gpt tokenizer
2.7.0
gpt-tokenizerは、すべてのOpenAIのモデル(GPT-3.5、GPT-4、GPT-4O、およびO1を含む)をサポートするトークンバイトペアエンコーダー/デコーダーです。これは、すべてのJavaScript環境で利用可能な最速、最小、および最低のフットプリントGPTトークン剤です。 TypeScriptで書かれています。
このライブラリは以下によって信頼されています。
考えてみてください?あなたがそれが役立つと思うならば、プロジェクトをスポンサーします。
2023年の時点で、NPMで最も機能を完全に完全にオープンソースGPTトークン化装置です。このパッケージは、OpenaiのTiktokenのポートであり、いくつかの追加のユニークな機能が上に散らばっています。
encodeChat機能のおかげで、簡単にトークン化チャットのサポートr50k_base 、 p50k_base 、 p50k_edit 、 cl100k_base 、 o200k_base )decodeAsyncGeneratorおよびdecodeGeneratorを使用して、任意の反復可能な入力を使用して)isWithinTokenLimit機能を含むnpm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >カスタムエンコードを使用する場合は、関連するスクリプトを取得します。
o1 gpt-4o場合)gpt-4-*およびgpt-3.5-turboの場合)グローバル名は連結です: GPTTokenizer_${encoding} 。
詳細については、サポートされているモデルとそのエンコーディングセクションを参照してください。
遊び場は、記憶に残るURLの下で公開されています:https://gpt-tokenizer.dev/
CodeSandbox Playgroundを使用して、ブラウザでパッケージをプレイできます。
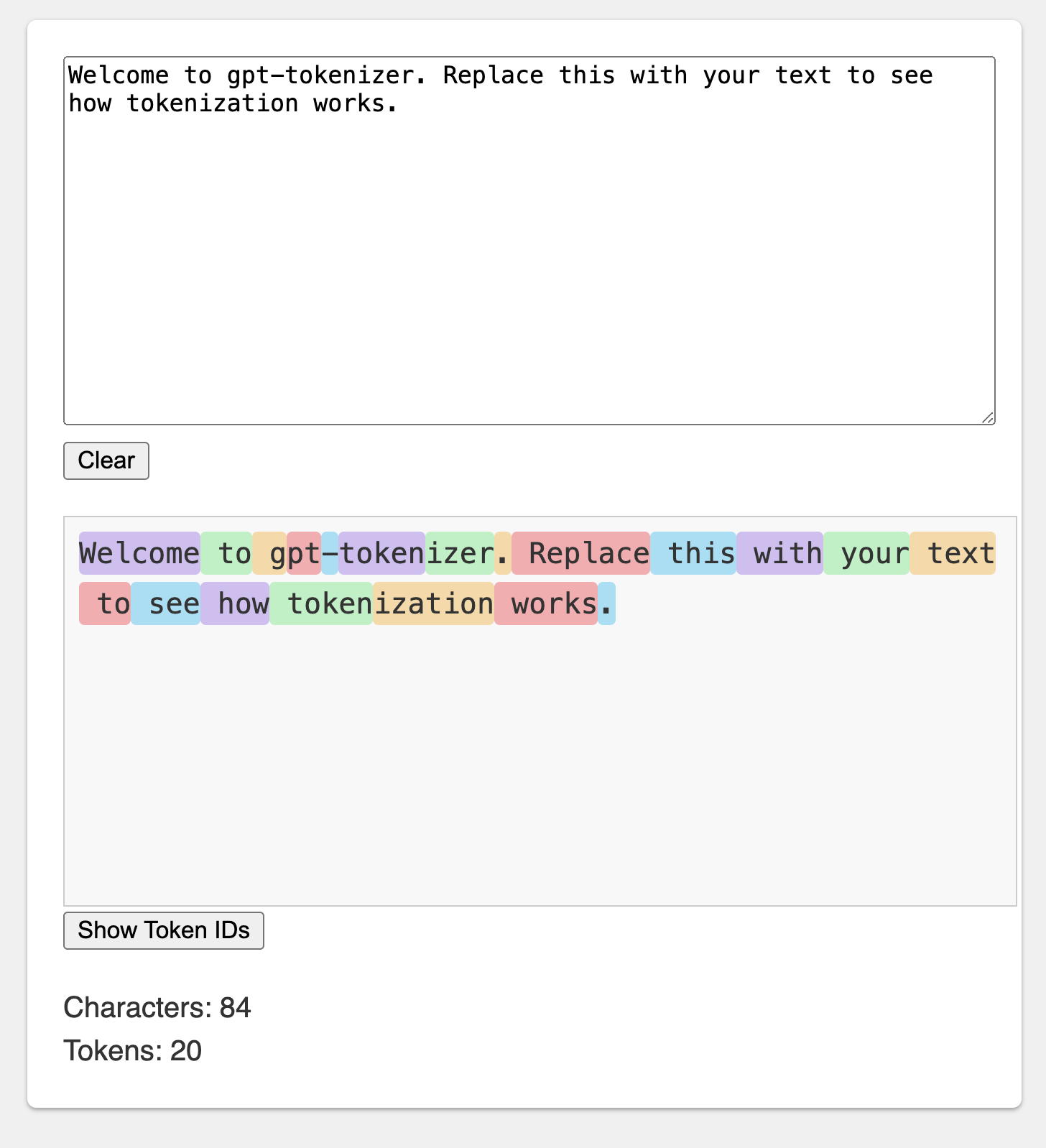
遊び場は、公式のOpenaiトークンザーを模倣しています。
ライブラリは、テキストをLLMモデルに供給できる整数(トークン)のシーケンスに(およびそれから)変換するさまざまな機能を提供します。変換は、OpenAIが使用するバイトペアエンコード(BPE)アルゴリズムを使用して行われます。
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
}デフォルトでは、 gpt-tokenizerからのインポートは、 gpt-3.5-turboおよびgpt-4が使用するcl100k_baseエンコードを使用します。
別のモデルのトークン剤を取得するには、たとえば次のように直接インポートします。
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' package.json exports解像度をサポートしていないリゾルバーを扱っている場合は、それぞれのcjsまたはesmディレクトリからインポートする必要がある場合があります。
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' トークン剤のロードを非同期にロードすることを気にしない場合は、次のように、関数内で動的なインポートを使用できます。
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) モデルがパッケージでサポートされていないが、使用するBPEを使用するBPEを知っている場合、エンコードを直接読み込むことができます。
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base )注: gpt-3.5-*またはgpt-4-*を使用していて、探しているモデルが表示されない場合は、 cl100k_baseエンコードを直接使用してください。
encode(text: string): number[]指定されたテキストを一連のトークンにエンコードします。このメソッドを使用して、GPTモデルが処理できるテキストをトークン形式に変換する必要がある場合に使用します。
例:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringトークンのシーケンスをテキストに戻します。 GPTモデルからの出力トークンを人間の読み取り可能なテキストに戻す場合は、この方法を使用します。
例:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | numberテキストがトークン制限内にあるかどうかを確認します。制限を超えた場合にfalseを返し、それ以外の場合はトークンの数を返します。この方法を使用して、特定のテキストが、テキスト全体をエンコードせずに、GPTモデルによって課されるトークン制限内にあるかどうかを迅速に確認します。
例:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): number入力テキストまたはチャットのトークンの数をカウントします。制限を確認せずにトークンの数を決定する必要がある場合は、この方法を使用してください。
例:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]指定されたチャットを一連のトークンにエンコードします。
モデルバージョンを直接インポートしなかった場合、または初期化中にmodelが提供されなかった場合は、特定のモデルのチャットを正しくトークン化するためにここで提供する必要があります。チャットをGPTモデルが処理できるトークン形式に変換する必要がある場合は、この方法を使用します。
例:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )空のチャットをエンコードすると、最小数の特別なトークンが含まれていることに注意してください。
encodeGenerator(text: string): Generator<number[], void, undefined>発電機を使用して指定されたテキストをエンコードして、トークンの塊を生成します。このメソッドを使用して、テキストをチャンクでエンコードする場合は、大きなテキストやストリーミングデータの処理に役立ちます。
例:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> encodeChatと同じですが、ジェネレーターを出力として使用し、任意のイテレーターを入力chatとして使用する場合があります。
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>ジェネレーターを使用して一連のトークンを解読し、デコードされたテキストの塊を生成します。トークンをチャンクでデコードする場合は、この方法を使用してください。これは、大きな出力やストリーミングデータの処理に役立ちます。
例:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>ジェネレーターを使用して非同期にトークンのシーケンスをデコードし、デコードされたテキストの塊を生成します。この方法を使用して、非同期のコンテキストでの大きな出力やストリーミングデータの処理に役立つことがあります。
例:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} GPTモデルで使用される特別なトークンがいくつかあります。すべてのモデルがこれらすべてのトークンをサポートするわけではありません。
gpt-tokenizer使用すると、テキストをエンコードするときに許可された特別なトークンのカスタムセットを指定できます。これを行うには、 encode関数のパラメーターとして許可された特別なトークンを含むSetを渡します。
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded )同様に、テキストをエンコードするときに、許可されていない特別なトークンのカスタムセットを指定できます。 encode関数のパラメーターとして許可されていない特別なトークンを含むSetを渡します。
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )この例では、入力テキストには許可されていない特別なトークンが含まれているため、エラーがスローされます。
gpt-tokenizerには、OpenAIのPython tiktokenライブラリとの互換性を確保するために、TestPlans.txtファイルにテストケースのセットが含まれています。これらのテストケースは、 gpt-tokenizerの機能と動作を検証し、開発者に信頼できる参照を提供します。
ユニットテストを実行し、テストケースを検証することは、ライブラリと元のPython実装との間の一貫性を維持するのに役立ちます。
gpt-tokenizer gpt-tokenizer/modelsからのmodelsエクスポートを通じて、すべてのOpenAIモデルに関する包括的なデータを提供します。これには、コンテキストウィンドウ、コスト、トレーニングデータのカットオフ、および非推奨のステータスに関する詳細情報が含まれます。
データは、Openaiの公式文書に一致するように定期的に維持されています。このデータを最新の状態に保つための貢献は大歓迎です - 不一致に気付いたり、更新がある場合は、PRを自由に開いてください。
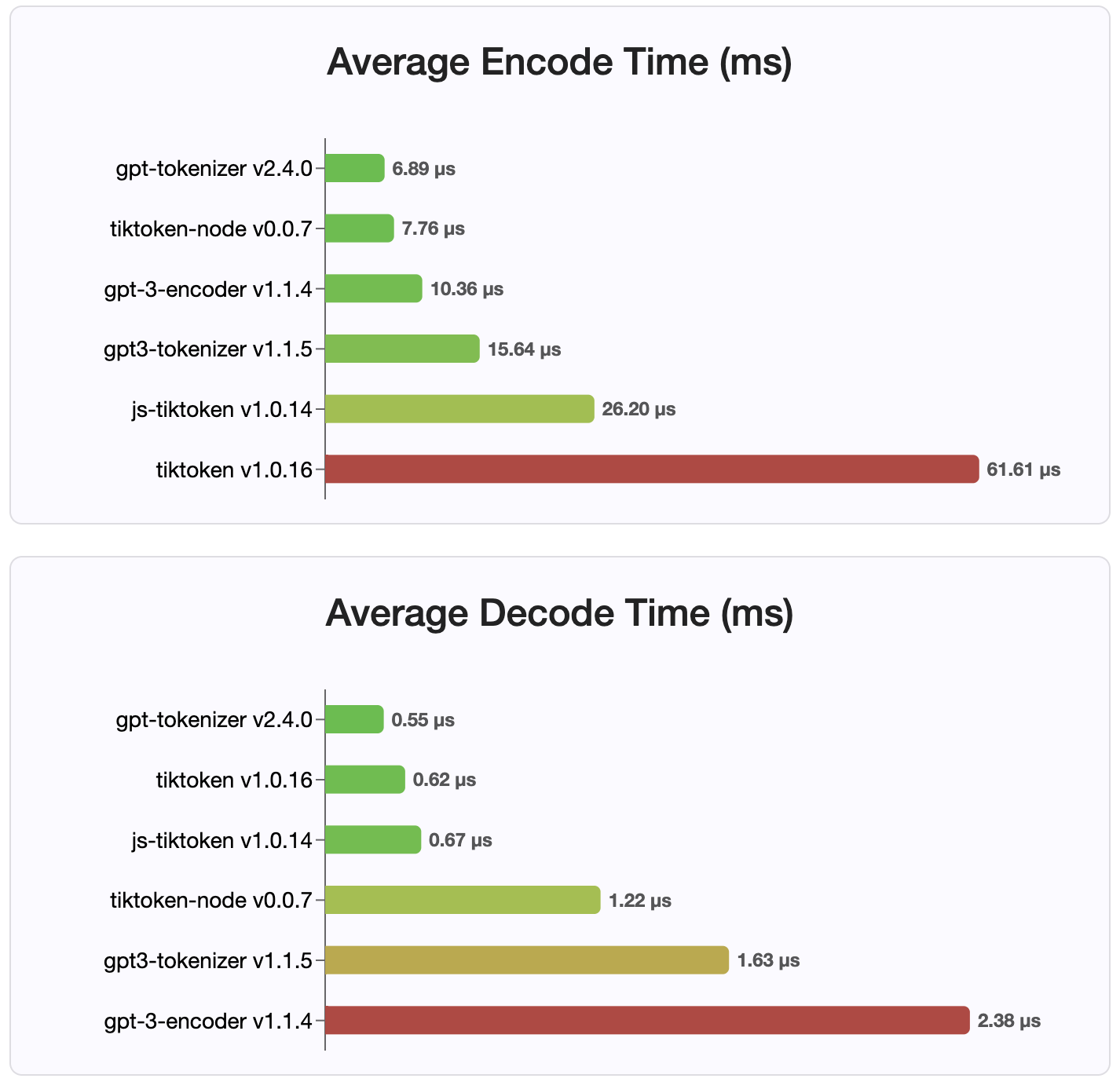
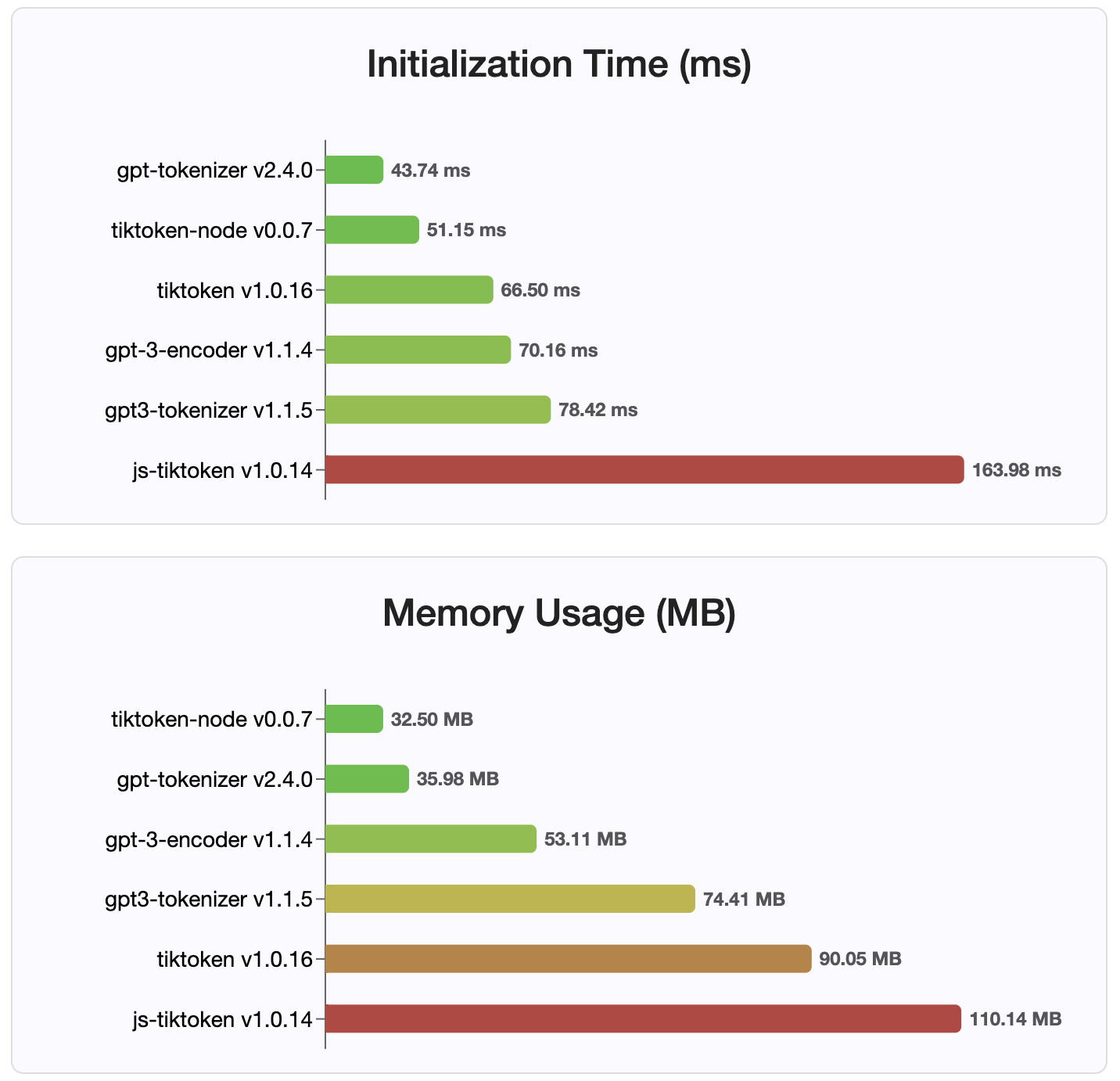
バージョン2.4.0以降、 gpt-tokenizer NPMで利用可能な最速のトークネザーの実装です。利用可能なWASM/ノードバインディングの実装よりもさらに高速です。エンコード、デコード時間、小さなメモリフットプリントが最も速いです。また、他のすべての実装よりも速く初期化されます。
エンコーディング自体は、保存されているコンパクトな形式のため、サイズが最小です。
mit
貢献は大歓迎です!プルリクエストまたは問題を開いてバグレポートについて話し合うか、アイデアやその他の問い合わせのためにディスカッション機能を使用してください。
@dmitry-BrazhenkoのSharptokenに感謝します。そのコードは、ポートのリファレンスとして提供されました。
gpt-tokenizerがプロジェクトで役立つと思うことを願っています!


