gpt tokenizer
2.7.0
gpt-tokenizer представляет собой энкодер/декодер для пары токенов/декодер, поддерживающий все модели OpenAI (включая GPT-3.5, GPT-4, GPT-4O и O1). Это самый быстрый, самый маленький и самый низкий токенизатор GPT GPT, доступный для всех средах JavaScript. Это написано в TypeScript.
Этой библиотеке доверяли:
Пожалуйста, рассмотрим? спонсировать проект, если вы найдете его полезным.
По состоянию на 2023 год это самый функциональный токенизатор GPT с открытым исходным кодом на NPM. Этот пакет является портом Tiktoken's, с некоторыми дополнительными, уникальными функциями, посыпанными сверху:
encodeChatr50k_base , p50k_base , p50k_edit , cl100k_base и o200k_base )decodeAsyncGenerator и decodeGenerator с любым итерабильным входом)isWithinTokenLimit для оценки предела токена без кодирования всего текста/чатаnpm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >Если вы хотите использовать пользовательское кодирование, принесите соответствующий сценарий.
gpt-4o и o1 )gpt-4-* и gpt-3.5-turbo ) Глобальное название - это объединение: GPTTokenizer_${encoding} .
Обратитесь к поддерживаемым моделям и разделу их кодировки для получения дополнительной информации.
Игровая площадка опубликована под запоминающимся URL: https://gpt-tokenizer.dev/
Вы можете играть с пакетом в браузере, используя игровую площадку CodeSandbox.
Игровая площадка имитирует официальный токенизатор Openai.
Библиотека предоставляет различные функции для преобразования текста в (и из) последовательности целых чисел (токенов), которые могут быть поданы в модель LLM. Преобразование осуществляется с использованием алгоритма кодирования пары байтов (BPE), используемого OpenAI.
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} По умолчанию импорт из gpt-tokenizer использует кодирование cl100k_base , используемое gpt-3.5-turbo и gpt-4 .
Чтобы получить токенизатор для другой модели, импортируйте напрямую, например:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' Если вы имеете дело с разрешением, который не поддерживает разрешение exports Package.json, вам может потребоваться импортировать из соответствующего каталога cjs или esm , например:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' Если вы не против загружать токенизатор асинхронно, вы можете использовать динамический импорт внутри вашей функции, например, так:
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) Если ваша модель не поддерживается пакетом, но вы знаете, какой кодирование BPE он использует, вы можете загрузить кодирование напрямую, например:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) ПРИМЕЧАНИЕ. Если вы используете gpt-3.5-* или gpt-4-* и не видите модель, которую вы ищете, используйте кодирование cl100k_base напрямую.
encode(text: string): number[]Кодирует заданный текст в последовательность токенов. Используйте этот метод, когда вам нужно преобразовать кусок текста в формат токена, который могут обрабатывать модели GPT.
Пример:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringДекодирует последовательность токенов обратно в текст. Используйте этот метод, когда вы хотите преобразовать выходные токены из моделей GPT обратно в читаемый на человеке текст.
Пример:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number Проверяет, находится ли текст в пределах токена. Возвращает false если предел превышен, в противном случае возвращает количество токенов. Используйте этот метод, чтобы быстро проверить, находится ли заданный текст в пределах токена, налагаемым моделями GPT, без кодирования всего текста.
Пример:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): numberПодсчитывает количество токенов в входном тексте или в чате. Используйте этот метод, когда вам нужно определить количество токенов, не проверяя предел.
Пример:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]Кодирует данное чат в последовательность токенов.
Если вы не импортировали модельную версию напрямую, или если model не была предоставлена во время инициализации, она должна быть предоставлена здесь, чтобы правильно ориентироваться в чате для данной модели. Используйте этот метод, когда вам нужно преобразовать чат в формат токена, который могут обрабатывать модели GPT.
Пример:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )Обратите внимание, что если вы кодируете пустой чат, он все равно будет содержать минимальное количество специальных токенов.
encodeGenerator(text: string): Generator<number[], void, undefined>Кодирует заданный текст, используя генератор, давая куски токенов. Используйте этот метод, когда вы хотите кодировать текст в куски, что может быть полезно для обработки больших текстов или потоковых данных.
Пример:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> То же, что и encodeChat , но использует генератор в качестве вывода и может использовать любой итератор в качестве входного chat .
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>Декодирует последовательность токенов с помощью генератора, давая куски декодированного текста. Используйте этот метод, когда вы хотите декодировать токены в кусочках, которые могут быть полезны для обработки больших выходов или потоковых данных.
Пример:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>Декодирует последовательность токенов, асинхронно используя генератор, давая куски декодированного текста. Используйте этот метод, когда вы хотите декодировать токены в асинхронных кусках, которые могут быть полезны для обработки больших выходов или потоковых данных в асинхронном контексте.
Пример:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} Есть несколько специальных токенов, которые используются моделями GPT. Не все модели поддерживают все эти токены.
gpt-tokenizer позволяет указать пользовательские наборы разрешенных специальных токенов при кодировании текста. Для этого передайте Set , содержащий разрешенные специальные токены в качестве параметра функции encode :
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) Аналогичным образом, вы можете указать пользовательские наборы запрещенных специальных токенов при кодировании текста. Передайте Set , содержащий запрещенные специальные токены в качестве параметра функции encode :
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )В этом примере ошибочна, потому что входной текст содержит запрещенный специальный токен.
gpt-tokenizer включает в себя набор тестовых случаев в файле testPlans.txt, чтобы обеспечить его совместимость с библиотекой Python tiktoken от OpenAI. Эти тестовые примеры подтверждают функциональность и поведение gpt-tokenizer , обеспечивая надежную ссылку для разработчиков.
Запуск модульных тестов и проверка тестовых случаев помогает поддерживать согласованность между библиотекой и оригинальной реализацией Python.
gpt-tokenizer предоставляет всесторонние данные обо всех моделях OpenaI через экспорт models из gpt-tokenizer/models . Это включает в себя подробную информацию о окнах контекста, затратах, отсечке обучающих данных и статусе управления.
Данные регулярно поддерживаются, чтобы соответствовать официальной документации Openai. Взносы для поддержания этих данных приветствуются-если вы заметите какие-либо расхождения или имеют обновления, пожалуйста, не стесняйтесь открывать PR.
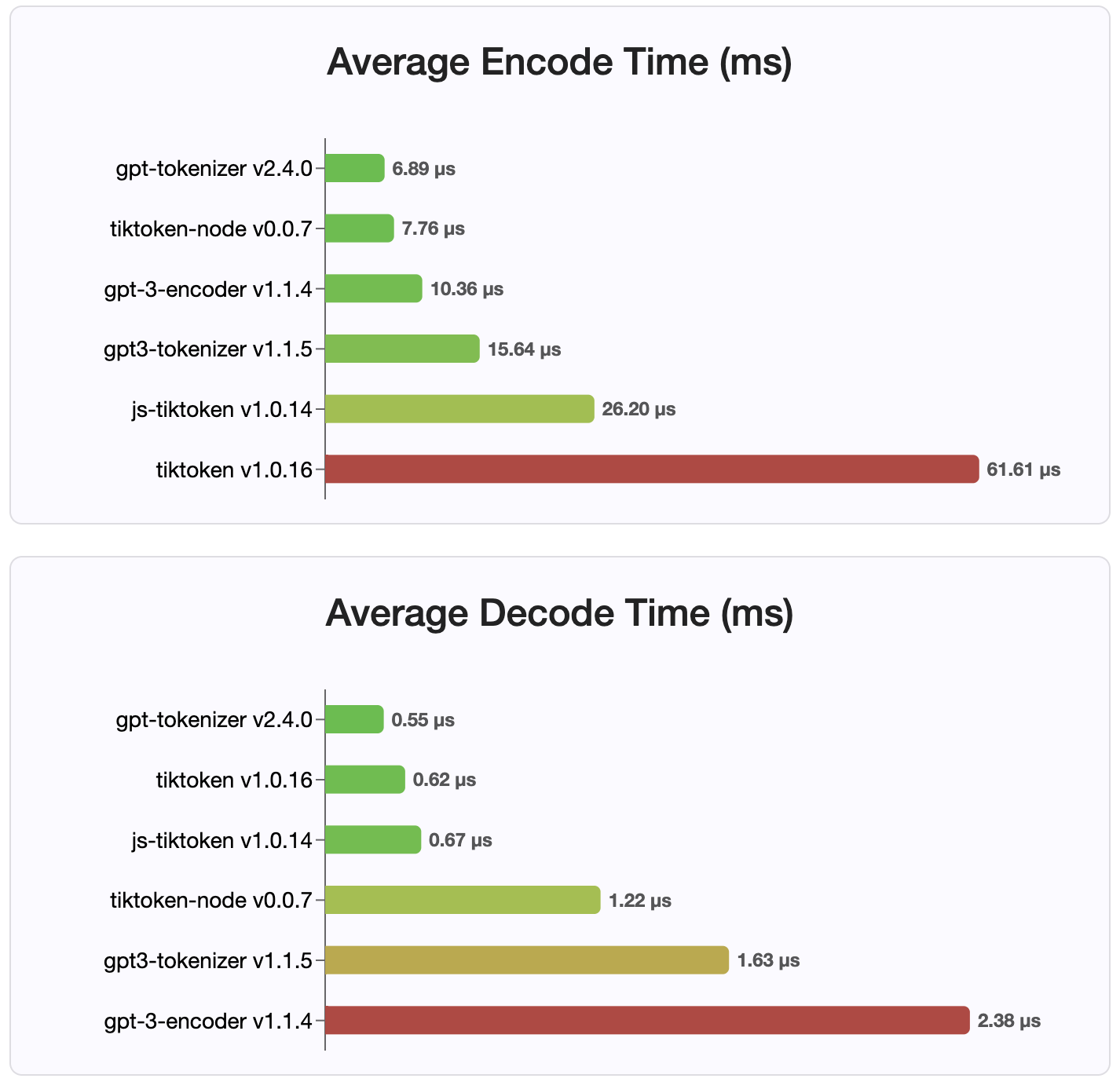
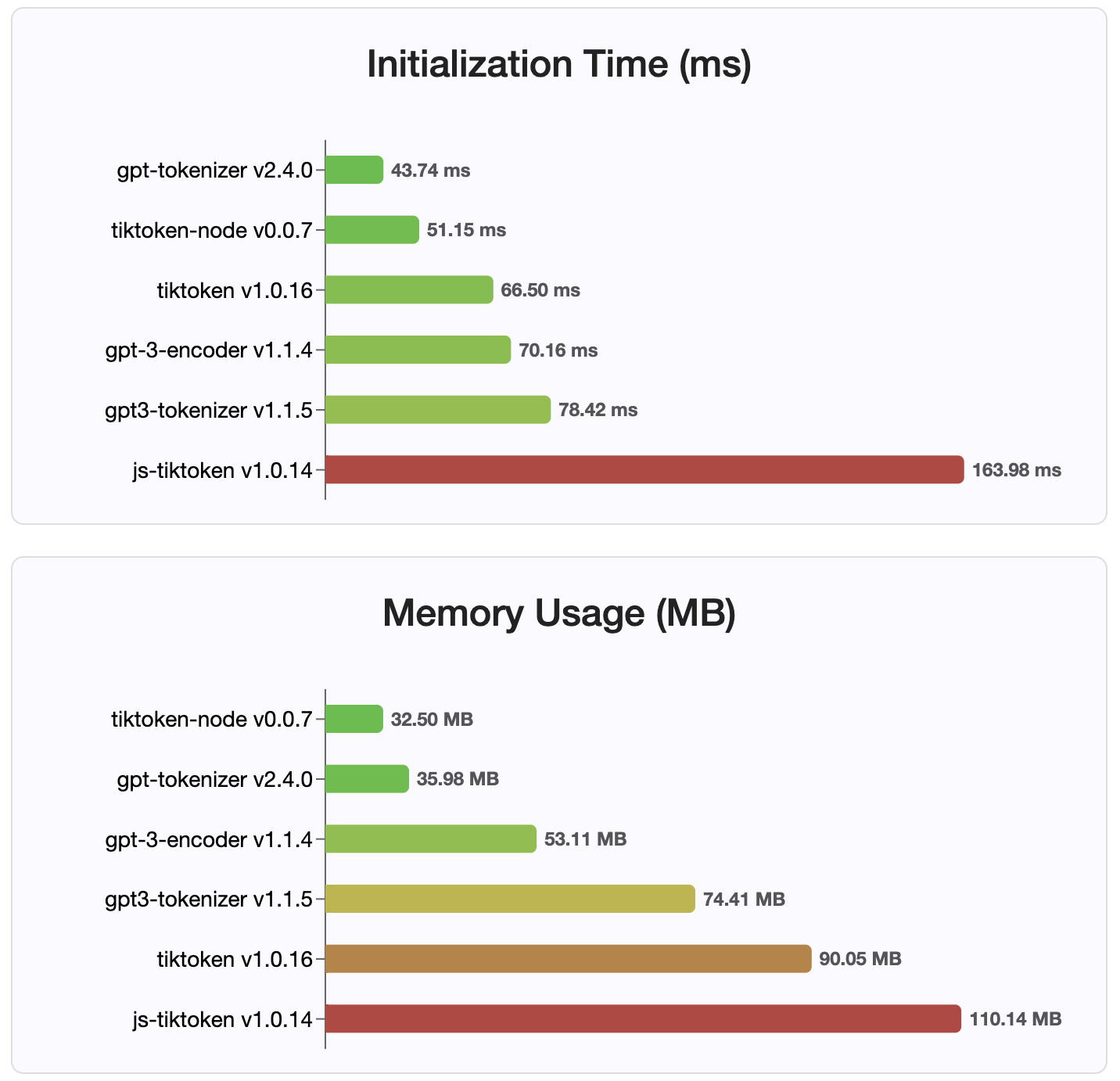
С момента версии 2.4.0 gpt-tokenizer является самой быстрой реализацией токенизатора, доступной на NPM. Это даже быстрее, чем доступные реализации привязки WASM/узла. Он имеет самое быстрое кодирование, время декодирования и крошечный след памяти. Он также инициализируется быстрее, чем все другие реализации.
Сами кодировки также имеют наименьший размер из -за компактного формата, в котором они хранятся.
Грань
Взносы приветствуются! Пожалуйста, откройте запрос на привлечение или проблему для обсуждения ваших отчетов об ошибках или использования функции обсуждений для идей или любых других запросов.
Спасибо @Dmitry-Brazhenko's Sharptoken, код которого был посвящен ссылкой для порта.
Надеюсь, вы найдете gpt-tokenizer полезным в ваших проектах!


