epub_to_audiobook
v0.6.1
質問や議論については、Discord Serverに参加してください。
このプロジェクトは、Epub eBooksをオーディオブックに変換するためのコマンドラインツールを提供します。現在、Microsoft Azure Text-to-Speech API(Alternativly Edgetts)とOpenaiテキストからスピーチAPIの両方をサポートして、電子書籍の各章のオーディオを生成します。出力オーディオファイルは、オーディオブックシェルフで使用するために最適化されています。
このプロジェクトは、ChatGptの助けを借りて開発されました。
このツールによって生成されたオーディオブックのサンプルを聞くことに興味がある場合は、リンクを確認してください。
このプロジェクトによって生成されたオーディオブックは、オーディオブックシェルフで使用するために最適化されています。 epubファイルの各章は別のMP3ファイルに変換され、章のタイトルが抽出され、メタデータとして含まれています。
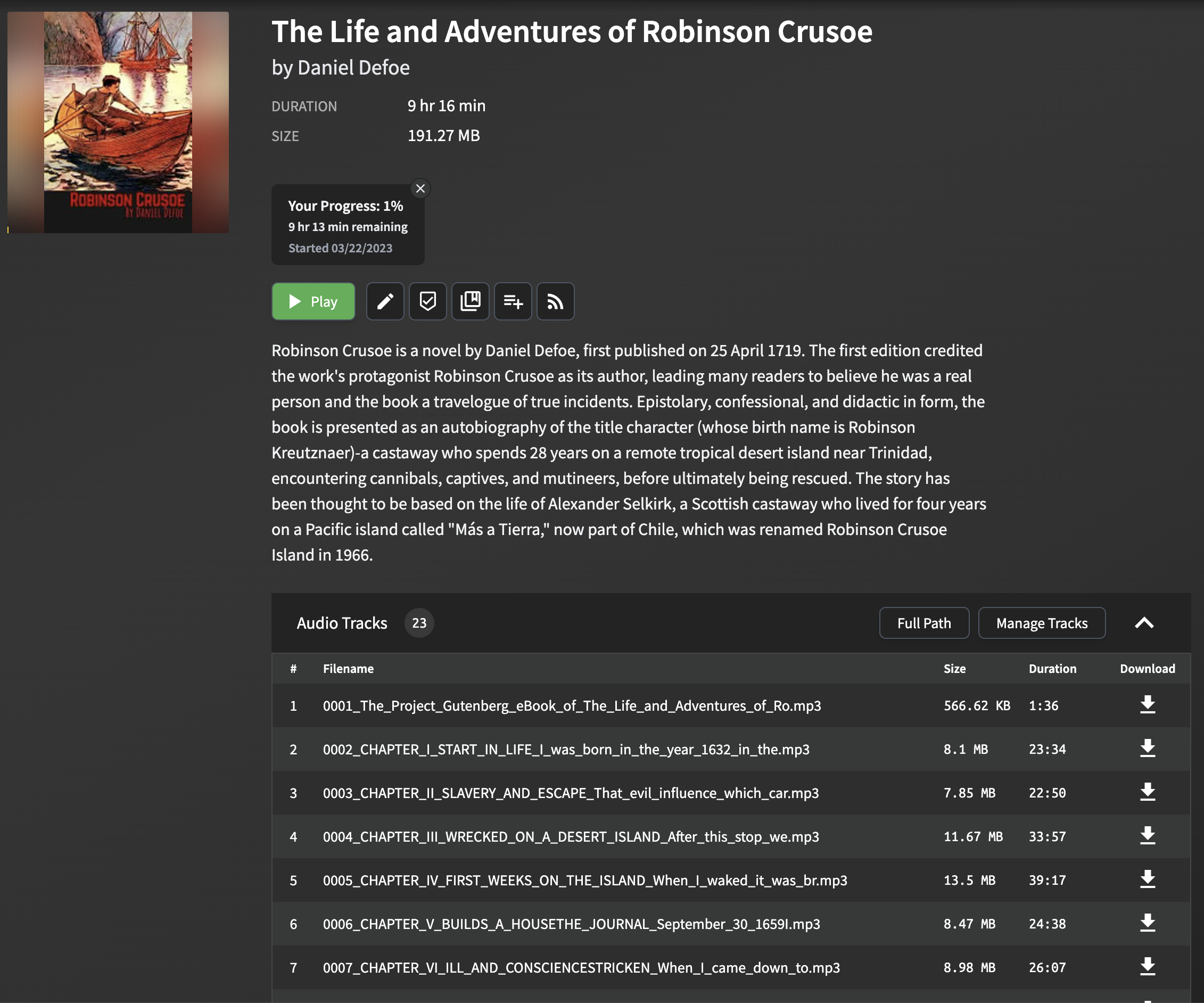
Epubファイルからの章のタイトルの解析と抽出は、形式と構造が異なる電子ブック間で大幅に異なる場合があるため、困難な場合があります。このスクリプトは、ほとんどのEPUBファイルで機能する章のタイトルを抽出するためのシンプルだが効果的な方法を採用しています。このメソッドには、epubファイルを解析し、各章のHTMLコンテンツでtitleタグを探すことが含まれます。タイトルタグが存在しない場合、チャプターテキストの最初のいくつかの単語を使用して、フォールバックタイトルが生成されます。
このアプローチは、すべてのEPUBファイル、特に複雑なフォーマットまたは異常なフォーマットを持つファイルで完全に機能しない場合があることに注意してください。ただし、ほとんどの場合、オーディオブックシェルフで使用するための章のタイトルを抽出する信頼できる方法を提供します。
生成されたmp3ファイルをAudiobookshelfにインポートすると、章のタイトルが表示され、章の間を簡単に移動し、リスニングエクスペリエンスを向上させます。
このリポジトリをクローンします:
git clone https://github.com/p0n1/epub_to_audiobook.git
cd epub_to_audiobook仮想環境を作成してアクティブ化します。
python3 -m venv venv
source venv/bin/activate必要な依存関係をインストールします。
pip install -r requirements.txtAzure Text-to-Speech API資格情報で次の環境変数を設定するか、OpenAI TTSを使用している場合はOpenAI APIキーを設定します。
export MS_TTS_KEY= < your_subscription_key > # for Azure
export MS_TTS_REGION= < your_region > # for Azure
export OPENAI_API_KEY= < your_openai_api_key > # for OpenAI epub ebookをオーディオブックに変換するには、次のコマンドを実行して、 --ttsオプションで選択したTTSプロバイダーを指定します。
python3 main.py < input_file > < output_folder > [options]このスクリプトの最新のオプションの説明を確認するには、端末で次のコマンドを実行できます。
python3 main.py -husage: main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
Convert text book to audiobook
positional arguments:
input_file Path to the EPUB file
output_folder Path to the output folder
options:
-h, --help show this help message and exit
--tts {azure,openai,edge,piper}
Choose TTS provider (default: azure). azure: Azure
Cognitive Services, openai: OpenAI TTS API. When using
azure, environment variables MS_TTS_KEY and
MS_TTS_REGION must be set. When using openai,
environment variable OPENAI_API_KEY must be set.
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Log level (default: INFO), can be DEBUG, INFO,
WARNING, ERROR, CRITICAL
--preview Enable preview mode. In preview mode, the script will
not convert the text to speech. Instead, it will print
the chapter index, titles, and character counts.
--no_prompt Don ' t ask the user if they wish to continue after
estimating the cloud cost for TTS. Useful for
scripting.
--language LANGUAGE Language for the text-to-speech service (default: en-
US). For Azure TTS (--tts=azure), check
https://learn.microsoft.com/en-us/azure/ai-
services/speech-service/language-
support?tabs=tts#text-to-speech for supported
languages. For OpenAI TTS (--tts=openai), their API
detects the language automatically. But setting this
will also help on splitting the text into chunks with
different strategies in this tool, especially for
Chinese characters. For Chinese books, use zh-CN, zh-
TW, or zh-HK.
--newline_mode {single,double,none}
Choose the mode of detecting new paragraphs: ' single ' ,
' double ' , or ' none ' . ' single ' means a single newline
character, while ' double ' means two consecutive
newline characters. ' none ' means all newline
characters will be replace with blank so paragraphs
will not be detected. (default: double, works for most
ebooks but will detect less paragraphs for some
ebooks)
--title_mode {auto,tag_text,first_few}
Choose the parse mode for chapter title, ' tag_text '
search ' title ' , ' h1 ' , ' h2 ' , ' h3 ' tag for title,
' first_few ' set first 60 characters as title, ' auto '
auto apply the best mode for current chapter.
--chapter_start CHAPTER_START
Chapter start index (default: 1, starting from 1)
--chapter_end CHAPTER_END
Chapter end index (default: -1, meaning to the last
chapter)
--output_text Enable Output Text. This will export a plain text file
for each chapter specified and write the files to the
output folder specified.
--remove_endnotes This will remove endnote numbers from the end or
middle of sentences. This is useful for academic
books.
--search_and_replace_file SEARCH_AND_REPLACE_FILE
Path to a file that contains 1 regex replace per line,
to help with fixing pronunciations, etc. The format
is: <search>==<replace> Note that you may have to
specify word boundaries, to avoid replacing parts of
words.
--voice_name VOICE_NAME
Various TTS providers has different voice names, look
up for your provider settings.
--output_format OUTPUT_FORMAT
Output format for the text-to-speech service.
Supported format depends on selected TTS provider
--model_name MODEL_NAME
Various TTS providers has different neural model names
edge specific:
--voice_rate VOICE_RATE
Speaking rate of the text. Valid relative values range
from -50%(--xxx= ' -50% ' ) to +100%. For negative value
use format --arg=value,
--voice_volume VOICE_VOLUME
Volume level of the speaking voice. Valid relative
values floor to -100%. For negative value use format
--arg=value,
--voice_pitch VOICE_PITCH
Baseline pitch for the text.Valid relative values like
-80Hz,+50Hz, pitch changes should be within 0.5 to 1.5
times the original audio. For negative value use
format --arg=value,
--proxy PROXY Proxy server for the TTS provider. Format:
http://[username:password@]proxy.server:port
azure/edge specific:
--break_duration BREAK_DURATION
Break duration in milliseconds for the different
paragraphs or sections (default: 1250, means 1.25 s).
Valid values range from 0 to 5000 milliseconds for
Azure TTS.
piper specific:
--piper_path PIPER_PATH
Path to the Piper TTS executable
--piper_speaker PIPER_SPEAKER
Piper speaker id, used for multi-speaker models
--piper_sentence_silence PIPER_SENTENCE_SILENCE
Seconds of silence after each sentence
--piper_length_scale PIPER_LENGTH_SCALE
Phoneme length, a.k.a. speaking rate例:
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder上記のコマンドを実行すると、 output_folderという名前のディレクトリが生成され、デフォルトのTTSプロバイダーと音声を使用して、内部の各章のmp3ファイルを保存します。生成されたら、これらのオーディオファイルをオーディオブックシェルフにインポートしたり、選択したオーディオプレーヤーで再生したりできます。
EPUBファイルをオーディオブックに変換する前に、 --previewオプションを使用して各章の概要を取得できます。これにより、テキストをスピーチに変換する代わりに、各章の文字カウントと合計カウントが提供されます。
例:
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --preview略語を拡張するため、または発音を支援するために、テキストを検索して交換することをお勧めします。これを行うことができます。検索と交換ファイルを指定します。これには、単一の正規表現検索と交換が含まれ、「==」で区切られています。
例:
search.conf :
# this is the general structure
<search>==<replace>
# this is a comment
# fix cardinal direction abbreviations
N.E.==north east
# be careful with your regexes, as this would also match Sally N. Smith
N.==north
# pronounce Barbadoes like the locals
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.conf例:
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewこのツールはDockerイメージとして利用でき、Python依存関係を管理することなく簡単に実行できます。
まず、システムにDockerがインストールされていることを確認してください。
GitHubコンテナレジストリからDocker画像を引くことができます。
docker pull ghcr.io/p0n1/epub_to_audiobook:latest次に、次のコマンドでツールを実行できます。
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY= $MS_TTS_KEY -e MS_TTS_REGION= $MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azureOpenaiの場合、実行できます。
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY= $OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai $MS_TTS_KEYと$MS_TTS_REGIONをAzure Text-to-Speech API資格情報に置き換えます。 $OPENAI_API_KEY Openai APIキーに置き換えます。 your_book.epub入力epubファイルの名前に置き換え、 audiobook_output出力ファイルを保存するディレクトリの名前で置き換えます。
-v ./:/appオプションは、現在のディレクトリ( . )をDockerコンテナの/appディレクトリにマウントします。これにより、ツールは入力ファイルを読み取り、出力ファイルをローカルファイルシステムに書き込むことができます。
-iおよび-tオプションは、インタラクティブモードを有効にし、擬似ツーティを割り当てるために必要です。
Docker Composeの使用に関するこの例を確認することもできます。
Windowsユーザーの場合、特にコマンドラインツールにあまり精通していない場合は、カバーしています。私たちは課題を理解し、あなたのために特別に調整されたガイドを作成しました。
このステップバイステップガイドを確認し、問題が発生した場合はメッセージを残してください。
出典:https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/get-started-text-topeech#prerequisites
https://platform.openai.com/docs/quickstart/account-setupを確認してください。使用前に価格の詳細を確認してください。
Edge TTSとAzure TTSはほぼ同じです。違いは、Edge TTSがAPIキーを必要としないことです。これは、エッジ読み取りの機能性に基づいており、カスタムSSMLのようにパラメーターが少し制限されていることです。
https://gist.github.com/bettyjj/17cbaa1de96235a7f5773b8690a20462サポートされている声を確認してください。
このプロジェクトをすばやく試してみたい場合は、Edge TTSを強くお勧めします。
スクリプトを実行するときに--voice_nameおよび--languageオプションを渡すことにより、テキストからスピーチへの変換に使用される音声と言語をカスタマイズできます。
Microsoft Azureは、テキストからスピーチサービスのためのさまざまな声と言語を提供しています。利用可能なオプションのリストについては、Microsoft Azure Text-to-Speechドキュメントを参照してください。
また、Azure TTS Voice Galleryで利用可能な声のサンプルを聴いて、オーディオブックに最適な音声を選択するのに役立ちます。
たとえば、変換に英国の英語の女性の声を使用する場合は、次のコマンドを使用できます。
python3 main.py < input_file > < output_folder > --voice_name en-GB-LibbyNeural --language en-GB OpenAI TTSの場合、それぞれ--model_name 、 --voice_name 、および--output_formatを使用して、モデル、音声、およびフォーマットオプションを指定できます。
さまざまなオプションの組み合わせを実証する例を次に示します。
デフォルト設定を使用したAzureを使用した基本変換
このコマンドは、AzureのデフォルトのTTS設定を使用して、EPUBファイルをオーディオブックに変換します。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azureカスタム言語、音声、ロギングレベルを使用したAzure変換
EPUBファイルを指定された音声とデバッグ目的でカスタムログレベルを使用してオーディオブックに変換します。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --language zh-CN --voice_name " zh-CN-YunyeNeural " --log DEBUGチャプターの範囲とブレーク期間を使用したazure変換
段落間のカスタムブレーク期間を使用して、指定された章の範囲をEPUBファイルからオーディオブックに変換します。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --chapter_start 5 --chapter_end 10 --break_duration " 1500 "デフォルト設定を備えたOpenAIを使用した基本的な変換
このコマンドは、OpenAIのデフォルトのTTS設定を使用して、EPUBファイルをオーディオブックに変換します。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai HDモデルと特定の音声を使用したOpenAI変換
高解像度OpenaIモデルと特定の音声選択を使用して、EPUBファイルをオーディオブックに変換します。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --model_name " tts-1-hd " --voice_name " fable "プレビューとテキスト出力によるOpenAI変換
プレビューモードとテキスト出力を有効にします。テキスト出力は、それらを変換する代わりに章のインデックスとタイトルを表示し、テキストをエクスポートします。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --preview --output_textデフォルト設定を備えたEdgeを使用した基本的な変換
このコマンドは、EdgeのデフォルトのTTS設定を使用して、EPUBファイルをオーディオブックに変換します。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edgeカスタム言語、音声、ロギングレベルでのエッジ変換は、 EPUBファイルを指定された音声とデバッグ目的でカスタムログレベルを使用してオーディオブックに変換します。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --language zh-CN --voice_name " zh-CN-YunxiNeural " --log DEBUG章の範囲とブレーク期間を使用したエッジ変換は、段落間のカスタムブレーク期間を使用して、epubファイルから指定された範囲の範囲をオーディオブックに変換します。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --chapter_start 5 --chapter_end 10 --break_duration " 1500 "Piper TTSをインストールし、ONNXモデルファイルと対応する構成ファイルを持っていることを確認してください。詳細については、Piper TTSを確認してください。指示に従って、Piper TTSをインストールし、モデルと構成ファイルをダウンロードし、それで再生してから、以下の例を試してみることができます。
このコマンドは、EPUBファイルを、ベア最小パラメーターを使用してPiper TTSを使用してオーディオブックに変換します。常にONNXモデルファイルを指定する必要があり、 piper実行可能ファイルは現在の$パスにある必要があります。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_pathパラメーターを使用して、Piper実行可能ファイルへのカスタムパスを指定できます。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_path < path_to > /piper一部のモデルは複数の声をサポートしており、Voice_Nameパラメーターを使用して指定できます。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256また、速度(piper_length_scale)を指定して、持続時間(piper_sentence_silence)を一時停止することもできます。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 Piper TTS出力wavフォーマットファイル(またはRAW)デフォルトでは、 --output_formatパラメーターを介して合理的な形式を指定できるはずです。 opusとmp3 、サイズと互換性の良い選択です。
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opusこれは、使用しているPythonバージョンが3.8未満であるためかもしれません。 pip3 install importlib-metadataで手動でインストールするか、より高いPythonバージョンを使用することを試みることができます。
FFMPEGバイナリにパスからアクセスできることを確認してください。 Macに参加してHomeBrewを使用している場合は、 brew install ffmpeg sudo apt install ffmpeg実行できます。
インストール関連の問題については、Piper TTSリポジトリを参照してください。 PIPを介してpiper-ttsをインストールしている場合、Python 3.10のみが現在サポートされていることに注意することが重要です。 Macユーザーは、ダウンロードされたバイナリを使用する場合、追加の課題に遭遇する可能性があります。 MAC固有の問題の詳細については、この問題とこのプルリクエストを確認してください。
また、Piper TTSに問題がある場合はこれを確認してください。
このプロジェクトは、MITライセンスの下でライセンスされています。詳細については、ライセンスファイルを参照してください。


