epub_to_audiobook
v0.6.1
انضم إلى خادم Discord لدينا عن أي أسئلة أو مناقشات.
يوفر هذا المشروع أداة سطر الأوامر لتحويل الكتب الإلكترونية EPUB إلى كتب صوتية. وهو يدعم الآن كلاً من Microsoft Azure Text-to-Speech API (Edgetts Alternativly) و API Openai Text-to-Speech لإنشاء الصوت لكل فصل في الكتاب الإلكتروني. يتم تحسين ملفات الصوت الإخراج للاستخدام مع AudiObookShelf.
تم تطوير هذا المشروع بمساعدة chatgpt.
إذا كنت مهتمًا بسماع عينة من كتاب AudiObook الذي تم إنشاؤه بواسطة هذه الأداة ، فتحقق من الروابط.
تم تحسين الكتب المسموعة التي تم إنشاؤها بواسطة هذا المشروع للاستخدام مع Audiobookshelf. يتم تحويل كل فصل في ملف EPUB إلى ملف MP3 منفصل ، مع استخراج عنوان الفصل وإدراجه كبيانات تعريف.
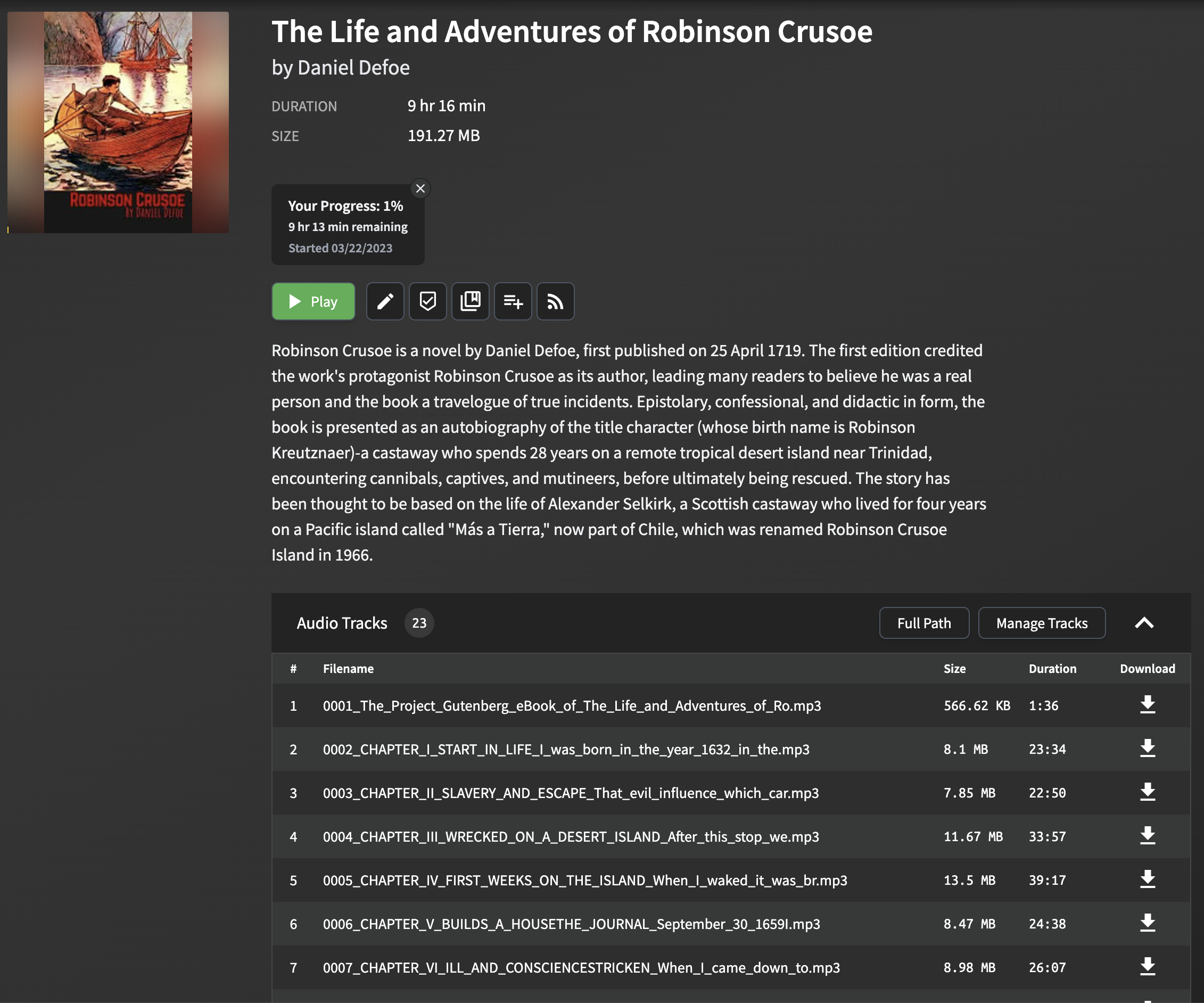
قد يكون تحليل عناوين الفصل واستخراجها من ملفات EPUB أمرًا صعبًا ، حيث قد يختلف التنسيق والبنية بشكل كبير بين الكتب الإلكترونية المختلفة. يستخدم البرنامج النصي طريقة بسيطة ولكنها فعالة لاستخراج عناوين الفصل ، والتي تعمل لمعظم ملفات EPUB. تتضمن الطريقة تحليل ملف EPUB والبحث عن علامة title في محتوى HTML لكل فصل. إذا لم تكن علامة العنوان موجودة ، يتم إنشاء عنوان احتياطي باستخدام الكلمات القليلة الأولى من نص الفصل.
يرجى ملاحظة أن هذا النهج قد لا يعمل بشكل مثالي لجميع ملفات EPUB ، وخاصة تلك ذات التنسيق المعقد أو غير العادي. ومع ذلك ، في معظم الحالات ، يوفر طريقة موثوقة لاستخراج عناوين الفصل لاستخدامها في Audiobookshelf.
عند استيراد ملفات MP3 التي تم إنشاؤها إلى Audiobookshelf ، سيتم عرض عناوين الفصل ، مما يجعل من السهل التنقل بين الفصول وتعزيز تجربة الاستماع الخاصة بك.
استنساخ هذا المستودع:
git clone https://github.com/p0n1/epub_to_audiobook.git
cd epub_to_audiobookقم بإنشاء بيئة افتراضية وتفعيلها:
python3 -m venv venv
source venv/bin/activateتثبيت التبعيات المطلوبة:
pip install -r requirements.txtقم بتعيين متغيرات البيئة التالية مع بيانات اعتماد Azure Text-to-Speech API ، أو مفتاح Openai API إذا كنت تستخدم Openai TTS:
export MS_TTS_KEY= < your_subscription_key > # for Azure
export MS_TTS_REGION= < your_region > # for Azure
export OPENAI_API_KEY= < your_openai_api_key > # for OpenAI لتحويل كتاب epub epub إلى كتاب مسموع ، قم بتشغيل الأمر التالي ، مع تحديد موفر TTS الذي تختاره مع خيار --tts :
python3 main.py < input_file > < output_folder > [options]للتحقق من أحدث أوصاف الخيار لهذا البرنامج النصي ، يمكنك تشغيل الأمر التالي في المحطة:
python3 main.py -husage: main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
Convert text book to audiobook
positional arguments:
input_file Path to the EPUB file
output_folder Path to the output folder
options:
-h, --help show this help message and exit
--tts {azure,openai,edge,piper}
Choose TTS provider (default: azure). azure: Azure
Cognitive Services, openai: OpenAI TTS API. When using
azure, environment variables MS_TTS_KEY and
MS_TTS_REGION must be set. When using openai,
environment variable OPENAI_API_KEY must be set.
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Log level (default: INFO), can be DEBUG, INFO,
WARNING, ERROR, CRITICAL
--preview Enable preview mode. In preview mode, the script will
not convert the text to speech. Instead, it will print
the chapter index, titles, and character counts.
--no_prompt Don ' t ask the user if they wish to continue after
estimating the cloud cost for TTS. Useful for
scripting.
--language LANGUAGE Language for the text-to-speech service (default: en-
US). For Azure TTS (--tts=azure), check
https://learn.microsoft.com/en-us/azure/ai-
services/speech-service/language-
support?tabs=tts#text-to-speech for supported
languages. For OpenAI TTS (--tts=openai), their API
detects the language automatically. But setting this
will also help on splitting the text into chunks with
different strategies in this tool, especially for
Chinese characters. For Chinese books, use zh-CN, zh-
TW, or zh-HK.
--newline_mode {single,double,none}
Choose the mode of detecting new paragraphs: ' single ' ,
' double ' , or ' none ' . ' single ' means a single newline
character, while ' double ' means two consecutive
newline characters. ' none ' means all newline
characters will be replace with blank so paragraphs
will not be detected. (default: double, works for most
ebooks but will detect less paragraphs for some
ebooks)
--title_mode {auto,tag_text,first_few}
Choose the parse mode for chapter title, ' tag_text '
search ' title ' , ' h1 ' , ' h2 ' , ' h3 ' tag for title,
' first_few ' set first 60 characters as title, ' auto '
auto apply the best mode for current chapter.
--chapter_start CHAPTER_START
Chapter start index (default: 1, starting from 1)
--chapter_end CHAPTER_END
Chapter end index (default: -1, meaning to the last
chapter)
--output_text Enable Output Text. This will export a plain text file
for each chapter specified and write the files to the
output folder specified.
--remove_endnotes This will remove endnote numbers from the end or
middle of sentences. This is useful for academic
books.
--search_and_replace_file SEARCH_AND_REPLACE_FILE
Path to a file that contains 1 regex replace per line,
to help with fixing pronunciations, etc. The format
is: <search>==<replace> Note that you may have to
specify word boundaries, to avoid replacing parts of
words.
--voice_name VOICE_NAME
Various TTS providers has different voice names, look
up for your provider settings.
--output_format OUTPUT_FORMAT
Output format for the text-to-speech service.
Supported format depends on selected TTS provider
--model_name MODEL_NAME
Various TTS providers has different neural model names
edge specific:
--voice_rate VOICE_RATE
Speaking rate of the text. Valid relative values range
from -50%(--xxx= ' -50% ' ) to +100%. For negative value
use format --arg=value,
--voice_volume VOICE_VOLUME
Volume level of the speaking voice. Valid relative
values floor to -100%. For negative value use format
--arg=value,
--voice_pitch VOICE_PITCH
Baseline pitch for the text.Valid relative values like
-80Hz,+50Hz, pitch changes should be within 0.5 to 1.5
times the original audio. For negative value use
format --arg=value,
--proxy PROXY Proxy server for the TTS provider. Format:
http://[username:password@]proxy.server:port
azure/edge specific:
--break_duration BREAK_DURATION
Break duration in milliseconds for the different
paragraphs or sections (default: 1250, means 1.25 s).
Valid values range from 0 to 5000 milliseconds for
Azure TTS.
piper specific:
--piper_path PIPER_PATH
Path to the Piper TTS executable
--piper_speaker PIPER_SPEAKER
Piper speaker id, used for multi-speaker models
--piper_sentence_silence PIPER_SENTENCE_SILENCE
Seconds of silence after each sentence
--piper_length_scale PIPER_LENGTH_SCALE
Phoneme length, a.k.a. speaking rateمثال :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder سيقوم تنفيذ الأمر أعلاه بإنشاء دليل يسمى output_folder وحفظ ملفات MP3 لكل فصل بداخله باستخدام مزود TTS الافتراضي والصوت. بمجرد إنشائها ، يمكنك استيراد ملفات الصوت هذه إلى Audiobookshelf أو تشغيلها مع أي مشغل صوت من اختيارك.
قبل تحويل ملف EPUB الخاص بك إلى كتاب مسموع ، يمكنك استخدام خيار --preview للحصول على ملخص لكل فصل. سيوفر لك ذلك عدد الأحرف من كل فصل والعدد الكلي ، بدلاً من تحويل النص إلى الكلام.
مثال :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewقد ترغب في البحث واستبدال النص ، إما لتوسيع الاختصارات ، أو للمساعدة في النطق. يمكنك القيام بذلك عن طريق تحديد ملف بحث واستبداله ، والذي يحتوي على بحث regex واحد واستبداله لكل سطر ، مفصولة بـ '==':
مثال :
Search.Conf :
# this is the general structure
<search>==<replace>
# this is a comment
# fix cardinal direction abbreviations
N.E.==north east
# be careful with your regexes, as this would also match Sally N. Smith
N.==north
# pronounce Barbadoes like the locals
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.confمثال :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewتتوفر هذه الأداة كصورة Docker ، مما يسهل تشغيله دون الحاجة إلى إدارة تبعيات Python.
أولاً ، تأكد من تثبيت Docker على نظامك.
يمكنك سحب صورة Docker من سجل حاوية Github:
docker pull ghcr.io/p0n1/epub_to_audiobook:latestثم ، يمكنك تشغيل الأداة مع الأمر التالي:
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY= $MS_TTS_KEY -e MS_TTS_REGION= $MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azureلـ Openai ، يمكنك الركض:
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY= $OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai استبدل $MS_TTS_KEY و $MS_TTS_REGION بأوراق اعتماد Azure text-to-Speech. استبدل $OPENAI_API_KEY بمفتاح Openai API الخاص بك. استبدل your_book.epub باسم ملف epub input و audiobook_output باسم الدليل الذي تريد حفظ ملفات الإخراج.
. /app -v ./:/app يتيح هذا للأداة قراءة ملف الإدخال وكتابة ملفات الإخراج إلى نظام الملفات المحلي.
خيارات -i و -t مطلوبة لتمكين الوضع التفاعلي وتخصيص مجموعة زائفة.
يمكنك أيضًا التحقق من ملف التكوين هذا المثال الخاص بـ Docker.
بالنسبة لمستخدمي Windows ، خاصة إذا لم تكن على دراية بأدوات سطر الأوامر ، فقد قمنا بتغطيتك. نحن نفهم التحديات وأنشأنا دليلًا مصمم خصيصًا لك.
تحقق من هذا الدليل خطوة بخطوة واترك رسالة إذا واجهت مشكلات.
المصدر: https://learn.microsoft.com/en-us/azure/cealitive-services/speech-service/get-started-text-to-speade#preequesites
تحقق من https://platform.openai.com/docs/quickstart/account-setup. تأكد من التحقق من تفاصيل السعر قبل الاستخدام.
الحافة TTS و Azure TTs هي نفسها تقريبًا ، والفرق هو أن TTS TTS لا تتطلب مفتاح API لأنه يعتمد على وظائف قراءة الحافة بصوت عالٍ ، والمعلمات مقيدة قليلاً ، مثل SSML المخصص.
تحقق من https://gist.github.com/bettyjj/17cbaa1de96235a7f5773b8690a20462 للأصوات المدعومة.
إذا كنت ترغب في تجربة هذا المشروع بسرعة ، يوصى بشدة بـ Edge TTS.
يمكنك تخصيص الصوت واللغة المستخدمة لتحويل النص إلى الكلام عن طريق تمرير خيارات- --voice_name و --language عند تشغيل البرنامج النصي.
تقدم Microsoft Azure مجموعة من الأصوات واللغات لخدمة النص إلى كلام. للحصول على قائمة بالخيارات المتاحة ، راجع وثائق Microsoft Azure النص إلى كلام.
يمكنك أيضًا الاستماع إلى عينات من الأصوات المتاحة في معرض Azure TTS الصوتية لمساعدتك في اختيار أفضل صوت لكتابك المسموع.
على سبيل المثال ، إذا كنت ترغب في استخدام صوت أنثى إنجليزي بريطاني للتحويل ، فيمكنك استخدام الأمر التالي:
python3 main.py < input_file > < output_folder > --voice_name en-GB-LibbyNeural --language en-GB بالنسبة إلى Openai TTS ، يمكنك تحديد خيارات النموذج والصوت والتنسيق باستخدام --model_name ، --voice_name ، و --output_format ، على التوالي.
فيما يلي بعض الأمثلة التي توضح مجموعات الخيارات المختلفة:
التحويل الأساسي باستخدام Azure مع الإعدادات الافتراضية
سيقوم هذا الأمر بتحويل ملف EPUB إلى كتاب صوتي باستخدام إعدادات TTS الافتراضية لـ Azure.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure تحويل Azure باللغة المخصصة والصوت ومستوى التسجيل
يحول ملف EPUB إلى كتاب صوتي مع صوت محدد ومستوى سجل مخصص لأغراض تصحيح الأخطاء.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --language zh-CN --voice_name " zh-CN-YunyeNeural " --log DEBUG تحويل Azure مع نطاق الفصل ومدة كسر
يحول مجموعة محددة من الفصول من ملف EPUB إلى كتاب صوتي مع مدة كسر مخصص بين الفقرات.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --chapter_start 5 --chapter_end 10 --break_duration " 1500 " التحويل الأساسي باستخدام Openai مع الإعدادات الافتراضية
سيقوم هذا الأمر بتحويل ملف EPUB إلى كتاب صوتي باستخدام إعدادات TTS الافتراضية من Openai.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai تحويل Openai مع نموذج HD وصوت محدد
يحول ملف EPUB إلى كتاب صوتي باستخدام نموذج Openai عالي الدقة واختيار صوت محدد.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --model_name " tts-1-hd " --voice_name " fable " تحويل Openai مع المعاينة وإخراج النص
يتيح وضع المعاينة وإخراج النص ، والذي سيعرض فهرس الفصل والعناوين بدلاً من تحويلها وسيقوم أيضًا بتصدير النص.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --preview --output_text التحويل الأساسي باستخدام الحافة مع الإعدادات الافتراضية
سيقوم هذا الأمر بتحويل ملف EPUB إلى كتاب صوتي باستخدام إعدادات TTS الافتراضية من Edge.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edgeيحول تحويل الحافة باللغة المخصصة والصوت ومستوى التسجيل ملف EPUB إلى كتاب صوتي مع صوت محدد ومستوى سجل مخصص لأغراض تصحيح الأخطاء.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --language zh-CN --voice_name " zh-CN-YunxiNeural " --log DEBUGيحول تحويل الحافة مع نطاق الفصل ومدة الفاصل مجموعة محددة من الفصول من ملف EPUB إلى كتاب صوتي مع مدة كسر مخصصة بين الفقرات.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --chapter_start 5 --chapter_end 10 --break_duration " 1500 "تأكد من تثبيت Piper TTS ولديك ملف نموذج ONNX وملف التكوين المقابل. تحقق من Piper TTS لمزيد من التفاصيل. يمكنك اتباع إرشاداتهم لتثبيت Piper TTS ، وتنزيل النماذج وملفات التكوين ، والتشغيل معها ، ثم العودة لتجربة الأمثلة أدناه.
سيقوم هذا الأمر بتحويل ملف EPUB إلى كتاب صوتي باستخدام Piper TTS باستخدام المعلمات الدنيا العارية. تحتاج دائمًا إلى تحديد ملف طراز ONNX ويجب أن يكون piper Texportable في مسار $ الحالي.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx يمكنك تحديد مسارك المخصص إلى Piper قابل للتنفيذ باستخدام معلمة --piper_path .
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_path < path_to > /piperتدعم بعض النماذج أصوات متعددة ويمكن تحديدها باستخدام معلمة Voice_Name.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256يمكنك أيضًا تحديد السرعة (piper_length_scale) ومدة الإيقاف المؤقت (piper_sentence_silence).
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 يقوم Piper TTS بإخراج ملفات تنسيق wav (أو RAW) افتراضيًا ، يجب أن تكون قادرًا على تحديد أي تنسيق معقول عبر المعلمة --output_format . يعد opus و mp3 خيارات جيدة للحجم والتوافق.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opus قد يكون هذا لأن إصدار Python الذي تستخدمه أقل من 3.8. يمكنك محاولة تثبيته يدويًا عن طريق pip3 install importlib-metadata ، أو استخدام إصدار Python أعلى.
تأكد من الوصول إلى FFMPEG الثنائي من مسارك. إذا كنت على جهاز Mac واستخدمت Homebrew ، فيمكنك القيام brew install ffmpeg ، على Ubuntu ، يمكنك القيام sudo apt install ffmpeg
للمشكلات المتعلقة بالتثبيت ، يرجى الرجوع إلى مستودع Piper TTS. من المهم أن نلاحظ أنه إذا كنت تقوم بتثبيت piper-tts عبر PIP ، فسيتم دعم Python 3.10 فقط حاليًا. قد يواجه مستخدمو MAC تحديات إضافية عند استخدام الثنائي الذي تم تنزيله. لمزيد من المعلومات حول المشكلات الخاصة بـ Mac ، يرجى التحقق من هذه المشكلة وطلب السحب هذا.
تحقق أيضًا من هذا إذا كنت تواجه مشكلة مع Piper TTS.
هذا المشروع مرخص بموجب ترخيص معهد ماساتشوستس للتكنولوجيا. انظر ملف الترخيص للحصول على التفاصيل.


