epub_to_audiobook
v0.6.1
Bergabunglah dengan server Discord kami untuk setiap pertanyaan atau diskusi.
Proyek ini menyediakan alat baris perintah untuk mengonversi eBook EPUB menjadi buku audio. Sekarang mendukung API Microsoft Azure Text-to-Speech (alternativly Edgetts) dan API teks-ke-speech openai untuk menghasilkan audio untuk setiap bab dalam ebook. File audio output dioptimalkan untuk digunakan dengan AudioBookShelf.
Proyek ini dikembangkan dengan bantuan chatgpt.
Jika Anda tertarik mendengar sampel buku audio yang dihasilkan oleh alat ini, periksa tautan di bawahnya.
Buku audio yang dihasilkan oleh proyek ini dioptimalkan untuk digunakan dengan AudioBookShelf. Setiap bab dalam file EPUB dikonversi menjadi file MP3 terpisah, dengan judul bab diekstraksi dan dimasukkan sebagai metadata.
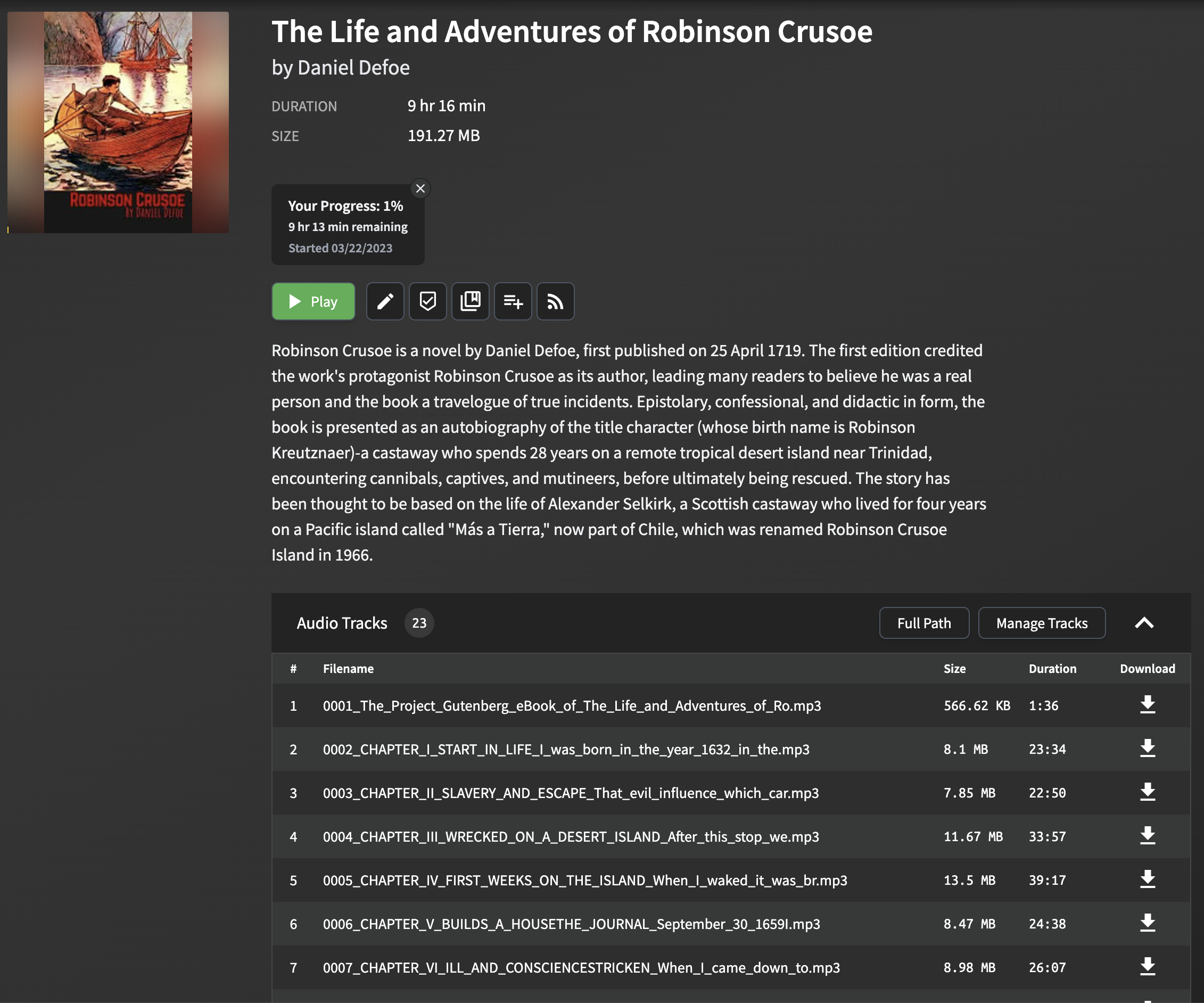
Parsing dan mengekstraksi judul bab dari file EPUB dapat menantang, karena format dan struktur dapat bervariasi secara signifikan antara berbagai eBook. Script menggunakan metode sederhana namun efektif untuk mengekstraksi judul bab, yang berfungsi untuk sebagian besar file EPUB. Metode ini melibatkan parsing file EPUB dan mencari tag title dalam konten HTML dari setiap bab. Jika tag judul tidak ada, judul fallback dihasilkan menggunakan beberapa kata pertama dari teks bab.
Harap dicatat bahwa pendekatan ini mungkin tidak berfungsi dengan baik untuk semua file EPUB, terutama yang memiliki format yang kompleks atau tidak biasa. Namun, dalam kebanyakan kasus, ini memberikan cara yang dapat diandalkan untuk mengekstrak judul bab untuk digunakan di AudioBookshelf.
Saat Anda mengimpor file MP3 yang dihasilkan ke AudioBookShelf, judul bab akan ditampilkan, membuatnya mudah untuk dinavigasi di antara bab -bab dan meningkatkan pengalaman mendengarkan Anda.
Klon Repositori ini:
git clone https://github.com/p0n1/epub_to_audiobook.git
cd epub_to_audiobookBuat lingkungan virtual dan aktifkan:
python3 -m venv venv
source venv/bin/activateInstal dependensi yang diperlukan:
pip install -r requirements.txtAtur variabel lingkungan berikut dengan kredensial API Azure Text-to-Speech API Anda, atau Kunci API OpenAI Anda jika Anda menggunakan OpenAI TTS:
export MS_TTS_KEY= < your_subscription_key > # for Azure
export MS_TTS_REGION= < your_region > # for Azure
export OPENAI_API_KEY= < your_openai_api_key > # for OpenAI Untuk mengonversi ebook Epub ke buku audio, jalankan perintah berikut, menentukan penyedia TTS pilihan Anda dengan opsi --tts :
python3 main.py < input_file > < output_folder > [options]Untuk memeriksa deskripsi opsi terbaru untuk skrip ini, Anda dapat menjalankan perintah berikut di terminal:
python3 main.py -husage: main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
Convert text book to audiobook
positional arguments:
input_file Path to the EPUB file
output_folder Path to the output folder
options:
-h, --help show this help message and exit
--tts {azure,openai,edge,piper}
Choose TTS provider (default: azure). azure: Azure
Cognitive Services, openai: OpenAI TTS API. When using
azure, environment variables MS_TTS_KEY and
MS_TTS_REGION must be set. When using openai,
environment variable OPENAI_API_KEY must be set.
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Log level (default: INFO), can be DEBUG, INFO,
WARNING, ERROR, CRITICAL
--preview Enable preview mode. In preview mode, the script will
not convert the text to speech. Instead, it will print
the chapter index, titles, and character counts.
--no_prompt Don ' t ask the user if they wish to continue after
estimating the cloud cost for TTS. Useful for
scripting.
--language LANGUAGE Language for the text-to-speech service (default: en-
US). For Azure TTS (--tts=azure), check
https://learn.microsoft.com/en-us/azure/ai-
services/speech-service/language-
support?tabs=tts#text-to-speech for supported
languages. For OpenAI TTS (--tts=openai), their API
detects the language automatically. But setting this
will also help on splitting the text into chunks with
different strategies in this tool, especially for
Chinese characters. For Chinese books, use zh-CN, zh-
TW, or zh-HK.
--newline_mode {single,double,none}
Choose the mode of detecting new paragraphs: ' single ' ,
' double ' , or ' none ' . ' single ' means a single newline
character, while ' double ' means two consecutive
newline characters. ' none ' means all newline
characters will be replace with blank so paragraphs
will not be detected. (default: double, works for most
ebooks but will detect less paragraphs for some
ebooks)
--title_mode {auto,tag_text,first_few}
Choose the parse mode for chapter title, ' tag_text '
search ' title ' , ' h1 ' , ' h2 ' , ' h3 ' tag for title,
' first_few ' set first 60 characters as title, ' auto '
auto apply the best mode for current chapter.
--chapter_start CHAPTER_START
Chapter start index (default: 1, starting from 1)
--chapter_end CHAPTER_END
Chapter end index (default: -1, meaning to the last
chapter)
--output_text Enable Output Text. This will export a plain text file
for each chapter specified and write the files to the
output folder specified.
--remove_endnotes This will remove endnote numbers from the end or
middle of sentences. This is useful for academic
books.
--search_and_replace_file SEARCH_AND_REPLACE_FILE
Path to a file that contains 1 regex replace per line,
to help with fixing pronunciations, etc. The format
is: <search>==<replace> Note that you may have to
specify word boundaries, to avoid replacing parts of
words.
--voice_name VOICE_NAME
Various TTS providers has different voice names, look
up for your provider settings.
--output_format OUTPUT_FORMAT
Output format for the text-to-speech service.
Supported format depends on selected TTS provider
--model_name MODEL_NAME
Various TTS providers has different neural model names
edge specific:
--voice_rate VOICE_RATE
Speaking rate of the text. Valid relative values range
from -50%(--xxx= ' -50% ' ) to +100%. For negative value
use format --arg=value,
--voice_volume VOICE_VOLUME
Volume level of the speaking voice. Valid relative
values floor to -100%. For negative value use format
--arg=value,
--voice_pitch VOICE_PITCH
Baseline pitch for the text.Valid relative values like
-80Hz,+50Hz, pitch changes should be within 0.5 to 1.5
times the original audio. For negative value use
format --arg=value,
--proxy PROXY Proxy server for the TTS provider. Format:
http://[username:password@]proxy.server:port
azure/edge specific:
--break_duration BREAK_DURATION
Break duration in milliseconds for the different
paragraphs or sections (default: 1250, means 1.25 s).
Valid values range from 0 to 5000 milliseconds for
Azure TTS.
piper specific:
--piper_path PIPER_PATH
Path to the Piper TTS executable
--piper_speaker PIPER_SPEAKER
Piper speaker id, used for multi-speaker models
--piper_sentence_silence PIPER_SENTENCE_SILENCE
Seconds of silence after each sentence
--piper_length_scale PIPER_LENGTH_SCALE
Phoneme length, a.k.a. speaking rateContoh :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder Mengeksekusi perintah di atas akan menghasilkan direktori bernama output_folder dan menyimpan file MP3 untuk setiap bab di dalamnya menggunakan penyedia dan suara TTS default. Setelah dihasilkan, Anda dapat mengimpor file audio ini ke AudioBookShelf atau memainkannya dengan pemutar audio pilihan Anda.
Sebelum mengonversi file Epub Anda ke buku audio, Anda dapat menggunakan opsi --preview untuk mendapatkan ringkasan dari setiap bab. Ini akan memberi Anda jumlah karakter dari setiap bab dan jumlah total, alih -alih mengubah teks menjadi ucapan.
Contoh :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewAnda mungkin ingin mencari dan mengganti teks, baik untuk memperluas singkatan, atau membantu pengucapan. Anda dapat melakukan ini dengan menentukan file pencarian dan ganti, yang berisi pencarian regex tunggal dan mengganti per baris, dipisahkan oleh '==':
Contoh :
search.conf :
# this is the general structure
<search>==<replace>
# this is a comment
# fix cardinal direction abbreviations
N.E.==north east
# be careful with your regexes, as this would also match Sally N. Smith
N.==north
# pronounce Barbadoes like the locals
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.confContoh :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewAlat ini tersedia sebagai gambar Docker, membuatnya mudah dijalankan tanpa perlu mengelola dependensi Python.
Pertama, pastikan Anda memasang Docker di sistem Anda.
Anda dapat menarik gambar Docker dari Registry Container GitHub:
docker pull ghcr.io/p0n1/epub_to_audiobook:latestKemudian, Anda dapat menjalankan alat dengan perintah berikut:
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY= $MS_TTS_KEY -e MS_TTS_REGION= $MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azureUntuk Openai, Anda dapat menjalankan:
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY= $OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai Ganti $MS_TTS_KEY dan $MS_TTS_REGION dengan kredensial API teks-ke-speech Azure Anda. Ganti $OPENAI_API_KEY dengan kunci API openai Anda. Ganti your_book.epub dengan nama file input EPUB, dan audiobook_output dengan nama direktori tempat Anda ingin menyimpan file output.
Opsi -v ./:/app memasang direktori saat ini ( . ) Ke direktori /app di wadah Docker. Ini memungkinkan alat untuk membaca file input dan menulis file output ke sistem file lokal Anda.
Opsi -i dan -t diperlukan untuk mengaktifkan mode interaktif dan mengalokasikan pseudo -tty.
Anda juga dapat memeriksa file konfigurasi contoh ini untuk penggunaan Docker Compose.
Untuk pengguna Windows, terutama jika Anda tidak terlalu terbiasa dengan alat baris perintah, kami telah meliput Anda. Kami memahami tantangan dan telah menciptakan panduan yang secara khusus dirancang untuk Anda.
Periksa panduan langkah demi langkah ini dan tinggalkan pesan jika Anda menemukan masalah.
Sumber: https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/get-started-text-t-feech#prerequisites
Periksa https://platform.openai.com/docs/quickstart/account-setup. Pastikan Anda memeriksa detail harga sebelum digunakan.
TTS Edge dan Azure TTS hampir sama, perbedaannya adalah bahwa TTS EDGE tidak memerlukan kunci API karena didasarkan pada fungsionalitas bacaan tepi dengan lantang, dan parameter dibatasi sedikit, seperti SSML khusus.
Periksa https://gist.github.com/bettyjj/17cbaa1de96235a7f5773b8690a20462 untuk suara yang didukung.
Jika Anda ingin mencoba proyek ini dengan cepat, Edge TTS sangat disarankan.
Anda dapat menyesuaikan suara dan bahasa yang digunakan untuk konversi teks-ke-speech dengan melewati --voice_name dan-opsi --language saat menjalankan skrip.
Microsoft Azure menawarkan berbagai suara dan bahasa untuk layanan teks-ke-speech. Untuk daftar opsi yang tersedia, konsultasikan dokumentasi Microsoft Azure Text-to-Speech.
Anda juga dapat mendengarkan sampel suara yang tersedia di Galeri Suara Azure TTS untuk membantu Anda memilih suara terbaik untuk buku audio Anda.
Misalnya, jika Anda ingin menggunakan suara wanita Inggris Inggris untuk konversi, Anda dapat menggunakan perintah berikut:
python3 main.py < input_file > < output_folder > --voice_name en-GB-LibbyNeural --language en-GB Untuk OpenAI TTS, Anda dapat menentukan opsi model, suara, dan format menggunakan --model_name , --voice_name , dan --output_format .
Berikut adalah beberapa contoh yang menunjukkan berbagai kombinasi opsi:
Konversi Dasar Menggunakan Azure Dengan Pengaturan Default
Perintah ini akan mengonversi file Epub ke buku audio menggunakan pengaturan TTS default Azure.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure Konversi Azure dengan Bahasa Kustom, Level Suara dan Logging
Konversi file EPUB ke buku audio dengan suara yang ditentukan dan level log khusus untuk tujuan debugging.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --language zh-CN --voice_name " zh-CN-YunyeNeural " --log DEBUG Konversi Azure dengan rentang bab dan durasi istirahat
Konversi berbagai bab tertentu dari file EPUB menjadi buku audio dengan durasi break khusus antara paragraf.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --chapter_start 5 --chapter_end 10 --break_duration " 1500 " Konversi Dasar Menggunakan OpenAi dengan Pengaturan Default
Perintah ini akan mengonversi file Epub ke buku audio menggunakan pengaturan TTS default OpenAI.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai Konversi openai dengan model HD dan suara tertentu
Mengubah file EPUB ke buku audio menggunakan model OpenAI definisi tinggi dan pilihan suara tertentu.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --model_name " tts-1-hd " --voice_name " fable " Konversi openai dengan pratinjau dan output teks
Mengaktifkan mode pratinjau dan output teks, yang akan menampilkan indeks bab dan judul alih -alih mengonversi dan juga akan mengekspor teks.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --preview --output_text Konversi Dasar Menggunakan Edge Dengan Pengaturan Default
Perintah ini akan mengonversi file Epub ke buku audio menggunakan pengaturan TTS default Edge.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edgeKonversi tepi dengan bahasa kustom, level suara, dan logging mengubah file EPUB ke buku audio dengan suara yang ditentukan dan level log khusus untuk tujuan debugging.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --language zh-CN --voice_name " zh-CN-YunxiNeural " --log DEBUGKonversi tepi dengan rentang bab dan durasi break mengkonversi berbagai bab tertentu dari file EPUB menjadi buku audio dengan durasi istirahat khusus antara paragraf.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --chapter_start 5 --chapter_end 10 --break_duration " 1500 "Pastikan Anda telah menginstal Piper TTS dan memiliki file model ONNX dan file konfigurasi yang sesuai. Periksa Piper TTS untuk lebih jelasnya. Anda dapat mengikuti instruksi mereka untuk menginstal Piper TTS, mengunduh model dan mengkonfigurasi file, bermain dengannya dan kemudian kembali untuk mencoba contoh di bawah ini.
Perintah ini akan mengonversi file EPUB ke buku audio menggunakan Piper TTS menggunakan parameter minimum telanjang. Anda selalu perlu menentukan file model ONNX dan piper dapat dieksekusi harus berada di jalur $ saat ini.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx Anda dapat menentukan jalur khusus Anda ke Piper dapat dieksekusi dengan menggunakan parameter --piper_path .
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_path < path_to > /piperBeberapa model mendukung banyak suara dan itu dapat ditentukan dengan menggunakan parameter Voice_Name.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256Anda juga dapat menentukan kecepatan (piper_length_scale) dan jeda durasi (piper_sentence_silence).
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 Piper TTS Output wav Format File (atau RAW) Secara default Anda harus dapat menentukan format yang masuk akal melalui parameter --output_format . opus dan mp3 adalah pilihan yang baik untuk ukuran dan kompatibilitas.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opus Ini mungkin karena versi Python yang Anda gunakan kurang dari 3,8. Anda dapat mencoba menginstalnya secara manual dengan pip3 install importlib-metadata , atau menggunakan versi Python yang lebih tinggi.
Pastikan biner FFMPEG dapat diakses dari jalur Anda. Jika Anda menggunakan Mac dan menggunakan homebrew, Anda dapat membuat brew install ffmpeg , di ubuntu Anda dapat melakukan sudo apt install ffmpeg
Untuk masalah terkait instalasi, silakan merujuk ke repositori Piper TTS. Penting untuk dicatat bahwa jika Anda memasang piper-tts melalui PIP, hanya Python 3.10 yang saat ini didukung. Pengguna Mac dapat menghadapi tantangan tambahan saat menggunakan biner yang diunduh. Untuk informasi lebih lanjut tentang masalah khusus Mac, silakan periksa masalah ini dan permintaan tarik ini.
Periksa juga jika Anda mengalami masalah dengan Piper TTS.
Proyek ini dilisensikan di bawah lisensi MIT. Lihat file lisensi untuk detailnya.


