epub_to_audiobook
v0.6.1
Присоединяйтесь к нашему серверу Discord для любых вопросов или обсуждений.
Этот проект предоставляет инструмент командной строки для преобразования электронных книг EPUB в аудиокниги. Теперь он поддерживает как API Microsoft Azure Text-To Speek (Alternativly Edgetts), так и API Openai Text-To Speek для создания звука для каждой главы в электронной книге. Выходные аудиофайлы оптимизированы для использования с аудиоксипкой.
Этот проект разработан с помощью CHATGPT.
Если вы заинтересованы в том, чтобы услышать образец аудиокниги, сгенерированной этим инструментом, проверьте ссылки.
Аудиокниги, сгенерированные этим проектом, оптимизированы для использования с аудиокнижью. Каждая глава в файле EPUB преобразуется в отдельный файл MP3, с извлеченным и включенным в качестве метаданных.
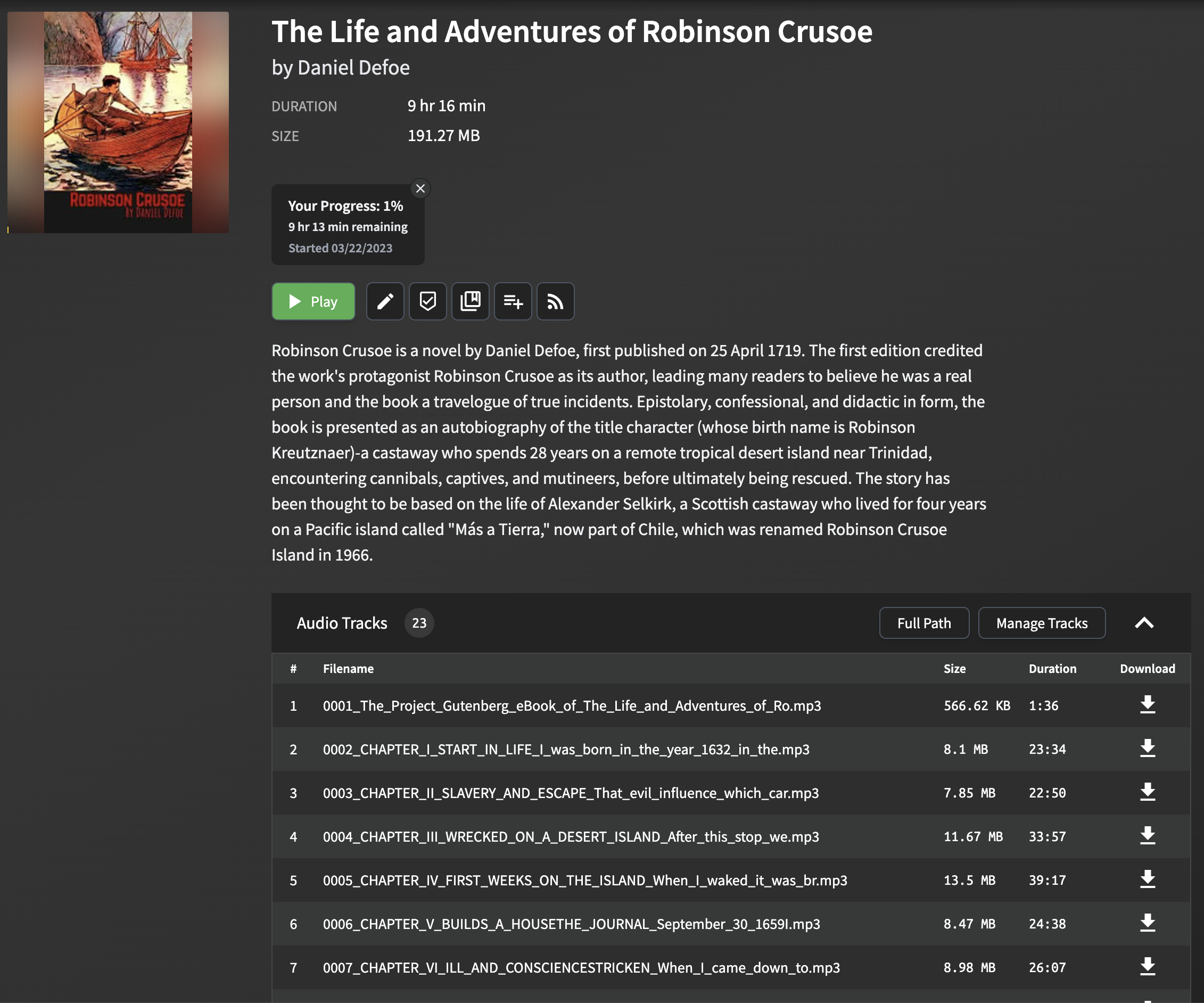
Расположение и извлечение названий главах из файлов EPUB может быть сложным, так как формат и структура могут значительно варьироваться между различными электронными книгами. В скрипте используется простой, но эффективный метод для извлечения заголовков глава, который работает для большинства файлов EPUB. Метод включает в себя анализ файла EPUB и поиск тега title в HTML -содержании каждой главы. Если тег заголовка не присутствует, название запасного пути генерируется с использованием первых нескольких слов текста главы.
Обратите внимание, что этот подход может не отлично работать для всех файлов EPUB, особенно с сложным или необычным форматированием. Тем не менее, в большинстве случаев он обеспечивает надежный способ извлечения заголовков глава для использования в аудиокнижью.
Когда вы импортируете сгенерированные файлы MP3 в аудиоксипцию, будут отображаться заголовки главы, что позволяет легко ориентироваться между главами и улучшая ваш опыт прослушивания.
Клонировать это хранилище:
git clone https://github.com/p0n1/epub_to_audiobook.git
cd epub_to_audiobookСоздайте виртуальную среду и активируйте ее:
python3 -m venv venv
source venv/bin/activateУстановите требуемые зависимости:
pip install -r requirements.txtУстановите следующие переменные среды с помощью ваших учетных данных API Text-Speek Text-Speech или вашим ключом API OpenAI, если вы используете Openai TTS:
export MS_TTS_KEY= < your_subscription_key > # for Azure
export MS_TTS_REGION= < your_region > # for Azure
export OPENAI_API_KEY= < your_openai_api_key > # for OpenAI Чтобы преобразовать электронную книгу EPUB в аудиокнигу, запустите следующую команду, указав поставщик TTS по вашему выбору с помощью опции --tts :
python3 main.py < input_file > < output_folder > [options]Чтобы проверить последние описания опций для этого сценария, вы можете запустить следующую команду в терминале:
python3 main.py -husage: main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
Convert text book to audiobook
positional arguments:
input_file Path to the EPUB file
output_folder Path to the output folder
options:
-h, --help show this help message and exit
--tts {azure,openai,edge,piper}
Choose TTS provider (default: azure). azure: Azure
Cognitive Services, openai: OpenAI TTS API. When using
azure, environment variables MS_TTS_KEY and
MS_TTS_REGION must be set. When using openai,
environment variable OPENAI_API_KEY must be set.
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Log level (default: INFO), can be DEBUG, INFO,
WARNING, ERROR, CRITICAL
--preview Enable preview mode. In preview mode, the script will
not convert the text to speech. Instead, it will print
the chapter index, titles, and character counts.
--no_prompt Don ' t ask the user if they wish to continue after
estimating the cloud cost for TTS. Useful for
scripting.
--language LANGUAGE Language for the text-to-speech service (default: en-
US). For Azure TTS (--tts=azure), check
https://learn.microsoft.com/en-us/azure/ai-
services/speech-service/language-
support?tabs=tts#text-to-speech for supported
languages. For OpenAI TTS (--tts=openai), their API
detects the language automatically. But setting this
will also help on splitting the text into chunks with
different strategies in this tool, especially for
Chinese characters. For Chinese books, use zh-CN, zh-
TW, or zh-HK.
--newline_mode {single,double,none}
Choose the mode of detecting new paragraphs: ' single ' ,
' double ' , or ' none ' . ' single ' means a single newline
character, while ' double ' means two consecutive
newline characters. ' none ' means all newline
characters will be replace with blank so paragraphs
will not be detected. (default: double, works for most
ebooks but will detect less paragraphs for some
ebooks)
--title_mode {auto,tag_text,first_few}
Choose the parse mode for chapter title, ' tag_text '
search ' title ' , ' h1 ' , ' h2 ' , ' h3 ' tag for title,
' first_few ' set first 60 characters as title, ' auto '
auto apply the best mode for current chapter.
--chapter_start CHAPTER_START
Chapter start index (default: 1, starting from 1)
--chapter_end CHAPTER_END
Chapter end index (default: -1, meaning to the last
chapter)
--output_text Enable Output Text. This will export a plain text file
for each chapter specified and write the files to the
output folder specified.
--remove_endnotes This will remove endnote numbers from the end or
middle of sentences. This is useful for academic
books.
--search_and_replace_file SEARCH_AND_REPLACE_FILE
Path to a file that contains 1 regex replace per line,
to help with fixing pronunciations, etc. The format
is: <search>==<replace> Note that you may have to
specify word boundaries, to avoid replacing parts of
words.
--voice_name VOICE_NAME
Various TTS providers has different voice names, look
up for your provider settings.
--output_format OUTPUT_FORMAT
Output format for the text-to-speech service.
Supported format depends on selected TTS provider
--model_name MODEL_NAME
Various TTS providers has different neural model names
edge specific:
--voice_rate VOICE_RATE
Speaking rate of the text. Valid relative values range
from -50%(--xxx= ' -50% ' ) to +100%. For negative value
use format --arg=value,
--voice_volume VOICE_VOLUME
Volume level of the speaking voice. Valid relative
values floor to -100%. For negative value use format
--arg=value,
--voice_pitch VOICE_PITCH
Baseline pitch for the text.Valid relative values like
-80Hz,+50Hz, pitch changes should be within 0.5 to 1.5
times the original audio. For negative value use
format --arg=value,
--proxy PROXY Proxy server for the TTS provider. Format:
http://[username:password@]proxy.server:port
azure/edge specific:
--break_duration BREAK_DURATION
Break duration in milliseconds for the different
paragraphs or sections (default: 1250, means 1.25 s).
Valid values range from 0 to 5000 milliseconds for
Azure TTS.
piper specific:
--piper_path PIPER_PATH
Path to the Piper TTS executable
--piper_speaker PIPER_SPEAKER
Piper speaker id, used for multi-speaker models
--piper_sentence_silence PIPER_SENTENCE_SILENCE
Seconds of silence after each sentence
--piper_length_scale PIPER_LENGTH_SCALE
Phoneme length, a.k.a. speaking rateПример :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder Выполнение вышеуказанной команды будет генерировать каталог с именем output_folder и сохранить файлы mp3 для каждой главы внутри нее, используя поставщик TTS по умолчанию и голос. После создания вы можете импортировать эти аудиофайлы в аудиоксипку или воспроизвести их с любым аудиоплеерным игроком по вашему выбору.
Прежде чем преобразовать ваш файл ePUB в аудиокнигу, вы можете использовать опцию --preview , чтобы получить сводку каждой главы. Это предоставит вам количество символов каждой главы и общее количество, вместо того, чтобы преобразовать текст в речь.
Пример :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewВы можете искать и заменить текст, чтобы расширить сокращения, либо помочь с произношением. Вы можете сделать это, указав файл поиска и замены, который содержит один поиск и заменить одну режиму REGEX, разделенную на '==':
Пример :
search.conf :
# this is the general structure
<search>==<replace>
# this is a comment
# fix cardinal direction abbreviations
N.E.==north east
# be careful with your regexes, as this would also match Sally N. Smith
N.==north
# pronounce Barbadoes like the locals
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.confПример :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewЭтот инструмент доступен в виде изображения Docker, что позволяет легко работать без необходимости управления зависимостями Python.
Во -первых, убедитесь, что в вашей системе установлен Docker.
Вы можете вытащить изображение Docker из реестра контейнеров GitHub:
docker pull ghcr.io/p0n1/epub_to_audiobook:latestЗатем вы можете запустить инструмент со следующей командой:
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY= $MS_TTS_KEY -e MS_TTS_REGION= $MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azureДля Openai вы можете бежать:
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY= $OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai Замените $MS_TTS_KEY и $MS_TTS_REGION на свои учетные данные API Text-To-Speek. Замените $OPENAI_API_KEY на ключ Openai API. Замените your_book.epub с именем файла ввода epub и audiobook_output с именем каталога, где вы хотите сохранить выходные файлы.
Опция -v ./:/app объединяет текущий каталог ( . ) В каталог /app в контейнере Docker. Это позволяет инструменту прочитать входной файл и записывать выходные файлы в вашу локальную файловую систему.
Параметры -i и -t необходимы для включения интерактивного режима и выделения псевдо -tty.
Вы также можете проверить этот пример файл конфигурации для использования Docker Compose.
Для пользователей Windows, особенно если вы не очень хорошо знакомы с инструментами командной строки, мы предоставляем вам вас. Мы понимаем проблемы и создали руководство, специально предназначенное для вас.
Проверьте это пошаговое руководство и оставьте сообщение, если вы столкнетесь с проблемами.
Источник: https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/get-started-text-to-speech#perequisites
Проверьте https://platform.openai.com/docs/quickstart/account-setup. Убедитесь, что вы проверяете детали цены перед использованием.
Edge TTS и Azure TTS практически одинаковы, разница в том, что Edge TTS не требует ключа API, потому что он основан на функциональности чтения Edge, а параметры немного ограничены, как пользовательский SSML.
Проверьте https://gist.github.com/bettyjj/17cbaa1de96235a7f5773b8690a20462 для поддерживаемых голосов.
Если вы хотите быстро попробовать этот проект, настоятельно рекомендуется Edge TTS.
Вы можете настроить голос и язык, используемый для преобразования текста в речь, передавая параметры --voice_name и --language при запуске сценария.
Microsoft Azure предлагает ряд голосов и языков для сервиса текста в речь. Чтобы получить список доступных вариантов, обратитесь к документации Microsoft Azure Text-To Speek.
Вы также можете слушать образцы доступных голосов в галерее Voice Azure TTS, чтобы помочь вам выбрать лучший голос для вашей аудиокниги.
Например, если вы хотите использовать британский английский женский голос для преобразования, вы можете использовать следующую команду:
python3 main.py < input_file > < output_folder > --voice_name en-GB-LibbyNeural --language en-GB Для Openai TTS вы можете указать параметры модели, голоса и формата, используя --model_name , --voice_name и --output_format соответственно.
Вот несколько примеров, которые демонстрируют различные комбинации вариантов:
Базовое преобразование с использованием Azure с настройками по умолчанию
Эта команда преобразует файл EPUB в аудиокнигу с помощью настройки TTS по умолчанию Azure.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure Преобразование лазурного языка с пользовательским языком, голосом и уровнем ведения журнала
Преобразует файл EPUB в аудиокнигу с указанным голосом и пользовательским уровнем журнала для отладки.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --language zh-CN --voice_name " zh-CN-YunyeNeural " --log DEBUG Преобразование лазурного диапазона и продолжительность разрыва и продолжительность разрыва
Преобразует указанный диапазон глав из файла EPUB в аудиокнигу с нестандартной продолжительностью разрыва между абзацами.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --chapter_start 5 --chapter_end 10 --break_duration " 1500 " Базовое преобразование с использованием OpenAI с настройками по умолчанию
Эта команда будет преобразовать файл EPUB в аудиокнигу, используя настройки TTS Openai по умолчанию.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai Преобразование OpenAI с HD -моделью и конкретным голосом
Преобразует файл EPUB в аудиокнигу, используя модель Openai в высокой четкости и определенный выбор голоса.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --model_name " tts-1-hd " --voice_name " fable " Openai преобразование с предварительным просмотром и выводом текста
Включает режим предварительного просмотра и вывод текста, который будет отображать индекс главы и заголовки вместо преобразования их, а также будет экспортировать текст.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --preview --output_text Базовое преобразование с использованием Edge с настройками по умолчанию
Эта команда преобразует файл EPUB в аудиокнигу с помощью настройки TTS по умолчанию Edge.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edgeПреобразование края с помощью пользовательского языка, уровня голоса и журнала преобразует файл EPUB в аудиокнигу с указанным голосом и пользовательским уровнем журнала для целей отладки.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --language zh-CN --voice_name " zh-CN-YunxiNeural " --log DEBUGПреобразование края с диапазоном главы и продолжительностью разрыва преобразует указанный диапазон глав из файла EPUB в аудиокнигу с пользовательской продолжительностью разрыва между абзацами.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --chapter_start 5 --chapter_end 10 --break_duration " 1500 "Убедитесь, что у вас установили Piper TTS и имели файл модели ONNX и соответствующий файл конфигурации. Проверьте Piper TTS для получения более подробной информации. Вы можете следовать их инструкциям по установке Piper TTS, загрузки моделей и файлов конфигурации, воспроизвести с ним, а затем вернуться, чтобы попробовать примеры ниже.
Эта команда будет конвертировать файл EPUB в аудиокнигу с использованием Piper TTS с использованием минимальных параметров. Вам всегда нужно указать файл модели ONNX, и исполняемый файл piper должен быть в текущем пути $.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx Вы можете указать свой пользовательский путь к исполняемому файлу Piper, используя параметр --piper_path .
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_path < path_to > /piperНекоторые модели поддерживают несколько голосов, и это можно указать, используя параметр Voice_Name.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256Вы также можете указать скорость (piper_length_scale) и продолжительность паузы (piper_sentence_silence).
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 Piper TTS выходы файлов формата wav (или RAW) По умолчанию вы сможете указать любой разумный формат через параметр --output_format . opus и mp3 являются хорошим выбором для размера и совместимости.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opus Это может быть связано с тем, что версия Python, которую вы используете, меньше 3,8. Вы можете попытаться вручную установить его на pip3 install importlib-metadata или использовать более высокую версию Python.
Убедитесь, что FFMPEG Binary доступен с вашего пути. Если вы находитесь на Mac и используете Homebrew, вы можете сделать brew install ffmpeg , на Ubuntu вы можете сделать sudo apt install ffmpeg
Для проблем, связанных с установкой, пожалуйста, обратитесь к репозиторию Piper TTS. Важно отметить, что если вы устанавливаете piper-tts через PIP, в настоящее время поддерживается только Python 3.10. Пользователи Mac могут столкнуться с дополнительными проблемами при использовании загруженного двоичного файла. Для получения дополнительной информации по вопросам, специфичным для MAC, пожалуйста, проверьте эту проблему и этот запрос на привлечение.
Также проверьте это, если у вас проблемы с Piper TTS.
Этот проект лицензирован по лицензии MIT. Смотрите файл лицензии для получения подробной информации.


