gpt tokenizer
2.7.0
gpt-tokenizer es un codificador/decodificador de par de bytes token que admite todos los modelos de OpenAI (incluidos GPT-3.5, GPT-4, GPT-4O y O1). Es el tokenizador GPT de huella más rápido, más pequeño y más bajo disponible para todos los entornos de JavaScript. Está escrito en TypeScript.
Esta biblioteca ha sido confiada por:
Por favor considere? patrocinando el proyecto si lo encuentra útil.
A partir de 2023, es el tokenizador GPT de código abierto más completado y de código abierto en NPM. Este paquete es un puerto de Tiktoken de OpenAI, con algunas características adicionales y únicas esparcidas en la parte superior:
encodeChatr50k_base , p50k_base , p50k_edit , cl100k_base y o200k_base )decodeAsyncGenerator y decodeGenerator con cualquier entrada iterable)isWithinTokenLimit de alto rendimiento para evaluar el límite del token sin codificar todo el texto/chat.npm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >Si desea utilizar una codificación personalizada, obtenga el script relevante.
gpt-4o y o1 )gpt-4-* y gpt-3.5-turbo ) El nombre global es una concatenación: GPTTokenizer_${encoding} .
Consulte los modelos compatibles y su sección de codificaciones para obtener más información.
El patio de recreo se publica bajo una URL memorable: https://gpt-tokenizer.dev/
Puedes jugar con el paquete en el navegador usando el patio de juegos Codesandbox.
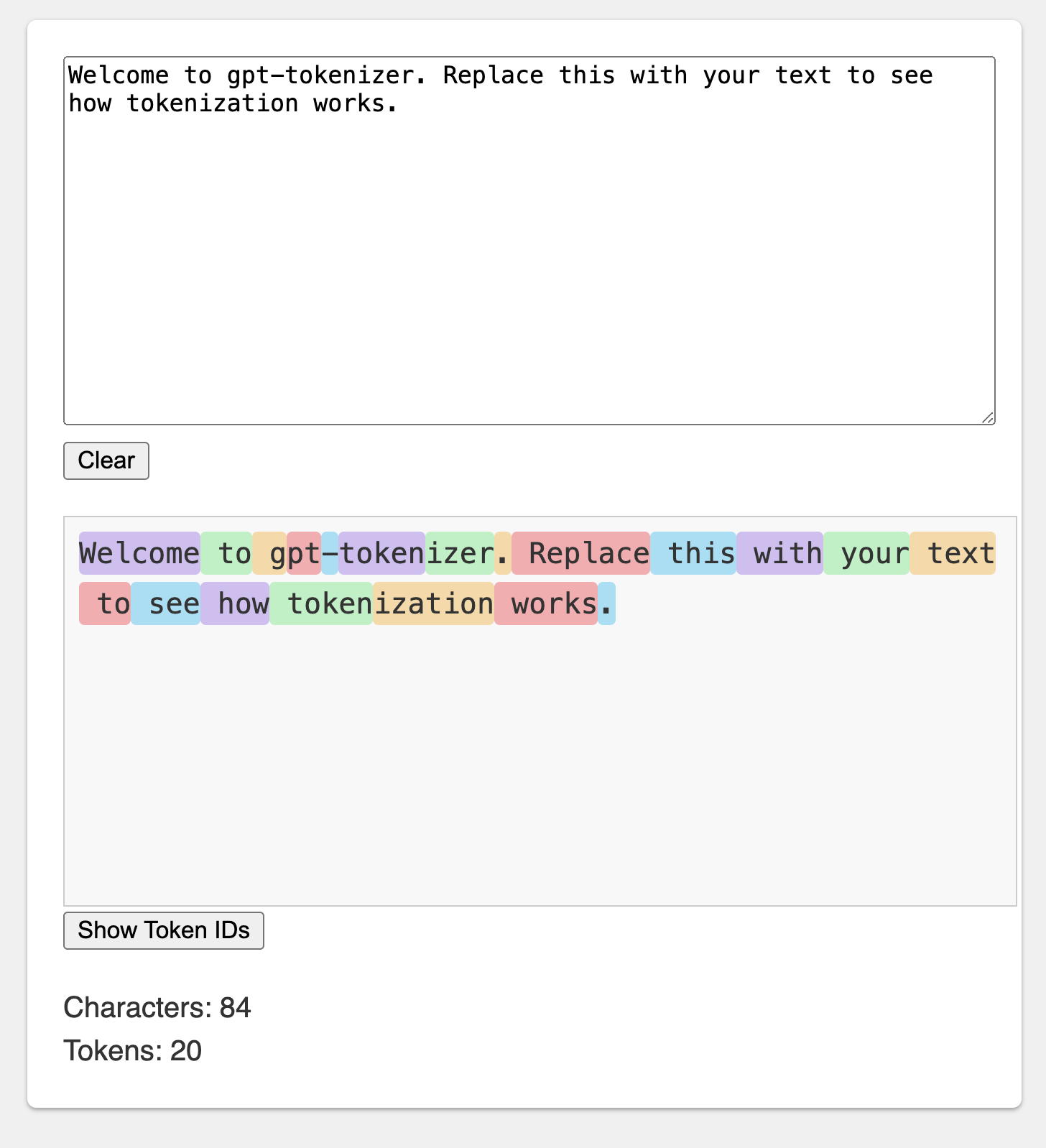
El patio de recreo imita el tokenizer oficial de OpenAi.
La biblioteca proporciona varias funciones para transformar el texto en (y de) una secuencia de enteros (tokens) que se pueden alimentar en un modelo LLM. La transformación se realiza utilizando un algoritmo de codificación de pares de bytes (BPE) utilizado por OpenAI.
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} Por defecto, la importación de gpt-tokenizer utiliza la codificación cl100k_base , utilizada por gpt-3.5-turbo y gpt-4 .
Para obtener un tokenizador para un modelo diferente, importárelo directamente, por ejemplo:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' Si está tratando con un resolución que no admite la resolución exports de paquete. Json, es posible que deba importar desde el directorio cjs o esm respectivo, por ejemplo, por ejemplo:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' Si no le importa cargar el tokenizer asincrónicamente, puede usar una importación dinámica dentro de su función, así:
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) Si su modelo no es compatible con el paquete, pero sabe qué codificación de BPE utiliza, puede cargar la codificación directamente, por ejemplo:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) Nota: Si está utilizando gpt-3.5-* o gpt-4-* y no ve el modelo que está buscando, use la codificación cl100k_base directamente.
encode(text: string): number[]Codifica el texto dado en una secuencia de tokens. Use este método cuando necesite transformar una pieza de texto en el formato de token que los modelos GPT pueden procesar.
Ejemplo:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringDecodifica una secuencia de tokens nuevamente en el texto. Use este método cuando desee convertir los tokens de salida de los modelos GPT nuevamente en texto legible por humanos.
Ejemplo:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number Comprueba si el texto está dentro del límite de token. Devuelve false si se excede el límite, de lo contrario devuelve el número de tokens. Use este método para verificar rápidamente si un texto dado está dentro del límite de token impuesto por los modelos GPT, sin codificar todo el texto.
Ejemplo:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): numberCuenta el número de tokens en el texto o el chat de entrada. Use este método cuando necesite determinar el número de tokens sin verificar contra un límite.
Ejemplo:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]Codifica el chat dado en una secuencia de tokens.
Si no importó la versión del modelo directamente, o si model no se proporcionó durante la inicialización, se debe proporcionar aquí para agitar correctamente el chat para un modelo determinado. Use este método cuando necesite transformar un chat en el formato de token que los modelos GPT pueden procesar.
Ejemplo:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )Tenga en cuenta que si codifica un chat vacío, aún contendrá el número mínimo de tokens especiales.
encodeGenerator(text: string): Generator<number[], void, undefined>Codifica el texto dado usando un generador, produciendo trozos de tokens. Use este método cuando desee codificar texto en fragmentos, lo que puede ser útil para procesar textos grandes o transmisión de datos.
Ejemplo:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> Igual que encodeChat , pero usa un generador como salida, y puede usar cualquier iterador como chat de entrada.
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>Decodifica una secuencia de tokens usando un generador, produciendo trozos de texto decodificado. Use este método cuando desee decodificar tokens en fragmentos, lo que puede ser útil para procesar grandes salidas o datos de transmisión.
Ejemplo:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>Decodifica una secuencia de tokens asincrónicamente usando un generador, produciendo trozos de texto decodificado. Use este método cuando desee decodificar tokens en fragmentos de forma asincrónica, lo que puede ser útil para procesar grandes salidas o transmitir datos en un contexto asincrónico.
Ejemplo:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} Hay algunos tokens especiales utilizados por los modelos GPT. No todos los modelos admiten todos estos tokens.
gpt-tokenizer le permite especificar conjuntos personalizados de tokens especiales permitidos al codificar texto. Para hacer esto, pase un Set que contenga los tokens especiales permitidos como parámetro para la función encode :
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) Del mismo modo, puede especificar conjuntos personalizados de tokens especiales no permitidos al codificar el texto. Pase un Set que contiene los tokens especiales no permitidos como parámetro a la función encode :
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )En este ejemplo, se lanza un error, porque el texto de entrada contiene un token especial no permitido.
gpt-tokenizer incluye un conjunto de casos de prueba en el archivo testplans.txt para garantizar su compatibilidad con la biblioteca Python tiktoken de OpenAI. Estos casos de prueba validan la funcionalidad y el comportamiento de gpt-tokenizer , proporcionando una referencia confiable para los desarrolladores.
Ejecutar las pruebas unitarias y verificar los casos de prueba ayuda a mantener la consistencia entre la biblioteca y la implementación original de Python.
gpt-tokenizer proporciona datos completos sobre todos los modelos OpenAI a través de los models exportados de gpt-tokenizer/models . Esto incluye información detallada sobre ventanas de contexto, costos, recortes de datos de capacitación y estado de deprecación.
Los datos se mantienen regularmente para que coincidan con la documentación oficial de OpenAI. Las contribuciones para mantener estos datos actualizados son bienvenidos: si nota alguna discrepancia o tiene actualizaciones, no dude en abrir un PR.
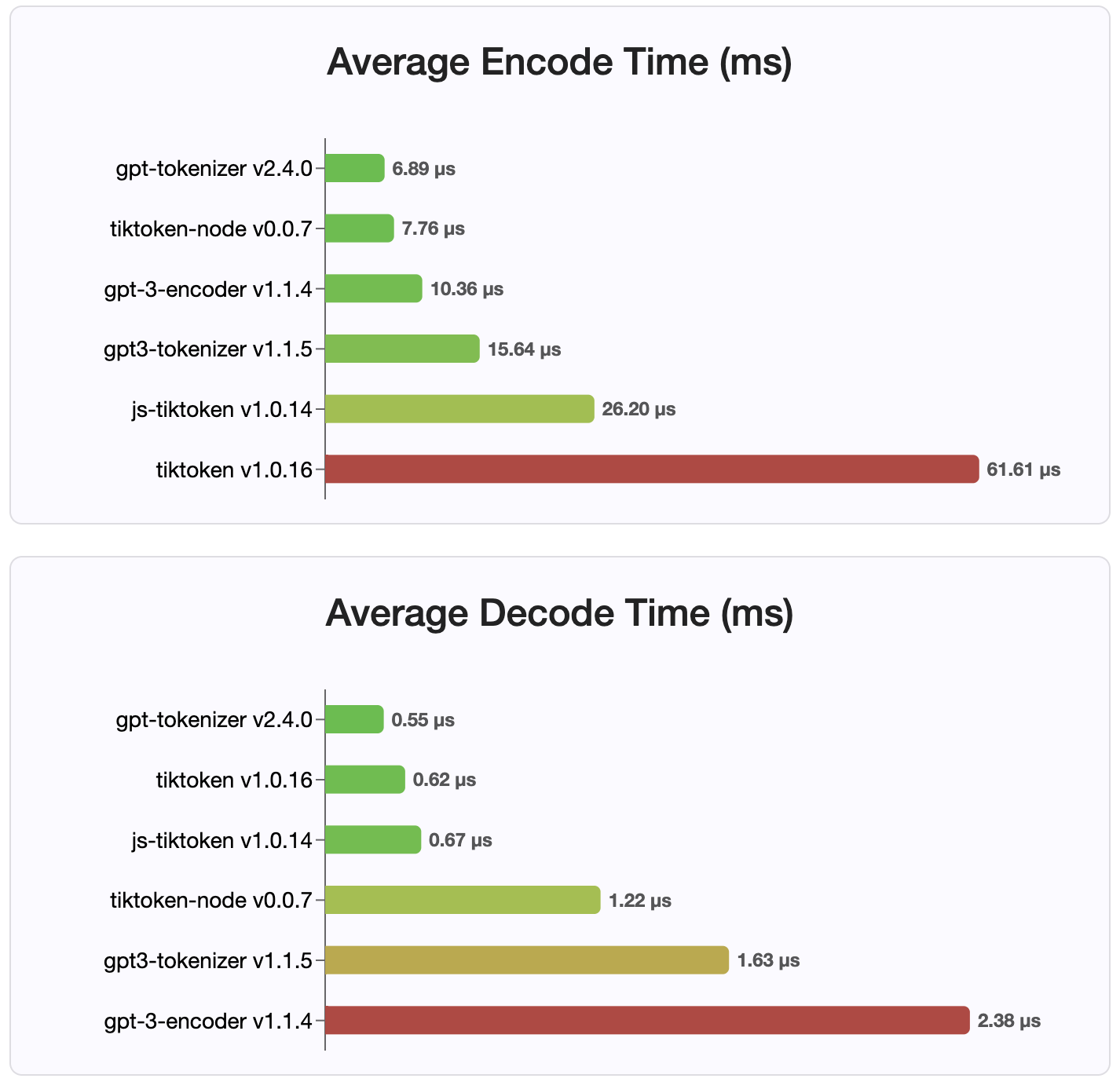
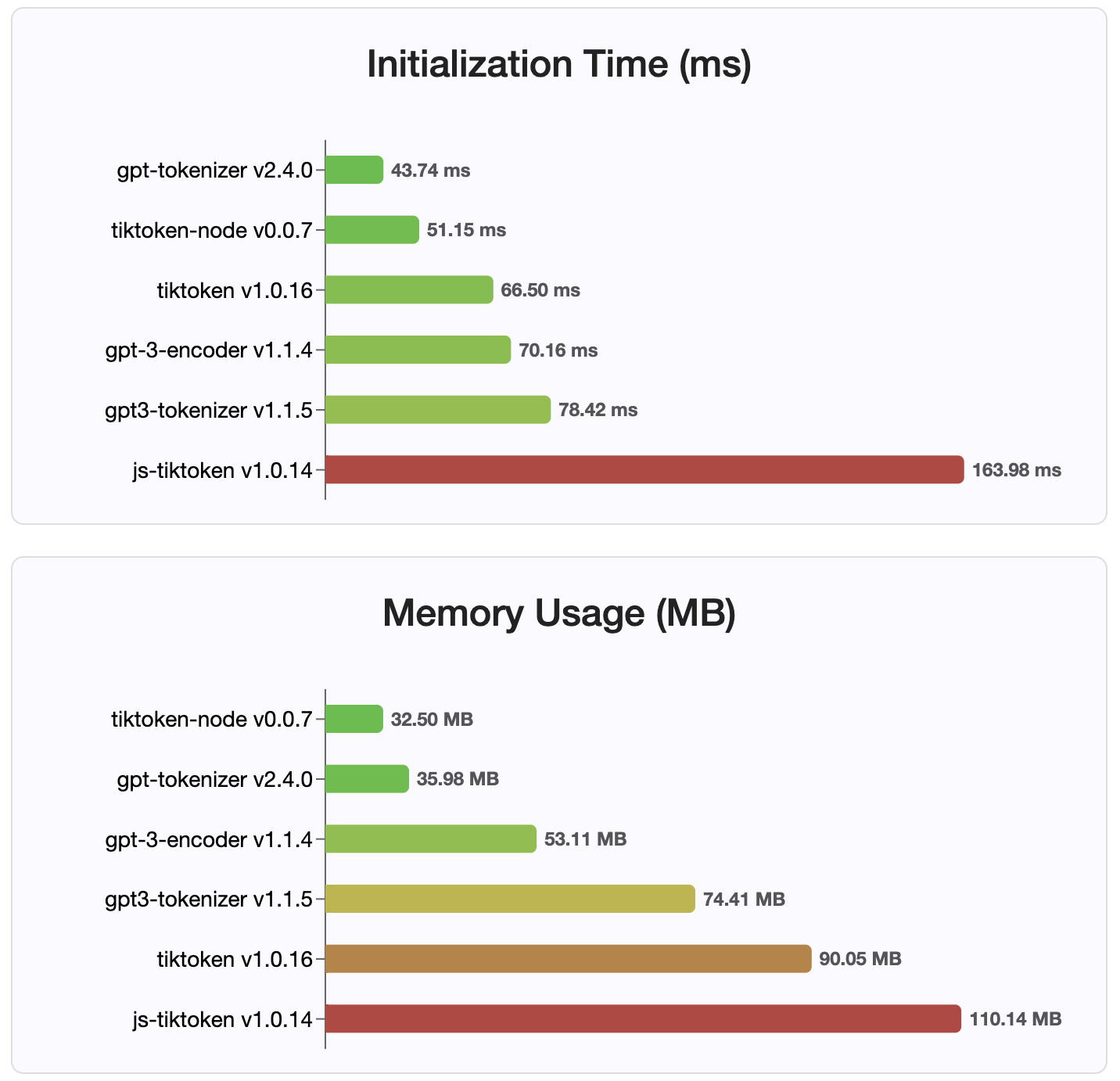
Desde la versión 2.4.0, gpt-tokenizer es la implementación de tokenizador más rápida disponible en NPM. Es aún más rápido que las implementaciones de enlace WASM/Node disponibles. Tiene el tiempo de decodificación de codificación más rápido y una pequeña huella de memoria. También se inicializa más rápido que todas las demás implementaciones.
Las codificaciones en sí también son los de tamaño más pequeño, debido al formato compacto en el que se almacenan.
MIT
¡Las contribuciones son bienvenidas! Abra una solicitud de extracción o un problema para discutir sus informes de errores, o utilice la función de discusión para ideas o cualquier otra consulta.
Gracias a Sharptoken de @Dmitry-Brazhenko, cuyo código se sirvió como referencia para el puerto.
¡Espero que encuentre útil el gpt-tokenizer en sus proyectos!


