ConvRe
1.0.0
? Données |? Code |? HuggingFace Leadboard |? Papier |

? Convre ? est l'indice de référence proposé dans notre document principal de la conférence EMNLP 2023: une enquête sur l'inefficacité des LLMS dans la compréhension des révations conformes . Il vise à évaluer la capacité des LLMS à comprendre les relations inverses. La relation inverse est définie comme l'opposé de la relation sémantique tout en gardant la forme de surface du triple inchangé. Par exemple, le triple (x, has part, y) est interprété comme "x a une partie appelée y" en relation normale, tandis que "y a une pièce appelée x" dans la relation inverse ?.
Les expériences de notre article ont suggéré que les LLM ont souvent recours à l'apprentissage des raccourcis (ou aux corrélations superficielles) et sont toujours confrontés à des défis sur notre? Convre? Benchmark même pour des modèles puissants comme GPT-4. L'image suivante montre les performances des modèles GPT sous des paramètres faciles / durs de zéro sur notre référence. On peut observer que dans les tâches Re2Text et Text2Re , les modèles GPT présentent une tendance de mise à l'échelle positive sous la définition facile et la tendance de mise à l'échelle inverse sous la fin. Veuillez vérifier notre papier? Ou un classement en étreinte? Pour des résultats plus détaillés et complets.
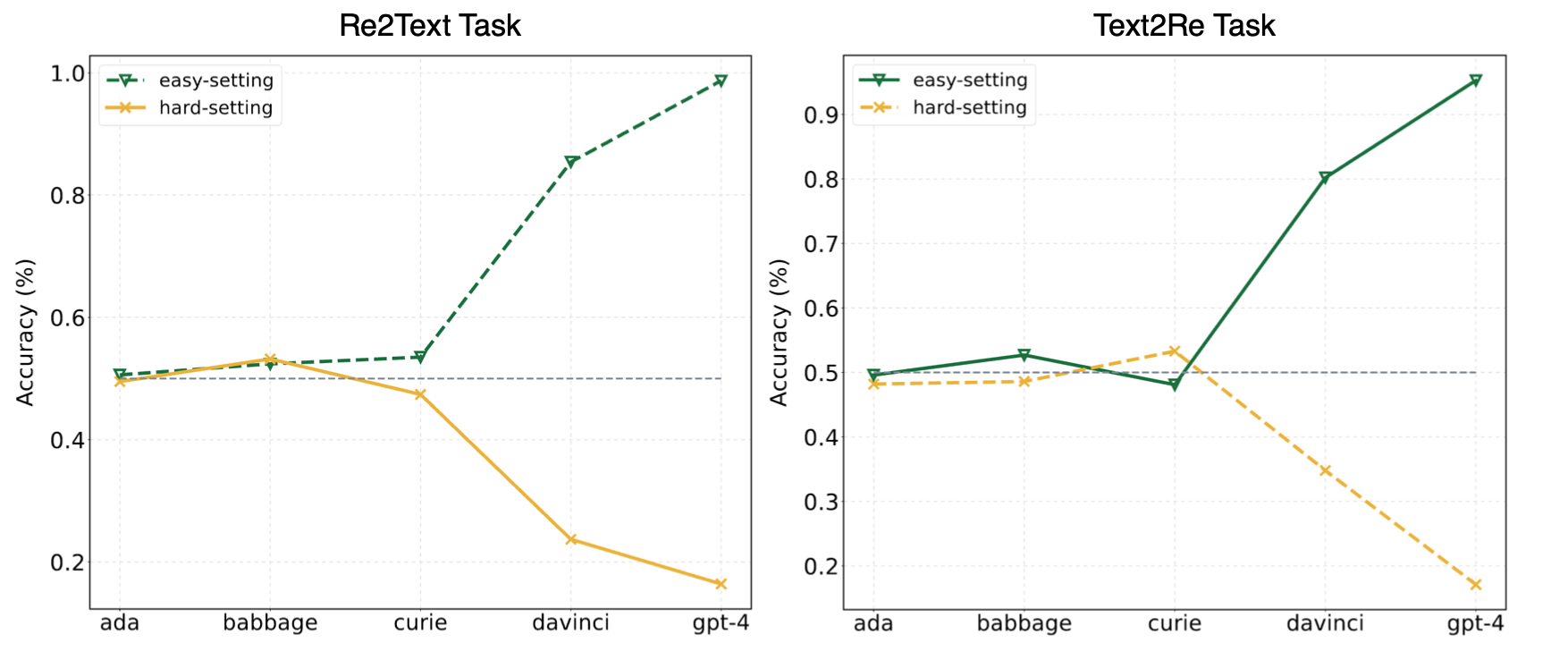
Lisez ceci dans 中文.
Convre Benchmark est composé de 17 relations et 1240 triples de cinq ensembles de données de graphiques de connaissances largement utilisés: WN18RR, FB15K-237, Nell-One, Wikidata5m, ICEWS14, conceptNet5. Le nombre détaillé de triplets pour chaque relation dans la référence est répertorié ci-dessous.
| Relation | # Triples | Source |
|---|---|---|
| hypernyme | 80 | Wn18rr |
| a partie | 78 | Wn18rr |
| organisation, relation organisation, enfant | 75 | FB15K-237 |
| Emplacement, emplacement, contient partiellement | 77 | FB15K-237 |
| athlète battu l'athlète | 80 | Nell-one |
| parent de | 145 | Nell-one & wikidata5m |
| représenté par | 79 | Wikidata5m |
| effet secondaire | 8 | Wikidata5m |
| a une installation | 62 | Wikidata5m |
| influencé par | 65 | Wikidata5m |
| appartenant à | 51 | Wikidata5m |
| consulter | 73 | ICEWS14 |
| louer ou approuver | 78 | ICEWS14 |
| fait de | 80 | Conceptnet5 |
| utilisé | 79 | Conceptnet5 |
| a des biens | 55 | Conceptnet5 |
| a un sous-événement | 75 | Conceptnet5 |
| Total | 1240 |
Les fichiers d'ensemble de données peuvent être trouvés dans le répertoire data . Voici la description de chaque fichier.
re2text_relations.json : la définition de la relation normale et de conversation et les choix correspondants de chaque relation pour la tâche re2text .re2text_examples.json : les quelques exemples de tir de la tâche re2text , y compris le réglage de l'invite normal et le réglage hint+cot .text2re_relations : la définition normale et de la relation de conversation et les choix correspondants de chaque relation pour la tâche text2re .text2re_examples.json : les quelques exemples de tir de la tâche re2text , y compris le réglage de l'invite normal et le réglage hint+cot .triple_dataset : ensemble de données complet de la référence, y compris les triplets et les réponses correctes.triple_subset : le sous-ensemble que nous avons utilisé dans notre article, il contient 328 triples et leurs réponses correctes correspondantes. Les modèles répertoriés ci-dessous sont testés et peuvent être exécutés directement en utilisant le script en inférence.
Modèles de texte GPT
Modèles de Claude
Modèles Flan-T5
Modèles de chat llama2
Modèles de chat Qwen
Modèles interlm
Notre référence est disponible sur HuggingFace? (lien). Vous pouvez facilement exécuter l'inférence en utilisant main_hf.py et spécifier les trois arguments suivants.
model_name : le nom du modèle de grande langue, voir notre liste de modèles pris en charge.task : La sous-tâche de Convre Benchmark: text2re ou re2text .setting : Paramètre d'invite pour l'exécution actuelle (invite1-PROMPT 12), veuillez consulter notre article (lien) pour plus de détails de chaque paramètre.Exemple
Voici le script pour exécuter prompt4 de la tâche re2text sur text-davinci-003 ?
python3 main_hf.py --model_name text-davinci-003 --task re2text --setting prompt4Nous fournissons également un moyen plus flexible d'exécuter les expériences. Il y a des arguments de toute valeur que vous devez spécifier.
model_name : le nom du modèle de grande langue que vous souhaitez utiliser, consultez notre liste de modèles pris en charge.task : La sous-tâche de Convre Benchmark: text2re ou re2text .data_dir : Le répertoire où l'ensemble de données est stocké.prompt : Le type d'invite à utiliser dans l'expérience: normal , hint ou hint+cot .relation : Le type de relation à utiliser dans l'expérience: normal pour la relation normale et converse pour la relation inverse.n_shot : nombres à quelques coups, choisissez un nombre en [0, 1, 2, 3, 4, 5, 6].example_type : le type d'exemples à quelques tirs, hard ou regular .text_type : le type de texte à utiliser dans l'expérience, regular ou hard .Les paramètres d'argument pour chacun des 12 invites utilisés dans notre article sont répertoriés ci-dessous.
| ID rapide | rapide | relation | n_shot | Exemple_type | text_type |
|---|---|---|---|---|---|
| re2text 1 # | normale | normale | 0 | régulier | régulier |
| text2re 1 # | normale | normale | 0 | régulier | dur |
| re2text 2 # | normale | normale | 0 | régulier | dur |
| text2re 2 # | normale | normale | 0 | régulier | régulier |
| re2text 3 # | normale | converser | 0 | régulier | régulier |
| text2re 3 # | normale | converser | 0 | régulier | dur |
| re2text 4 # | normale | converser | 0 | régulier | dur |
| text2re 4 # | normale | converser | 0 | régulier | régulier |
| re2text 5 # | indice | converser | 0 | régulier | régulier |
| text2re 5 # | indice | converser | 0 | régulier | dur |
| re2text 6 # | indice | converser | 0 | régulier | dur |
| text2re 6 # | indice | converser | 0 | régulier | régulier |
| 7 # | normale | converser | 3 | dur | dur |
| 8 # | indice + lit | converser | 3 | dur | dur |
| 9 # | normale | converser | 6 | dur | dur |
| 10 # | normale | converser | 3 | régulier | dur |
| 11 # | indice + lit | converser | 3 | régulier | dur |
| 12 # | normale | converser | 6 | régulier | dur |
Exemple
Voici le script pour exécuter prompt3 de la tâche text2re sur gpt-3.5-turbo-0301 ?
python3 main.py --model_name gpt-3.5-turbo-0301 --task text2re --data_dir data --prompt normal --relation converse --n_shot 0 --example_type regular --text_type hardIl y a trois arguments à spécifier lors de l'exécution du script d'évaluation.
file_path : le path du fichier de résultat ?.model_family : La famille du modèle du fichier de résultat, utilisé pour choisir l'évaluateur correspondant. Vous devez choisir parmi flan-t5 , claude , gpt-text , gpt-chat , llama2 , qwen , internlm .mode : Nous fournissons deux mode d'évaluation: strict et auto . Le mode strict augmentera les erreurs si la réponse du modèle n'est pas cohérente avec ce que nous voulons. Dans ce cas, vous devez vérifier la réponse du modèle manuellement. Le mode auto ignorera simplement les réponses incohérentes. Les performances calculées en mode auto peuvent être inférieures à celles strict , mais elle est très pratique et n'a pas besoin de support humain. La possibilité de s'aligner sur la demande de l'utilisateur est également un indicateur très important de la capacité de LLMS. Tout d'abord, vous devez créer une nouvelle classe qui hérite LanguageModels dans llms_interface.py , puis implémenter la méthode completion en fonction des caractéristiques (telles que la structure de l'API du nouveau modèle) de votre modèle.
Après avoir obtenu le résultat, vous devez créer une nouvelle classe qui hérite de BaseEvaluator dans llms_evaluator.py , puis implémentez la méthode evaluate en fonction du modèle de la réponse de votre modèle.
Pour ajouter une nouvelle relation dans la référence, vous devez d'abord vérifier si la relation répond aux exigences de Section 2.5 de notre article. Ensuite, vous devez écrire les invites correspondantes pour les tâches Re2Text et Text2Re .
Re2text
Remarque: Dans cette tâche, toute la question est de demander une entité principale.
normal : l'instruction normal de la relation.converse : L'instruction converse du Relaiton.normal-regular : la description regular de la question en relation normal .normal-hard : La description hard de la question en relation normal .converse-regular : la description regular de la question sous la relation converse .converse-hard : la description hard de la question sous la relation converse .Text2re
normal : l'instruction normal de la relation.converse : L'instruction converse du Relaton.hard : La description hard de la question.regular : La description regular de la question.normal-correct : le correct choix en relation normal .normal-wrong : le wrong choix en relation normal .converse-correct : le correct choix sous la relation converse .converse-wrong : le wrong choix sous la relation converse .N'hésitez pas à ajouter de nouveaux modèles et relations à notre référence?
@misc{qi2023investigation,
title={An Investigation of LLMs' Inefficacy in Understanding Converse Relations},
author={Chengwen Qi and Bowen Li and Binyuan Hui and Bailin Wang and Jinyang Li and Jinwang Wu and Yuanjun Laili},
year={2023},
eprint={2310.05163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


