epub_to_audiobook
v0.6.1
Únase a nuestro servidor Discord para cualquier pregunta o discusión.
Este proyecto proporciona una herramienta de línea de comandos para convertir los libros electrónicos EPUB en audiolibros. Ahora es compatible con la API de texto a voz de Microsoft Azure (alternativa edgetts) y la API de texto a voz de OpenAI para generar el audio para cada capítulo del libro electrónico. Los archivos de audio de salida están optimizados para su uso con AudiobookShelf.
Este proyecto se desarrolla con la ayuda de ChatGPT.
Si está interesado en escuchar una muestra del audiolibro generado por esta herramienta, consulte los enlaces a continuación.
Los audiolibros generados por este proyecto están optimizados para su uso con Audiobookshelf. Cada capítulo del archivo EPUB se convierte en un archivo MP3 separado, con el título del capítulo extraído e incluido como metadatos.
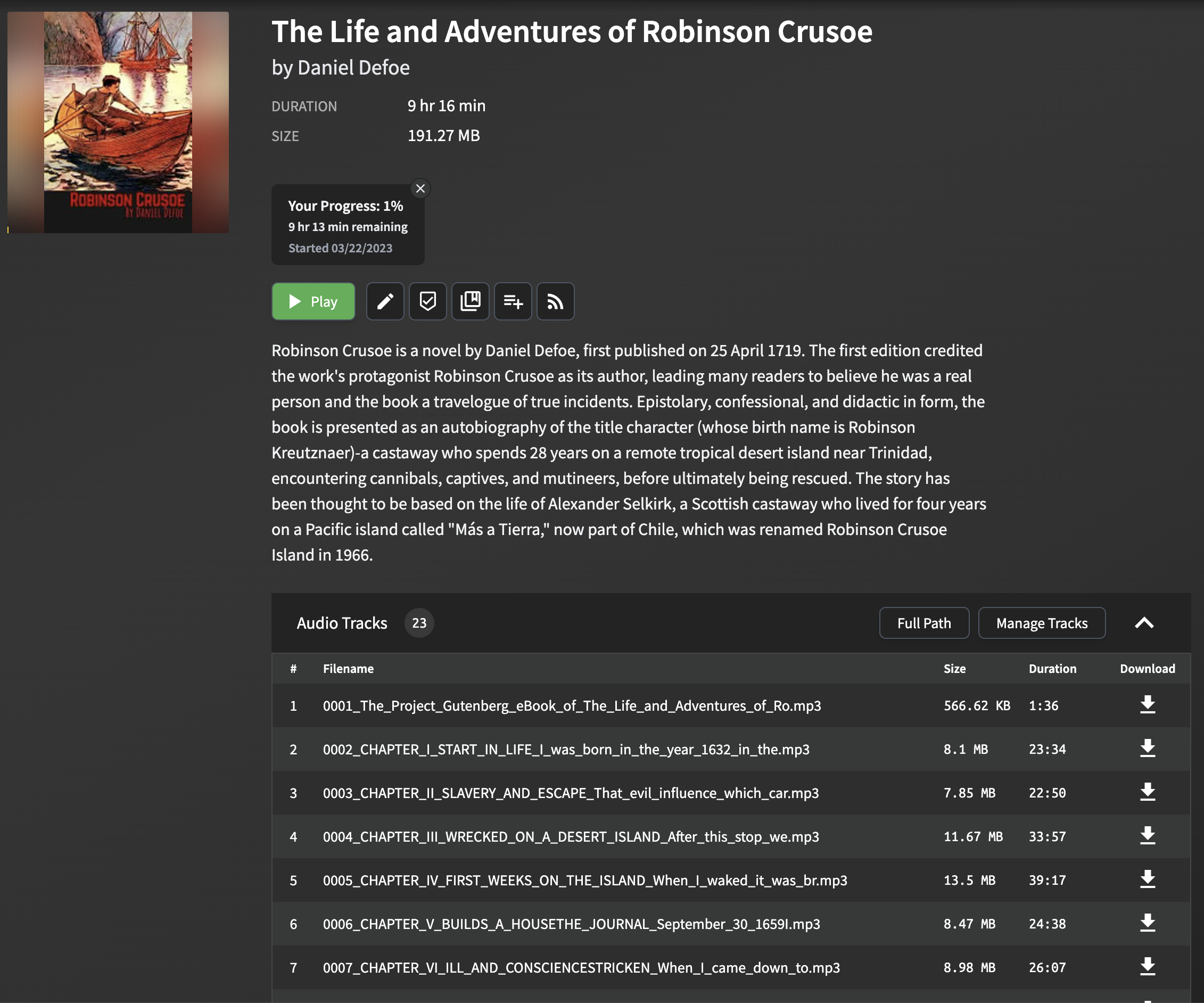
El análisis y la extracción de los títulos de los capítulos de los archivos EPUB pueden ser desafiantes, ya que el formato y la estructura pueden variar significativamente entre diferentes libros electrónicos. El script emplea un método simple pero efectivo para extraer títulos de capítulos, que funciona para la mayoría de los archivos EPUB. El método implica analizar el archivo EPUB y buscar la etiqueta title en el contenido HTML de cada capítulo. Si la etiqueta de título no está presente, se genera un título de respaldo utilizando las primeras palabras del texto del capítulo.
Tenga en cuenta que este enfoque puede no funcionar perfectamente para todos los archivos EPUB, especialmente aquellos con formato complejo o inusual. Sin embargo, en la mayoría de los casos, proporciona una forma confiable de extraer títulos de capítulos para su uso en audiolibro.
Cuando importe los archivos MP3 generados en Audiobookshelf, los títulos de los capítulos se mostrarán, lo que facilita la navegación entre los capítulos y mejorando su experiencia auditiva.
Clon este repositorio:
git clone https://github.com/p0n1/epub_to_audiobook.git
cd epub_to_audiobookCrear un entorno virtual y activarlo:
python3 -m venv venv
source venv/bin/activateInstale las dependencias requeridas:
pip install -r requirements.txtEstablezca las siguientes variables de entorno con sus credenciales de API de texto a voz de Azure, o su tecla API OpenAI si está utilizando OpenAI TTS:
export MS_TTS_KEY= < your_subscription_key > # for Azure
export MS_TTS_REGION= < your_region > # for Azure
export OPENAI_API_KEY= < your_openai_api_key > # for OpenAI Para convertir un libro electrónico de EPUB en un audiolibro, ejecute el siguiente comando, especificando el proveedor TTS de su elección con la opción --tts :
python3 main.py < input_file > < output_folder > [options]Para verificar las últimas descripciones de opciones para este script, puede ejecutar el siguiente comando en el terminal:
python3 main.py -husage: main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
Convert text book to audiobook
positional arguments:
input_file Path to the EPUB file
output_folder Path to the output folder
options:
-h, --help show this help message and exit
--tts {azure,openai,edge,piper}
Choose TTS provider (default: azure). azure: Azure
Cognitive Services, openai: OpenAI TTS API. When using
azure, environment variables MS_TTS_KEY and
MS_TTS_REGION must be set. When using openai,
environment variable OPENAI_API_KEY must be set.
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Log level (default: INFO), can be DEBUG, INFO,
WARNING, ERROR, CRITICAL
--preview Enable preview mode. In preview mode, the script will
not convert the text to speech. Instead, it will print
the chapter index, titles, and character counts.
--no_prompt Don ' t ask the user if they wish to continue after
estimating the cloud cost for TTS. Useful for
scripting.
--language LANGUAGE Language for the text-to-speech service (default: en-
US). For Azure TTS (--tts=azure), check
https://learn.microsoft.com/en-us/azure/ai-
services/speech-service/language-
support?tabs=tts#text-to-speech for supported
languages. For OpenAI TTS (--tts=openai), their API
detects the language automatically. But setting this
will also help on splitting the text into chunks with
different strategies in this tool, especially for
Chinese characters. For Chinese books, use zh-CN, zh-
TW, or zh-HK.
--newline_mode {single,double,none}
Choose the mode of detecting new paragraphs: ' single ' ,
' double ' , or ' none ' . ' single ' means a single newline
character, while ' double ' means two consecutive
newline characters. ' none ' means all newline
characters will be replace with blank so paragraphs
will not be detected. (default: double, works for most
ebooks but will detect less paragraphs for some
ebooks)
--title_mode {auto,tag_text,first_few}
Choose the parse mode for chapter title, ' tag_text '
search ' title ' , ' h1 ' , ' h2 ' , ' h3 ' tag for title,
' first_few ' set first 60 characters as title, ' auto '
auto apply the best mode for current chapter.
--chapter_start CHAPTER_START
Chapter start index (default: 1, starting from 1)
--chapter_end CHAPTER_END
Chapter end index (default: -1, meaning to the last
chapter)
--output_text Enable Output Text. This will export a plain text file
for each chapter specified and write the files to the
output folder specified.
--remove_endnotes This will remove endnote numbers from the end or
middle of sentences. This is useful for academic
books.
--search_and_replace_file SEARCH_AND_REPLACE_FILE
Path to a file that contains 1 regex replace per line,
to help with fixing pronunciations, etc. The format
is: <search>==<replace> Note that you may have to
specify word boundaries, to avoid replacing parts of
words.
--voice_name VOICE_NAME
Various TTS providers has different voice names, look
up for your provider settings.
--output_format OUTPUT_FORMAT
Output format for the text-to-speech service.
Supported format depends on selected TTS provider
--model_name MODEL_NAME
Various TTS providers has different neural model names
edge specific:
--voice_rate VOICE_RATE
Speaking rate of the text. Valid relative values range
from -50%(--xxx= ' -50% ' ) to +100%. For negative value
use format --arg=value,
--voice_volume VOICE_VOLUME
Volume level of the speaking voice. Valid relative
values floor to -100%. For negative value use format
--arg=value,
--voice_pitch VOICE_PITCH
Baseline pitch for the text.Valid relative values like
-80Hz,+50Hz, pitch changes should be within 0.5 to 1.5
times the original audio. For negative value use
format --arg=value,
--proxy PROXY Proxy server for the TTS provider. Format:
http://[username:password@]proxy.server:port
azure/edge specific:
--break_duration BREAK_DURATION
Break duration in milliseconds for the different
paragraphs or sections (default: 1250, means 1.25 s).
Valid values range from 0 to 5000 milliseconds for
Azure TTS.
piper specific:
--piper_path PIPER_PATH
Path to the Piper TTS executable
--piper_speaker PIPER_SPEAKER
Piper speaker id, used for multi-speaker models
--piper_sentence_silence PIPER_SENTENCE_SILENCE
Seconds of silence after each sentence
--piper_length_scale PIPER_LENGTH_SCALE
Phoneme length, a.k.a. speaking rateEjemplo :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder Ejecución del comando anterior generará un directorio llamado output_folder y guardará los archivos mp3 para cada capítulo dentro de él utilizando el proveedor TTS predeterminado y la voz. Una vez generado, puede importar estos archivos de audio en audiolibro o reproducirlos con cualquier reproductor de audio de su elección.
Antes de convertir su archivo EPUB en un audiolibro, puede usar la opción --preview para obtener un resumen de cada capítulo. Esto le proporcionará el recuento de caracteres de cada capítulo y el recuento total, en lugar de convertir el texto en discurso.
Ejemplo :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewEs posible que desee buscar y reemplazar el texto, ya sea para expandir abreviaturas o ayudar con la pronunciación. Puede hacerlo especificando un archivo de búsqueda y reemplazo, que contiene una sola búsqueda de regex y reemplazar por línea, separado por '==':
Ejemplo :
Search.conf :
# this is the general structure
<search>==<replace>
# this is a comment
# fix cardinal direction abbreviations
N.E.==north east
# be careful with your regexes, as this would also match Sally N. Smith
N.==north
# pronounce Barbadoes like the locals
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.confEjemplo :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewEsta herramienta está disponible como una imagen de Docker, lo que facilita la ejecución sin necesidad de administrar las dependencias de Python.
Primero, asegúrese de tener Docker instalado en su sistema.
Puede extraer la imagen Docker del registro de contenedores GitHub:
docker pull ghcr.io/p0n1/epub_to_audiobook:latestLuego, puede ejecutar la herramienta con el siguiente comando:
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY= $MS_TTS_KEY -e MS_TTS_REGION= $MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azurePara OpenAi, puedes ejecutar:
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY= $OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai Reemplace $MS_TTS_KEY y $MS_TTS_REGION con sus credenciales de API de texto a voz de Azure. Reemplace $OPENAI_API_KEY con su tecla API OpenAI. Reemplace your_book.epub con el nombre del archivo Epub de entrada y audiobook_output con el nombre del directorio donde desea guardar los archivos de salida.
La opción -v ./:/app monta el directorio actual ( . ) En el directorio /app en el contenedor Docker. Esto permite que la herramienta lea el archivo de entrada y escriba los archivos de salida en su sistema de archivos local.
Las opciones -i y -t son necesarias para habilitar el modo interactivo y asignar un pseudo -tty.
También puede verificar el archivo de configuración de este ejemplo para el uso de Docker Compose.
Para los usuarios de Windows, especialmente si no está muy familiarizado con las herramientas de línea de comandos, lo tenemos cubierto. Entendemos los desafíos y hemos creado una guía específicamente adaptada para usted.
Verifique esta guía paso a paso y deje un mensaje si encuentra problemas.
Fuente: https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/get-started-text-to-speech#perrerequisites
Consulte https://platform.openai.com/docs/quickstart/account-setup. Asegúrese de verificar los detalles del precio antes de usar.
Los TTS y Azure TTS son casi la misma, la diferencia es que los TT de borde no requieren la tecla API porque se basa en la funcionalidad de lectura de borde, y los parámetros están restringidos un poco, como SSML personalizado.
Consulte https://gist.github.com/bettyjj/17cbaa1de96235a7f5773b8690a20462 para voces compatibles.
Si desea probar este proyecto rápidamente, Edge TTS es muy recomendable.
Puede personalizar la voz y el lenguaje utilizados para la conversión de texto a voz pasando las opciones --voice_name y --language al ejecutar el script.
Microsoft Azure ofrece una gama de voces e idiomas para el servicio de texto a voz. Para obtener una lista de opciones disponibles, consulte la documentación de texto a voz de Microsoft Azure.
También puede escuchar muestras de las voces disponibles en la galería de voz Azure TTS para ayudarlo a elegir la mejor voz para su audiolibro.
Por ejemplo, si desea usar una voz femenina inglesa británica para la conversión, puede usar el siguiente comando:
python3 main.py < input_file > < output_folder > --voice_name en-GB-LibbyNeural --language en-GB Para OpenAI TTS, puede especificar las opciones de modelo, voz y formato utilizando --model_name , --voice_name y --output_format , respectivamente.
Aquí hay algunos ejemplos que demuestran varias combinaciones de opciones:
Conversión básica usando Azure con configuración predeterminada
Este comando convertirá un archivo EPUB en un audiolibro utilizando la configuración TTS predeterminada de Azure.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure Conversión de Azure con lenguaje personalizado, voz y nivel de registro
Convierte un archivo EPUB en un audiolibro con una voz especificada y un nivel de registro personalizado para fines de depuración.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --language zh-CN --voice_name " zh-CN-YunyeNeural " --log DEBUG Conversión de Azure con rango de capítulos y duración de la ruptura
Convierte un rango específico de capítulos de un archivo EPUB a un audiolibro con duración de ruptura personalizada entre los párrafos.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --chapter_start 5 --chapter_end 10 --break_duration " 1500 " Conversión básica usando OpenAI con configuración predeterminada
Este comando convertirá un archivo EPUB en un audiolibro utilizando la configuración TTS predeterminada de OpenAI.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai Conversión de Operai con modelo HD y voz específica
Convierte un archivo EPUB en un audiolibro utilizando el modelo OpenAI de alta definición y una opción de voz específica.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --model_name " tts-1-hd " --voice_name " fable " Conversión de OpenAI con vista previa y salida de texto
Habilita el modo de vista previa y la salida de texto, que mostrará el índice de capítulo y los títulos en lugar de convertirlos y también exportará el texto.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --preview --output_text Conversión básica usando Edge con configuración predeterminada
Este comando convertirá un archivo EPUB en un audiolibro utilizando la configuración TTS predeterminada de Edge.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edgeLa conversión de borde con lenguaje personalizado, nivel de voz y registro convierte un archivo EPUB en un audiolibro con una voz especificada y un nivel de registro personalizado para fines de depuración.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --language zh-CN --voice_name " zh-CN-YunxiNeural " --log DEBUGLa conversión de borde con el rango de capítulos y la duración de la ruptura convierte un rango específico de capítulos de un archivo EPUB a un audiolibro con duración de ruptura personalizada entre los párrafos.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --chapter_start 5 --chapter_end 10 --break_duration " 1500 "Asegúrese de haber instalado Piper TTS y tener un archivo de modelo ONNX y un archivo de configuración correspondiente. Consulte Piper TTS para obtener más detalles. Puede seguir sus instrucciones para instalar Piper TTS, descargar los modelos y los archivos de configuración, reproducir con él y luego volver para probar los ejemplos a continuación.
Este comando convertirá un archivo EPUB en un audiolibro utilizando Piper TTS utilizando los parámetros mínimos. Siempre debe especificar un archivo de modelo ONNX y el ejecutable piper debe estar en la ruta $ actual.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx Puede especificar su ruta personalizada al ejecutable Piper utilizando el parámetro --piper_path .
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_path < path_to > /piperAlgunos modelos admiten múltiples voces y eso se puede especificar utilizando el parámetro Voice_Name.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256También puede especificar la velocidad (piper_length_scale) y la duración de la pausa (piper_sentence_silence).
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 Piper TTS emite archivos de formato wav (o RAW) de forma predeterminada, debe poder especificar cualquier formato razonable a través del parámetro --output_format . El opus y mp3 son buenas opciones para el tamaño y la compatibilidad.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opus Esto puede deberse a que la versión de Python que está utilizando es inferior a 3.8. Puede intentar instalarlo manualmente por pip3 install importlib-metadata , o usar una versión de Python más alta.
Asegúrese de que FFMPEG binary sea accesible desde su camino. Si está en una Mac y usa Homebrew, puede hacer brew install ffmpeg , en Ubuntu puede hacer sudo apt install ffmpeg
Para cuestiones relacionadas con la instalación, consulte el repositorio Piper TTS. Es importante tener en cuenta que si está instalando piper-tts a través de PIP, solo se admite Python 3.10 actualmente. Los usuarios de Mac pueden enfrentar desafíos adicionales al usar el binario descargado. Para obtener más información sobre temas específicos de Mac, consulte este problema y esta solicitud de extracción.
También verifique esto si tiene problemas con Piper TTS.
Este proyecto tiene licencia bajo la licencia MIT. Consulte el archivo de licencia para obtener más detalles.


