epub_to_audiobook
v0.6.1
Rejoignez notre serveur Discord pour toute question ou discussion.
Ce projet fournit un outil de ligne de commande pour convertir les livres électroniques EPUB en livres audio. Il prend désormais en charge l'API Microsoft Azure Text-to-Speech (API alternativement Edgetts) et l'OpenAI Text-to-Speech pour générer l'audio pour chaque chapitre de l'ebook. Les fichiers audio de sortie sont optimisés pour une utilisation avec AudioRebookShelf.
Ce projet est développé avec l'aide de Chatgpt.
Si vous souhaitez entendre un échantillon du livre audio généré par cet outil, vérifiez les liens ci-dessous.
Les livres audio générés par ce projet sont optimisés pour une utilisation avec Audiobookshelf. Chaque chapitre du fichier EPUB est converti en un fichier MP3 séparé, avec le titre de chapitre extrait et inclus sous forme de métadonnées.
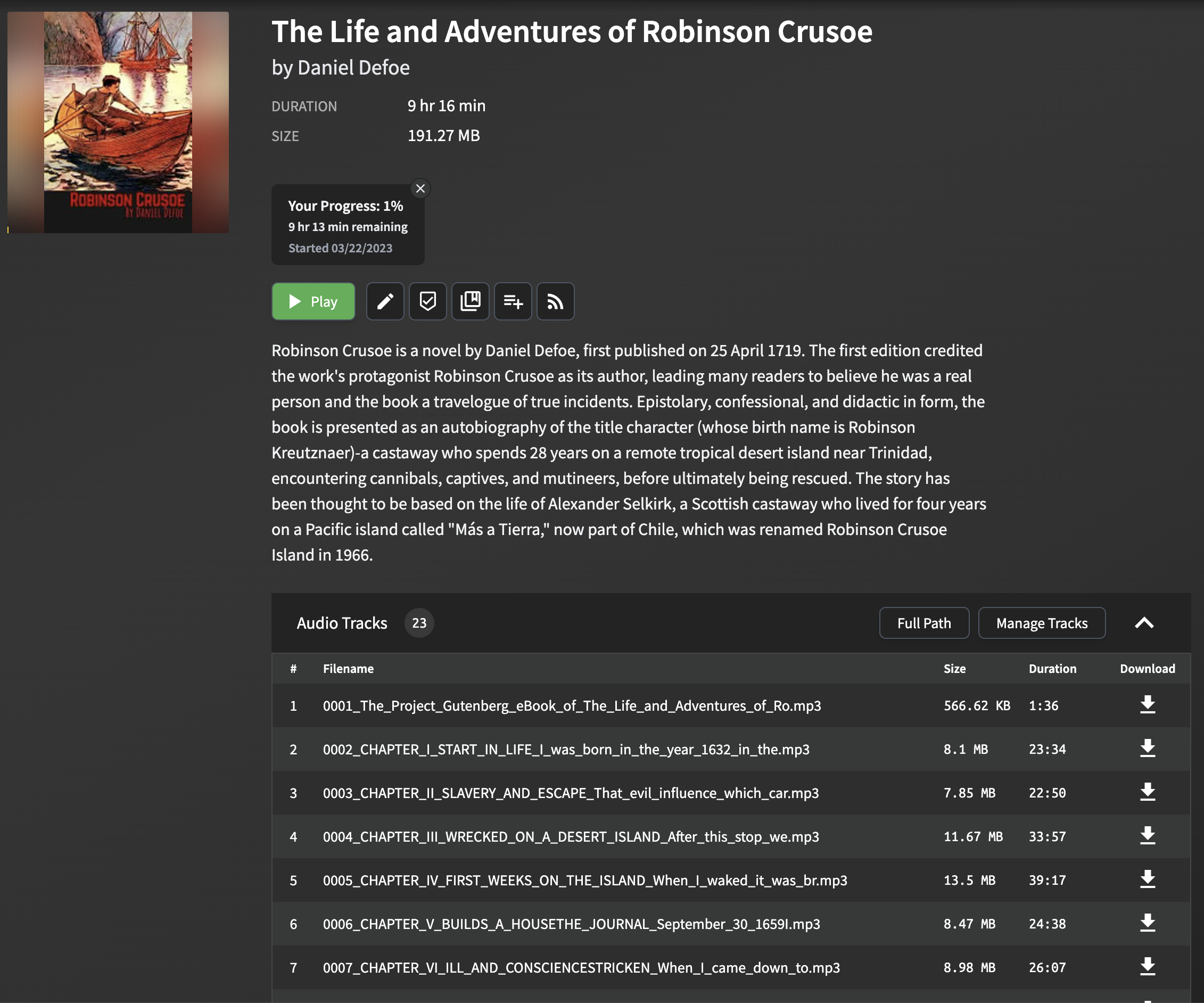
L'analyse et l'extraction des titres de chapitre des fichiers EPUB peuvent être difficiles, car le format et la structure peuvent varier considérablement entre les différents livres électroniques. Le script utilise une méthode simple mais efficace pour extraire les titres de chapitre, qui fonctionne pour la plupart des fichiers EPUB. La méthode consiste à analyser le fichier EPUB et à rechercher la balise title dans le contenu HTML de chaque chapitre. Si la balise de titre n'est pas présente, un titre de secours est généré en utilisant les premiers mots du texte du chapitre.
Veuillez noter que cette approche peut ne pas fonctionner parfaitement pour tous les fichiers EPUB, en particulier ceux qui ont un formatage complexe ou inhabituel. Cependant, dans la plupart des cas, il fournit un moyen fiable d'extraire les titres de chapitre à utiliser dans AudioRebookshelf.
Lorsque vous importez les fichiers MP3 générés dans AudiobookShelf, les titres de chapitre seront affichés, ce qui facilite la navigation entre les chapitres et l'amélioration de votre expérience d'écoute.
Cloner ce référentiel:
git clone https://github.com/p0n1/epub_to_audiobook.git
cd epub_to_audiobookCréez un environnement virtuel et activez-le:
python3 -m venv venv
source venv/bin/activateInstallez les dépendances requises:
pip install -r requirements.txtDéfinissez les variables d'environnement suivantes avec vos informations d'identification Azure Text-to-Speech API, ou votre clé API OpenAI si vous utilisez OpenAI TTS:
export MS_TTS_KEY= < your_subscription_key > # for Azure
export MS_TTS_REGION= < your_region > # for Azure
export OPENAI_API_KEY= < your_openai_api_key > # for OpenAI Pour convertir un eBook EPUB en un livre audio, exécutez la commande suivante, en spécifiant le fournisseur TTS de votre choix avec l'option --tts :
python3 main.py < input_file > < output_folder > [options]Pour vérifier les dernières descriptions d'options pour ce script, vous pouvez exécuter la commande suivante dans le terminal:
python3 main.py -husage: main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
Convert text book to audiobook
positional arguments:
input_file Path to the EPUB file
output_folder Path to the output folder
options:
-h, --help show this help message and exit
--tts {azure,openai,edge,piper}
Choose TTS provider (default: azure). azure: Azure
Cognitive Services, openai: OpenAI TTS API. When using
azure, environment variables MS_TTS_KEY and
MS_TTS_REGION must be set. When using openai,
environment variable OPENAI_API_KEY must be set.
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Log level (default: INFO), can be DEBUG, INFO,
WARNING, ERROR, CRITICAL
--preview Enable preview mode. In preview mode, the script will
not convert the text to speech. Instead, it will print
the chapter index, titles, and character counts.
--no_prompt Don ' t ask the user if they wish to continue after
estimating the cloud cost for TTS. Useful for
scripting.
--language LANGUAGE Language for the text-to-speech service (default: en-
US). For Azure TTS (--tts=azure), check
https://learn.microsoft.com/en-us/azure/ai-
services/speech-service/language-
support?tabs=tts#text-to-speech for supported
languages. For OpenAI TTS (--tts=openai), their API
detects the language automatically. But setting this
will also help on splitting the text into chunks with
different strategies in this tool, especially for
Chinese characters. For Chinese books, use zh-CN, zh-
TW, or zh-HK.
--newline_mode {single,double,none}
Choose the mode of detecting new paragraphs: ' single ' ,
' double ' , or ' none ' . ' single ' means a single newline
character, while ' double ' means two consecutive
newline characters. ' none ' means all newline
characters will be replace with blank so paragraphs
will not be detected. (default: double, works for most
ebooks but will detect less paragraphs for some
ebooks)
--title_mode {auto,tag_text,first_few}
Choose the parse mode for chapter title, ' tag_text '
search ' title ' , ' h1 ' , ' h2 ' , ' h3 ' tag for title,
' first_few ' set first 60 characters as title, ' auto '
auto apply the best mode for current chapter.
--chapter_start CHAPTER_START
Chapter start index (default: 1, starting from 1)
--chapter_end CHAPTER_END
Chapter end index (default: -1, meaning to the last
chapter)
--output_text Enable Output Text. This will export a plain text file
for each chapter specified and write the files to the
output folder specified.
--remove_endnotes This will remove endnote numbers from the end or
middle of sentences. This is useful for academic
books.
--search_and_replace_file SEARCH_AND_REPLACE_FILE
Path to a file that contains 1 regex replace per line,
to help with fixing pronunciations, etc. The format
is: <search>==<replace> Note that you may have to
specify word boundaries, to avoid replacing parts of
words.
--voice_name VOICE_NAME
Various TTS providers has different voice names, look
up for your provider settings.
--output_format OUTPUT_FORMAT
Output format for the text-to-speech service.
Supported format depends on selected TTS provider
--model_name MODEL_NAME
Various TTS providers has different neural model names
edge specific:
--voice_rate VOICE_RATE
Speaking rate of the text. Valid relative values range
from -50%(--xxx= ' -50% ' ) to +100%. For negative value
use format --arg=value,
--voice_volume VOICE_VOLUME
Volume level of the speaking voice. Valid relative
values floor to -100%. For negative value use format
--arg=value,
--voice_pitch VOICE_PITCH
Baseline pitch for the text.Valid relative values like
-80Hz,+50Hz, pitch changes should be within 0.5 to 1.5
times the original audio. For negative value use
format --arg=value,
--proxy PROXY Proxy server for the TTS provider. Format:
http://[username:password@]proxy.server:port
azure/edge specific:
--break_duration BREAK_DURATION
Break duration in milliseconds for the different
paragraphs or sections (default: 1250, means 1.25 s).
Valid values range from 0 to 5000 milliseconds for
Azure TTS.
piper specific:
--piper_path PIPER_PATH
Path to the Piper TTS executable
--piper_speaker PIPER_SPEAKER
Piper speaker id, used for multi-speaker models
--piper_sentence_silence PIPER_SENTENCE_SILENCE
Seconds of silence after each sentence
--piper_length_scale PIPER_LENGTH_SCALE
Phoneme length, a.k.a. speaking rateExemple :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder L'exécution de la commande ci-dessus générera un répertoire nommé output_folder et enregistrera les fichiers MP3 pour chaque chapitre à l'intérieur à l'aide du fournisseur et de la voix TTS par défaut. Une fois généré, vous pouvez importer ces fichiers audio dans AudiobookShelflf ou les lire avec n'importe quel lecteur audio de votre choix.
Avant de convertir votre fichier EPUB en un livre audio, vous pouvez utiliser l'option --preview pour obtenir un résumé de chaque chapitre. Cela vous fournira le nombre de caractères de chaque chapitre et le nombre total, au lieu de convertir le texte en discours.
Exemple :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewVous voudrez peut-être rechercher et remplacer le texte, soit pour étendre les abréviations, soit pour aider à la prononciation. Vous pouvez le faire en spécifiant un fichier de recherche et de remplacement, qui contient une seule recherche regex et remplace par ligne, séparée par '==':
Exemple :
search.conf :
# this is the general structure
<search>==<replace>
# this is a comment
# fix cardinal direction abbreviations
N.E.==north east
# be careful with your regexes, as this would also match Sally N. Smith
N.==north
# pronounce Barbadoes like the locals
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.confExemple :
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --previewCet outil est disponible sous forme d'image Docker, ce qui facilite l'exécution sans avoir besoin de gérer les dépendances Python.
Tout d'abord, assurez-vous que Docker est installé sur votre système.
Vous pouvez tirer l'image Docker du registre des conteneurs GitHub:
docker pull ghcr.io/p0n1/epub_to_audiobook:latestEnsuite, vous pouvez exécuter l'outil avec la commande suivante:
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY= $MS_TTS_KEY -e MS_TTS_REGION= $MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azurePour Openai, vous pouvez courir:
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY= $OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai Remplacez $MS_TTS_KEY et $MS_TTS_REGION par vos informations d'identification Azure Text-to-Speech. Remplacez $OPENAI_API_KEY par votre touche API OpenAI. Remplacez your_book.epub par le nom du fichier EPUB d'entrée et audiobook_output par le nom du répertoire où vous souhaitez enregistrer les fichiers de sortie.
L'option -v ./:/app monte le répertoire actuel ( . ) Vers le répertoire /app dans le conteneur Docker. Cela permet à l'outil de lire le fichier d'entrée et d'écrire les fichiers de sortie dans votre système de fichiers local.
Les options -i et -t sont nécessaires pour activer le mode interactif et allouer un pseudo-tty.
Vous pouvez également vérifier le fichier de configuration de cet exemple pour l'utilisation de Docker Compose.
Pour les utilisateurs de Windows, surtout si vous n'êtes pas très familier avec les outils de ligne de commande, nous vous avons couvert. Nous comprenons les défis et avons créé un guide spécifiquement adapté pour vous.
Consultez ce guide étape par étape et laissez un message si vous rencontrez des problèmes.
Source: https://learn.microsoft.com/en-us/azure/cognititive-services/spech-service/get-started-text-to-speech#prerequisites
Consultez https://platform.openai.com/docs/quickstart/account-setup. Assurez-vous de vérifier les détails du prix avant utilisation.
Edge TTS et Azure TTS sont presque les mêmes, la différence est que Edge TTS ne nécessite pas de clé API car elle est basée sur la fonctionnalité à haute voix de bord, et les paramètres sont un peu restreints, comme le SSML personnalisé.
Vérifiez https://gist.github.com/bettyjj/17cbaa1de96235a7f5773b8690a20462 pour les voix prises en charge.
Si vous souhaitez essayer ce projet rapidement, Edge TTS est fortement recommandé.
Vous pouvez personnaliser la voix et le langage utilisées pour la conversion de texte-parole en passant les options --voice_name et --language lors de l'exécution du script.
Microsoft Azure propose une gamme de voix et de langues pour le service de texte vocal. Pour une liste des options disponibles, consultez la documentation de texte-vocation Microsoft Azure.
Vous pouvez également écouter des échantillons des voix disponibles dans la galerie de voix Azure TTS pour vous aider à choisir la meilleure voix pour votre livre audio.
Par exemple, si vous souhaitez utiliser une voix féminine anglaise britannique pour la conversion, vous pouvez utiliser la commande suivante:
python3 main.py < input_file > < output_folder > --voice_name en-GB-LibbyNeural --language en-GB Pour OpenAI TTS, vous pouvez spécifier les options de modèle, de voix et de format à l'aide --model_name , --voice_name et --output_format , respectivement.
Voici quelques exemples qui démontrent diverses combinaisons d'options:
Conversion de base à l'aide d'Azure avec paramètres par défaut
Cette commande convertira un fichier EPUB en un livre audio à l'aide des paramètres TTS par défaut d'Azure.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure Conversion azure avec un langage personnalisé, une voix et un niveau de journalisation
Convertit un fichier EPUB en livre audio avec une voix spécifiée et un niveau de journal personnalisé à des fins de débogage.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --language zh-CN --voice_name " zh-CN-YunyeNeural " --log DEBUG Conversion azure avec la plage de chapitre et la durée de rupture
Convertit une gamme spécifiée de chapitres d'un fichier EPUB en un livre audio avec une durée de rupture personnalisée entre les paragraphes.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts azure --chapter_start 5 --chapter_end 10 --break_duration " 1500 " Conversion de base à l'aide d'OpenAI avec paramètres par défaut
Cette commande convertira un fichier EPUB en un livre audio à l'aide des paramètres TTS par défaut d'OpenAI.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai Conversion Openai avec le modèle HD et la voix spécifique
Convertit un fichier EPUB en un livre audio à l'aide du modèle OpenAI haute définition et d'un choix vocal spécifique.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --model_name " tts-1-hd " --voice_name " fable " Conversion Openai avec aperçu et sortie de texte
Permet le mode d'aperçu et la sortie du texte, qui affichera l'index de chapitre et les titres au lieu de les convertir et exportera également le texte.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts openai --preview --output_text Conversion de base en utilisant le bord avec les paramètres par défaut
Cette commande convertira un fichier EPUB en livre audio utilisant les paramètres TTS par défaut d'Edge.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edgeLa conversion Edge avec le langage personnalisé, la voix et le niveau de journalisation convertit un fichier ePub en un livre audio avec une voix spécifiée et un niveau de journal personnalisé à des fins de débogage.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --language zh-CN --voice_name " zh-CN-YunxiNeural " --log DEBUGLa conversion de bord avec la plage de chapitre et la durée de rupture convertit une gamme spécifiée de chapitres d'un fichier ePub à un livre audio avec une durée de rupture personnalisée entre les paragraphes.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts edge --chapter_start 5 --chapter_end 10 --break_duration " 1500 "Assurez-vous d'avoir installé Piper TTS et d'avoir un fichier de modèle ONNX et un fichier de configuration correspondant. Vérifiez Piper TTS pour plus de détails. Vous pouvez suivre leurs instructions pour installer Piper TTS, télécharger les modèles et configurer des fichiers, lire avec lui, puis revenir pour essayer les exemples ci-dessous.
Cette commande convertira un fichier EPUB en un livre audio à l'aide de Piper TTS en utilisant les paramètres minimums nus. Vous devez toujours spécifier un fichier de modèle ONNX et l'exécutable piper doit être dans le chemin $ actuel.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx Vous pouvez spécifier votre chemin personnalisé vers l'exécutable Piper en utilisant le paramètre --piper_path .
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_path < path_to > /piperCertains modèles prennent en charge plusieurs voix et cela peut être spécifié en utilisant le paramètre Voice_name.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256Vous pouvez également spécifier la vitesse (piper_length_scale) et la durée de pause (Piper_Sentence_Silence).
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 Piper TTS sortira des fichiers de format wav (ou brut) par défaut, vous devez être en mesure de spécifier tout format raisonnable via le paramètre --output_format . L' opus et mp3 sont de bons choix pour la taille et la compatibilité.
python3 main.py " path/to/book.epub " " path/to/output/folder " --tts piper --model_name < path_to > /en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opus Cela peut être dû au fait que la version Python que vous utilisez est inférieure à 3,8. Vous pouvez essayer de l'installer manuellement par pip3 install importlib-metadata ou d'utiliser une version Python plus élevée.
Assurez-vous que le binaire FFMPEG est accessible à partir de votre chemin. Si vous êtes sur un Mac et utilisez HomeBrew, vous pouvez faire brew install ffmpeg , sur Ubuntu, vous pouvez faire sudo apt install ffmpeg
Pour les problèmes liés à l'installation, veuillez vous référer au référentiel Piper TTS. Il est important de noter que si vous installez piper-tts via PIP, seul Python 3.10 est actuellement pris en charge. Les utilisateurs de Mac peuvent rencontrer des défis supplémentaires lors de l'utilisation du binaire téléchargé. Pour plus d'informations sur les problèmes spécifiques à Mac, veuillez vérifier ce problème et cette demande de traction.
Vérifiez également cela si vous rencontrez des problèmes avec Piper TTS.
Ce projet est autorisé sous la licence du MIT. Voir le fichier de licence pour plus de détails.


