gpt tokenizer
2.7.0
gpt-tokenizer هو مشفر/وحدة فك ترميز زوج بايت رمز يدعم جميع طرز Openai (بما في ذلك GPT-3.5 و GPT-4 و GPT-4O و O1). إنها الأسرع والأصغر والأدنى البصمة GPT المميز المتاحة لجميع بيئات JavaScript. إنه مكتوب في TypeScript.
هذه المكتبة تم الوثوق بها من قبل:
من فضلك فكر؟ رعاية المشروع إذا وجدت أنه مفيد.
اعتبارًا من عام 2023 ، إنه رمز GPT الأكثر إكمالًا ، مفتوح المصدر على NPM. هذه الحزمة عبارة عن ميناء من Tiktoken من Openai ، مع بعض الميزات الفريدة الإضافية التي يتم رشها في الأعلى:
encodeChatr50k_base ، p50k_base ، p50k_edit ، cl100k_base و o200k_base )decodeAsyncGenerator و decodeGenerator مع أي مدخلات غير قابلة)isWithinTokenLimit ذات الأداء العالي لتقييم حد الرمز المميز دون ترميز النص/الدردشة بأكملهاnpm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >إذا كنت ترغب في استخدام ترميز مخصص ، فأحضر البرنامج النصي ذي الصلة.
gpt-4o و o1 )gpt-4-* و gpt-3.5-turbo ) الاسم العالمي هو تسلسل: GPTTokenizer_${encoding} .
ارجع إلى النماذج المدعومة وقسم الترميزات الخاصة بها لمزيد من المعلومات.
تم نشر الملعب تحت عنوان URL الذي لا يُنسى: https://gpt-tokenizer.dev/
يمكنك اللعب مع الحزمة في المتصفح باستخدام ملعب CodesandBox.
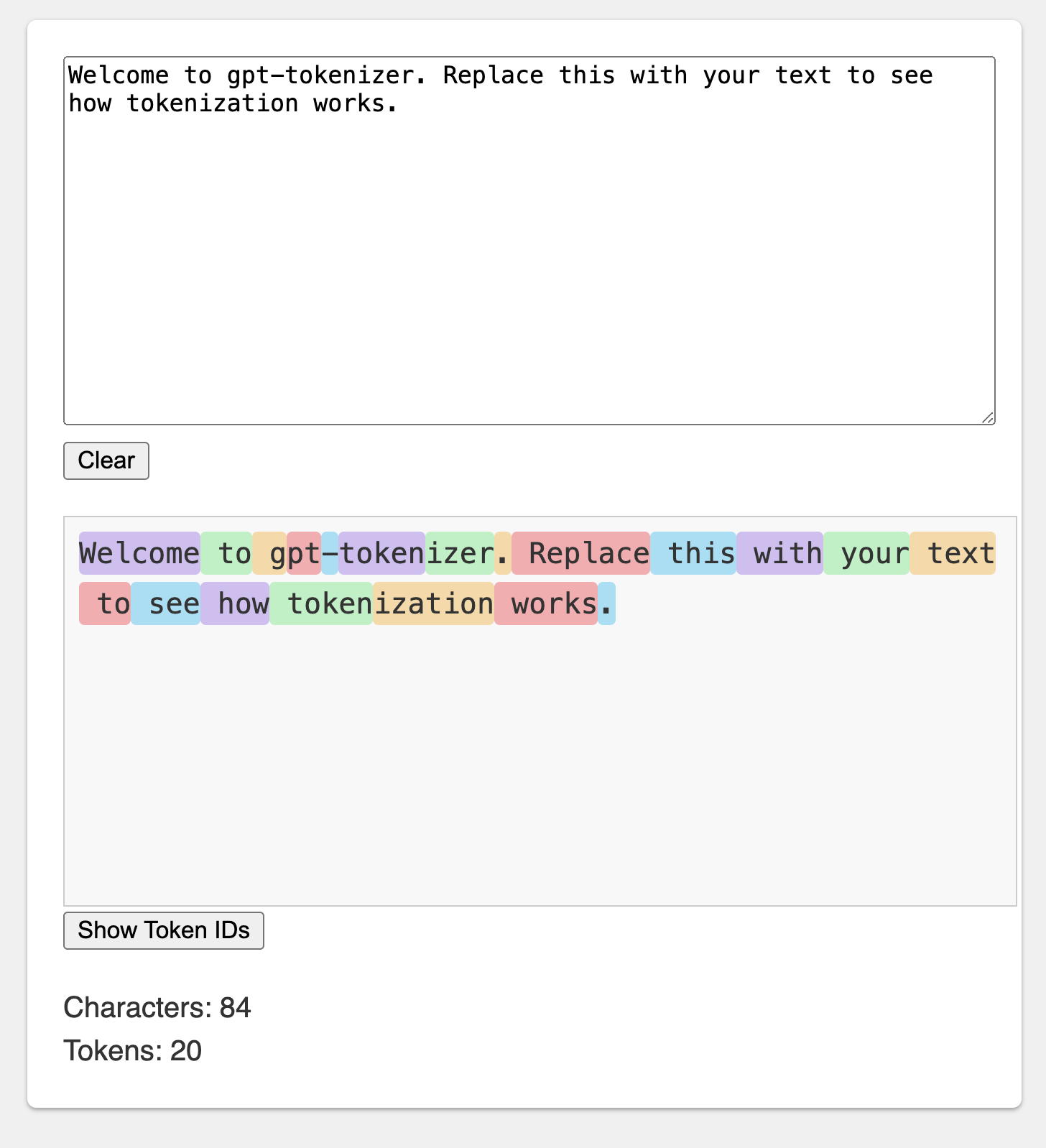
يحاكي الملعب الرسمي Openai Tokenizer.
توفر المكتبة وظائف مختلفة لتحويل النص إلى (ومن) سلسلة من الأعداد الصحيحة (الرموز) التي يمكن إطعامها في نموذج LLM. يتم التحول باستخدام خوارزمية ترميز زوج البايت (BPE) المستخدمة بواسطة Openai.
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} بشكل افتراضي ، يستخدم الاستيراد من gpt-tokenizer ترميز cl100k_base ، الذي يستخدمه gpt-3.5-turbo و gpt-4 .
للحصول على رمز رمزي لنموذج مختلف ، استيراده مباشرة ، على سبيل المثال:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' إذا كنت تتعامل مع حل لا يدعم exports Package.json ، فقد تحتاج إلى الاستيراد من دليل cjs أو esm المعني ، على سبيل المثال:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' إذا كنت لا تمانع في تحميل الرمز المميز بشكل غير متزامن ، فيمكنك استخدام استيراد ديناميكي داخل وظيفتك ، مثل ذلك:
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) إذا لم يكن النموذج الخاص بك مدعومًا من الحزمة ، لكنك تعرف أي ترميز BPE الذي يستخدمه ، فيمكنك تحميل الترميز مباشرة ، على سبيل المثال:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) ملاحظة: إذا كنت تستخدم gpt-3.5-* أو gpt-4-* ولا ترى النموذج الذي تبحث عنه ، فاستخدم ترميز cl100k_base مباشرة.
encode(text: string): number[]يشفر النص المحدد في سلسلة من الرموز. استخدم هذه الطريقة عندما تحتاج إلى تحويل قطعة من النص إلى تنسيق الرمز المميز الذي يمكن أن تقوم به نماذج GPT.
مثال:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringفك تشفير سلسلة من الرموز مرة أخرى في النص. استخدم هذه الطريقة عندما تريد تحويل الرموز المميزة من نماذج GPT إلى نص قابل للقراءة البشرية.
مثال:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number يتحقق مما إذا كان النص ضمن حد الرمز المميز. إرجاع false إذا تم تجاوز الحد ، وإلا بإرجاع عدد الرموز. استخدم هذه الطريقة للتحقق بسرعة مما إذا كان نص معين ضمن الحد المميز الذي تفرضه نماذج GPT ، دون ترميز النص بأكمله.
مثال:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): numberيحسب عدد الرموز في نص الإدخال أو الدردشة. استخدم هذه الطريقة عندما تحتاج إلى تحديد عدد الرموز دون التحقق من الحد.
مثال:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]يشفر الدردشة المعطاة في سلسلة من الرموز.
إذا لم تقم باستيراد إصدار النموذج مباشرة ، أو إذا لم يتم توفير model أثناء التهيئة ، فيجب توفيره هنا لتكرار الدردشة بشكل صحيح لنموذج معين. استخدم هذه الطريقة عندما تحتاج إلى تحويل الدردشة إلى تنسيق الرمز المميز الذي يمكن أن تقوم به نماذج GPT.
مثال:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )لاحظ أنه إذا قمت بترميز دردشة فارغة ، فستظل تحتوي على الحد الأدنى لعدد الرموز الخاصة.
encodeGenerator(text: string): Generator<number[], void, undefined>يشفر النص المحدد باستخدام مولد ، ويعطي قطعًا من الرموز. استخدم هذه الطريقة عندما تريد تشفير النص في أجزاء ، والتي يمكن أن تكون مفيدة لمعالجة النصوص الكبيرة أو بيانات الدفق.
مثال:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> مثل encodeChat ، ولكنه يستخدم مولدًا كإخراج ، وقد يستخدم أي تكرار chat الإدخال.
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>يفكّر ترميز سلسلة من الرموز باستخدام مولد ، مما يعطي قطعًا من النص الذي تم فك تشفيره. استخدم هذه الطريقة عندما تريد فك تشفير الرموز في قطع ، والتي يمكن أن تكون مفيدة لمعالجة المخرجات الكبيرة أو بيانات الدفق.
مثال:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>يدلل ترميز سلسلة من الرموز المميزة بشكل غير متزامن باستخدام مولد ، مما يؤدي إلى قطع نص من النص فك التشفير. استخدم هذه الطريقة عندما تريد فك تشفير الرموز في قطع غير متزامنة ، والتي يمكن أن تكون مفيدة لمعالجة المخرجات الكبيرة أو دفق البيانات في سياق غير متزامن.
مثال:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} هناك عدد قليل من الرموز الخاصة التي تستخدمها نماذج GPT. لا تدعم جميع النماذج كل هذه الرموز.
يتيح لك gpt-tokenizer تحديد مجموعات مخصصة من الرموز المميزة المسموح بها عند ترميز النص. للقيام بذلك ، تمرير Set تحتوي على الرموز الخاصة المسموح بها كمعلمة إلى وظيفة encode :
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) وبالمثل ، يمكنك تحديد مجموعات مخصصة من الرموز الخاصة غير المسموح بها عند ترميز النص. تمرير Set تحتوي على الرموز الخاصة غير المسموح بها كمعلمة إلى وظيفة encode :
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )في هذا المثال ، يتم طرح خطأ ، لأن نص الإدخال يحتوي على رمز خاص غير مسموح به.
يتضمن gpt-tokenizer مجموعة من حالات الاختبار في ملف testplans.txt لضمان توافقه مع مكتبة Python tiktoken من Openai. تتحقق حالات الاختبار هذه من وظائف وسلوك gpt-tokenizer ، مما يوفر مرجعًا موثوقًا للمطورين.
يساعد تشغيل اختبارات الوحدة والتحقق من حالات الاختبار في الحفاظ على الاتساق بين المكتبة وتنفيذ Python الأصلي.
يوفر gpt-tokenizer بيانات شاملة حول جميع نماذج Openai من خلال تصدير models من gpt-tokenizer/models . يتضمن ذلك معلومات مفصلة حول نوافذ السياق والتكاليف وخفض بيانات التدريب وحالة الإهمال.
يتم الحفاظ على البيانات بانتظام لتتناسب مع الوثائق الرسمية لـ Openai. نرحب بالمساهمات في الحفاظ على تحديث البيانات هذه-إذا لاحظت أي تباينات أو لديك تحديثات ، فلا تتردد في فتح العلاقات العامة.
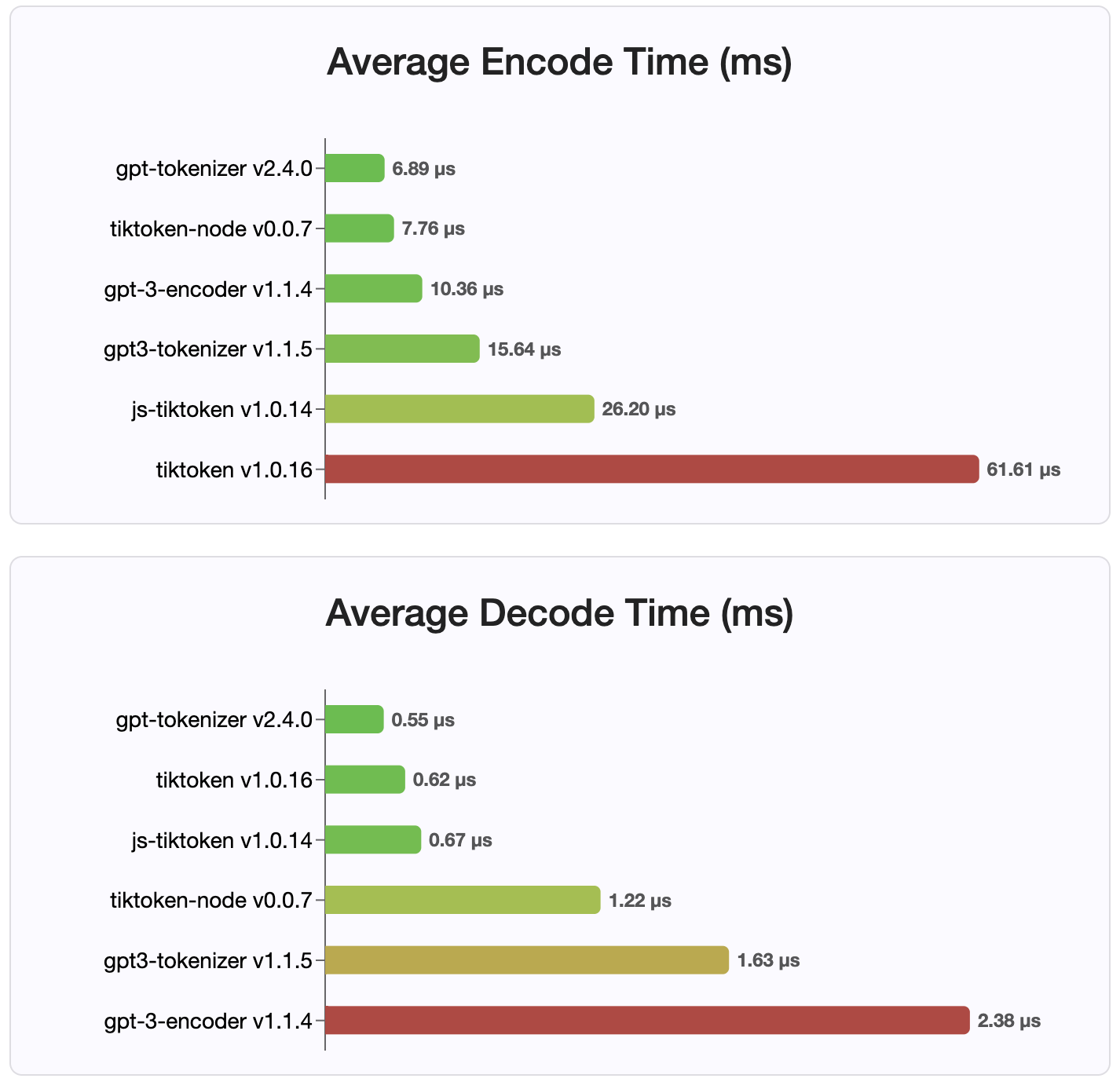
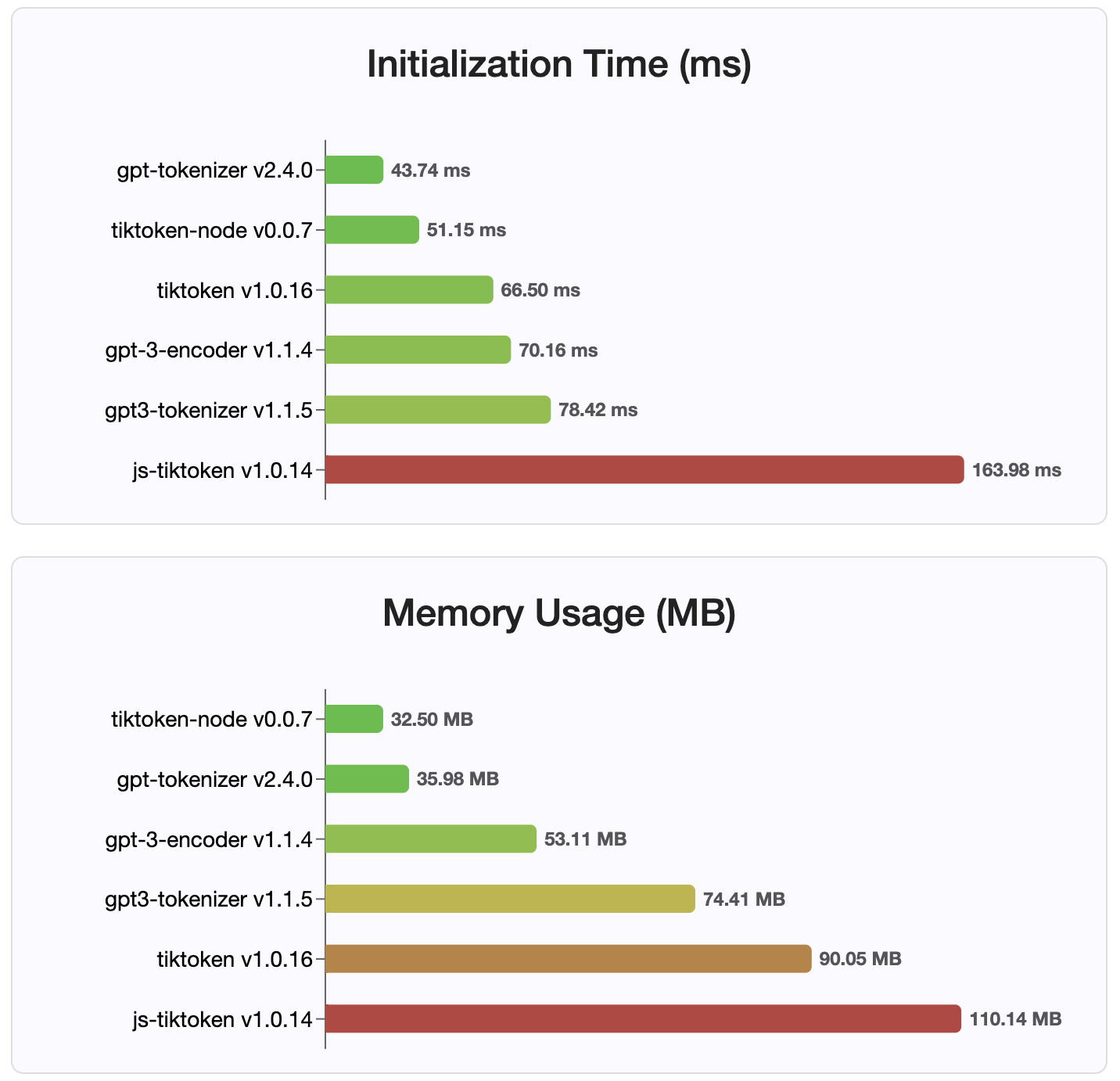
منذ الإصدار 2.4.0 ، يعد gpt-tokenizer هو أسرع تطبيقات الرمز المميز المتاح على NPM. إنها أسرع من تطبيقات ربط WASM/Node المتاحة. لديها أسرع وقت تشفير ، فك تشفير ، بصمة ذاكرة صغيرة. كما أنه يهيئة أسرع من جميع التطبيقات الأخرى.
الترميزات نفسها هي أيضًا الأصغر حجمًا ، نظرًا للتنسيق المضغوط الذي يتم تخزينه.
معهد ماساتشوستس للتكنولوجيا
المساهمات مرحب بها! يرجى فتح طلب سحب أو مشكلة لمناقشة تقارير الأخطاء الخاصة بك ، أو استخدام ميزة المناقشات للأفكار أو أي استفسارات أخرى.
بفضل @Dmitry-Brazhenko's Sharptoken ، الذي تم تقديم رمزه كمرجع للميناء.
آمل أن تجد gpt-tokenizer مفيدًا في مشاريعك!


