ConvRe
1.0.0
? Daten |? Code |? Umarmung der Rangliste |? Papier |

? Überzeugen ? ist der in unserem EMNLP 2023 Hauptkonferenzpapier vorgeschlagene Benchmark: Eine Untersuchung der Ineffizität von LLMs beim Verständnis der Überzeugung . Ziel ist es, die Fähigkeit von LLMs zu bewerten, umgekehrte Beziehungen zu verstehen. Die umgekehrte Beziehung ist definiert als das Gegenteil der semantischen Beziehung, während die Oberflächenform des Dreifach unverändert bleibt. Zum Beispiel wird das Triple (x, has part, y) als "x hat einen Teil y" in normaler Beziehung interpretiert, während "y einen Teil X" in umgekehrter Beziehung namens X hat?
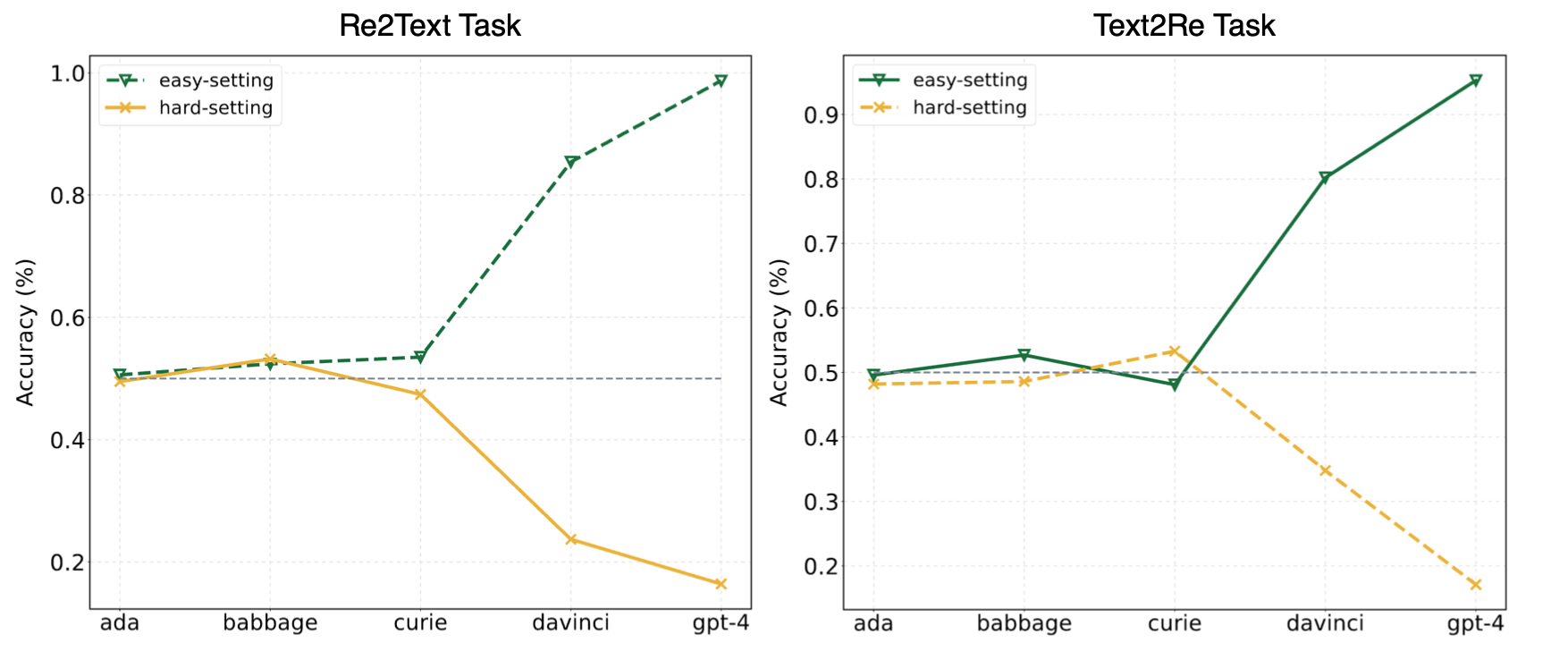
Die Experimente in unserem Artikel deuteten darauf hin, dass LLMs häufig auf Abkürzung (oder oberflächliche Korrelationen) zurückgreifen und dennoch vor Herausforderungen bei unserem überzeugen stehen? Benchmark sogar für mächtige Modelle wie GPT-4. Das folgende Bild zeigt die Leistungen von GPT-Modellen unter Null-Shot-Easy/Hard-Einstellungen auf unserem Benchmark. Es kann beobachtet werden, dass GPT-Modelle sowohl in Re2Text als auch in Text2Re Aufgaben einen positiven Skalierungs-Trend unter leichtem Festlegen und inversen Skalierungstrend unter hartem Festlegen aufweisen. Bitte überprüfen Sie unser Papier. oder Umarmung der Rangliste? Für detailliertere und umfassendere Ergebnisse.
Lesen Sie dies in 中文.
Convre Benchmark besteht aus 17 Beziehungen und 1240 Tripel aus fünf weit verbreiteten Wissensgraphendatensätzen: WN18RR, FB15K-237, Nell-One, Wikidata5M, ICEWS14, CONCECTNET5. Die detaillierte Anzahl von Dreier für jede Beziehung im Benchmark ist unten aufgeführt.
| Beziehung | # Dreifach | Quelle |
|---|---|---|
| Hypernym | 80 | WN18RR |
| hat einen Teil | 78 | WN18RR |
| Organisation, Organisationsbeziehung, Kind | 75 | FB15K-237 |
| Ort, Ort, teilweise enthält | 77 | FB15K-237 |
| Athlet schlug Athlet | 80 | Nell-eins |
| Elternteil von | 145 | Nell-One & Wikidata5m |
| vertreten durch | 79 | Wikidata5m |
| Nebenwirkung | 8 | Wikidata5m |
| hat Einrichtung | 62 | Wikidata5m |
| beeinflusst von | 65 | Wikidata5m |
| im Besitz von | 51 | Wikidata5m |
| konsultieren | 73 | ICEWS14 |
| Lob oder befürworten | 78 | ICEWS14 |
| gemacht aus | 80 | Conceptnet5 |
| verwendet von | 79 | Conceptnet5 |
| hat Eigentum | 55 | Conceptnet5 |
| hat Subenevent | 75 | Conceptnet5 |
| Gesamt | 1240 |
Die Datensatzdateien finden Sie im data . Hier ist die Beschreibung jeder Datei.
re2text_relations.json : Die normale und umgekehrte Beziehungsdefinition und entsprechende Auswahlmöglichkeiten jeder Beziehung für re2text -Aufgabe.re2text_examples.json : Die wenigen Aufgaben Beispiele für re2text -Aufgabe, einschließlich normal Einstellung und hint+cot -Einstellung.text2re_relations : Die normale und umgekehrte Beziehungsdefinition und entsprechende Auswahlmöglichkeiten jeder Beziehung für text2re -Aufgabe.text2re_examples.json : Die wenigen Schussbeispiele für re2text -Aufgabe, einschließlich normal Einstellung und hint+cot -Einstellung.triple_dataset : Voller Datensatz des Benchmarks, einschließlich Dreifachungen und korrekten Antworten.triple_subset : Die Teilmenge, die wir in unserem Papier verwendet haben, enthält 328 Dreifach und ihre entsprechenden korrekten Antworten. Die unten aufgeführten Modelle werden getestet und können direkt unter Verwendung des Skripts in Inferenz ausgeführt werden.
GPT -Textmodelle
Claude -Modelle
FLAN-T5-Modelle
LAMA2 CHAT -Modelle
Qwen Chat -Modelle
Internlmmodelle
Unser Benchmark ist bei Huggingface erhältlich? (Link). Sie können die Inferenz einfach mit main_hf.py ausführen und die folgenden drei Argumente angeben.
model_name : Der Name des großen Sprachmodells siehe unsere unterstützte Modellliste.task : Die Subtask von Convre Benchmark: text2re oder re2text .setting : Eingabeaufforderung für den aktuellen Lauf (Eingabeaufforderung1-Prompt 12) finden Sie in unserem Artikel (Link) für weitere Informationen zu jeder Einstellung.Beispiel
Hier ist das Skript, um prompt4 der re2text Aufgabe in text-davinci-003 auszuführen?
python3 main_hf.py --model_name text-davinci-003 --task re2text --setting prompt4Wir bieten auch eine flexiblere Möglichkeit, die Experimente durchzuführen. Es gibt echte Argumente, die Sie angeben müssen.
model_name : Der Name des großen Sprachmodells, das Sie verwenden möchten, siehe unsere unterstützte Modellliste.task : Die Subtask von Convre Benchmark: text2re oder re2text .data_dir : Das Verzeichnis, in dem der Datensatz gespeichert ist.prompt : Die Art der Eingabeaufforderung im Experiment: normal , hint oder hint+cot .relation : Der im Experiment zu verwendende Beziehungstyp: normal für normale Beziehung und converse für die umgekehrte Beziehung.n_shot : Wenig-Shot-Nummern, wählen Sie eine Zahl in [0, 1, 2, 3, 4, 5, 6].example_type : Die Art der wenigen Schussbeispiele, hard oder regular .text_type : Die Art des Textes, der im Experiment regular oder hard verwendet wird.Die Argumenteinstellungen für jede der in unserem Papier verwendeten Eingabeaufforderung finden Sie unten.
| Prompt ID | prompt | Beziehung | n_shot | Beispiel_Type | text_type |
|---|---|---|---|---|---|
| Re2Text 1## | Normal | Normal | 0 | regulär | regulär |
| text2re 1## | Normal | Normal | 0 | regulär | hart |
| Re2Text 2# | Normal | Normal | 0 | regulär | hart |
| text2re 2# | Normal | Normal | 0 | regulär | regulär |
| Re2Text 3# | Normal | umgekehrt | 0 | regulär | regulär |
| text2re 3# | Normal | umgekehrt | 0 | regulär | hart |
| Re2Text 4# | Normal | umgekehrt | 0 | regulär | hart |
| text2re 4# | Normal | umgekehrt | 0 | regulär | regulär |
| Re2Text 5# | Hinweis | umgekehrt | 0 | regulär | regulär |
| text2re 5# | Hinweis | umgekehrt | 0 | regulär | hart |
| Re2Text 6# | Hinweis | umgekehrt | 0 | regulär | hart |
| text2re 6# | Hinweis | umgekehrt | 0 | regulär | regulär |
| 7# | Normal | umgekehrt | 3 | hart | hart |
| 8# | Tipp+COT | umgekehrt | 3 | hart | hart |
| 9# | Normal | umgekehrt | 6 | hart | hart |
| 10# | Normal | umgekehrt | 3 | regulär | hart |
| 11# | Tipp+COT | umgekehrt | 3 | regulär | hart |
| 12# | Normal | umgekehrt | 6 | regulär | hart |
Beispiel
Hier ist das Skript zum Ausführen von prompt3 der text2re -Aufgabe in gpt-3.5-turbo-0301 ?
python3 main.py --model_name gpt-3.5-turbo-0301 --task text2re --data_dir data --prompt normal --relation converse --n_shot 0 --example_type regular --text_type hardBei der Ausführung des Bewertungsskripts müssen drei Argumente angegeben werden.
file_path : Der path der Ergebnisdatei?.model_family : Die Modellfamilie der Ergebnisdatei, die zum Auswählen des entsprechenden Bewerters verwendet wird. Sie sollten aus flan-t5 , claude , gpt-text , gpt-chat , llama2 , qwen , internlm wählen.mode : Wir bieten zwei Bewertungsmodus: strict und auto . strict Modus erhöht Fehler, wenn die Antwort des Modells nicht mit dem übereinstimmt, was wir wollen. In diesem Fall sollten Sie die Antwort des Modells manuell überprüfen. auto -Modus ignoriert nur die inkonsistenten Antworten. Die im auto -Modus berechnete Leistung ist möglicherweise niedriger als strict Modus, ist jedoch sehr bequem und benötigt keine menschliche Unterstützung. Die Fähigkeit, sich auf die Anfrage des Benutzers auszurichten, ist auch ein sehr wichtiger Indikator für die Fähigkeit von LLMs. Erstens sollten Sie eine neue Klasse erstellen, die LanguageModels in llms_interface.py erben und dann die completion gemäß den Merkmalen (wie der Struktur der API des neuen Modells) Ihres Modells implementieren.
Nachdem Sie das Ergebnis erhalten haben, sollten Sie eine neue Klasse erstellen, die BaseEvaluator in llms_evaluator.py erben und dann die evaluate -Methode gemäß dem Muster der Antwort Ihres Modells implementieren.
Um eine neue Beziehung in den Benchmark hinzuzufügen, sollten Sie zunächst prüfen, ob die Beziehung die Anforderungen in Section 2.5 unseres Papiers entspricht. Dann sollten Sie die entsprechenden Eingabeaufforderungen sowohl für Re2Text als auch für Text2Re -Aufgaben schreiben.
Re2Text
Hinweis: In dieser Aufgabe werden alle Frage nach der Haupteinheit gestellt.
normal : Die normal Anweisung der Beziehung.converse : Die converse Anweisung des Relitons.normal-regular : Die regular Beschreibung für die Frage in normal Beziehung.normal-hard : Die hard Beschreibung für die Frage in normal Beziehung.converse-regular : Die regular Beschreibung für die Frage unter converse .converse-hard : Die hard Beschreibung für die Frage unter converse Beziehung.Text2re
normal : Die normal Anweisung der Beziehung.converse : Die converse Anweisung des Relatons.hard : Die hard Beschreibung der Frage.regular : Die regular Beschreibung der Frage.normal-correct : Die correct Wahl unter normal Beziehung.normal-wrong : Die wrong Wahl unter normal Verhältnis.converse-correct : Die correct Wahl unter converse .converse-wrong : Die wrong Wahl unter converse Beziehung.Fühlen Sie sich frei, neue Modelle und Beziehungen zu unserem Benchmark hinzuzufügen?
@misc{qi2023investigation,
title={An Investigation of LLMs' Inefficacy in Understanding Converse Relations},
author={Chengwen Qi and Bowen Li and Binyuan Hui and Bailin Wang and Jinyang Li and Jinwang Wu and Yuanjun Laili},
year={2023},
eprint={2310.05163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


