gpt tokenizer
2.7.0
gpt-tokenizer 모든 OpenAI 모델 (GPT-3.5, GPT-4, GPT-4O 및 O1 포함)을 지원하는 토큰 바이트 쌍 인코더/디코더입니다. 모든 JavaScript 환경에서 사용할 수있는 가장 빠르고 가장 작고 가장 낮은 발자국 GPT 토큰 화기입니다. TypeScript로 작성되었습니다.
이 라이브러리는 다음과 같이 신뢰했습니다.
제발 고려해야합니까? 유용하다고 생각되면 프로젝트를 후원합니다.
2023 년 현재 NPM에서 가장 기능이 완료되고 오픈 소스 GPT 토큰 화기입니다. 이 패키지는 Openai의 Tiktoken 포트로, 몇 가지 추가로 독특한 기능이 뿌려져 있습니다.
encodeChat 함수 덕분에 쉽게 채팅을 할 수 있도록 지원r50k_base , p50k_base , p50k_edit , cl100k_base 및 o200k_base )decodeAsyncGenerator 사용하고 반복 가능한 입력을 사용하여 decodeGenerator 사용)isWithinTokenLimit 함수를 포함합니다.npm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >사용자 정의 인코딩을 사용하려면 관련 스크립트를 가져 오십시오.
gpt-4o 및 o1 용)gpt-4-* 및 gpt-3.5-turbo ) 글로벌 이름은 연결입니다 : GPTTokenizer_${encoding} .
자세한 내용은 지원되는 모델 및 인코딩 섹션을 참조하십시오.
놀이터는 기억에 남는 URL 아래에 출판됩니다 : https://gpt-tokenizer.dev/
Codesandbox Playground를 사용하여 브라우저에서 패키지로 재생할 수 있습니다.
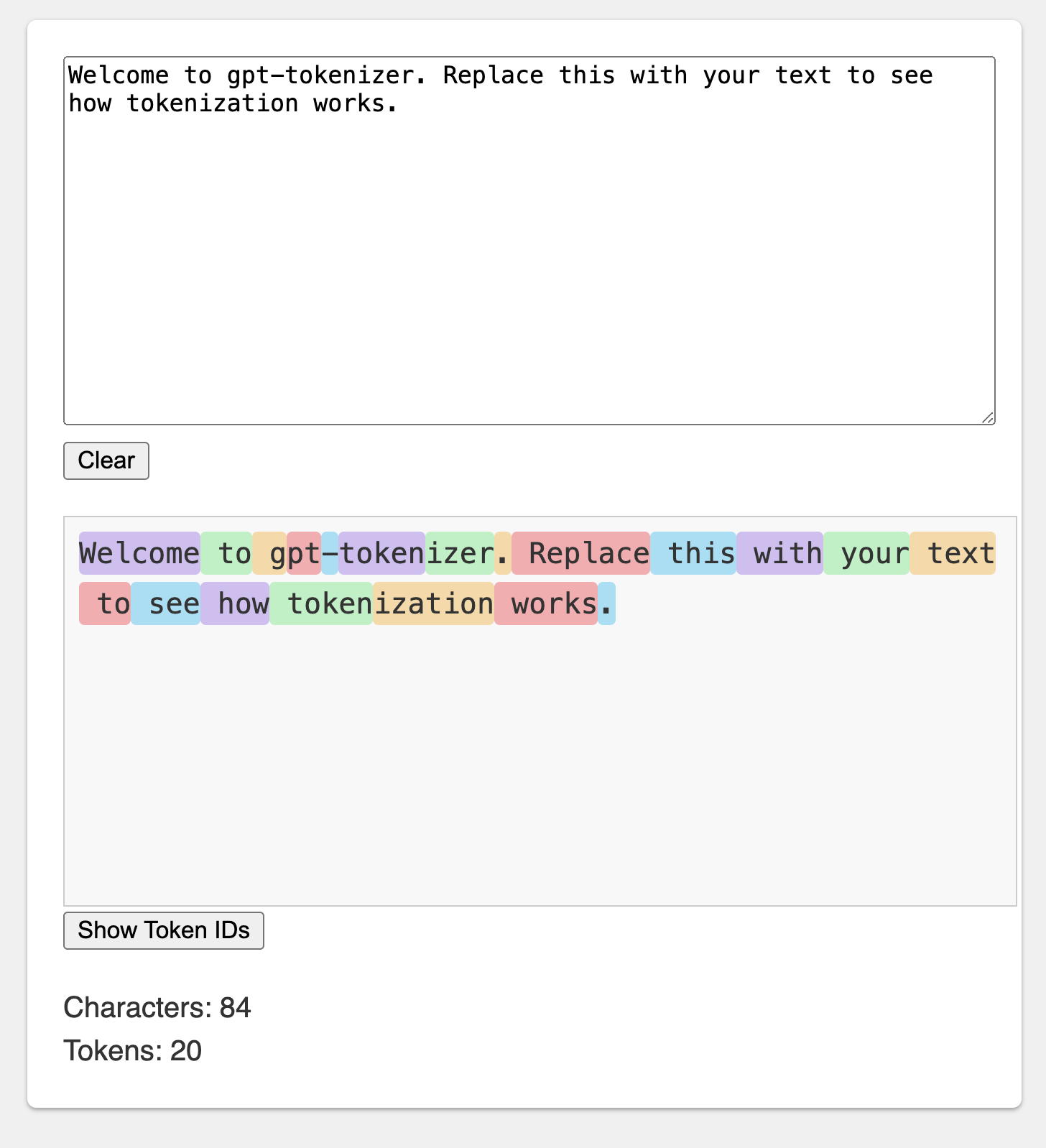
놀이터는 공식 Openai 토큰 화기를 모방합니다.
라이브러리는 텍스트를 LLM 모델로 공급할 수있는 일련의 정수 (토큰)로 텍스트를 변환하는 다양한 기능을 제공합니다. 변환은 OpenAI가 사용하는 BPE (Byte Pair Encoding) 알고리즘을 사용하여 수행됩니다.
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} 기본적으로 gpt-tokenizer 에서 가져 오기에는 gpt-3.5-turbo 및 gpt-4 에서 사용하는 cl100k_base 인코딩을 사용합니다.
다른 모델에 대한 토큰 화기를 얻으려면 다음과 같이 직접 가져옵니다.
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' Package.json exports 해상도를 지원하지 않는 Resolver를 다루는 경우 각 cjs 또는 esm 디렉토리에서 가져와야 할 수도 있습니다.
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' 토큰 화제를 비동기로로드하는 데 마음에 들지 않으면 기능 내에서 동적 가져 오기를 사용할 수 있습니다.
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) 패키지에서 모델이 지원되지 않지만 어떤 BPE 인코딩을 사용하는지 알고 있다면 인코딩을 직접로드 할 수 있습니다.
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) 참고 : gpt-3.5-* 또는 gpt-4-* 사용하고 있고 원하는 모델이 보이지 않는 경우 cl100k_base 인코딩을 직접 사용하십시오.
encode(text: string): number[]주어진 텍스트를 일련의 토큰으로 인코딩합니다. 텍스트를 GPT 모델이 처리 할 수있는 토큰 형식으로 변환해야 할 때이 방법을 사용하십시오.
예:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): string일련의 토큰을 다시 텍스트로 디코딩합니다. GPT 모델에서 출력 토큰을 사람이 읽을 수있는 텍스트로 변환하려는 경우이 방법을 사용하십시오.
예:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number 텍스트가 토큰 한도 내에 있는지 확인합니다. 한계가 초과되면 false 반환하고 그렇지 않으면 토큰 수를 반환합니다. 이 방법을 사용하여 주어진 텍스트가 전체 텍스트를 인코딩하지 않고 GPT 모델이 부과하는 토큰 한계 내에 있는지 빠르게 확인하십시오.
예:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): number입력 텍스트 또는 채팅의 토큰 수를 계산합니다. 한도를 확인하지 않고 토큰 수를 결정해야 할 때이 방법을 사용하십시오.
예:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]주어진 채팅을 일련의 토큰으로 인코딩합니다.
모델 버전을 직접 가져 오지 않았거나 초기화 중에 model 제공되지 않은 경우 주어진 모델에 대한 채팅을 올바르게 토큰 화하려면 여기에 제공되어야합니다. 채팅을 GPT 모델이 처리 할 수있는 토큰 형식으로 변환 해야하는 경우이 메소드를 사용하십시오.
예:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )빈 채팅을 인코딩하는 경우 여전히 최소 수의 특수 토큰 수가 포함됩니다.
encodeGenerator(text: string): Generator<number[], void, undefined>생성기를 사용하여 주어진 텍스트를 인코딩하여 토큰 덩어리를 산출합니다. 텍스트를 청크로 인코딩하려면이 메소드를 사용하십시오. 큰 텍스트 또는 스트리밍 데이터를 처리하는 데 유용 할 수 있습니다.
예:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> encodeChat 과 동일하지만 발전기를 출력으로 사용하고 ITERATOR를 입력 chat 으로 사용할 수 있습니다.
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>발전기를 사용하여 일련의 토큰을 디코딩하여 디코딩 된 텍스트 덩어리를 산출합니다. 청크에서 토큰을 디코딩하려면이 방법을 사용하여 큰 출력 또는 스트리밍 데이터를 처리하는 데 유용 할 수 있습니다.
예:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>발전기를 사용하여 비동기로 비동기로 일련의 토큰을 디코딩하여 디코딩 된 텍스트 덩어리를 산출합니다. 청크에서 토큰을 비동기로 디코딩하려면이 방법을 사용하여 비동기 컨텍스트에서 큰 출력 또는 스트리밍 데이터를 처리하는 데 유용 할 수 있습니다.
예:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} GPT 모델에서 사용하는 특수 토큰이 몇 개 있습니다. 모든 모델이 이러한 모든 토큰을 지원하는 것은 아닙니다.
gpt-tokenizer 사용하면 텍스트를 인코딩 할 때 허용되는 특수 토큰의 사용자 정의 세트를 지정할 수 있습니다. 이렇게하려면 허용 특수 토큰이 포함 된 Set encode 함수에 매개 변수로 전달합니다.
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) 마찬가지로 텍스트를 인코딩 할 때 허용하지 않는 특수 토큰의 사용자 정의 세트를 지정할 수 있습니다. 허용되지 않은 특수 토큰이 포함 된 Set encode 함수의 매개 변수로 전달하십시오.
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )이 예에서는 입력 텍스트에 허용되지 않은 특수 토큰이 포함되어 있기 때문에 오류가 발생합니다.
gpt-tokenizer OpenAI의 Python tiktoken 라이브러리와의 호환성을 보장하기 위해 TestPlans.txt 파일에 일련의 테스트 케이스가 포함되어 있습니다. 이러한 테스트 사례는 gpt-tokenizer 의 기능과 동작을 검증하여 개발자에게 안정적인 참조를 제공합니다.
단위 테스트를 실행하고 테스트 케이스를 확인하면 라이브러리와 원래 Python 구현 간의 일관성을 유지하는 데 도움이됩니다.
gpt-tokenizer gpt-tokenizer/models 의 models 통해 모든 OpenAI 모델에 대한 포괄적 인 데이터를 제공합니다. 여기에는 컨텍스트 창, 비용, 교육 데이터 컷오프 및 감가 상각 상태에 대한 자세한 정보가 포함됩니다.
데이터는 OpenAI의 공식 문서와 일치하도록 정기적으로 유지됩니다. 이 데이터를 최신 상태로 유지하기위한 기여를 환영합니다. 불일치가 없거나 업데이트가 있으면 PR을 열어주십시오.
버전 2.4.0이므로 gpt-tokenizer NPM에서 사용할 수있는 가장 빠른 토큰 화제 구현입니다. 사용 가능한 WASM/노드 바인딩 구현보다 훨씬 빠릅니다. 가장 빠른 인코딩, 디코딩 시간 및 작은 메모리 발자국이 있습니다. 또한 다른 모든 구현보다 빠르게 초기화됩니다.
인코딩 자체는 크기가 가장 작습니다.
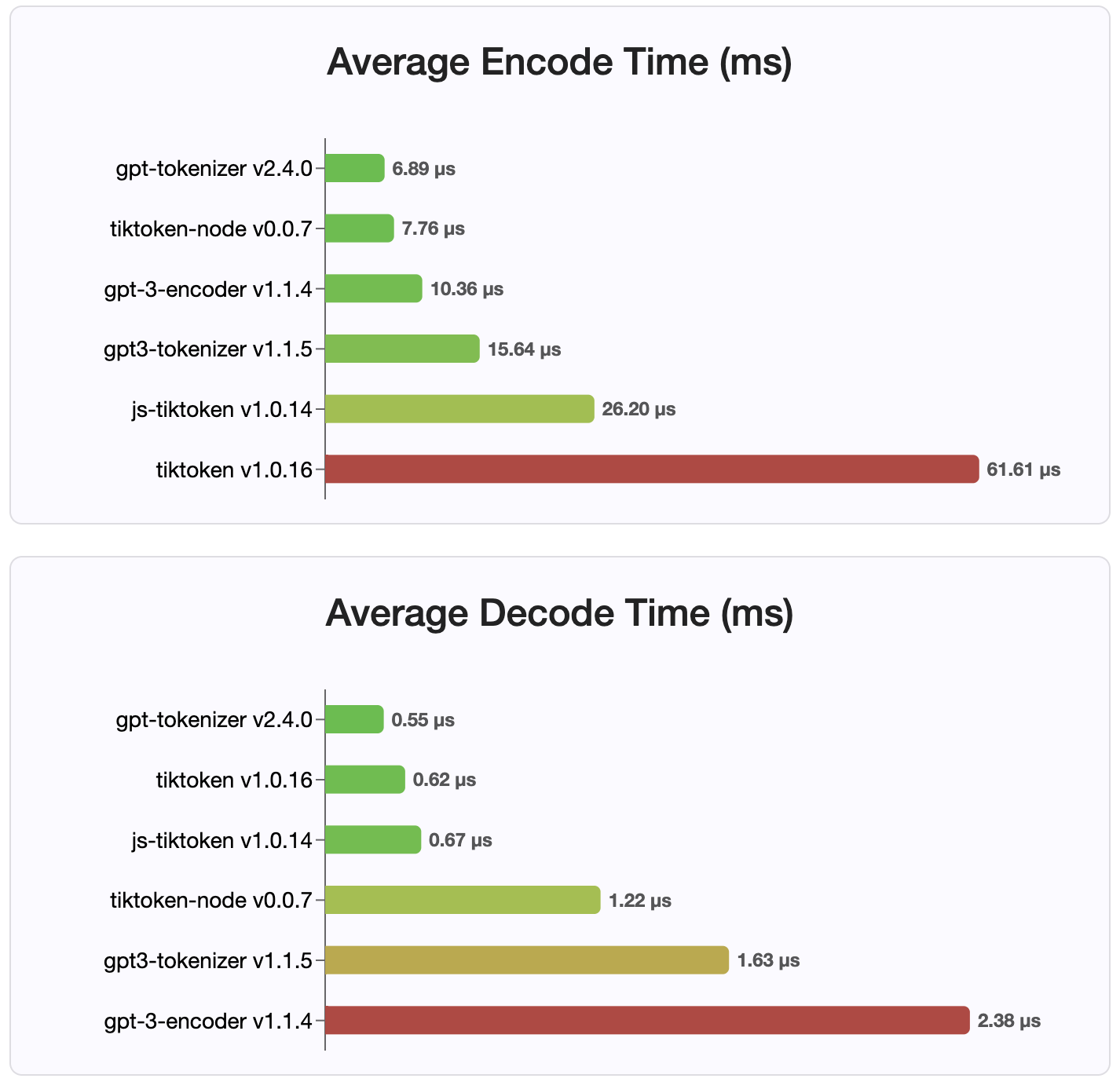
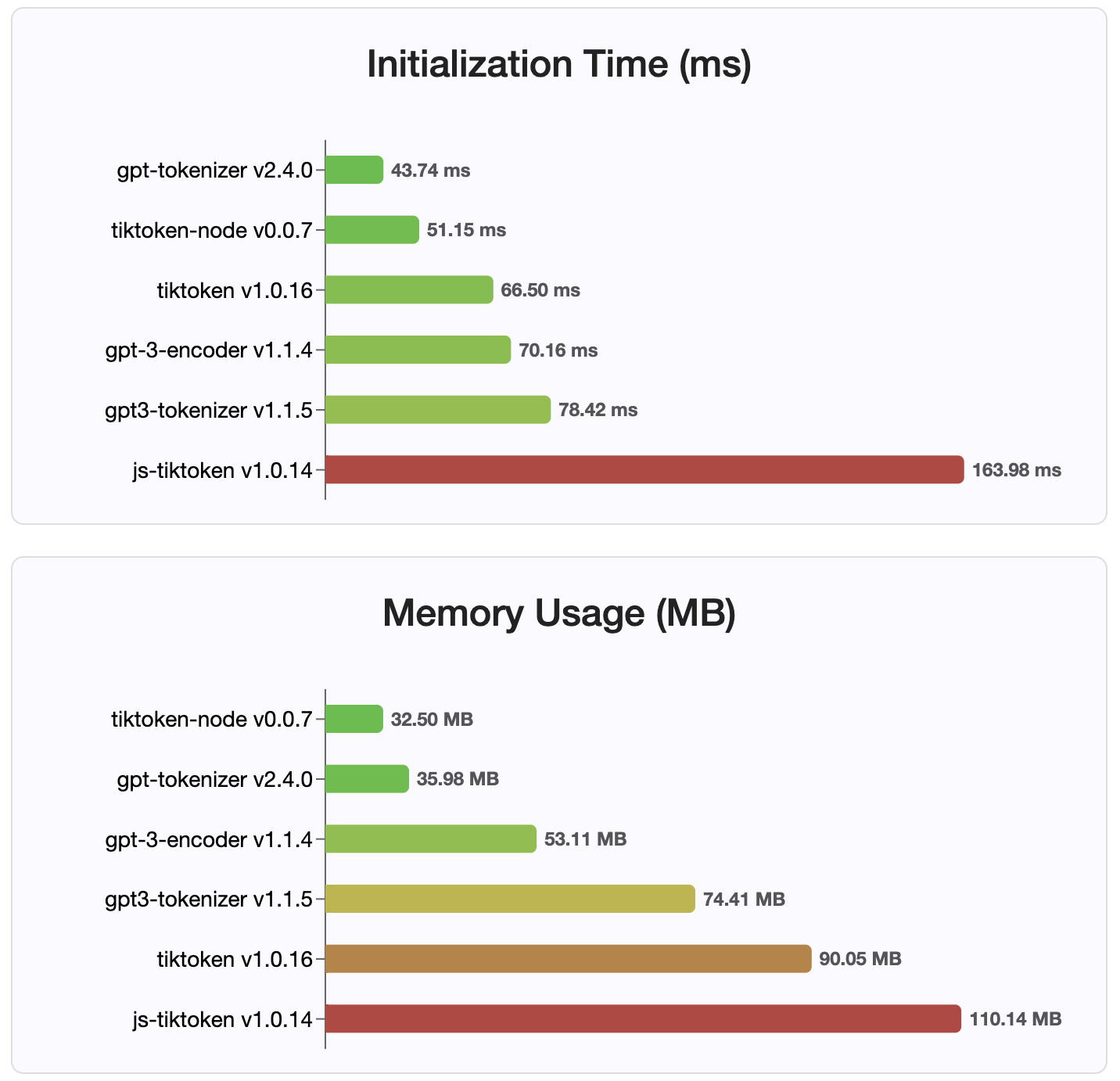
MIT
기부금을 환영합니다! 버그 보고서에 대해 논의하거나 아이디어 또는 기타 문의에 대한 토론 기능을 사용하려면 풀 요청 또는 문제를 열어주십시오.
@Dmitry-Brazhenko의 Sharptoken 덕분에 코드가 포트 참조로 제공되었습니다.
프로젝트에 유용한 gpt-tokenizer 찾기를 바랍니다!


