ConvRe
1.0.0
? Dados |? Código |? RABELA DE LIGADOR DE HUGGINGFACE |? Papel |

? Convre ? é o benchmark proposto em nosso documento de conferência principal do EMNLP 2023: uma investigação da ineficácia da LLMS em entender as relações convencionais . O objetivo é avaliar a capacidade da LLMS na compreensão das relações conversas. A relação inversa é definida como o oposto da relação semântica, mantendo a forma superficial do triplo inalterado. Por exemplo, o triplo (x, has part, y) é interpretado como "x tem uma peça chamada y" na relação normal, enquanto "y tem uma parte chamada x" na relação conversse?.
Os experimentos em nosso artigo sugeriram que os LLMs geralmente recorriam à aprendizagem de atalho (ou correlações superficiais) e ainda enfrentam desafios em nosso? Referência até mesmo para modelos poderosos como o GPT-4. A figura a seguir mostra o desempenho dos modelos GPT sob configurações fáceis/duras com tiro zero em nossa referência. Pode-se observar que, nas tarefas Re2Text e Text2Re , os modelos GPT exibem uma tendência de escala positiva sob fáceis de definição e tendência de escala inversa sob resistência. Por favor, verifique nosso papel? ou tabela de classificação Huggingface? Para resultados mais detalhados e abrangentes.
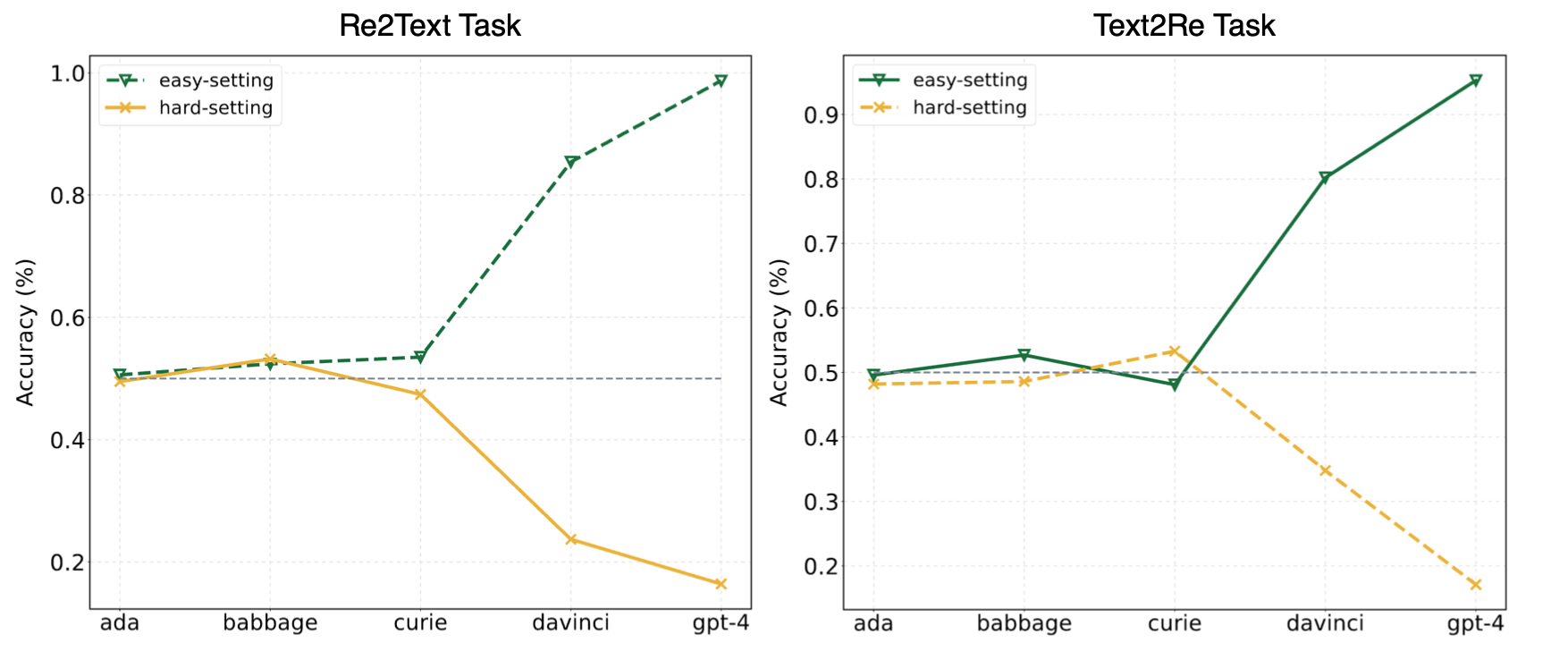
Leia isso em 中文.
O Benchmark Convre é composto por 17 relações e 1240 triplos de cinco conjuntos de dados de gráficos de conhecimento amplamente utilizados: WN18RR, FB15K-237, NELL-ONE, WIKIDATA5M, ICEWS14, ConceptNet5. O número detalhado de triplos para cada relação na referência está listado abaixo.
| Relação | # Triplos | Fonte |
|---|---|---|
| Hypernym | 80 | WN18RR |
| tem parte | 78 | WN18RR |
| organização, relacionamento organizacional, criança | 75 | FB15K-237 |
| Localização, localização, contém parcialmente | 77 | FB15K-237 |
| Atleta venceu o atleta | 80 | Nell-one |
| pai de | 145 | Nell-One & Wikidata5m |
| representado por | 79 | Wikidata5m |
| efeito colateral | 8 | Wikidata5m |
| tem instalação | 62 | Wikidata5m |
| influenciado por | 65 | Wikidata5m |
| de propriedade de | 51 | Wikidata5m |
| consultar | 73 | ICEWS14 |
| louvar ou endossar | 78 | ICEWS14 |
| feito de | 80 | ConceptNet5 |
| usado de | 79 | ConceptNet5 |
| tem propriedade | 55 | ConceptNet5 |
| tem subevent | 75 | ConceptNet5 |
| Total | 1240 |
Os arquivos do conjunto de dados podem ser encontrados no diretório data . Aqui está a descrição de cada arquivo.
re2text_relations.json : A definição de relação normal e conversada e escolhas correspondentes de cada relação para a tarefa re2text .re2text_examples.json : Os poucos exemplos de tiro de tarefa re2text , incluindo configuração de prompt normal e configuração hint+cot .text2re_relations : a definição de relação normal e conversada e as escolhas correspondentes de cada relação para a tarefa text2re .text2re_examples.json : Os poucos exemplos de tiro de tarefa re2text , incluindo configuração de prompt normal e configuração hint+cot .triple_dataset : conjunto de dados completo da referência, incluindo triplos e respostas corretas.triple_subset : o subconjunto que usamos em nosso papel, ele contém 328 triplos e suas respostas corretas correspondentes. Os modelos listados abaixo são testados e podem ser executados diretamente usando o script em inferência.
Modelos de texto GPT
Modelos Claude
Modelos Flan-T5
Modelos de bate -papo llama2
Modelos de bate -papo Qwen
Modelos InternLM
Nosso benchmark está disponível no Huggingface? (link). Você pode executar facilmente a inferência usando main_hf.py e especificando os três argumentos a seguir.
model_name : o nome do modelo de idioma grande, consulte nossa lista de modelos suportados.task : a subtarefa de Benchmark Convre: text2re ou re2text .setting : Configuração de prompt para execução atual (Prompt1-PROMPT 12), consulte o nosso artigo (link) para obter mais detalhes de cada configuração.Exemplo
Aqui está o script para executar prompt4 da tarefa re2text no text-davinci-003 ?
python3 main_hf.py --model_name text-davinci-003 --task re2text --setting prompt4Também fornecemos uma maneira mais flexível de executar os experimentos. Existem argumentos ️Eight que você precisa especificar.
model_name : o nome do modelo de idioma grande que você deseja usar, consulte nossa lista de modelos suportados.task : a subtarefa de Benchmark Convre: text2re ou re2text .data_dir : o diretório onde o conjunto de dados armazenou.prompt : o tipo de prompt para usar no experimento: normal , hint ou hint+cot .relation : o tipo de relação a uso no experimento: normal para relação normal e converse para a relação conversse.n_shot : números de poucos anos, escolha um número em [0, 1, 2, 3, 4, 5, 6].example_type : o tipo de exemplos de poucos anos, hard ou regular .text_type : o tipo de texto a ser usado no experimento, regular ou hard .As configurações de argumento para cada um dos 12 prompts usadas em nosso artigo estão listadas abaixo.
| ID de prompt | incitar | relação | n_shot | exemplo_type | text_type |
|---|---|---|---|---|---|
| re2text 1# | normal | normal | 0 | regular | regular |
| text2re 1# | normal | normal | 0 | regular | duro |
| re2text 2# | normal | normal | 0 | regular | duro |
| text2re 2# | normal | normal | 0 | regular | regular |
| re2text 3# | normal | conversar | 0 | regular | regular |
| text2re 3# | normal | conversar | 0 | regular | duro |
| re2text 4# | normal | conversar | 0 | regular | duro |
| text2re 4# | normal | conversar | 0 | regular | regular |
| re2text 5# | dica | conversar | 0 | regular | regular |
| text2re 5# | dica | conversar | 0 | regular | duro |
| re2text 6# | dica | conversar | 0 | regular | duro |
| text2re 6# | dica | conversar | 0 | regular | regular |
| 7# | normal | conversar | 3 | duro | duro |
| 8# | dica+berço | conversar | 3 | duro | duro |
| 9# | normal | conversar | 6 | duro | duro |
| 10# | normal | conversar | 3 | regular | duro |
| 11# | dica+berço | conversar | 3 | regular | duro |
| 12# | normal | conversar | 6 | regular | duro |
Exemplo
Aqui está o script para executar prompt3 da tarefa text2re no gpt-3.5-turbo-0301 ?
python3 main.py --model_name gpt-3.5-turbo-0301 --task text2re --data_dir data --prompt normal --relation converse --n_shot 0 --example_type regular --text_type hardHá três argumentos precisam ser especificados ao executar o script de avaliação.
file_path : o path do arquivo de resultado?.model_family : A família modelo do arquivo de resultado, usada para escolher o avaliador correspondente. Você deve escolher entre flan-t5 , claude , gpt-text , gpt-chat , llama2 , qwen , internlm .mode : Fornecemos dois modo de avaliação: strict e auto . O modo strict levantará erros se a resposta do modelo não for consistente com o que queremos. Nesse caso, você deve verificar a resposta do modelo manualmente. O modo auto simplesmente ignorará as respostas inconsistentes. O desempenho calculado no modo auto pode ser menor que o modo strict , mas é muito conveniente e não precisa de suporte humano. A capacidade de se alinhar com a solicitação do usuário também é um indicador muito importante da capacidade do LLMS. Em primeiro lugar, você deve criar uma nova classe que herde LanguageModels em llms_interface.py e implemente o método completion de acordo com as características (como a estrutura da API do novo modelo) do seu modelo.
Após obter o resultado, você deve criar uma nova classe que herde BaseEvaluator em llms_evaluator.py e, em seguida, implemente o método evaluate de acordo com o padrão da resposta do seu modelo.
Para adicionar uma nova relação na referência, você deve primeiro verificar se a relação atende aos requisitos na Section 2.5 do nosso artigo. Em seguida, você deve escrever os prompts correspondentes para as tarefas Re2Text e Text2Re .
Re2text
Nota: Nesta tarefa, toda a pergunta está pedindo entidade principal.
normal : a instrução normal da relação.converse : A instrução converse do Relaiton.normal-regular : a descrição regular para a questão sob relação normal .normal-hard : A descrição hard da questão sob relação normal .converse-regular : a descrição regular para a questão em relação ao converse .converse-hard : A descrição hard da questão em relação à converse .Text2re
normal : a instrução normal da relação.converse : A instrução converse da Relaton.hard : a descrição hard da pergunta.regular : a descrição regular da pergunta.normal-correct : a escolha correct sob relação normal .normal-wrong : a escolha wrong sob relação normal .converse-correct : a escolha correct sob a relação converse .converse-wrong : A escolha wrong sob a relação converse .Sinta -se à vontade para adicionar novos modelos e relações à nossa referência?
@misc{qi2023investigation,
title={An Investigation of LLMs' Inefficacy in Understanding Converse Relations},
author={Chengwen Qi and Bowen Li and Binyuan Hui and Bailin Wang and Jinyang Li and Jinwang Wu and Yuanjun Laili},
year={2023},
eprint={2310.05163},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


