epub_to_audiobook
v0.6.1
เข้าร่วมเซิร์ฟเวอร์ Discord ของเราสำหรับคำถามหรือการอภิปรายใด ๆ
โครงการนี้มีเครื่องมือบรรทัดคำสั่งเพื่อแปลง eBooks EPUB เป็นหนังสือเสียง ตอนนี้รองรับทั้ง Microsoft Azure Text-to-Speech API (ทางเลือก edgetts) และ OpenAI Text-to-Speech API เพื่อสร้างเสียงสำหรับแต่ละบทใน ebook ไฟล์เสียงเอาต์พุตได้รับการปรับให้เหมาะสมสำหรับการใช้งานกับ AudioBookshelf
โครงการนี้ได้รับการพัฒนาด้วยความช่วยเหลือของ CHATGPT
หากคุณสนใจที่จะได้ยินตัวอย่างของหนังสือเสียงที่สร้างขึ้นโดยเครื่องมือนี้ให้ตรวจสอบลิงก์ที่ตะโกน
หนังสือเสียงที่สร้างขึ้นโดยโครงการนี้ได้รับการปรับให้เหมาะสมสำหรับการใช้งานกับ AudioBookshelf แต่ละบทในไฟล์ epub จะถูกแปลงเป็นไฟล์ MP3 แยกต่างหากโดยมีการสกัดชื่อบทและรวมเป็นข้อมูลเมตา
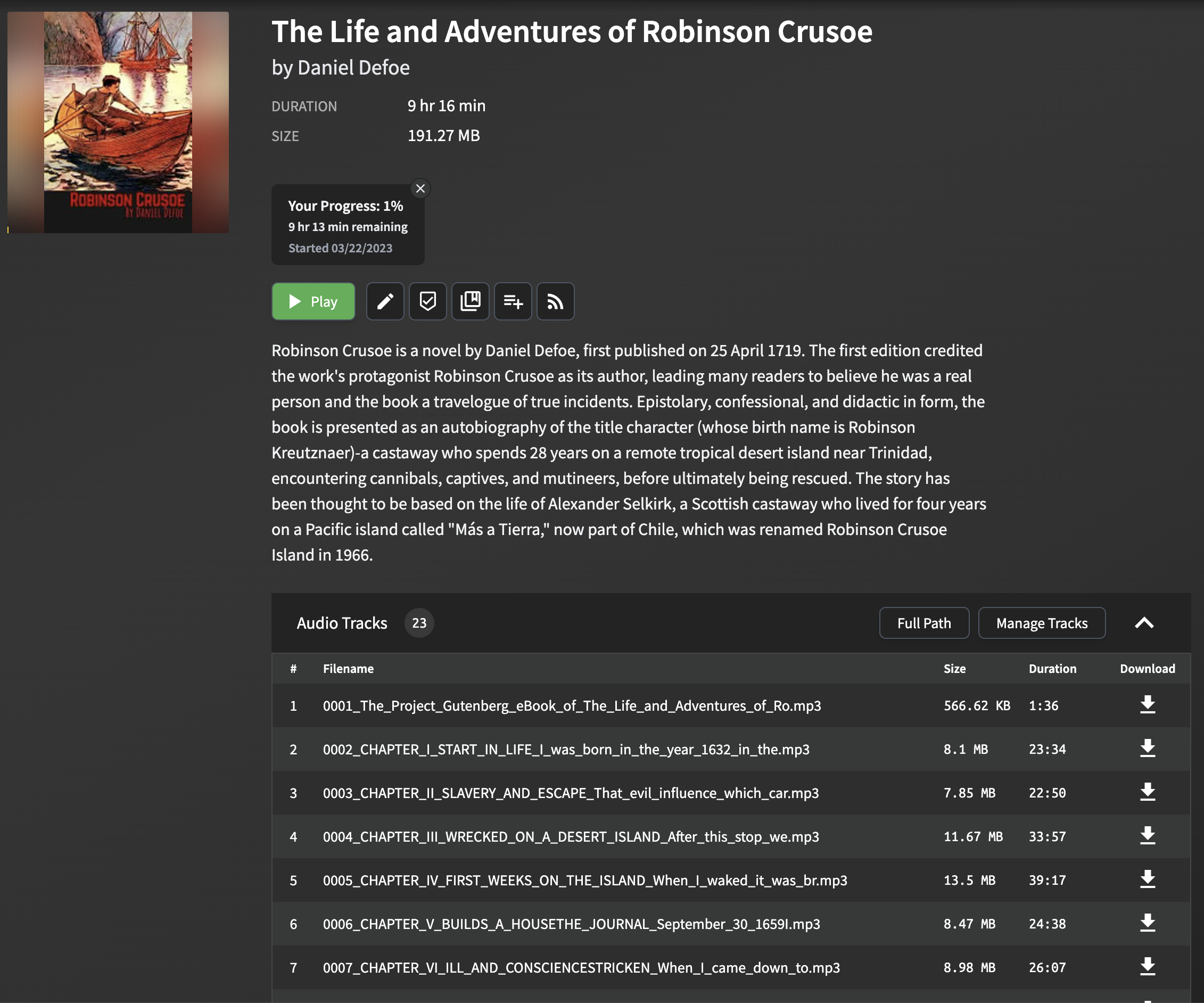
การแยกวิเคราะห์และการแยกชื่อบทจากไฟล์ EPUB อาจเป็นเรื่องที่ท้าทายเนื่องจากรูปแบบและโครงสร้างอาจแตกต่างกันอย่างมีนัยสำคัญระหว่าง ebooks ที่แตกต่างกัน สคริปต์ใช้วิธีการที่ง่าย แต่มีประสิทธิภาพในการแยกชื่อบทซึ่งใช้งานได้กับไฟล์ EPUB ส่วนใหญ่ วิธีนี้เกี่ยวข้องกับการแยกวิเคราะห์ไฟล์ epub และค้นหาแท็ก title ในเนื้อหา HTML ของแต่ละบท หากแท็กชื่อเรื่องไม่มีอยู่ชื่อทางเลือกจะถูกสร้างขึ้นโดยใช้คำสองสามคำแรกของข้อความบท
โปรดทราบว่าวิธีการนี้อาจไม่ทำงานได้อย่างสมบูรณ์แบบสำหรับไฟล์ EPUB ทั้งหมดโดยเฉพาะอย่างยิ่งไฟล์ที่มีการจัดรูปแบบที่ซับซ้อนหรือผิดปกติ อย่างไรก็ตามในกรณีส่วนใหญ่มันเป็นวิธีที่เชื่อถือได้ในการแยกชื่อบทเพื่อใช้ใน AudioBookshelf
เมื่อคุณนำเข้าไฟล์ MP3 ที่สร้างขึ้นใน AudioBookshelf ชื่อบทจะปรากฏขึ้นทำให้ง่ายต่อการนำทางระหว่างบทและเพิ่มประสบการณ์การฟังของคุณ
โคลนที่เก็บนี้:
git clone https://github.com/p0n1/epub_to_audiobook.git
cd epub_to_audiobookสร้างสภาพแวดล้อมเสมือนจริงและเปิดใช้งาน:
python3 -m venv venv
source venv/bin/activateติดตั้งการพึ่งพาที่ต้องการ:
pip install -r requirements.txtตั้งค่าตัวแปรสภาพแวดล้อมต่อไปนี้ด้วยข้อมูลประจำตัว API Text-to-Speech ของคุณหรือคีย์ OpenAI API ของคุณหากคุณใช้ OpenAI TTS:
export MS_TTS_KEY= < your_subscription_key > # for Azure
export MS_TTS_REGION= < your_region > # for Azure
export OPENAI_API_KEY= < your_openai_api_key > # for OpenAI ในการแปลง ePub eBook เป็นหนังสือเสียงให้เรียกใช้คำสั่งต่อไปนี้โดยระบุผู้ให้บริการ TTS ที่คุณเลือกด้วยตัวเลือก --tts :
python3 main.py < input_file > < output_folder > [options]ในการตรวจสอบคำอธิบายตัวเลือกล่าสุดสำหรับสคริปต์นี้คุณสามารถเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล:
python3 main.py -husage: main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
Convert text book to audiobook
positional arguments:
input_file Path to the EPUB file
output_folder Path to the output folder
options:
-h, --help show this help message and exit
--tts {azure,openai,edge,piper}
Choose TTS provider (default: azure). azure: Azure
Cognitive Services, openai: OpenAI TTS API. When using
azure, environment variables MS_TTS_KEY and
MS_TTS_REGION must be set. When using openai,
environment variable OPENAI_API_KEY must be set.
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Log level (default: INFO), can be DEBUG, INFO,
WARNING, ERROR, CRITICAL
--preview Enable preview mode. In preview mode, the script will
not convert the text to speech. Instead, it will print
the chapter index, titles, and character counts.
--no_prompt Don ' t ask the user if they wish to continue after
estimating the cloud cost for TTS. Useful for
scripting.
--language LANGUAGE Language for the text-to-speech service (default: en-
US). For Azure TTS (--tts=azure), check
https://learn.microsoft.com/en-us/azure/ai-
services/speech-service/language-
support?tabs=tts#text-to-speech for supported
languages. For OpenAI TTS (--tts=openai), their API
detects the language automatically. But setting this
will also help on splitting the text into chunks with
different strategies in this tool, especially for
Chinese characters. For Chinese books, use zh-CN, zh-
TW, or zh-HK.
--newline_mode {single,double,none}
Choose the mode of detecting new paragraphs: ' single ' ,
' double ' , or ' none ' . ' single ' means a single newline
character, while ' double ' means two consecutive
newline characters. ' none ' means all newline
characters will be replace with blank so paragraphs
will not be detected. (default: double, works for most
ebooks but will detect less paragraphs for some
ebooks)
--title_mode {auto,tag_text,first_few}
Choose the parse mode for chapter title, ' tag_text '
search ' title ' , ' h1 ' , ' h2 ' , ' h3 ' tag for title,
' first_few ' set first 60 characters as title, ' auto '
auto apply the best mode for current chapter.
--chapter_start CHAPTER_START
Chapter start index (default: 1, starting from 1)
--chapter_end CHAPTER_END
Chapter end index (default: -1, meaning to the last
chapter)
--output_text Enable Output Text. This will export a plain text file
for each chapter specified and write the files to the
output folder specified.
--remove_endnotes This will remove endnote numbers from the end or
middle of sentences. This is useful for academic
books.
--search_and_replace_file SEARCH_AND_REPLACE_FILE
Path to a file that contains 1 regex replace per line,
to help with fixing pronunciations, etc. The format
is: <search>==<replace> Note that you may have to
specify word boundaries, to avoid replacing parts of
words.
--voice_name VOICE_NAME
Various TTS providers has different voice names, look
up for your provider settings.
--output_format OUTPUT_FORMAT
Output format for the text-to-speech service.
Supported format depends on selected TTS provider
--model_name MODEL_NAME
Various TTS providers has different neural model names
edge specific:
--voice_rate VOICE_RATE
Speaking rate of the text. Valid relative values range
from -50%(--xxx= ' -50% ' ) to +100%. For negative value
use format --arg=value,
--voice_volume VOICE_VOLUME
Volume level of the speaking voice. Valid relative
values floor to -100%. For negative value use format
--arg=value,
--voice_pitch VOICE_PITCH
Baseline pitch for the text.Valid relative values like
-80Hz,+50Hz, pitch changes should be within 0.5 to 1.5
times the original audio. For negative value use
format --arg=value,
--proxy PROXY Proxy server for the TTS provider. Format:
http://[username:password@]proxy.server:port
azure/edge specific:
--break_duration BREAK_DURATION
Break duration in milliseconds for the different
paragraphs or sections (default: 1250, means 1.25 s).
Valid values range from 0 to 5000 milliseconds for
Azure TTS.
piper specific:
--piper_path PIPER_PATH
Path to the Piper TTS executable
--piper_speaker PIPER_SPEAKER
Piper speaker id, used for multi-speaker models
--piper_sentence_silence PIPER_SENTENCE_SILENCE
Seconds of silence after each sentence
--piper_length_scale PIPER_LENGTH_SCALE
Phoneme length, a.k.a. speaking rateตัวอย่าง :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder การดำเนินการคำสั่งด้านบนจะสร้างไดเรกทอรีที่ชื่อ output_folder และบันทึกไฟล์ MP3 สำหรับแต่ละบทภายในโดยใช้ผู้ให้บริการ TTS เริ่มต้นและเสียง เมื่อสร้างขึ้นแล้วคุณสามารถนำเข้าไฟล์เสียงเหล่านี้ไปยัง AudioBookShelf หรือเล่นกับเครื่องเล่นเสียงใด ๆ ที่คุณเลือก
ก่อนที่จะแปลงไฟล์ epub ของคุณเป็นหนังสือเสียงคุณสามารถใช้ตัวเลือก --preview เพื่อรับบทสรุปของแต่ละบท สิ่งนี้จะช่วยให้คุณมีจำนวนอักขระของแต่ละบทและจำนวนรวมแทนที่จะแปลงข้อความเป็นคำพูด
ตัวอย่าง :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewคุณอาจต้องการค้นหาและแทนที่ข้อความเพื่อขยายตัวย่อหรือช่วยในการออกเสียง คุณสามารถทำได้โดยการระบุการค้นหาและแทนที่ไฟล์ซึ่งมีการค้นหา regex เดียวและแทนที่ต่อบรรทัดโดยคั่นด้วย '==':
ตัวอย่าง :
search.conf :
# this is the general structure
<search>==<replace>
# this is a comment
# fix cardinal direction abbreviations
N.E.==north east
# be careful with your regexes, as this would also match Sally N. Smith
N.==north
# pronounce Barbadoes like the locals
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.confตัวอย่าง :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewเครื่องมือนี้มีให้เป็นภาพนักเทียบท่าทำให้ง่ายต่อการทำงานโดยไม่จำเป็นต้องจัดการการพึ่งพา Python
ก่อนอื่นตรวจสอบให้แน่ใจว่าคุณติดตั้ง Docker ในระบบของคุณ
คุณสามารถดึงอิมเมจนักเทียบท่าจากรีจิสทรีคอนเทนเนอร์ GitHub:
docker pull ghcr.io/p0n1/epub_to_audiobook:latestจากนั้นคุณสามารถเรียกใช้เครื่องมือด้วยคำสั่งต่อไปนี้:
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY= $MS_TTS_KEY -e MS_TTS_REGION= $MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azureสำหรับ Openai คุณสามารถเรียกใช้:
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY= $OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai แทนที่ $MS_TTS_KEY และ $MS_TTS_REGION ด้วยข้อมูลรับรอง API Text-to-Speech API ของคุณ แทนที่ $OPENAI_API_KEY ด้วยคีย์ OpenAI API ของคุณ แทนที่ your_book.epub ด้วยชื่อของไฟล์อินพุต epub และ audiobook_output ด้วยชื่อของไดเรกทอรีที่คุณต้องการบันทึกไฟล์เอาต์พุต
ตัวเลือก -v ./:/app ติดตั้งไดเรกทอรีปัจจุบัน ( . ) ไปยังไดเรกทอรี /app ในคอนเทนเนอร์ Docker สิ่งนี้อนุญาตให้เครื่องมืออ่านไฟล์อินพุตและเขียนไฟล์เอาต์พุตไปยังระบบไฟล์โลคัลของคุณ
ตัวเลือก -i และ -t จำเป็นต้องมีเพื่อเปิดใช้งานโหมดอินเทอร์แอคทีฟและจัดสรร pseudo -tty
นอกจากนี้คุณยังสามารถตรวจสอบไฟล์กำหนดค่าตัวอย่างนี้สำหรับ Docker เขียนการใช้งาน
สำหรับผู้ใช้ Windows โดยเฉพาะอย่างยิ่งหากคุณไม่คุ้นเคยกับเครื่องมือบรรทัดคำสั่งเรามีคุณครอบคลุม เราเข้าใจถึงความท้าทายและได้สร้างคำแนะนำที่เหมาะกับคุณโดยเฉพาะ
ตรวจสอบคู่มือทีละขั้นตอนและฝากข้อความหากคุณพบปัญหา
ที่มา: https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/get-started-text-to-tarted-text-to-speech#preherequisites
ตรวจสอบ https://platform.openai.com/docs/quickstart/account-setup ตรวจสอบให้แน่ใจว่าคุณตรวจสอบรายละเอียดราคาก่อนใช้งาน
Edge TTS และ Azure TTS เกือบจะเหมือนกันความแตกต่างคือ Edge TTS ไม่ต้องการคีย์ API เพราะมันขึ้นอยู่กับฟังก์ชั่นการอ่านออกเสียงขอบและพารามิเตอร์จะถูก จำกัด เล็กน้อยเช่น SSML ที่กำหนดเอง
ตรวจสอบ https://gist.github.com/bettyjj/17cbaa1de96235a7f5773b8690a20462 สำหรับเสียงที่รองรับ
หากคุณต้องการลองใช้โครงการนี้อย่างรวดเร็วขอแนะนำให้ใช้ Edge TTS
คุณสามารถปรับแต่งเสียงและภาษาที่ใช้สำหรับการแปลงข้อความเป็นคำพูดโดยผ่านตัวเลือก --voice_name และ --language เมื่อเรียกใช้สคริปต์
Microsoft Azure นำเสนอเสียงและภาษาที่หลากหลายสำหรับบริการข้อความเป็นคำพูด สำหรับรายการตัวเลือกที่มีอยู่ให้ปรึกษาเอกสารประกอบการพูดข้อความของ Microsoft Azure
นอกจากนี้คุณยังสามารถฟังตัวอย่างเสียงที่มีอยู่ใน Azure TTS Voice Gallery เพื่อช่วยคุณเลือกเสียงที่ดีที่สุดสำหรับหนังสือเสียงของคุณ
ตัวอย่างเช่นหากคุณต้องการใช้เสียงผู้หญิงอังกฤษอังกฤษสำหรับการแปลงคุณสามารถใช้คำสั่งต่อไปนี้:
python3 main.py < input_file > < output_folder > --voice_name en-GB-LibbyNeural --language en-GB สำหรับ OpenAI TTS คุณสามารถระบุตัวเลือกโมเดลเสียงและรูปแบบโดยใช้ --model_name , --voice_name และ --output_format ตามลำดับ
นี่คือตัวอย่างบางส่วนที่แสดงให้เห็นถึงการผสมผสานตัวเลือกต่าง ๆ :
การแปลงขั้นพื้นฐานโดยใช้ Azure พร้อมการตั้งค่าเริ่มต้น
คำสั่งนี้จะแปลงไฟล์ epub เป็นหนังสือเสียงโดยใช้การตั้งค่า TTS เริ่มต้นของ Azure
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure การแปลง Azure ด้วยภาษาที่กำหนดเองเสียงและระดับการบันทึก
แปลงไฟล์ epub เป็นหนังสือเสียงด้วยเสียงที่ระบุและระดับบันทึกที่กำหนดเองเพื่อวัตถุประสงค์ในการแก้ไขข้อบกพร่อง
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --language zh-CN --voice_name " zh-CN-YunyeNeural " --log DEBUG การแปลง Azure กับช่วงบทและระยะเวลาพัก
แปลงช่วงของบทที่ระบุจากไฟล์ epub เป็นหนังสือเสียงที่มีระยะเวลาการหยุดพักที่กำหนดเองระหว่างวรรค
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --chapter_start 5 --chapter_end 10 --break_duration " 1500 " การแปลงขั้นพื้นฐานโดยใช้ openai พร้อมการตั้งค่าเริ่มต้น
คำสั่งนี้จะแปลงไฟล์ ePub เป็นหนังสือเสียงโดยใช้การตั้งค่า TTS เริ่มต้นของ OpenAI
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai การแปลง OpenAI ด้วยรุ่น HD และเสียงเฉพาะ
แปลงไฟล์ epub เป็นหนังสือเสียงโดยใช้โมเดล OpenAI ที่มีความละเอียดสูงและตัวเลือกเสียงเฉพาะ
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --model_name " tts-1-hd " --voice_name " fable " การแปลง OpenAI ด้วยการแสดงตัวอย่างและเอาต์พุตข้อความ
เปิดใช้งานโหมดตัวอย่างและเอาต์พุตข้อความซึ่งจะแสดงดัชนีบทและชื่อเรื่องแทนการแปลงและจะส่งออกข้อความด้วย
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --preview --output_text การแปลงขั้นพื้นฐานโดยใช้ขอบพร้อมการตั้งค่าเริ่มต้น
คำสั่งนี้จะแปลงไฟล์ epub เป็นหนังสือเสียงโดยใช้การตั้งค่า TTS เริ่มต้นของ Edge
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edgeการแปลงขอบด้วยภาษาที่กำหนดเองระดับเสียงและการบันทึก จะแปลงไฟล์ epub เป็นหนังสือเสียงด้วยเสียงที่ระบุและระดับบันทึกที่กำหนดเองเพื่อวัตถุประสงค์ในการดีบัก
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --language zh-CN --voice_name " zh-CN-YunxiNeural " --log DEBUGการแปลงขอบด้วยช่วงบทและช่วงเวลา การแบ่งช่วงเวลาที่กำหนดของบทที่ระบุจากไฟล์ epub ไปเป็นหนังสือเสียงที่มีระยะเวลาการหยุดพักที่กำหนดเองระหว่างวรรค
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --chapter_start 5 --chapter_end 10 --break_duration " 1500 "ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง Piper TTS และมีไฟล์รุ่น ONNX และไฟล์กำหนดค่าที่สอดคล้องกัน ตรวจสอบรายละเอียดเพิ่มเติมของ Piper TTS คุณสามารถทำตามคำแนะนำของพวกเขาเพื่อติดตั้ง Piper TTS ดาวน์โหลดรุ่นและไฟล์กำหนดค่าเล่นด้วยแล้วกลับมาลองตัวอย่างด้านล่าง
คำสั่งนี้จะแปลงไฟล์ epub เป็นหนังสือเสียงโดยใช้ Piper TTS โดยใช้พารามิเตอร์ขั้นต่ำเปล่า คุณจะต้องระบุไฟล์โมเดล ONNX เสมอและ piper Executable จำเป็นต้องอยู่ในเส้นทาง $ ปัจจุบัน
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx คุณสามารถระบุเส้นทางที่กำหนดเองของคุณไปยัง Piper Consenable โดยใช้พารามิเตอร์ --piper_path
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_path < path_to > /piperบางรุ่นรองรับเสียงหลายเสียงและสามารถระบุได้โดยใช้พารามิเตอร์ Voice_name
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256คุณยังสามารถระบุความเร็ว (piper_length_scale) และระยะเวลาหยุดชั่วคราว (piper_sentence_silence)
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 Piper TTS เอาต์พุตไฟล์รูปแบบ wav (หรือ RAW) โดยค่าเริ่มต้นคุณควรจะสามารถระบุรูปแบบที่สมเหตุสมผลใด ๆ ผ่านพารามิเตอร์ --output_format opus และ mp3 เป็นตัวเลือกที่ดีสำหรับขนาดและความเข้ากันได้
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opus อาจเป็นเพราะรุ่น Python ที่คุณใช้น้อยกว่า 3.8 คุณสามารถลองติดตั้งด้วยตนเองโดย pip3 install importlib-metadata หรือใช้รุ่น Python ที่สูงขึ้น
ตรวจสอบให้แน่ใจว่า FFMPEG ไบนารีสามารถเข้าถึงได้จากเส้นทางของคุณ หากคุณอยู่บน Mac และใช้ homebrew คุณสามารถทำการ brew install ffmpeg บน Ubuntu คุณสามารถทำการ sudo apt install ffmpeg
สำหรับปัญหาที่เกี่ยวข้องกับการติดตั้งโปรดดูที่ที่เก็บ Piper TTS เป็นสิ่งสำคัญที่จะต้องทราบว่าหากคุณกำลังติดตั้ง piper-tts ผ่าน PIP จะรองรับเฉพาะ Python 3.10 เท่านั้น ผู้ใช้ Mac อาจเผชิญกับความท้าทายเพิ่มเติมเมื่อใช้ไบนารีที่ดาวน์โหลดมา สำหรับข้อมูลเพิ่มเติมเกี่ยวกับปัญหาเฉพาะ MAC โปรดตรวจสอบปัญหานี้และคำขอดึงนี้
ตรวจสอบสิ่งนี้ด้วยว่าคุณมีปัญหากับ Piper TTS
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต MIT ดูไฟล์ใบอนุญาตสำหรับรายละเอียด


