gpt tokenizer
2.7.0
gpt-tokenizer é um codificador/decodificador de pares de token que suporta todos os modelos do OpenAI (incluindo GPT-3.5, GPT-4, GPT-4O e O1). É o tokenizador GPT mais rápido, menor e mais baixo disponível para todos os ambientes JavaScript. Está escrito no TypeScript.
Esta biblioteca foi confiável por:
Por favor, considere? Pomitando o projeto se você achar útil.
A partir de 2023, é o tokenizador GPT de código aberto mais completo, no NPM. Este pacote é um porto do Tiktoken do OpenAI, com alguns recursos adicionais e exclusivos espalhados no topo:
encodeChatr50k_base , p50k_base , p50k_edit , cl100k_base e o200k_base )decodeAsyncGenerator e decodeGenerator com qualquer entrada iterável)isWithinTokenLimit para avaliar o limite de token sem codificar todo o texto/bate -paponpm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >Se você deseja usar uma codificação personalizada, busque o script relevante.
gpt-4o e o1 )gpt-4-* e gpt-3.5-turbo ) O nome global é uma concatenação: GPTTokenizer_${encoding} .
Consulte os modelos suportados e sua seção de codificação para obter mais informações.
O playground é publicado sob um URL memorável: https://gpt-tokenizer.dev/
Você pode brincar com o pacote no navegador usando o Playground do Codesandbox.
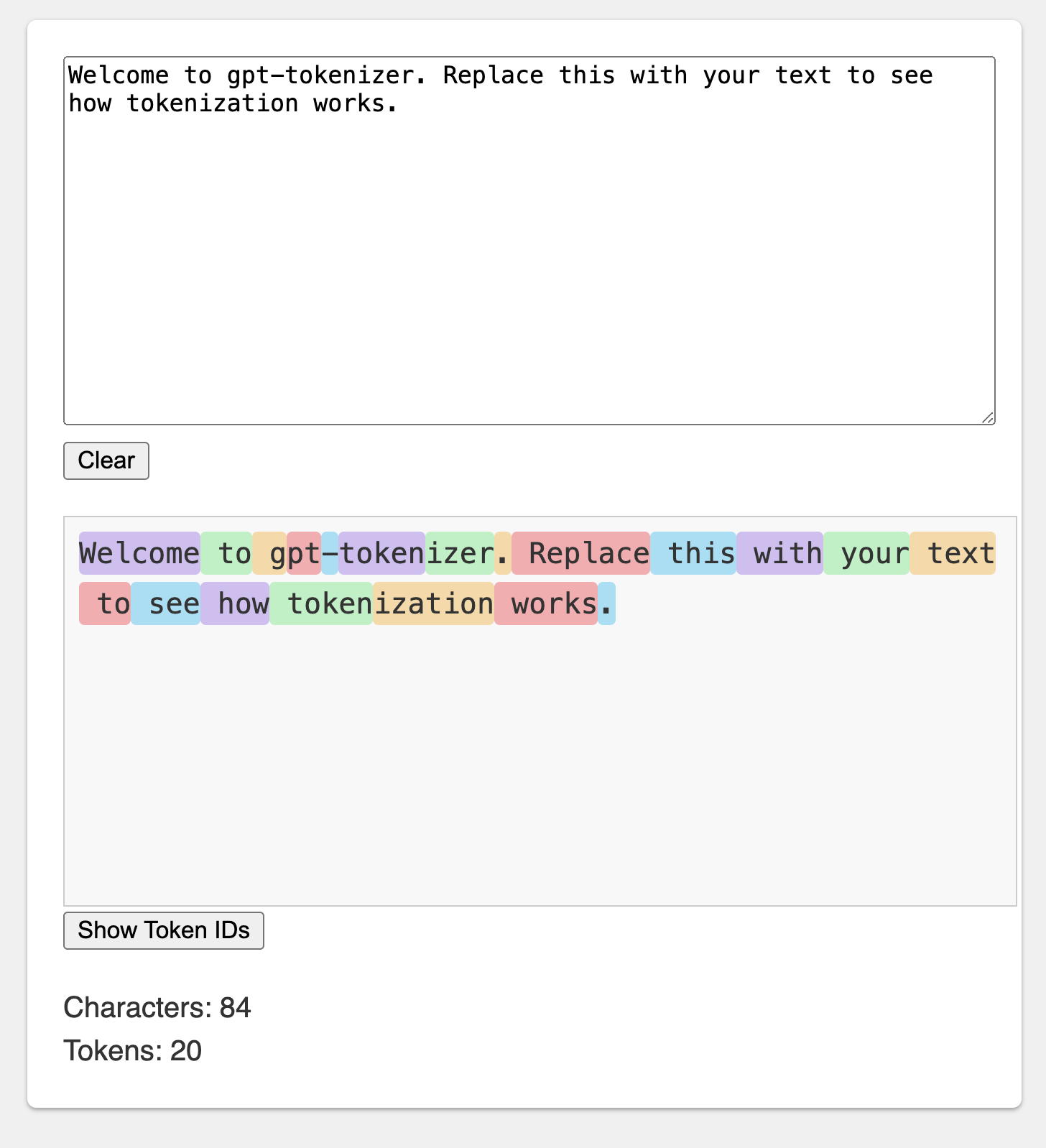
O playground imita o tokenizador oficial do Openai.
A biblioteca fornece várias funções para transformar o texto em (e a partir) de uma sequência de números inteiros (tokens) que podem ser alimentados em um modelo LLM. A transformação é feita usando um algoritmo de codificação de pares de bytes (BPE) usado pelo OpenAI.
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} Por padrão, a importação do gpt-tokenizer usa a codificação cl100k_base , usada pelo gpt-3.5-turbo e gpt-4 .
Para obter um tokenizer para um modelo diferente, importá -lo diretamente, por exemplo:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' Se você estiver lidando com um resolvedor que não suporta a resolução do Package.json exports , pode ser necessário importar do respectivo diretório cjs ou esm , por exemplo:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' Se você não se importa de carregar o tokenizer de forma assíncrona, pode usar uma importação dinâmica dentro de sua função, assim:
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) Se o seu modelo não for suportado pelo pacote, mas você sabe qual codificação do BPE ele usa, você pode carregar a codificação diretamente, por exemplo:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) Nota: Se você estiver usando gpt-3.5-* ou gpt-4-* e não veja o modelo que você está procurando, use a codificação cl100k_base diretamente.
encode(text: string): number[]Codifica o texto fornecido em uma sequência de tokens. Use este método quando precisar transformar um texto no formato token que os modelos GPT podem processar.
Exemplo:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringDecodifica uma sequência de tokens de volta ao texto. Use este método quando deseja converter os tokens de saída dos modelos GPT de volta ao texto legível por humanos.
Exemplo:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number Verifica se o texto está dentro do limite do token. Retorna false se o limite for excedido, caso contrário, retornará o número de tokens. Use este método para verificar rapidamente se um determinado texto está dentro do limite de token imposto pelos modelos GPT, sem codificar o texto inteiro.
Exemplo:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): numberConta o número de tokens no texto ou bate -papo de entrada. Use este método quando precisar determinar o número de tokens sem verificar um limite.
Exemplo:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]Codifica o bate -papo dado em uma sequência de tokens.
Se você não importou a versão do modelo diretamente ou se model não foi fornecido durante a inicialização, ele deve ser fornecido aqui para tokenizar corretamente o bate -papo para um determinado modelo. Use este método quando precisar transformar um bate -papo no formato token que os modelos GPT podem processar.
Exemplo:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )Observe que, se você codificar um bate -papo vazio, ele ainda conterá o número mínimo de tokens especiais.
encodeGenerator(text: string): Generator<number[], void, undefined>Codifica o texto fornecido usando um gerador, produzindo pedaços de tokens. Use este método quando deseja codificar o texto em pedaços, o que pode ser útil para processar textos grandes ou transmitir dados.
Exemplo:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> O mesmo que encodeChat , mas usa um gerador como saída e pode usar qualquer iterador como chat de entrada.
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>Decodifica uma sequência de tokens usando um gerador, produzindo pedaços de texto decodificado. Use este método quando deseja decodificar tokens em pedaços, que podem ser úteis para processar grandes saídas ou streaming de dados.
Exemplo:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>Decodifica uma sequência de tokens de forma assíncrona usando um gerador, produzindo pedaços de texto decodificado. Use esse método quando deseja decodificar tokens em pedaços de forma assíncrona, o que pode ser útil para processar grandes saídas ou transmitir dados em um contexto assíncrono.
Exemplo:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} Existem alguns tokens especiais que são usados pelos modelos GPT. Nem todos os modelos suportam todos esses tokens.
gpt-tokenizer permite especificar conjuntos personalizados de tokens especiais permitidos ao codificar o texto. Para fazer isso, passe um Set contendo os tokens especiais permitidos como um parâmetro para a função encode :
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) Da mesma forma, você pode especificar conjuntos personalizados de tokens especiais não permitidos ao codificar o texto. Passe um Set contendo os tokens especiais não permitidos como um parâmetro para a função encode :
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )Neste exemplo, um erro é lançado, porque o texto de entrada contém um token especial não permitido.
gpt-tokenizer inclui um conjunto de casos de teste no arquivo testplans.txt para garantir sua compatibilidade com a biblioteca Python tiktoken do OpenAI. Esses casos de teste validam a funcionalidade e o comportamento do gpt-tokenizer , fornecendo uma referência confiável para os desenvolvedores.
A execução dos testes de unidade e a verificação dos casos de teste ajuda a manter a consistência entre a biblioteca e a implementação original do Python.
gpt-tokenizer fornece dados abrangentes sobre todos os modelos OpenAI por meio dos models exportar do gpt-tokenizer/models . Isso inclui informações detalhadas sobre janelas de contexto, custos, corte de dados de treinamento e status de depreciação.
Os dados são mantidos regularmente para corresponder à documentação oficial do OpenAI. As contribuições para manter esses dados atualizados são bem-vindos-se você notar alguma discrepâncias ou tiver atualizações, sinta-se à vontade para abrir um PR.
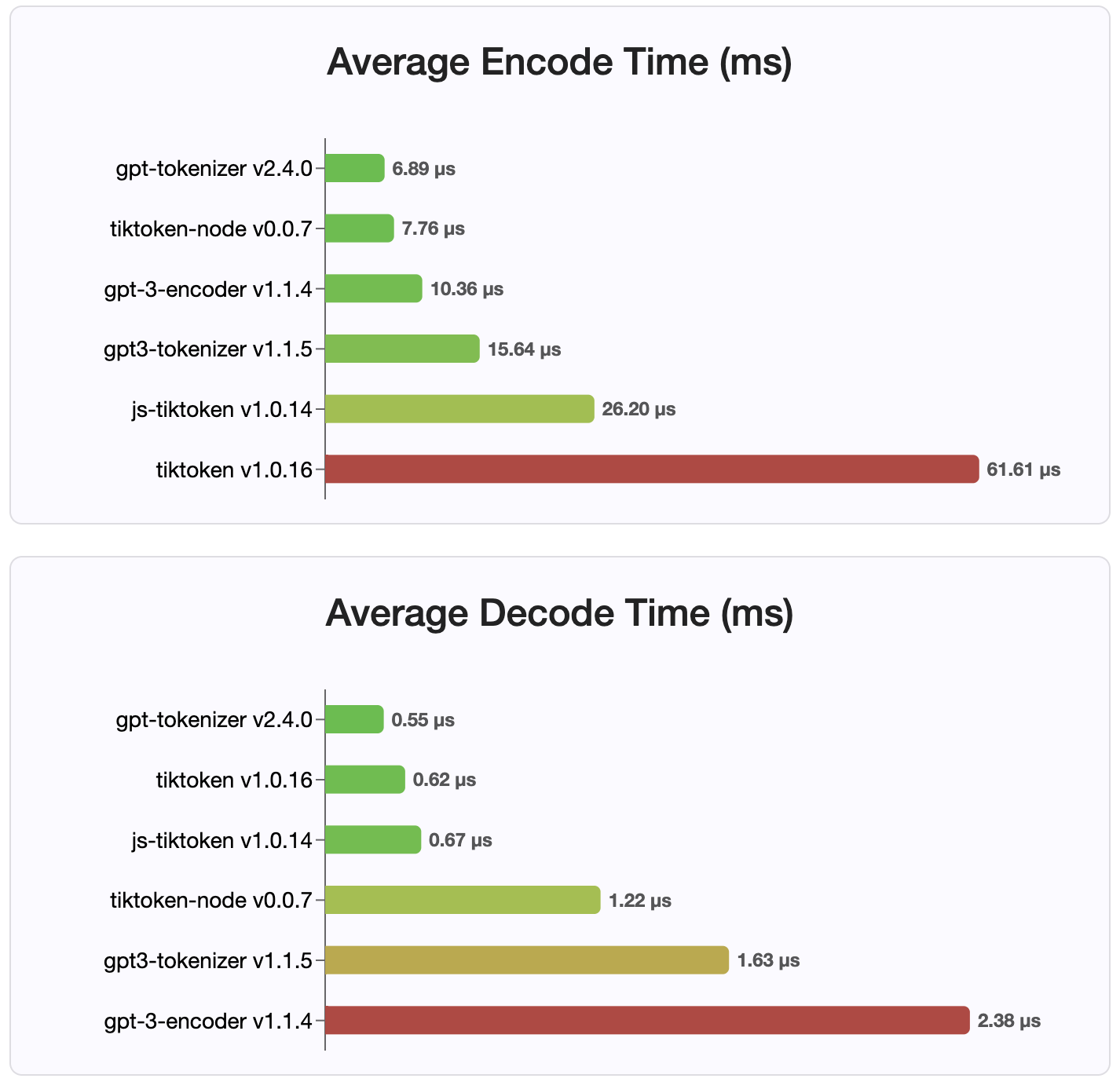
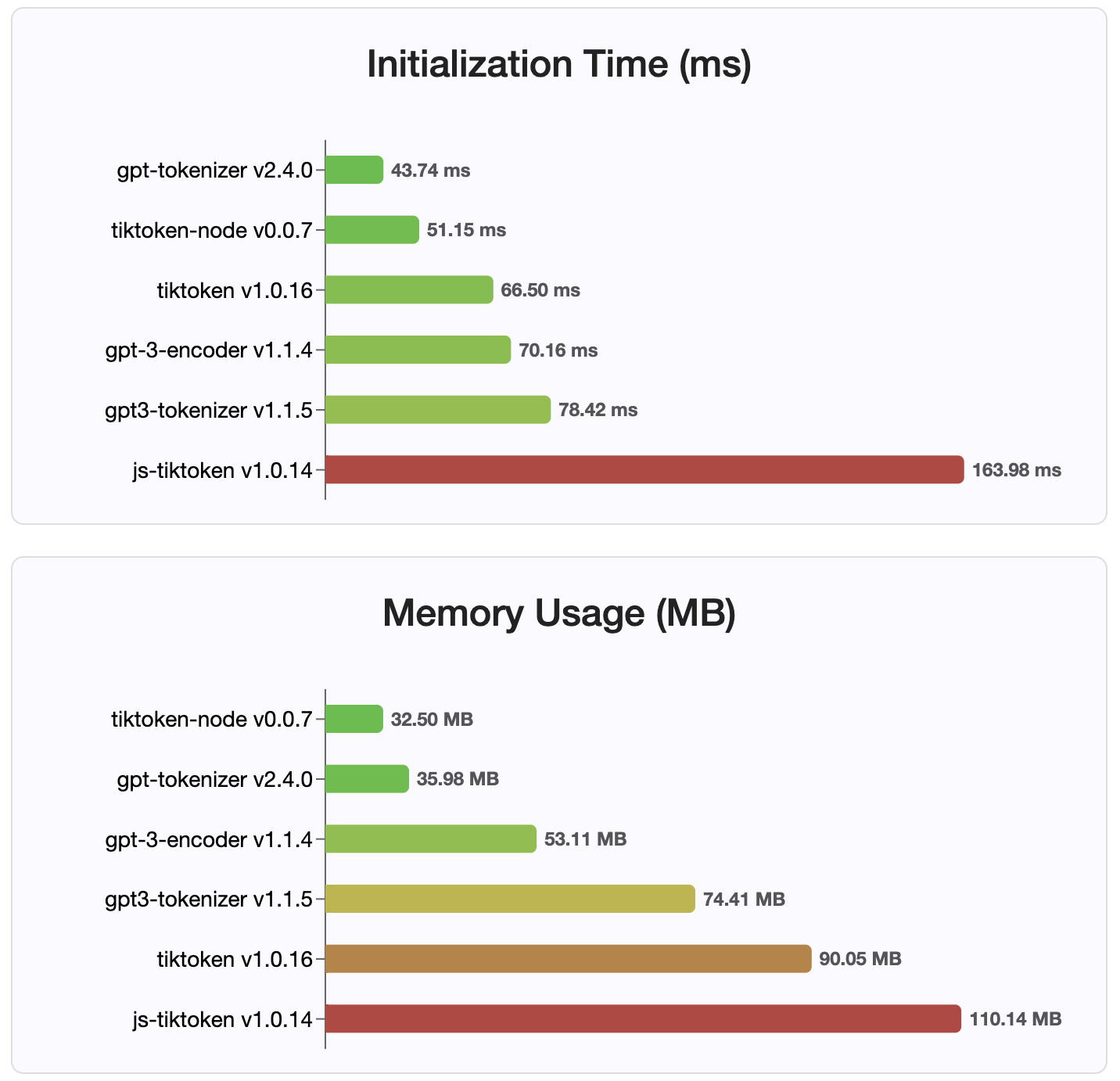
Desde a versão 2.4.0, gpt-tokenizer é a implementação do tokenizador mais rápida disponível no NPM. É ainda mais rápido que as implementações de ligação ao WASM/NODE disponíveis. Tem a codificação mais rápida, o tempo de decodificação e uma pequena pegada de memória. Ele também inicializa mais rápido do que todas as outras implementações.
As codificações também são as menores em tamanho, devido ao formato compacto em que são armazenadas.
Mit
As contribuições são bem -vindas! Abra uma solicitação de tração ou um problema para discutir seus relatórios de bugs ou usar o recurso de discussões para idéias ou qualquer outra pergunta.
Graças ao Sharptoken de @Dmitry-Brazhenko, cujo código foi servido como referência para o porto.
Espero que você ache o gpt-tokenizer útil em seus projetos!


