ConvRe
1.0.0
? 데이터 |? 코드 |? 포옹 페이스 리더 보드 board? 종이 |

? 회피 ? EMNLP 2023 메인 컨퍼런스 논문에서 제안 된 벤치 마크 : LLMS의 비효율적 인 비효율 에 대한 조사. 회전 관계를 이해하는 LLM의 능력을 평가하는 것을 목표로합니다. 대화 관계는 트리플의 표면 형태를 변하지 않은 상태로 유지하면서 의미 론적 관계의 반대로 정의됩니다. 예를 들어, 트리플 (x, has part, y) 은 정상 관계에서 "x는 y라는 부분"으로 해석되는 반면, "y는 x라고 불리는 부분"으로 해석됩니다.
우리 논문의 실험은 LLM이 종종 단축 학습 (또는 피상적 상관 관계)에 의지하고 여전히 우리의 도약에 대한 도전에 직면하고 있다고 제안했다. GPT-4와 같은 강력한 모델의 경우에도 벤치 마크. 다음 그림은 벤치 마크에서 Zero-Shot Easy/Hard 설정에서 GPT 모델의 성능을 보여줍니다. Re2Text 및 Text2Re 작업 모두에서 GPT 모델은 쉽게 설정하고 하드 설정 하에서 역 스케일링 추세에서 긍정적 인 스케일링 추세를 나타냅니다. 우리 신문을 확인 해주세요. 아니면 Huggingface Leaderboard? 보다 자세하고 포괄적 인 결과를 얻으려면.
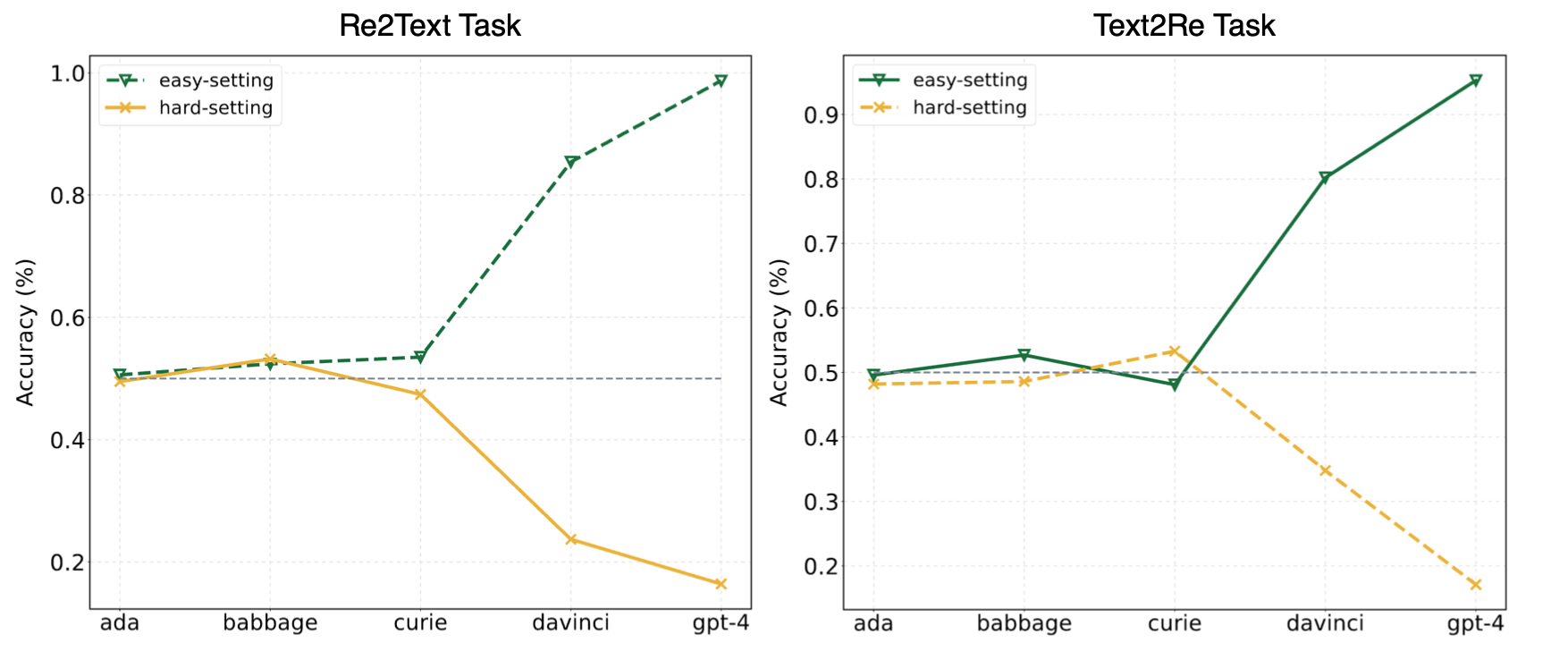
이것을 中文에서 읽으십시오.
COPRE 벤치 마크는 WN18RR, FB15K-237, NELL-ONE, Wikidata5M, ICEWS14, ConceptNET5의 5 가지 지식 그래프 데이터 세트에서 17 개의 관계와 1240 트리플으로 구성됩니다. 벤치 마크의 각 관계에 대한 세부 트리플 수는 다음과 같습니다.
| 관계 | # 트리플 | 원천 |
|---|---|---|
| 하이퍼 의미 | 80 | wn18rr |
| 부분이 있습니다 | 78 | wn18rr |
| 조직, 조직 관계, 아동 | 75 | FB15K-237 |
| 위치, 위치, 부분적으로 포함됩니다 | 77 | FB15K-237 |
| 운동 선수는 선수를 이겼습니다 | 80 | Nell-One |
| 부모 | 145 | Nell-One & Wikidata5m |
| 대표합니다 | 79 | wikidata5m |
| 부작용 | 8 | wikidata5m |
| 시설이 있습니다 | 62 | wikidata5m |
| 영향을받습니다 | 65 | wikidata5m |
| 소유 | 51 | wikidata5m |
| 찾다 | 73 | ICEWS14 |
| 칭찬 또는 보증 | 78 | ICEWS14 |
| 만들어졌습니다 | 80 | ConceptNet5 |
| 사용 | 79 | ConceptNet5 |
| 속성이 있습니다 | 55 | ConceptNet5 |
| 하위 이벤트가 있습니다 | 75 | ConceptNet5 |
| 총 | 1240 |
데이터 세트 파일은 data 디렉토리에서 찾을 수 있습니다. 다음은 각 파일에 대한 설명입니다.
re2text_relations.json : re2text 작업에 대한 각 관계의 정상 및 대화 관계 정의 및 해당 선택.re2text_examples.json : normal 프롬프트 설정 및 hint+cot 설정을 포함하여 re2text 작업의 몇 가지 샷 예제.text2re_relations : text2re 작업에 대한 각 관계의 정상 및 대화 정의 및 해당 선택.text2re_examples.json : normal 프롬프트 설정 및 hint+cot 설정을 포함한 re2text 작업의 몇 가지 샷 예제.triple_dataset : 트리플 및 정답을 포함한 벤치 마크의 전체 데이터 세트.triple_subset : 논문에서 사용한 서브 세트에는 328 개의 트리플과 해당 정답이 포함되어 있습니다. 아래에 나열된 모델은 테스트되었으며 스크립트를 추론하여 직접 실행할 수 있습니다.
GPT 텍스트 모델
클로드 모델
FLAN-T5 모델
llama2 채팅 모델
Qwen 채팅 모델
internlm 모델
우리의 벤치 마크는 Huggingface에서 사용할 수 있습니까? (링크). main_hf.py 사용하고 다음 세 인수를 지정하여 추론을 쉽게 실행할 수 있습니다.
model_name : 큰 언어 모델의 이름은 지원되는 모델 목록을 참조하십시오.task : COPRE 벤치 마크의 하위 작업 : text2re 또는 re2text .setting : 현재 실행에 대한 프롬프트 설정 (Prompt1-Prompt 12). 각 설정에 대한 자세한 내용은 용지 (링크)를 참조하십시오.예
다음은 text-davinci-003 에서 re2text 작업의 prompt4 실행하는 스크립트입니다.
python3 main_hf.py --model_name text-davinci-003 --task re2text --setting prompt4또한 실험을 수행하는보다 유연한 방법을 제공합니다. 지정 해야하는 knight 인수가 있습니다.
model_name : 사용하려는 대형 언어 모델의 이름은 지원되는 모델 목록을 참조하십시오.task : COPRE 벤치 마크의 하위 작업 : text2re 또는 re2text .data_dir : 데이터 세트가 저장된 디렉토리.prompt : 실험에서 사용할 프롬프트 유형 : normal , hint 또는 hint+cot .relation : 실험에서 사용할 관계 유형 : 정상 관계의 경우 normal 및 대화의 converse .n_shot : 소수의 샷 숫자는 [0, 1, 2, 3, 4, 5, 6에서 숫자를 선택하십시오.example_type : hard 하거나 regular 소수의 예제 유형.text_type : 실험에서 사용할 텍스트 유형, regular 또는 hard .본 논문에 사용 된 12 개의 프롬프트 각각에 대한 인수 설정은 아래에 나열되어 있습니다.
| 프롬프트 ID | 즉각적인 | 관계 | n_shot | example_type | text_type |
|---|---|---|---|---|---|
| re2text 1# | 정상 | 정상 | 0 | 정기적인 | 정기적인 |
| Text2re 1# | 정상 | 정상 | 0 | 정기적인 | 딱딱한 |
| re2text 2# | 정상 | 정상 | 0 | 정기적인 | 딱딱한 |
| Text2re 2# | 정상 | 정상 | 0 | 정기적인 | 정기적인 |
| re2text 3# | 정상 | 반대 | 0 | 정기적인 | 정기적인 |
| Text2re 3# | 정상 | 반대 | 0 | 정기적인 | 딱딱한 |
| re2text 4# | 정상 | 반대 | 0 | 정기적인 | 딱딱한 |
| Text2re 4# | 정상 | 반대 | 0 | 정기적인 | 정기적인 |
| re2text 5# | 힌트 | 반대 | 0 | 정기적인 | 정기적인 |
| Text2re 5# | 힌트 | 반대 | 0 | 정기적인 | 딱딱한 |
| re2text 6# | 힌트 | 반대 | 0 | 정기적인 | 딱딱한 |
| Text2re 6# | 힌트 | 반대 | 0 | 정기적인 | 정기적인 |
| 7# | 정상 | 반대 | 3 | 딱딱한 | 딱딱한 |
| 8# | 힌트+침대 | 반대 | 3 | 딱딱한 | 딱딱한 |
| 9# | 정상 | 반대 | 6 | 딱딱한 | 딱딱한 |
| 10# | 정상 | 반대 | 3 | 정기적인 | 딱딱한 |
| 11# | 힌트+침대 | 반대 | 3 | 정기적인 | 딱딱한 |
| 12# | 정상 | 반대 | 6 | 정기적인 | 딱딱한 |
예
다음은 gpt-3.5-turbo-0301 에서 text2re 작업의 prompt3 실행하는 스크립트입니다.
python3 main.py --model_name gpt-3.5-turbo-0301 --task text2re --data_dir data --prompt normal --relation converse --n_shot 0 --example_type regular --text_type hard평가 스크립트를 실행할 때 세 가지 인수를 지정해야합니다.
file_path : 결과 파일의 path ?.model_family : 해당 평가자를 선택하는 데 사용되는 결과 파일의 모델 패밀리입니다. flan-t5 , claude , gpt-text , gpt-chat , llama2 , qwen , internlm 중에서 선택해야합니다.mode : 우리는 두 가지 평가 모드를 제공합니다 : strict 하고 auto . 모델의 답변이 우리가 원하는 것과 일치하지 않으면 strict 모드가 오류가 발생합니다. 이 경우 모델의 답변을 수동으로 확인해야합니다. auto 모드는 불일치 답변을 무시합니다. auto 모드에서 계산 된 성능은 strict 모드보다 낮을 수 있지만 매우 편리하며 인간 지원이 필요하지 않습니다. 사용자의 요청에 맞는 능력은 LLMS 기능의 매우 중요한 지표입니다. 첫째, llms_interface.py 에서 LanguageModels 상속하는 새로운 클래스를 생성 한 다음 모델의 특성 (예 : 새로운 모델 API의 구조)에 따라 completion 방법을 구현해야합니다.
결과를 얻은 후 llms_evaluator.py 에서 BaseEvaluator 상속하는 새로운 클래스를 작성한 다음 모델의 답변 패턴에 따라 evaluate 방법을 구현해야합니다.
벤치 마크에 새로운 관계를 추가하려면 먼저 관계가 논문의 Section 2.5 요구 사항을 충족하는지 확인해야합니다. 그런 다음 Re2Text 및 Text2Re 작업 모두에 해당하는 프롬프트를 작성해야합니다.
re2text
참고 :이 작업에서 모든 질문은 헤드 엔티티를 요구하는 것입니다.
normal : 관계의 normal 지시.converse : Relaiton의 converse 지시.normal-regular : normal 관계에서 질문에 대한 regular 설명.normal-hard : normal 관계에서 질문에 대한 hard 설명.converse-regular : converse 하에서 질문에 대한 regular 설명.converse-hard : converse 관계에서 질문에 대한 hard 설명.Text2re
normal : 관계의 normal 지시.converse : Relaton의 converse 지시.hard : 질문에 대한 hard 설명.regular : 질문에 대한 regular 설명.normal-correct : normal 관계에서 correct 선택.normal-wrong : normal 관계에서 wrong 선택.converse-correct : converse 관계에서 correct 선택.converse-wrong : converse 관계에서 wrong 선택.벤치 마크에 새로운 모델과 관계를 자유롭게 추가 하시겠습니까?
@misc{qi2023investigation,
title={An Investigation of LLMs' Inefficacy in Understanding Converse Relations},
author={Chengwen Qi and Bowen Li and Binyuan Hui and Bailin Wang and Jinyang Li and Jinwang Wu and Yuanjun Laili},
year={2023},
eprint={2310.05163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


