gpt tokenizer
2.7.0
gpt-tokenizer เป็นตัวเข้ารหัส/ตัวถอดรหัสคู่โทเค็นที่รองรับโมเดลของ OpenAI ทั้งหมด (รวมถึง GPT-3.5, GPT-4, GPT-4O และ O1) เป็น GPT Tokenizer ที่เร็วที่สุดน้อยที่สุดและต่ำที่สุด สำหรับสภาพแวดล้อม JavaScript ทั้งหมด มันเขียนเป็น typeScript
ห้องสมุดนี้เชื่อถือได้โดย:
กรุณาพิจารณา? สนับสนุนโครงการหากคุณพบว่ามีประโยชน์
ตั้งแต่ปี 2023 มันเป็น Tokenizer GPT โอเพนซอร์ซที่สมบูรณ์แบบที่สุดใน NPM แพ็คเกจนี้เป็นพอร์ตของ Tiktoken ของ Openai พร้อมคุณสมบัติเพิ่มเติมที่เป็นเอกลักษณ์เพิ่มขึ้นด้านบน:
encodeChatr50k_base , p50k_base , p50k_edit , cl100k_base และ o200k_base )decodeAsyncGenerator และ decodeGenerator ด้วยอินพุตที่วนซ้ำ)isWithinTokenLimit ที่มีประสิทธิภาพสูงเพื่อประเมินขีด จำกัด โทเค็นโดยไม่ต้องเข้ารหัสข้อความ/แชททั้งหมดnpm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >หากคุณต้องการใช้การเข้ารหัสแบบกำหนดเองให้ดึงสคริปต์ที่เกี่ยวข้อง
gpt-4o และ o1 )gpt-4-* และ gpt-3.5-turbo ) ชื่อทั่วโลกคือการเชื่อมต่อ: GPTTokenizer_${encoding}
อ้างถึงโมเดลที่รองรับและส่วนการเข้ารหัสของพวกเขาสำหรับข้อมูลเพิ่มเติม
สนามเด็กเล่นได้รับการเผยแพร่ภายใต้ URL ที่น่าจดจำ: https://gpt-tokenizer.dev/
คุณสามารถเล่นกับแพ็คเกจในเบราว์เซอร์โดยใช้สนามเด็กเล่นโค้ดและบ็อกซ์
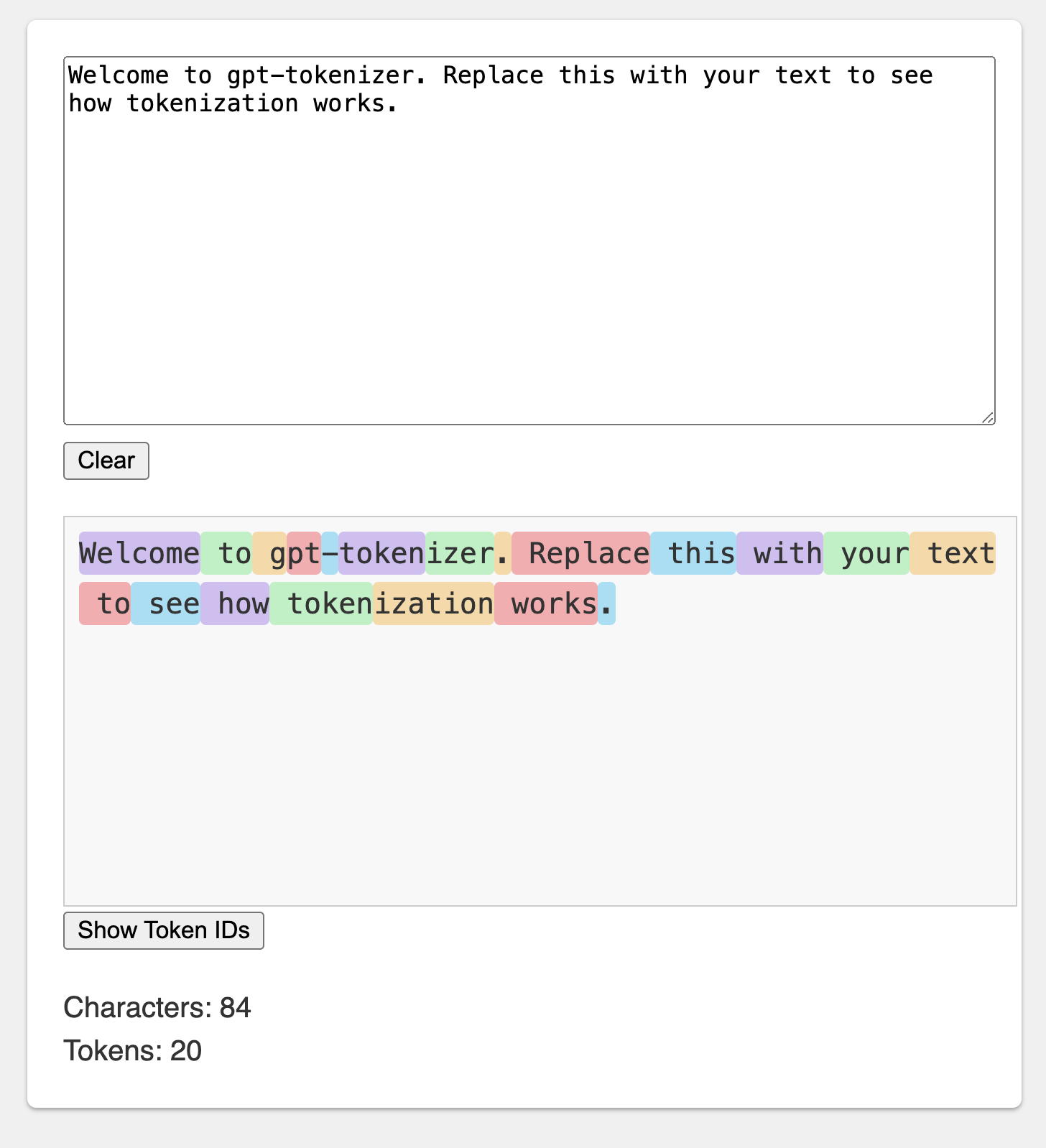
สนามเด็กเล่นเลียนแบบ Openai Tokenizer อย่างเป็นทางการ
ห้องสมุดมีฟังก์ชั่นต่าง ๆ ในการแปลงข้อความเป็น (และจาก) ลำดับของจำนวนเต็ม (โทเค็น) ที่สามารถป้อนเข้าสู่โมเดล LLM การแปลงทำได้โดยใช้อัลกอริทึมการเข้ารหัสคู่ไบต์ (BPE) ที่ใช้โดย OpenAI
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} โดยค่าเริ่มต้นการนำเข้าจาก gpt-tokenizer ใช้การเข้ารหัส cl100k_base ใช้โดย gpt-3.5-turbo และ gpt-4
หากต้องการรับ tokenizer สำหรับรุ่นที่แตกต่างนำเข้าโดยตรงตัวอย่างเช่น:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' หากคุณกำลังจัดการกับตัวแก้ไขที่ไม่สนับสนุนแพ็คเกจความละเอียด exports JSON คุณอาจต้องนำเข้าจากไดเรกทอรี cjs หรือ esm ที่เกี่ยวข้องเช่น::
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' หากคุณไม่สนใจที่จะโหลด tokenizer แบบอะซิงโครนัสคุณสามารถใช้การนำเข้าแบบไดนามิกภายในฟังก์ชั่นของคุณเช่น:
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) หากโมเดลของคุณไม่ได้รับการสนับสนุนโดยแพ็คเกจ แต่คุณรู้ว่าการเข้ารหัส BPE ใดที่ใช้คุณสามารถโหลดการเข้ารหัสได้โดยตรงเช่น:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) หมายเหตุ: หากคุณใช้ gpt-3.5-* หรือ gpt-4-* และไม่เห็นโมเดลที่คุณกำลังมองหาให้ใช้การเข้ารหัส cl100k_base โดยตรง
encode(text: string): number[]เข้ารหัสข้อความที่กำหนดเป็นลำดับของโทเค็น ใช้วิธีนี้เมื่อคุณต้องการแปลงข้อความเป็นรูปแบบโทเค็นที่รุ่น GPT สามารถประมวลผลได้
ตัวอย่าง:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringถอดรหัสลำดับโทเค็นกลับเป็นข้อความ ใช้วิธีนี้เมื่อคุณต้องการแปลงโทเค็นเอาต์พุตจากรุ่น GPT กลับเป็นข้อความที่มนุษย์อ่านได้
ตัวอย่าง:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number ตรวจสอบว่าข้อความอยู่ในขีด จำกัด โทเค็นหรือไม่ ส่งคืน false หากเกินขีด จำกัด มิฉะนั้นจะส่งคืนจำนวนโทเค็น ใช้วิธีนี้เพื่อตรวจสอบอย่างรวดเร็วว่าข้อความที่กำหนดอยู่ในขีด จำกัด โทเค็นที่กำหนดโดยรุ่น GPT โดยไม่ต้องเข้ารหัสข้อความทั้งหมด
ตัวอย่าง:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): numberนับจำนวนโทเค็นในข้อความอินพุตหรือแชท ใช้วิธีนี้เมื่อคุณต้องการกำหนดจำนวนโทเค็นโดยไม่ตรวจสอบกับขีด จำกัด
ตัวอย่าง:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]เข้ารหัสแชทที่กำหนดเป็นลำดับของโทเค็น
หากคุณไม่ได้นำเข้ารุ่นรุ่นโดยตรงหรือหากไม่ได้ให้ model ในระหว่างการเริ่มต้นจะต้องให้ที่นี่เพื่อให้การแชทอย่างถูกต้องสำหรับรุ่นที่กำหนด ใช้วิธีนี้เมื่อคุณต้องการแปลงการแชทในรูปแบบโทเค็นที่รุ่น GPT สามารถประมวลผลได้
ตัวอย่าง:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )โปรดทราบว่าหากคุณเข้ารหัสแชทที่ว่างเปล่ามันจะยังคงมีจำนวนโทเค็นพิเศษขั้นต่ำ
encodeGenerator(text: string): Generator<number[], void, undefined>เข้ารหัสข้อความที่กำหนดโดยใช้เครื่องกำเนิดไฟฟ้าซึ่งให้ผลผลิตโทเค็น ใช้วิธีนี้เมื่อคุณต้องการเข้ารหัสข้อความเป็นชิ้นซึ่งอาจเป็นประโยชน์สำหรับการประมวลผลข้อความขนาดใหญ่หรือการสตรีมข้อมูล
ตัวอย่าง:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> เช่นเดียวกับ encodeChat แต่ใช้เครื่องกำเนิดไฟฟ้าเป็นเอาต์พุตและอาจใช้ตัววนซ้ำใด ๆ เป็น chat อินพุต
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>ถอดรหัสลำดับโทเค็นโดยใช้เครื่องกำเนิดไฟฟ้าซึ่งให้ชิ้นส่วนของข้อความถอดรหัส ใช้วิธีนี้เมื่อคุณต้องการถอดรหัสโทเค็นเป็นชิ้นซึ่งอาจเป็นประโยชน์สำหรับการประมวลผลเอาต์พุตขนาดใหญ่หรือข้อมูลสตรีมมิ่ง
ตัวอย่าง:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>ถอดรหัสลำดับของโทเค็นแบบอะซิงโครนัสโดยใช้เครื่องกำเนิดไฟฟ้าซึ่งให้ชิ้นส่วนของข้อความถอดรหัส ใช้วิธีนี้เมื่อคุณต้องการถอดรหัสโทเค็นในชิ้นส่วนแบบอะซิงโครนัสซึ่งอาจเป็นประโยชน์สำหรับการประมวลผลเอาต์พุตขนาดใหญ่หรือการสตรีมข้อมูลในบริบทแบบอะซิงโครนัส
ตัวอย่าง:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} มีโทเค็นพิเศษบางอย่างที่ใช้โดยรุ่น GPT ไม่ใช่ทุกรุ่นที่รองรับโทเค็นเหล่านี้ทั้งหมด
gpt-tokenizer ช่วยให้คุณสามารถระบุชุดโทเค็นพิเศษที่ได้รับอนุญาตเมื่อเข้ารหัสข้อความ ในการทำเช่นนี้ให้ผ่าน Set ที่มีโทเค็นพิเศษที่อนุญาตเป็นพารามิเตอร์ไปยังฟังก์ชัน encode :
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) ในทำนองเดียวกันคุณสามารถระบุชุดโทเค็นพิเศษที่ไม่ได้รับอนุญาตเมื่อเข้ารหัสข้อความ ผ่าน Set ที่มีโทเค็นพิเศษที่ไม่ได้รับอนุญาตเป็นพารามิเตอร์ไปยังฟังก์ชัน encode :
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )ในตัวอย่างนี้ข้อผิดพลาดจะถูกโยนลงเนื่องจากข้อความอินพุตมีโทเค็นพิเศษที่ไม่ได้รับอนุญาต
gpt-tokenizer รวมชุดของกรณีทดสอบในไฟล์ testplans.txt เพื่อให้แน่ใจว่าเข้ากันได้กับห้องสมุด Python tiktoken ของ OpenAi กรณีทดสอบเหล่านี้ตรวจสอบการทำงานและพฤติกรรมของ gpt-tokenizer ให้การอ้างอิงที่เชื่อถือได้สำหรับนักพัฒนา
การเรียกใช้การทดสอบหน่วยและตรวจสอบกรณีทดสอบช่วยรักษาความสอดคล้องระหว่างไลบรารีและการใช้งาน Python ดั้งเดิม
gpt-tokenizer ให้ข้อมูลที่ครอบคลุมเกี่ยวกับทุกรุ่น OpenAI ผ่านการส่งออก models จาก gpt-tokenizer/models ซึ่งรวมถึงข้อมูลโดยละเอียดเกี่ยวกับหน้าต่างบริบทค่าใช้จ่ายการตัดข้อมูลการฝึกอบรมและสถานะการเสื่อมราคา
ข้อมูลได้รับการเก็บรักษาไว้อย่างสม่ำเสมอเพื่อให้ตรงกับเอกสารอย่างเป็นทางการของ OpenAI การมีส่วนร่วมเพื่อให้ข้อมูลนี้ทันสมัยยินดีต้อนรับ-หากคุณสังเกตเห็นความแตกต่างใด ๆ หรือมีการอัปเดตโปรดเปิด PR
ตั้งแต่เวอร์ชัน 2.4.0 gpt-tokenizer เป็นการใช้งาน Tokenizer ที่เร็วที่สุดที่มีอยู่ใน NPM มันเร็วกว่าการใช้งาน WASM/โหนดที่มีอยู่ มันมีการเข้ารหัสที่เร็วที่สุดเวลาในการถอดรหัสและรอยเท้าหน่วยความจำเล็ก ๆ นอกจากนี้ยังเริ่มต้นเร็วกว่าการใช้งานอื่น ๆ ทั้งหมด
การเข้ารหัสเองก็มีขนาดเล็กที่สุดเนื่องจากรูปแบบขนาดกะทัดรัดที่เก็บไว้
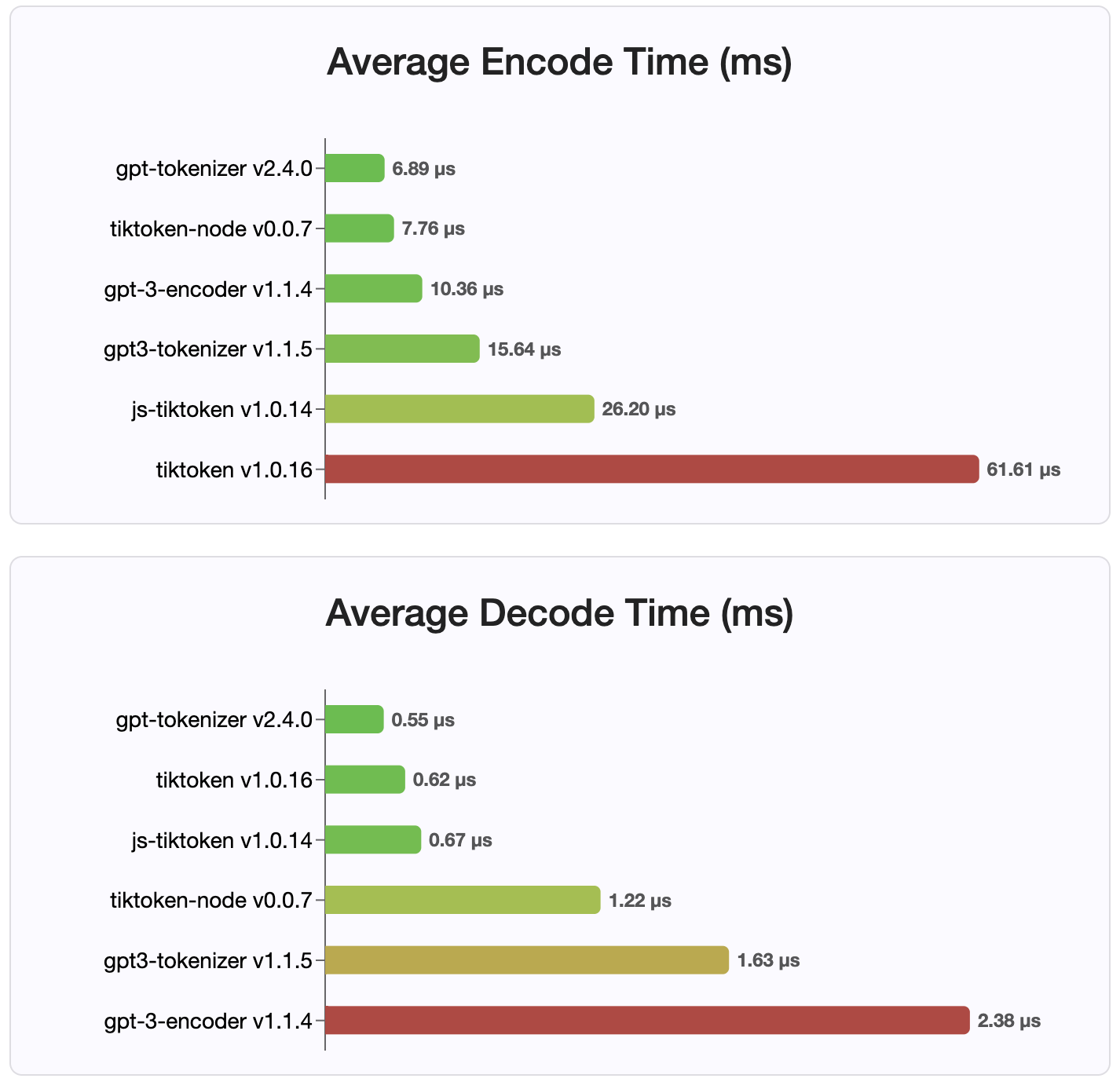
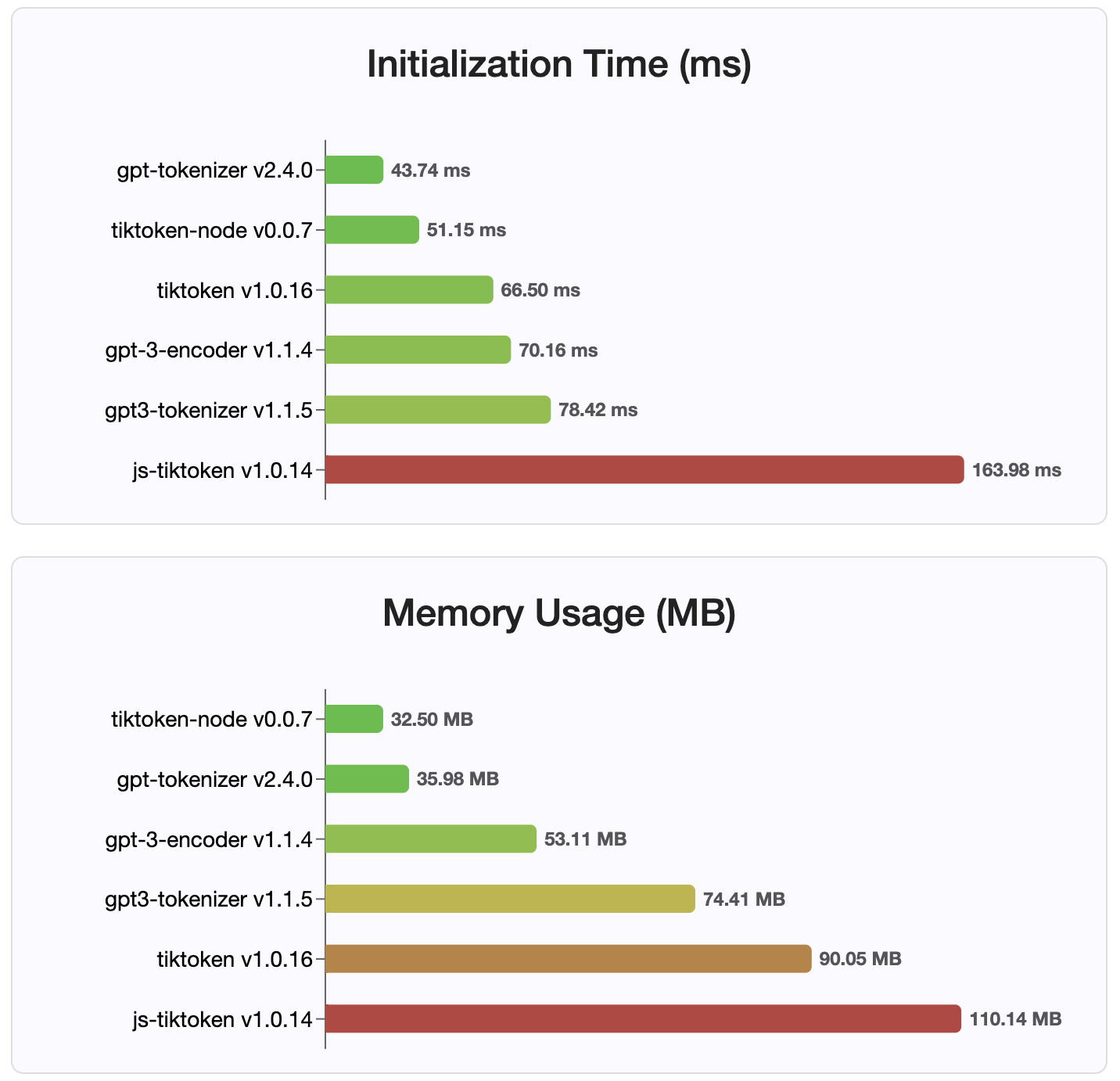
มิกซ์
ยินดีต้อนรับผลงาน! โปรดเปิดคำขอดึงหรือปัญหาเพื่อหารือเกี่ยวกับรายงานข้อผิดพลาดของคุณหรือใช้คุณสมบัติการอภิปรายสำหรับแนวคิดหรือการสอบถามอื่น ๆ
ขอบคุณ Sharpoken ของ @Dmitry-Brazhenko ซึ่งมีรหัสเป็นข้อมูลอ้างอิงสำหรับพอร์ต
หวังว่าคุณจะพบว่า gpt-tokenizer มีประโยชน์ในโครงการของคุณ!


