epub_to_audiobook
v0.6.1
Junte -se ao nosso servidor Discord para obter perguntas ou discussões.
Este projeto fornece uma ferramenta de linha de comando para converter eBooks EPUB em audiolivros. Agora, ele suporta a API de texto para fala do Microsoft Azure (Alternativly Edgetts) e a API de texto em fala do OpenAI para gerar o áudio para cada capítulo no e-book. Os arquivos de áudio de saída são otimizados para uso com o AudioBookshelf.
Este projeto é desenvolvido com a ajuda do ChatGPT.
Se você estiver interessado em ouvir uma amostra do audiolivro gerado por esta ferramenta, verifique os links abaixo.
Os audiolivros gerados por este projeto são otimizados para uso com o AudioShelf. Cada capítulo no arquivo epub é convertido em um arquivo MP3 separado, com o título do capítulo extraído e incluído como metadados.
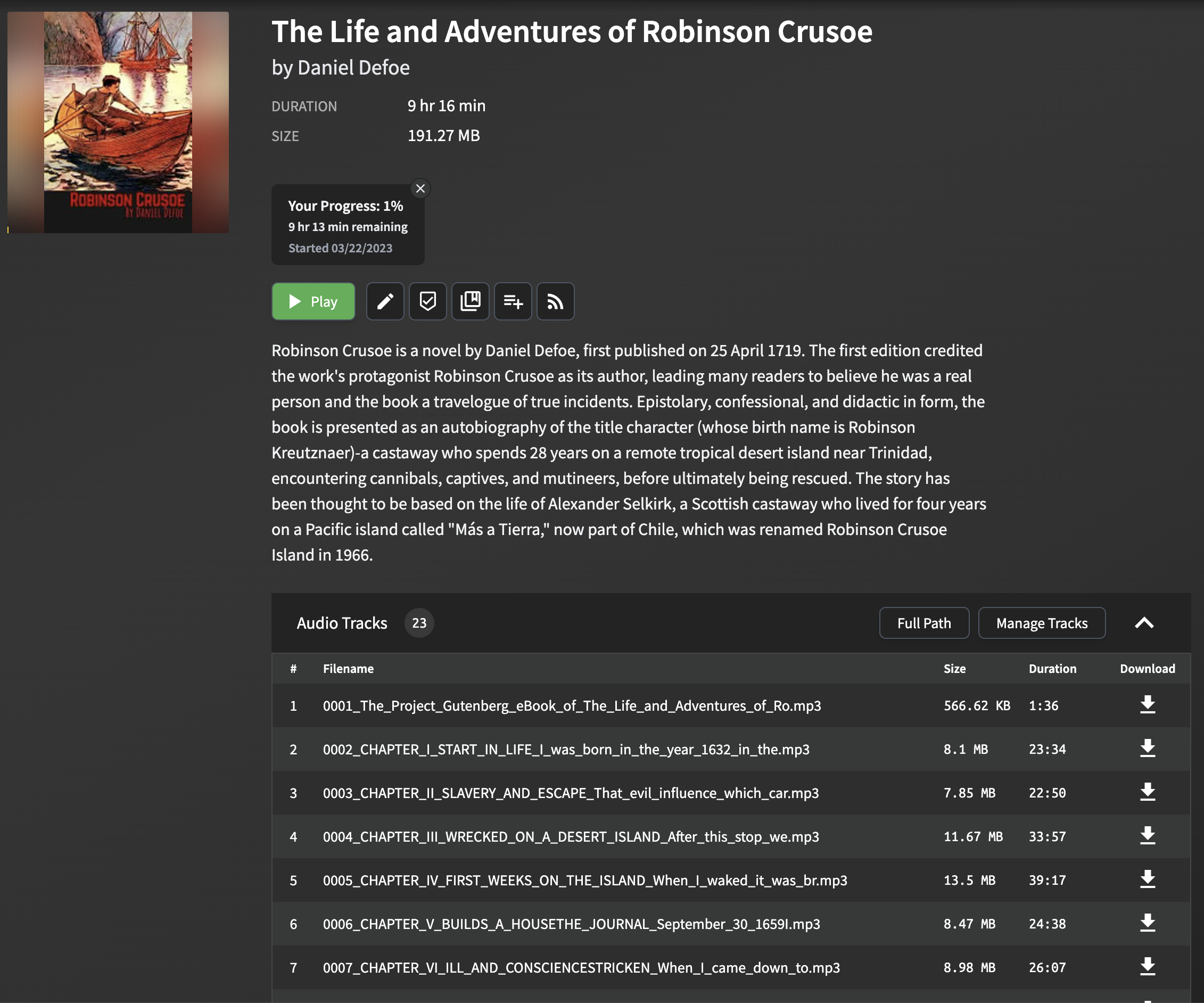
A análise e extração de títulos de capítulos dos arquivos EPUB pode ser desafiadora, pois o formato e a estrutura podem variar significativamente entre diferentes e -books. O script emprega um método simples, mas eficaz, para extrair títulos de capítulos, que funciona para a maioria dos arquivos EPUB. O método envolve analisar o arquivo EPUB e procurar a tag title no conteúdo HTML de cada capítulo. Se a tag de título não estiver presente, um título de fallback será gerado usando as primeiras palavras do texto do capítulo.
Observe que essa abordagem pode não funcionar perfeitamente para todos os arquivos EPUB, especialmente aqueles com formatação complexa ou incomum. No entanto, na maioria dos casos, fornece uma maneira confiável de extrair títulos de capítulos para uso no AudioShelf.
Quando você importa os arquivos MP3 gerados para o AudioShelf, os títulos dos capítulos serão exibidos, facilitando a navegação entre os capítulos e aprimorando sua experiência de audição.
Clone este repositório:
git clone https://github.com/p0n1/epub_to_audiobook.git
cd epub_to_audiobookCrie um ambiente virtual e ative -o:
python3 -m venv venv
source venv/bin/activateInstale as dependências necessárias:
pip install -r requirements.txtDefina as seguintes variáveis de ambiente com suas credenciais de API de texto para fala do Azure ou sua chave de API OpenAI se você estiver usando o OpenAI TTS:
export MS_TTS_KEY= < your_subscription_key > # for Azure
export MS_TTS_REGION= < your_region > # for Azure
export OPENAI_API_KEY= < your_openai_api_key > # for OpenAI Para converter um e -book Epub em um audiolivro, execute o seguinte comando, especificando o provedor TTS de sua escolha com a opção --tts :
python3 main.py < input_file > < output_folder > [options]Para verificar as descrições mais recentes da opção para este script, você pode executar o seguinte comando no terminal:
python3 main.py -husage: main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
Convert text book to audiobook
positional arguments:
input_file Path to the EPUB file
output_folder Path to the output folder
options:
-h, --help show this help message and exit
--tts {azure,openai,edge,piper}
Choose TTS provider (default: azure). azure: Azure
Cognitive Services, openai: OpenAI TTS API. When using
azure, environment variables MS_TTS_KEY and
MS_TTS_REGION must be set. When using openai,
environment variable OPENAI_API_KEY must be set.
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Log level (default: INFO), can be DEBUG, INFO,
WARNING, ERROR, CRITICAL
--preview Enable preview mode. In preview mode, the script will
not convert the text to speech. Instead, it will print
the chapter index, titles, and character counts.
--no_prompt Don ' t ask the user if they wish to continue after
estimating the cloud cost for TTS. Useful for
scripting.
--language LANGUAGE Language for the text-to-speech service (default: en-
US). For Azure TTS (--tts=azure), check
https://learn.microsoft.com/en-us/azure/ai-
services/speech-service/language-
support?tabs=tts#text-to-speech for supported
languages. For OpenAI TTS (--tts=openai), their API
detects the language automatically. But setting this
will also help on splitting the text into chunks with
different strategies in this tool, especially for
Chinese characters. For Chinese books, use zh-CN, zh-
TW, or zh-HK.
--newline_mode {single,double,none}
Choose the mode of detecting new paragraphs: ' single ' ,
' double ' , or ' none ' . ' single ' means a single newline
character, while ' double ' means two consecutive
newline characters. ' none ' means all newline
characters will be replace with blank so paragraphs
will not be detected. (default: double, works for most
ebooks but will detect less paragraphs for some
ebooks)
--title_mode {auto,tag_text,first_few}
Choose the parse mode for chapter title, ' tag_text '
search ' title ' , ' h1 ' , ' h2 ' , ' h3 ' tag for title,
' first_few ' set first 60 characters as title, ' auto '
auto apply the best mode for current chapter.
--chapter_start CHAPTER_START
Chapter start index (default: 1, starting from 1)
--chapter_end CHAPTER_END
Chapter end index (default: -1, meaning to the last
chapter)
--output_text Enable Output Text. This will export a plain text file
for each chapter specified and write the files to the
output folder specified.
--remove_endnotes This will remove endnote numbers from the end or
middle of sentences. This is useful for academic
books.
--search_and_replace_file SEARCH_AND_REPLACE_FILE
Path to a file that contains 1 regex replace per line,
to help with fixing pronunciations, etc. The format
is: <search>==<replace> Note that you may have to
specify word boundaries, to avoid replacing parts of
words.
--voice_name VOICE_NAME
Various TTS providers has different voice names, look
up for your provider settings.
--output_format OUTPUT_FORMAT
Output format for the text-to-speech service.
Supported format depends on selected TTS provider
--model_name MODEL_NAME
Various TTS providers has different neural model names
edge specific:
--voice_rate VOICE_RATE
Speaking rate of the text. Valid relative values range
from -50%(--xxx= ' -50% ' ) to +100%. For negative value
use format --arg=value,
--voice_volume VOICE_VOLUME
Volume level of the speaking voice. Valid relative
values floor to -100%. For negative value use format
--arg=value,
--voice_pitch VOICE_PITCH
Baseline pitch for the text.Valid relative values like
-80Hz,+50Hz, pitch changes should be within 0.5 to 1.5
times the original audio. For negative value use
format --arg=value,
--proxy PROXY Proxy server for the TTS provider. Format:
http://[username:password@]proxy.server:port
azure/edge specific:
--break_duration BREAK_DURATION
Break duration in milliseconds for the different
paragraphs or sections (default: 1250, means 1.25 s).
Valid values range from 0 to 5000 milliseconds for
Azure TTS.
piper specific:
--piper_path PIPER_PATH
Path to the Piper TTS executable
--piper_speaker PIPER_SPEAKER
Piper speaker id, used for multi-speaker models
--piper_sentence_silence PIPER_SENTENCE_SILENCE
Seconds of silence after each sentence
--piper_length_scale PIPER_LENGTH_SCALE
Phoneme length, a.k.a. speaking rateExemplo :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder A execução do comando acima gerará um diretório chamado output_folder e salvará os arquivos MP3 para cada capítulo dentro dele usando o provedor e a voz padrão do TTS. Uma vez gerado, você pode importar esses arquivos de áudio para o AudioShelf ou reproduzi -los com qualquer player de áudio de sua escolha.
Antes de converter seu arquivo EPUB em um audiolivro, você pode usar a opção --preview para obter um resumo de cada capítulo. Isso fornecerá a você a contagem de personagens de cada capítulo e a contagem total, em vez de converter o texto em fala.
Exemplo :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewVocê pode pesquisar e substituir o texto, para expandir as abreviações ou ajudar na pronúncia. Você pode fazer isso especificando um arquivo de pesquisa e substituição, que contém uma única pesquisa regex e substitua por linha, separada por '==':
Exemplo :
search.conf :
# this is the general structure
<search>==<replace>
# this is a comment
# fix cardinal direction abbreviations
N.E.==north east
# be careful with your regexes, as this would also match Sally N. Smith
N.==north
# pronounce Barbadoes like the locals
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.confExemplo :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewEsta ferramenta está disponível como uma imagem do Docker, facilitando a execução sem a necessidade de gerenciar dependências do Python.
Primeiro, verifique se você está instalado no Docker no seu sistema.
Você pode puxar a imagem do Docker do Registro de Contêineres do Github:
docker pull ghcr.io/p0n1/epub_to_audiobook:latestEm seguida, você pode executar a ferramenta com o seguinte comando:
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY= $MS_TTS_KEY -e MS_TTS_REGION= $MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azurePara o OpenAI, você pode correr:
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY= $OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai Substitua $MS_TTS_KEY e $MS_TTS_REGION pelas suas credenciais da API de texto para fala do Azure. Substitua $OPENAI_API_KEY pela sua tecla API OpenAI. Substitua your_book.epub pelo nome do arquivo EPUB de entrada e audiobook_output com o nome do diretório em que você deseja salvar os arquivos de saída.
A opção -v ./:/app monta o diretório atual ( . ) Para o diretório /app no contêiner do docker. Isso permite que a ferramenta leia o arquivo de entrada e grava os arquivos de saída no sistema de arquivos local.
As opções -i e -t são necessárias para ativar o modo interativo e alocar um pseudo -tty.
Você também pode verificar o arquivo de configuração deste exemplo para o uso do Docker compor.
Para os usuários do Windows, especialmente se você não estiver muito familiarizado com as ferramentas de linha de comando, temos você coberto. Entendemos os desafios e criamos um guia especificamente adaptado para você.
Verifique este guia passo a passo e deixe uma mensagem se encontrar problemas.
Fonte: https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/get-started-text-topeech#prerequisites
Verifique https://platform.openai.com/docs/quickstart/account-setup. Verifique os detalhes do preço antes do uso.
TTS de borda e Azure TTS são quase iguais, a diferença é que os TTs de borda não requerem a chave da API porque é baseada na funcionalidade de leitura em voz alta e os parâmetros são restritos um pouco, como o SSML personalizado.
Verifique https://gist.github.com/bettyjj/17cbaa1de96235a7f5773b8690a20462 para vozes suportadas.
Se você deseja experimentar este projeto rapidamente, o Edge TTS é altamente recomendado.
Você pode personalizar a voz e a linguagem usadas para a conversão de texto em fala, passando as opções --voice_name e --language ao executar o script.
O Microsoft Azure oferece uma variedade de vozes e idiomas para o serviço de texto em fala. Para obter uma lista de opções disponíveis, consulte a documentação do Microsoft Azure Text-topeel.
Você também pode ouvir amostras das vozes disponíveis na galeria de voz do Azure TTS para ajudá -lo a escolher a melhor voz para o seu audiolivro.
Por exemplo, se você deseja usar uma voz feminina inglesa britânica para a conversão, poderá usar o seguinte comando:
python3 main.py < input_file > < output_folder > --voice_name en-GB-LibbyNeural --language en-GB Para o OpenAI TTS, você pode especificar as opções de modelo, voz e formato usando --model_name , --voice_name e --output_format , respectivamente.
Aqui estão alguns exemplos que demonstram várias combinações de opções:
Conversão básica usando o Azure com configurações padrão
Este comando converterá um arquivo EPUB em um audiolivro usando as configurações TTS padrão do Azure.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure Conversão do Azure com linguagem, voz e nível de log personalizados
Converte um arquivo EPUB em um audiolivro com uma voz especificada e um nível de log personalizado para fins de depuração.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --language zh-CN --voice_name " zh-CN-YunyeNeural " --log DEBUG Conversão do Azure com o alcance do capítulo e duração do intervalo
Converte uma gama especificada de capítulos de um arquivo EPUB em um audiolivro com duração personalizada entre parágrafos.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --chapter_start 5 --chapter_end 10 --break_duration " 1500 " Conversão básica usando o OpenAI com configurações padrão
Este comando converterá um arquivo EPUB em um audiolivro usando as configurações de TTS padrão do OpenAI.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai Conversão OpenAI com modelo HD e voz específica
Converte um arquivo EPUB em um audiolivro usando o modelo OpenAI de alta definição e uma opção de voz específica.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --model_name " tts-1-hd " --voice_name " fable " Conversão OpenAI com visualização e saída de texto
Ativa o modo de visualização e a saída de texto, que exibirá o índice e os títulos do capítulo em vez de convertê -los e também exportará o texto.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --preview --output_text Conversão básica usando borda com configurações padrão
Este comando converterá um arquivo EPUB em um audiolivro usando as configurações de TTS padrão do Edge.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edgeA conversão de borda com nível de linguagem, voz e log de arestas converte um arquivo EPUB em um audiolivro com uma voz especificada e um nível de log personalizado para fins de depuração.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --language zh-CN --voice_name " zh-CN-YunxiNeural " --log DEBUGA conversão de borda com o intervalo de capítulos e a duração da interrupção converte um intervalo especificado de capítulos de um arquivo EPUB em um audiolivro com duração de quebra personalizada entre os parágrafos.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --chapter_start 5 --chapter_end 10 --break_duration " 1500 "Verifique se você instalou o Piper TTS e tenha um arquivo de modelo ONNX e o arquivo de configuração correspondente. Verifique o Piper TTS para obter mais detalhes. Você pode seguir as instruções deles para instalar o Piper TTS, baixar os modelos e configurar arquivos, reproduzir com ele e depois voltar para experimentar os exemplos abaixo.
Este comando converterá um arquivo epub em um audiolivro usando o Piper TTS usando os parâmetros mínimos vazios. Você sempre precisa especificar um arquivo de modelo ONNX e o executável piper precisa estar no caminho atual $.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx Você pode especificar seu caminho personalizado para o executável do Piper usando o parâmetro --piper_path .
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_path < path_to > /piperAlguns modelos suportam várias vozes e podem ser especificadas usando o parâmetro Voice_Name.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256Você também pode especificar a velocidade (Piper_Length_Scale) e a duração da pausa (PIPER_SENTENCE_SILENCE).
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 Piper TTS Saídas Arquivos de formato wav (ou RAW) Por padrão, você poderá especificar qualquer formato razoável através do parâmetro --output_format . O opus e mp3 são boas opções para tamanho e compatibilidade.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opus Isso pode ser porque a versão python que você está usando é menor que 3,8. Você pode tentar instalá-lo manualmente por pip3 install importlib-metadata ou usar uma versão Python mais alta.
Certifique -se de que o FFMPEG binário esteja acessível a partir do seu caminho. Se você estiver em um Mac e use homebrew, pode fazer brew install ffmpeg , no Ubuntu, você pode fazer sudo apt install ffmpeg
Para problemas relacionados à instalação, consulte o repositório Piper TTS. É importante observar que, se você estiver instalando piper-tts via PIP, apenas o Python 3.10 será suportado atualmente. Os usuários de Mac podem enfrentar desafios adicionais ao usar o binário baixado. Para obter mais informações sobre questões específicas do Mac, verifique este problema e esta solicitação de tração.
Verifique também isso se você estiver tendo problemas com o Piper TTS.
Este projeto está licenciado sob a licença do MIT. Consulte o arquivo de licença para obter detalhes.


