gpt tokenizer
2.7.0
gpt-tokenizer ist ein Token-Byte-Paar-Encoder/Decoder, das alle Modelle von OpenAI unterstützt (einschließlich GPT-3,5, GPT-4, GPT-4O und O1). Es ist der schnellste, kleinste und niedrigste Fußabdruck -GPT -Tokenizer für alle JavaScript -Umgebungen. Es ist in TypeScript geschrieben.
Diese Bibliothek wurde vertraut von:
Bitte bedenken? Sponsorieren Sie das Projekt, wenn Sie es nützlich finden.
Ab 2023 ist es der merkmalsvollste, Open-Source-GPT-Tokenizer auf NPM. Dieses Paket ist ein Hafen von Openai's Tiktoken, mit einigen zusätzlichen, einzigartigen Funktionen, die oben bestreut sind:
encodeChat -Funktionr50k_base , p50k_base , p50k_edit , cl100k_base und o200k_base )decodeAsyncGenerator und decodeGenerator mit jeder iterablen Eingabe)isWithinTokenLimit -Funktion zur Beurteilung der Token -Grenze, ohne den gesamten Text/Chat zu codierennpm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >Wenn Sie eine benutzerdefinierte Codierung verwenden möchten, holen Sie das relevante Skript.
gpt-4o und o1 )gpt-4-* und gpt-3.5-turbo ) Der globale Name ist eine Verkettung: GPTTokenizer_${encoding} .
Weitere Informationen finden Sie in unterstützten Modellen und deren Codings -Abschnitt.
Der Spielplatz wird unter einer unvergesslichen URL veröffentlicht: https://gpt-tekeizer.dev/
Sie können mit dem Paket im Browser mit dem CodesAndbox -Spielplatz spielen.
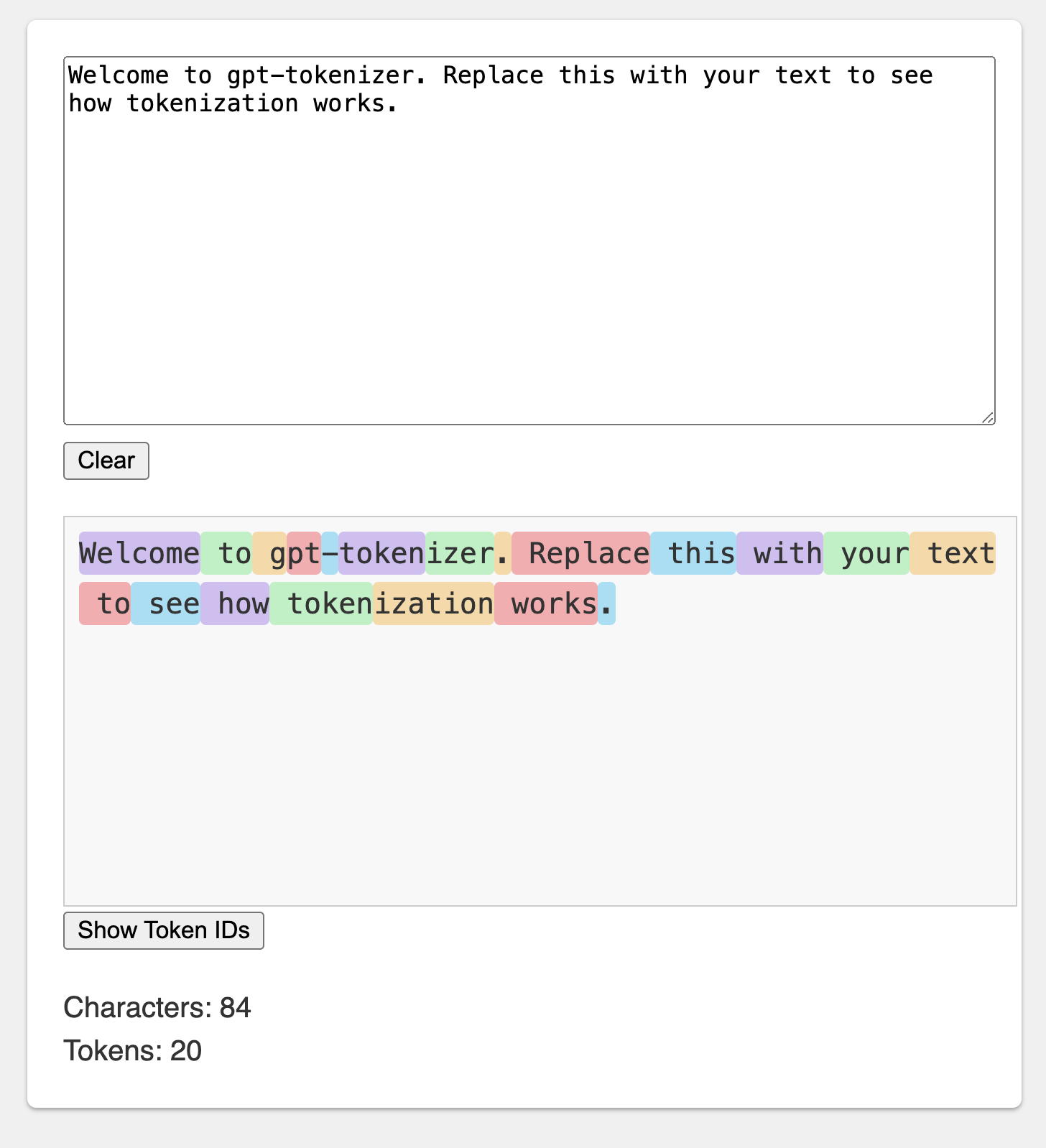
Der Spielplatz ahmt den offiziellen OpenAI -Tokenizer nach.
Die Bibliothek bietet verschiedene Funktionen, um Text in (und) in eine Abfolge von Ganzzahlen (Token) zu verwandeln, die in ein LLM -Modell eingespeist werden können. Die Transformation erfolgt unter Verwendung eines Byte -Paar -Codierungsalgorithmus (BPE), der von OpenAI verwendet wird.
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} Standardmäßig verwendet das Import von gpt-tokenizer cl100k_base -Codierung, die von gpt-3.5-turbo und gpt-4 verwendet wird.
Importieren Sie es beispielsweise direkt: Um einen Tokenizer für ein anderes Modell zu erhalten, importieren Sie es direkt:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' Wenn Sie sich mit einem Resolver befassen, cjs exports Paket nicht esm .
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' Wenn es Ihnen nichts ausmacht, den Tokenizer asynchron zu laden, können Sie einen dynamischen Import in Ihrer Funktion verwenden, wie SO:
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) Wenn Ihr Modell nicht vom Paket unterstützt wird, aber Sie wissen, welche BPE -Codierung es verwendet, können Sie die Codierung direkt laden, z. B.:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) Hinweis: Wenn Sie gpt-3.5-* oder gpt-4-* verwenden und das Modell, das Sie suchen, nicht sehen, verwenden Sie die cl100k_base -Codierung direkt.
encode(text: string): number[]Codiert den gegebenen Text in eine Sequenz von Token. Verwenden Sie diese Methode, wenn Sie ein Textstück in das Token -Format umwandeln müssen, das die GPT -Modelle verarbeiten können.
Beispiel:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringDekodiert eine Abfolge von Token zurück in den Text. Verwenden Sie diese Methode, wenn Sie die Ausgangs-Token aus GPT-Modellen wieder in den menschlich lesbaren Text umwandeln möchten.
Beispiel:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number Überprüft, ob sich der Text innerhalb der Token -Grenze befindet. Gibt false zurück, wenn die Grenze überschritten wird, andernfalls gibt die Anzahl der Token zurück. Verwenden Sie diese Methode, um schnell zu überprüfen, ob sich ein bestimmter Text innerhalb der von GPT -Modellen auferlegten Token -Grenze befindet, ohne den gesamten Text zu codieren.
Beispiel:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): numberZählt die Anzahl der Token im Eingabtext oder im Chat. Verwenden Sie diese Methode, wenn Sie die Anzahl der Token ermitteln müssen, ohne eine Grenze zu überprüfen.
Beispiel:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]Codiert den gegebenen Chat in eine Sequenz von Token.
Wenn Sie die Modellversion nicht direkt importiert haben oder wenn model während der Initialisierung nicht bereitgestellt wurde, muss es hier bereitgestellt werden, um den Chat für ein bestimmtes Modell korrekt zu tokenisieren. Verwenden Sie diese Methode, wenn Sie einen Chat in das Token -Format umwandeln müssen, das die GPT -Modelle verarbeiten können.
Beispiel:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )Beachten Sie, dass wenn Sie einen leeren Chat codieren, es weiterhin die minimale Anzahl spezieller Token enthält.
encodeGenerator(text: string): Generator<number[], void, undefined>Codiert den angegebenen Text mit einem Generator, wodurch Tokenbrocken erbracht werden. Verwenden Sie diese Methode, wenn Sie Text in Stücken codieren möchten, die für die Verarbeitung großer Texte oder Streamingdaten nützlich sein können.
Beispiel:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> Wie encodeChat , verwendet aber einen Generator als Ausgabe und kann jeden Iterator als chat verwenden.
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>Dekodiert eine Sequenz von Token mit einem Generator, wodurch ein dekodiertes Textbrocken erfolgt. Verwenden Sie diese Methode, wenn Sie Token in Stücken dekodieren möchten, was für die Verarbeitung großer Ausgänge oder Streaming -Daten nützlich sein kann.
Beispiel:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>Dekodiert eine Sequenz von Token asynchron mit einem Generator, wodurch Stücke von dekodiertem Text erbracht wird. Verwenden Sie diese Methode, wenn Sie die Token asynchron in Stücken dekodieren möchten, was für die Verarbeitung großer Ausgänge oder Streamingdaten in einem asynchronen Kontext nützlich sein kann.
Beispiel:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} Es gibt einige spezielle Token, die von den GPT -Modellen verwendet werden. Nicht alle Modelle unterstützen all diese Token.
gpt-tokenizer können Sie benutzerdefinierte Sätze von zulässigen speziellen Token beim Codierungstext angeben. Übergeben Sie dazu einen Set , der die zulässigen Spezialzusken als Parameter an die encode -Funktion enthält:
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) In ähnlicher Weise können Sie benutzerdefinierte Sätze von nicht zugelassenen speziellen Token bei Codierung von Text angeben. Übergeben Sie einen Set , der die nicht zugelassenen Special -Token als Parameter an die encode -Funktion enthält:
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )In diesem Beispiel wird ein Fehler geworfen, da der Eingangstext ein nicht zugelassenes spezielles Token enthält.
gpt-tokenizer enthält eine Reihe von Testfällen in der Datei testplans.txt, um seine Kompatibilität mit der Python tiktoken -Bibliothek von OpenAI sicherzustellen. Diese Testfälle validieren die Funktionalität und das Verhalten von gpt-tokenizer und bieten eine zuverlässige Referenz für Entwickler.
Das Ausführen der Unit -Tests und die Überprüfung der Testfälle hilft dabei, die Konsistenz zwischen der Bibliothek und der ursprünglichen Python -Implementierung aufrechtzuerhalten.
gpt-tokenizer liefert umfassende Daten zu allen OpenAI-Modellen durch die models , die von gpt-tokenizer/models exportiert werden. Dies umfasst detaillierte Informationen zu Kontextfenstern, Kosten, Schulungsdatenausschnitten und Abschaltstatus.
Die Daten werden regelmäßig so gehalten, dass sie die offizielle Dokumentation von OpenAI entspricht. Beiträge, um diese Daten auf dem neuesten Stand zu halten, sind willkommen. Wenn Sie Unstimmigkeiten oder Aktualisierungen aufweisen, können Sie bitte eine PR eröffnen.
Seit Version 2.4.0 ist gpt-tokenizer die schnellste Tokenizer-Implementierung, die auf NPM verfügbar ist. Es ist noch schneller als die verfügbaren Implementierungen von WASM/Knotenbindung. Es hat die schnellste Codierung, Dekodierzeit und einen winzigen Speicherpfunddruck. Es initialisiert auch schneller als alle anderen Implementierungen.
Die Codierungen selbst sind aufgrund des kompakten Formats, in dem sie gespeichert sind, auch die kleinste Größe.
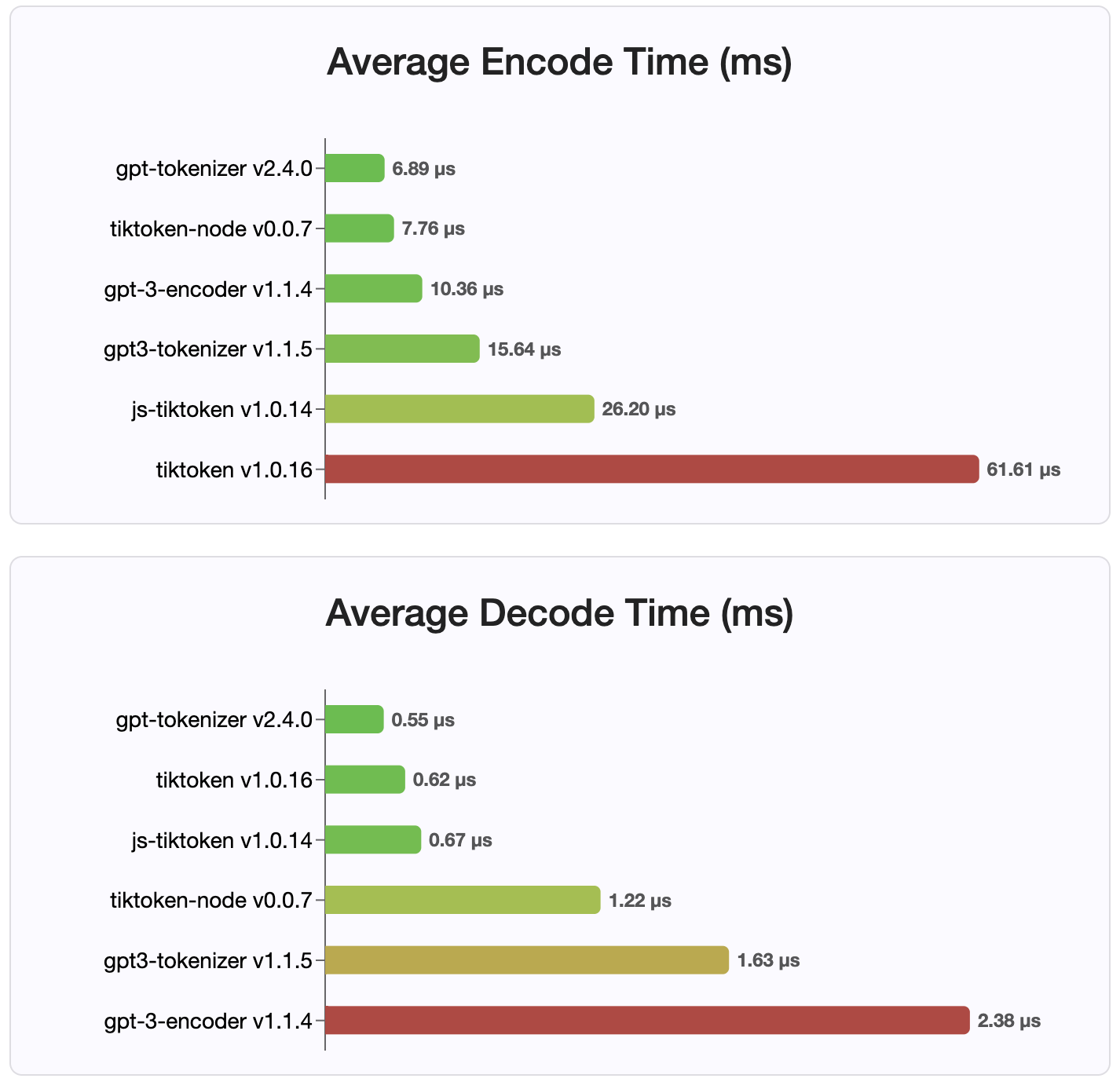
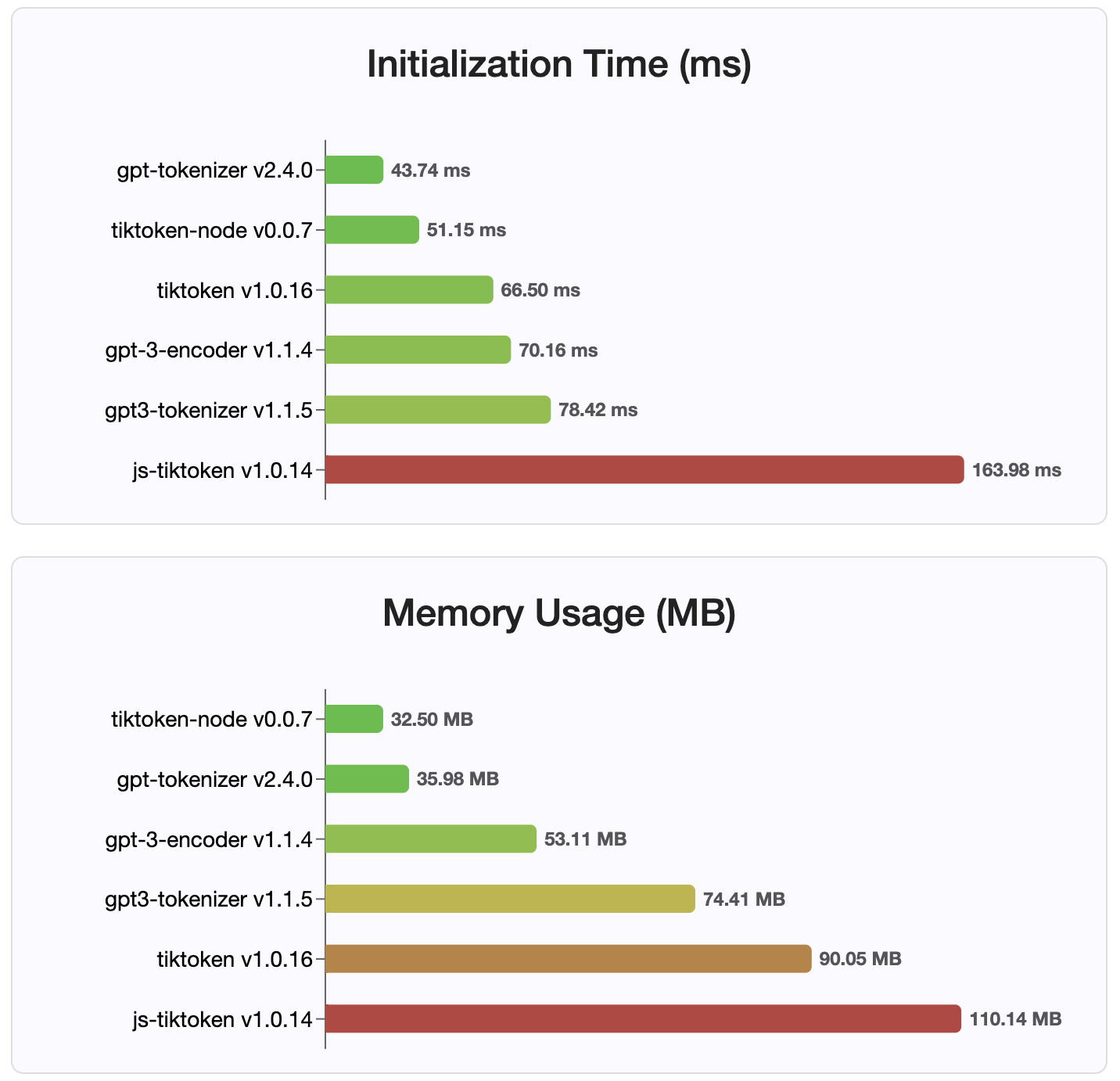
MIT
Beiträge sind willkommen! Bitte öffnen Sie eine Pull -Anfrage oder ein Problem, um Ihre Fehlerberichte zu besprechen, oder verwenden Sie die Diskussionsfunktion für Ideen oder andere Anfragen.
Vielen Dank an @Dmitry-Brazhenko's Sharptoken, dessen Code als Referenz für den Port zugestellt wurde.
Ich hoffe, Sie finden den gpt-tokenizer in Ihren Projekten nützlich!


