gpt tokenizer
2.7.0
gpt-tokenizer adalah encoder pair byte/dekoder yang mendukung semua model Openai (termasuk GPT-3.5, GPT-4, GPT-4O, dan O1). Ini adalah tokenizer GPT Footprint tercepat, terkecil dan terendah yang tersedia untuk semua lingkungan JavaScript. Itu ditulis dalam naskah.
Perpustakaan ini telah dipercaya oleh:
Harap pertimbangkan? mensponsori proyek jika Anda merasa berguna.
Pada tahun 2023, ini adalah tokenizer GPT open-source yang paling lengkap di NPM. Paket ini adalah pelabuhan Tiktoken Openai, dengan beberapa fitur unik tambahan yang ditaburkan di atas:
encodeChatr50k_base , p50k_base , p50k_edit , cl100k_base dan o200k_base )decodeAsyncGenerator dan decodeGenerator dengan input yang dapat diulang)isWithinTokenLimit untuk menilai batas token tanpa menyandikan seluruh teks/obrolannpm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >Jika Anda ingin menggunakan pengkodean khusus, ambil skrip yang relevan.
gpt-4o dan o1 )gpt-4-* dan gpt-3.5-turbo ) Nama global adalah gabungan: GPTTokenizer_${encoding} .
Lihat Model yang Didukung dan Bagian Pengkodeannya untuk informasi lebih lanjut.
The Playground diterbitkan di bawah URL yang berkesan: https://gpt-tokenizer.dev/
Anda dapat bermain dengan paket di browser menggunakan CodeSandBox Playground.
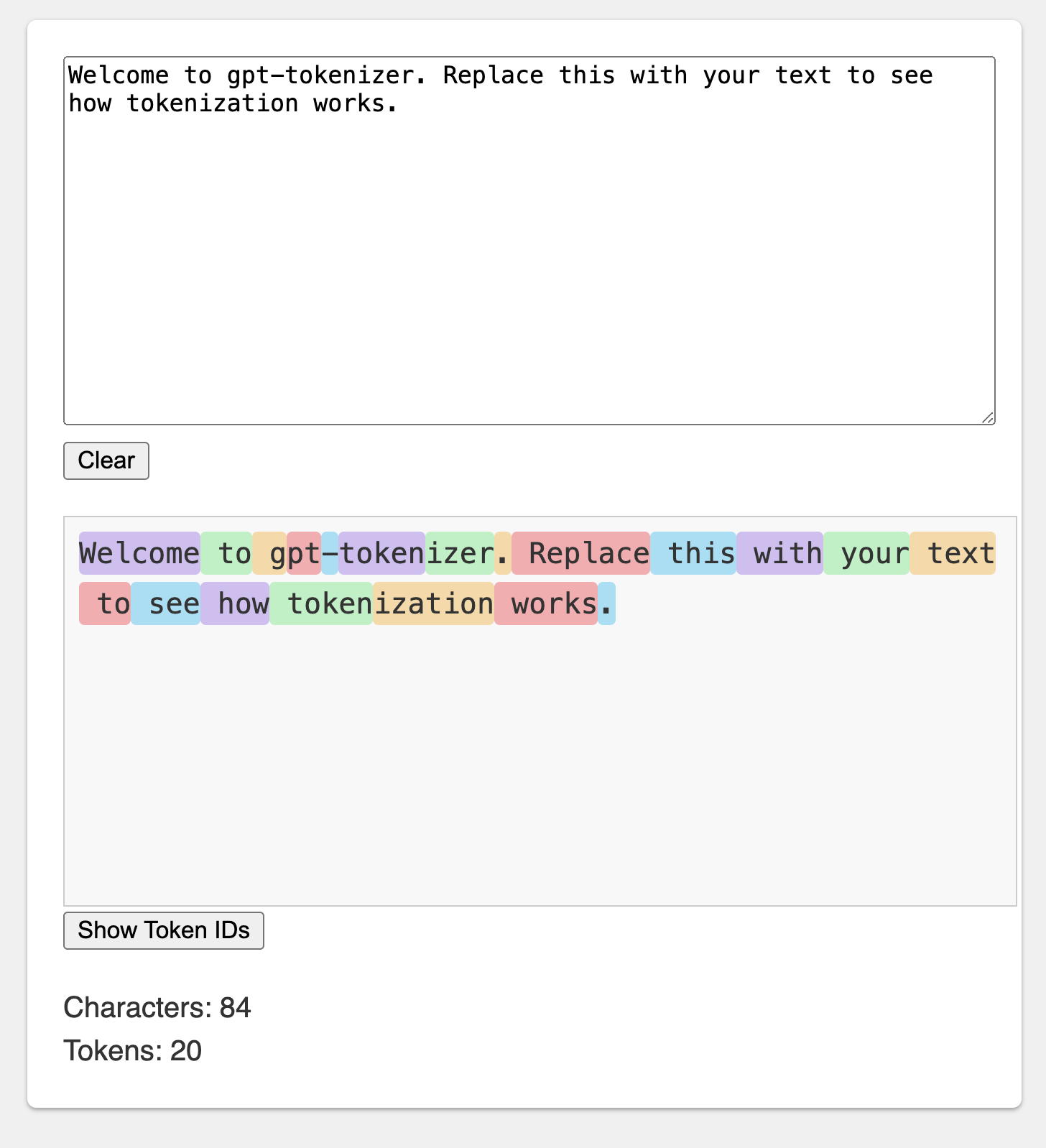
Taman bermain meniru Tokenizer Openai resmi.
Perpustakaan menyediakan berbagai fungsi untuk mengubah teks menjadi (dan dari) urutan bilangan bulat (token) yang dapat dimasukkan ke dalam model LLM. Transformasi dilakukan dengan menggunakan algoritma encoding pair byte (BPE) yang digunakan oleh OpenAI.
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} Secara default, mengimpor dari gpt-tokenizer menggunakan cl100k_base encoding, yang digunakan oleh gpt-3.5-turbo dan gpt-4 .
Untuk mendapatkan tokenizer untuk model yang berbeda, impor secara langsung, misalnya:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' Jika Anda berurusan dengan resolver yang cjs esm resolusi exports Paket.
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' Jika Anda tidak keberatan memuat tokenizer secara tidak sinkron, Anda dapat menggunakan impor dinamis di dalam fungsi Anda, seperti itu:
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) Jika model Anda tidak didukung oleh paket, tetapi Anda tahu pengkodean BPE mana yang digunakannya, Anda dapat memuat pengkodean secara langsung, misalnya:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) Catatan: Jika Anda menggunakan gpt-3.5-* atau gpt-4-* dan tidak melihat model yang Anda cari, gunakan pengkodean cl100k_base secara langsung.
encode(text: string): number[]Mengkodekan teks yang diberikan ke dalam urutan token. Gunakan metode ini ketika Anda perlu mengubah sepotong teks menjadi format token yang dapat diproses oleh model GPT.
Contoh:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringMendekode urutan token kembali ke teks. Gunakan metode ini ketika Anda ingin mengonversi token output dari model GPT kembali menjadi teks yang dapat dibaca manusia.
Contoh:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number Memeriksa apakah teks berada dalam batas token. Mengembalikan false jika batas terlampaui, jika tidak mengembalikan jumlah token. Gunakan metode ini untuk memeriksa dengan cepat apakah teks yang diberikan berada dalam batas token yang dikenakan oleh model GPT, tanpa menyandikan seluruh teks.
Contoh:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): numberMenghitung jumlah token dalam teks input atau obrolan. Gunakan metode ini ketika Anda perlu menentukan jumlah token tanpa memeriksa batas.
Contoh:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]Mengkodekan obrolan yang diberikan ke dalam urutan token.
Jika Anda tidak mengimpor versi model secara langsung, atau jika model tidak disediakan selama inisialisasi, itu harus disediakan di sini untuk membasahi obrolan dengan benar untuk model yang diberikan. Gunakan metode ini ketika Anda perlu mengubah obrolan menjadi format token yang dapat diproses oleh model GPT.
Contoh:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )Perhatikan bahwa jika Anda menyandikan obrolan kosong, itu masih akan berisi jumlah minimum token khusus.
encodeGenerator(text: string): Generator<number[], void, undefined>Mengkodekan teks yang diberikan menggunakan generator, menghasilkan potongan token. Gunakan metode ini saat Anda ingin menyandikan teks dalam potongan, yang dapat berguna untuk memproses teks besar atau data streaming.
Contoh:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> Sama seperti encodeChat , tetapi menggunakan generator sebagai output, dan dapat menggunakan iterator apa pun sebagai chat input.
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>Decodes urutan token menggunakan generator, menghasilkan potongan teks yang didekodekan. Gunakan metode ini ketika Anda ingin mendekode token dalam potongan, yang dapat berguna untuk memproses output besar atau streaming data.
Contoh:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>Decodes serangkaian token secara tidak sinkron menggunakan generator, menghasilkan potongan teks yang diterjemahkan. Gunakan metode ini ketika Anda ingin memecahkan kode token dalam potongan secara tidak sinkron, yang dapat berguna untuk memproses output besar atau streaming data dalam konteks asinkron.
Contoh:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} Ada beberapa token khusus yang digunakan oleh model GPT. Tidak semua model mendukung semua token ini.
gpt-tokenizer memungkinkan Anda untuk menentukan set kustom token khusus yang diizinkan saat mengkode teks. Untuk melakukan ini, berikan satu Set yang berisi token khusus yang diizinkan sebagai parameter ke fungsi encode :
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) Demikian pula, Anda dapat menentukan set kustom token khusus yang tidak diizinkan saat mengkode teks. Lulus satu Set yang berisi token khusus yang dilarang sebagai parameter ke fungsi encode :
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )Dalam contoh ini, kesalahan dilemparkan, karena teks input berisi token khusus yang tidak diizinkan.
gpt-tokenizer mencakup satu set kasus uji di file testplans.txt untuk memastikan kompatibilitasnya dengan pustaka Python tiktoken Openai. Kasus-kasus uji ini memvalidasi fungsionalitas dan perilaku gpt-tokenizer , memberikan referensi yang dapat diandalkan untuk pengembang.
Menjalankan tes unit dan memverifikasi kasus uji membantu mempertahankan konsistensi antara perpustakaan dan implementasi Python asli.
gpt-tokenizer menyediakan data komprehensif tentang semua model OpenAI melalui ekspor models dari gpt-tokenizer/models . Ini termasuk informasi terperinci tentang jendela konteks, biaya, cutoff data pelatihan, dan status penyusutan.
Data secara teratur disimpan agar sesuai dengan dokumentasi resmi Openai. Kontribusi untuk menjaga data ini diperbarui-jika Anda melihat perbedaan atau memiliki pembaruan, jangan ragu untuk membuka PR.
Karena versi 2.4.0, gpt-tokenizer adalah implementasi tokenizer tercepat yang tersedia di NPM. Bahkan lebih cepat dari implementasi pengikatan WASM/Node yang tersedia. Ini memiliki pengkodean tercepat, waktu decoding dan jejak kaki kecil. Ini juga menginisialisasi lebih cepat dari semua implementasi lainnya.
Pengkodean itu sendiri juga merupakan ukuran terkecil, karena format kompak yang disimpan.
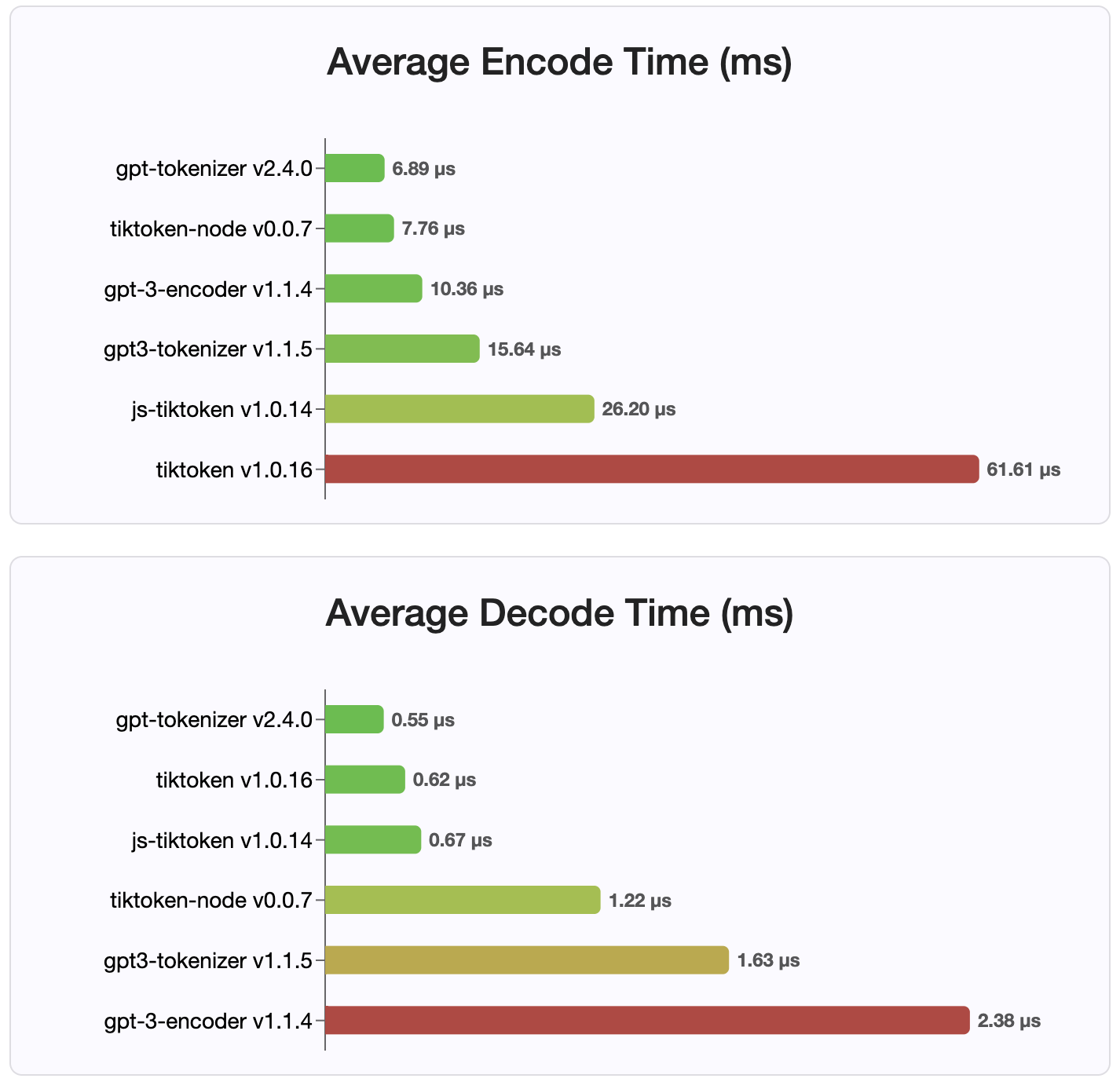
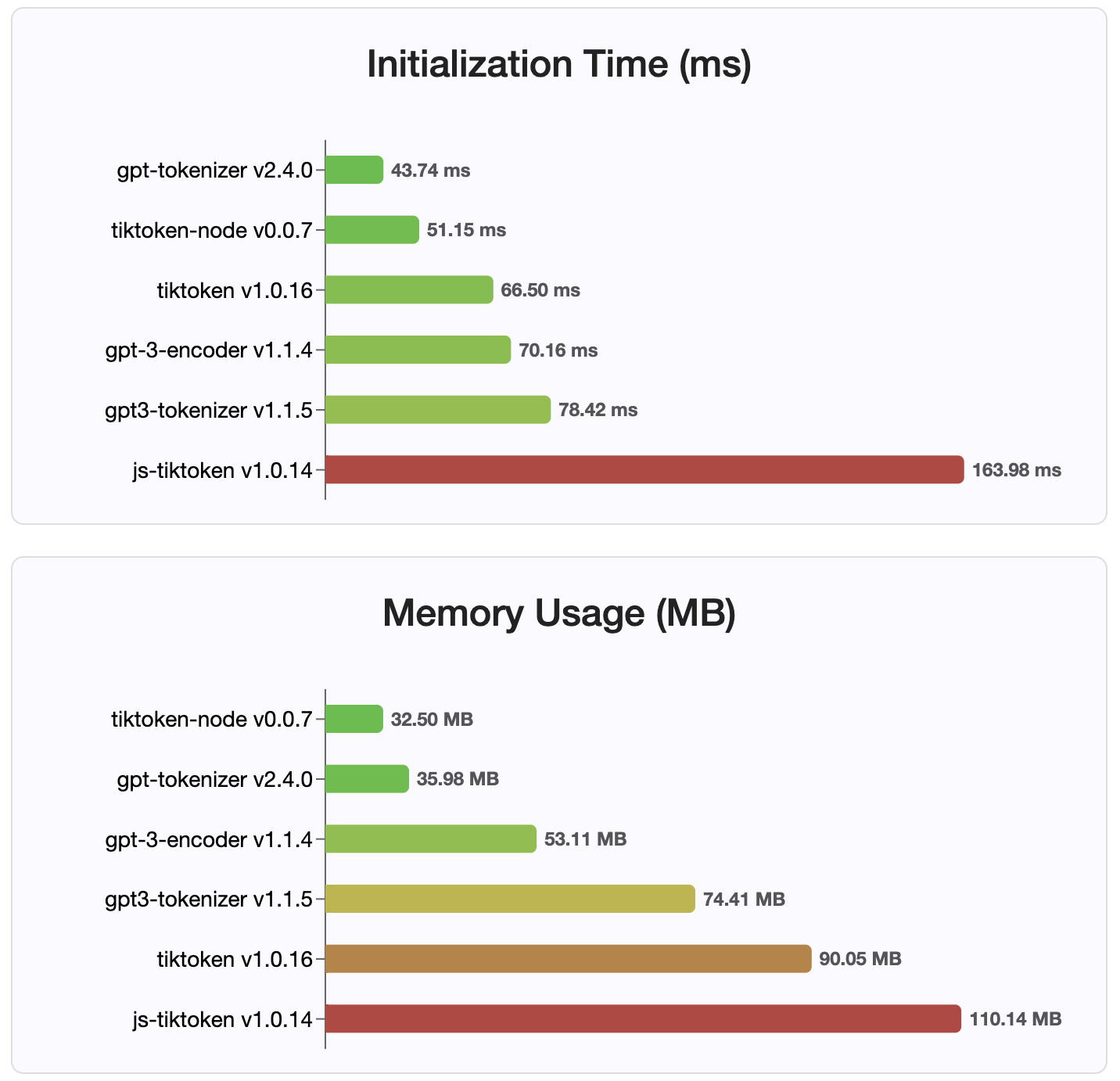
Mit
Kontribusi dipersilakan! Harap buka permintaan tarik atau masalah untuk membahas laporan bug Anda, atau gunakan fitur diskusi untuk ide atau pertanyaan lainnya.
Terima kasih kepada Sharptoken @Dmitry-Brazhenko, yang kodenya disajikan sebagai referensi untuk port.
Semoga Anda menemukan gpt-tokenizer berguna dalam proyek Anda!


