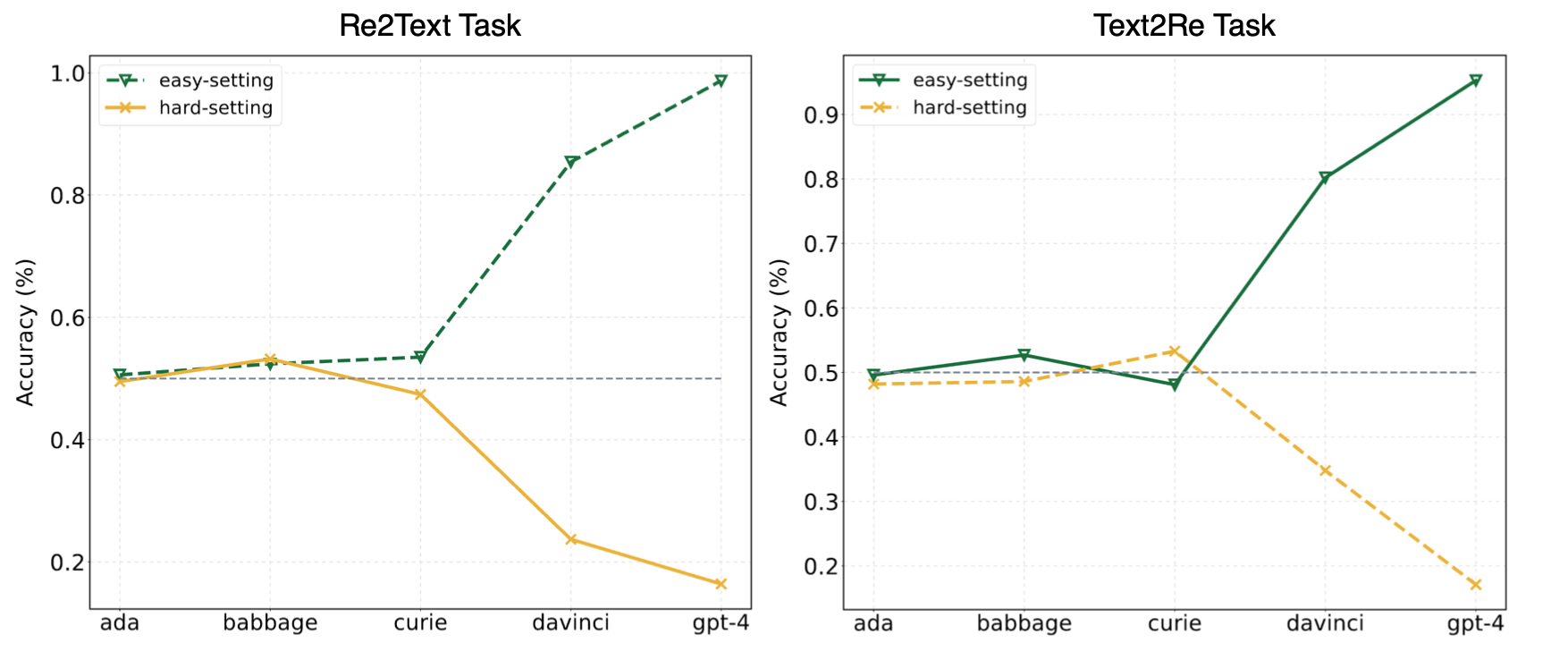
これを中文で読んでください。
Convre Benchmarkは、WN18RR、FB15K-237、Nell-One、Wikidata5M、IceWS14、ConceptNet5の5つの広く使用されているナレッジグラフデータセットからの17の関係と1240トリプルで構成されています。ベンチマーク内の各関係の詳細なトリプルの数を以下に示します。
| 関係 | #トリプル | ソース |
|---|---|---|
| hypernym | 80 | WN18RR |
| 一部があります | 78 | WN18RR |
| 組織、組織関係、子 | 75 | FB15K-237 |
| 場所、場所、部分的に含まれています | 77 | FB15K-237 |
| アスリートはアスリートを破った | 80 | ネル・ワン |
| 親 | 145 | Nell-One&Wikidata5m |
| 代表 | 79 | wikidata5m |
| 副作用 | 8 | wikidata5m |
| 施設があります | 62 | wikidata5m |
| 影響を受けた | 65 | wikidata5m |
| 所有 | 51 | wikidata5m |
| 相談してください | 73 | ICEWS14 |
| 賞賛または支持します | 78 | ICEWS14 |
| でできています | 80 | ConceptNet5 |
| の使用 | 79 | ConceptNet5 |
| 財産があります | 55 | ConceptNet5 |
| サブイベントがあります | 75 | ConceptNet5 |
| 合計 | 1240 |
データセットファイルは、 dataディレクトリにあります。各ファイルの説明は次のとおりです。
re2text_relations.json : re2textタスクの各関係の通常と逆の関係の定義と対応する選択。re2text_examples.json : normalプロンプト設定とhint+cot設定など、 re2textタスクのいくつかのショット例。text2re_relations : text2reタスクの各関係の通常と逆の関係の定義と対応する選択。text2re_examples.json : normalプロンプト設定とhint+cot設定など、 re2textタスクのいくつかのショット例。triple_dataset :トリプルや正解など、ベンチマークの完全なデータセット。triple_subset :私たちの論文で使用したサブセットは、328トリプルとそれに対応する正解が含まれています。 以下にリストされているモデルはテストされており、推論でスクリプトを使用して直接実行できます。
GPTテキストモデル
クロードモデル
Flan-T5モデル
llama2チャットモデル
Qwenチャットモデル
INTENLMモデル
私たちのベンチマークはHuggingfaceで入手できますか? (リンク)。 main_hf.pyを使用して、次の3つの引数を指定することにより、推論を簡単に実行できます。
model_name :大規模な言語モデルの名前、サポートされているモデルリストを参照してください。task :Convre Benchmarkのサブタスク: text2reまたはre2text 。setting :現在の実行のプロンプト設定(Prompt1-Prompt 12)、各設定の詳細については、論文(リンク)を参照してください。例
text-davinci-003でre2textタスクのprompt4を実行するスクリプトは次のとおりですか?
python3 main_hf.py --model_name text-davinci-003 --task re2text --setting prompt4また、実験を実行するためのより柔軟な方法も提供します。指定する必要がある§eight引数があります。
model_name :使用する大規模な言語モデルの名前、サポートされているモデルリストを参照してください。task :Convre Benchmarkのサブタスク: text2reまたはre2text 。data_dir :データセットが保存されているディレクトリ。prompt :実験で使用するプロンプトのタイプ: normal 、 hint 、またはhint+cot 。relation :実験で使用する関係タイプ:通常の関係はnormalであり、逆の関係のためのconverse 。n_shot :数字の数字、[0、1、2、3、4、5、6]で数字を選択します。example_type : hardまたはregular少数のショット例のタイプ。text_type :実験で使用するテキストのタイプ、 regularまたはhard 。私たちの論文で使用されている12のプロンプトのそれぞれの引数設定を以下に示します。
| プロンプトID | プロンプト | 関係 | n_shot | example_type | text_type |
|---|---|---|---|---|---|
| re2text 1# | 普通 | 普通 | 0 | 通常 | 通常 |
| text2re 1# | 普通 | 普通 | 0 | 通常 | 難しい |
| re2text2# | 普通 | 普通 | 0 | 通常 | 難しい |
| text2re 2# | 普通 | 普通 | 0 | 通常 | 通常 |
| re2text 3# | 普通 | コンバース | 0 | 通常 | 通常 |
| text2re 3# | 普通 | コンバース | 0 | 通常 | 難しい |
| re2text4# | 普通 | コンバース | 0 | 通常 | 難しい |
| text2re 4# | 普通 | コンバース | 0 | 通常 | 通常 |
| re2text5# | ヒント | コンバース | 0 | 通常 | 通常 |
| text2re 5# | ヒント | コンバース | 0 | 通常 | 難しい |
| re2text6# | ヒント | コンバース | 0 | 通常 | 難しい |
| text2re 6# | ヒント | コンバース | 0 | 通常 | 通常 |
| 7# | 普通 | コンバース | 3 | 難しい | 難しい |
| 8# | ヒント+ベッド | コンバース | 3 | 難しい | 難しい |
| 9# | 普通 | コンバース | 6 | 難しい | 難しい |
| 10# | 普通 | コンバース | 3 | 通常 | 難しい |
| 11# | ヒント+ベッド | コンバース | 3 | 通常 | 難しい |
| 12# | 普通 | コンバース | 6 | 通常 | 難しい |
例
gpt-3.5-turbo-0301でtext2reタスクのprompt3を実行するスクリプトはありますか?
python3 main.py --model_name gpt-3.5-turbo-0301 --task text2re --data_dir data --prompt normal --relation converse --n_shot 0 --example_type regular --text_type hard評価スクリプトを実行するときに、3つの引数を指定する必要があります。
file_path :結果ファイルのpath ?。model_family :対応する評価者を選択するために使用される結果ファイルのモデルファミリ。 flan-t5 、 claude 、 gpt-text 、 gpt-chat 、 llama2 、 qwen 、 internlmから選択する必要があります。mode : strictとauto 2つの評価モードを提供します。モデルの答えが私たちが望むものと一致しない場合、 strictモードはエラーを引き起こします。この場合、モデルの回答を手動で確認する必要があります。 auto Modeは、一貫性のない回答を無視するだけです。 autoモードで計算されるパフォーマンスは、 strictモードよりも低い場合がありますが、非常に便利で、人間のサポートは必要ありません。ユーザーのリクエストに合わせる機能は、LLMSの機能の非常に重要な指標でもあります。 まず、 llms_interface.pyでLanguageModelsを継承する新しいクラスを作成し、モデルの特性(新しいモデルのAPIの構造など)に従ってcompletion方法を実装する必要があります。
結果を取得した後、 llms_evaluator.pyでBaseEvaluatorを継承する新しいクラスを作成し、モデルの回答のパターンに従ってevaluate方法を実装する必要があります。
ベンチマークに新しい関係を追加するには、まず、関係が論文のSection 2.5の要件を満たしているかどうかを確認する必要があります。次に、 Re2TextとText2Reタスクの両方に対応するプロンプトを記述する必要があります。
re2text
注:このタスクでは、すべての問題がヘッドエンティティを求めることです。
normal :関係のnormal指示。converse :リラートンのconverse指示。normal-regular : normal関係に基づく質問のregular説明。normal-hard : normal関係の下での質問のhard説明。converse-regular : converse関係に基づく質問のregular説明。converse-hard : converse関係に基づく質問のhard説明。text2re
normal :関係のnormal指示。converse :Relatonのconverse指示。hard :質問のhard説明。regular :質問のregular説明。normal-correct : normal関係の下でのcorrect選択。normal-wrong : normal関係の下でのwrong選択。converse-correct : converse関係の下でのcorrect選択。converse-wrong : converse関係の下でのwrong選択。ベンチマークに新しいモデルと関係を自由に追加してください。
@misc{qi2023investigation,
title={An Investigation of LLMs' Inefficacy in Understanding Converse Relations},
author={Chengwen Qi and Bowen Li and Binyuan Hui and Bailin Wang and Jinyang Li and Jinwang Wu and Yuanjun Laili},
year={2023},
eprint={2310.05163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


