gpt tokenizer
2.7.0
gpt-tokenizer est un encodeur / décodeur de paires d'octets de jeton prenant en charge tous les modèles d'Openai (y compris GPT-3.5, GPT-4, GPT-4O et O1). C'est le tokenizer GPT le plus rapide, le plus petit et le plus bas disponible pour tous les environnements JavaScript. Il est écrit en dactylographie.
Cette bibliothèque a été fiable par:
Veuillez considérer? parrainer le projet si vous le trouvez utile.
À partir de 2023, il s'agit du tokenizer GPT le plus complet sur les fonctions open source sur NPM. Ce package est un port de Tiktoken d'Openai, avec des fonctionnalités uniques supplémentaires saupoudrées sur le dessus:
encodeChatr50k_base , p50k_base , p50k_edit , cl100k_base et o200k_base )decodeAsyncGenerator et decodeGenerator avec toute entrée itérable)isWithinTokenLimit hautement performante pour évaluer la limite de jetons sans codage tout le texte / chatnpm install gpt-tokenizer < script src =" https://unpkg.com/gpt-tokenizer " > </ script >
< script >
// the package is now available as a global:
const { encode , decode } = GPTTokenizer_cl100k_base
</ script >Si vous souhaitez utiliser un encodage personnalisé, récupérez le script pertinent.
gpt-4o et o1 )gpt-4-* et gpt-3.5-turbo ) Le nom global est une concaténation: GPTTokenizer_${encoding} .
Reportez-vous aux modèles pris en charge et à leur section d'encodages pour plus d'informations.
Le terrain de jeu est publié sous une URL mémorable: https://gpt-tokenizer.dev/
Vous pouvez jouer avec le package dans le navigateur à l'aide du terrain de jeu Codesandbox.
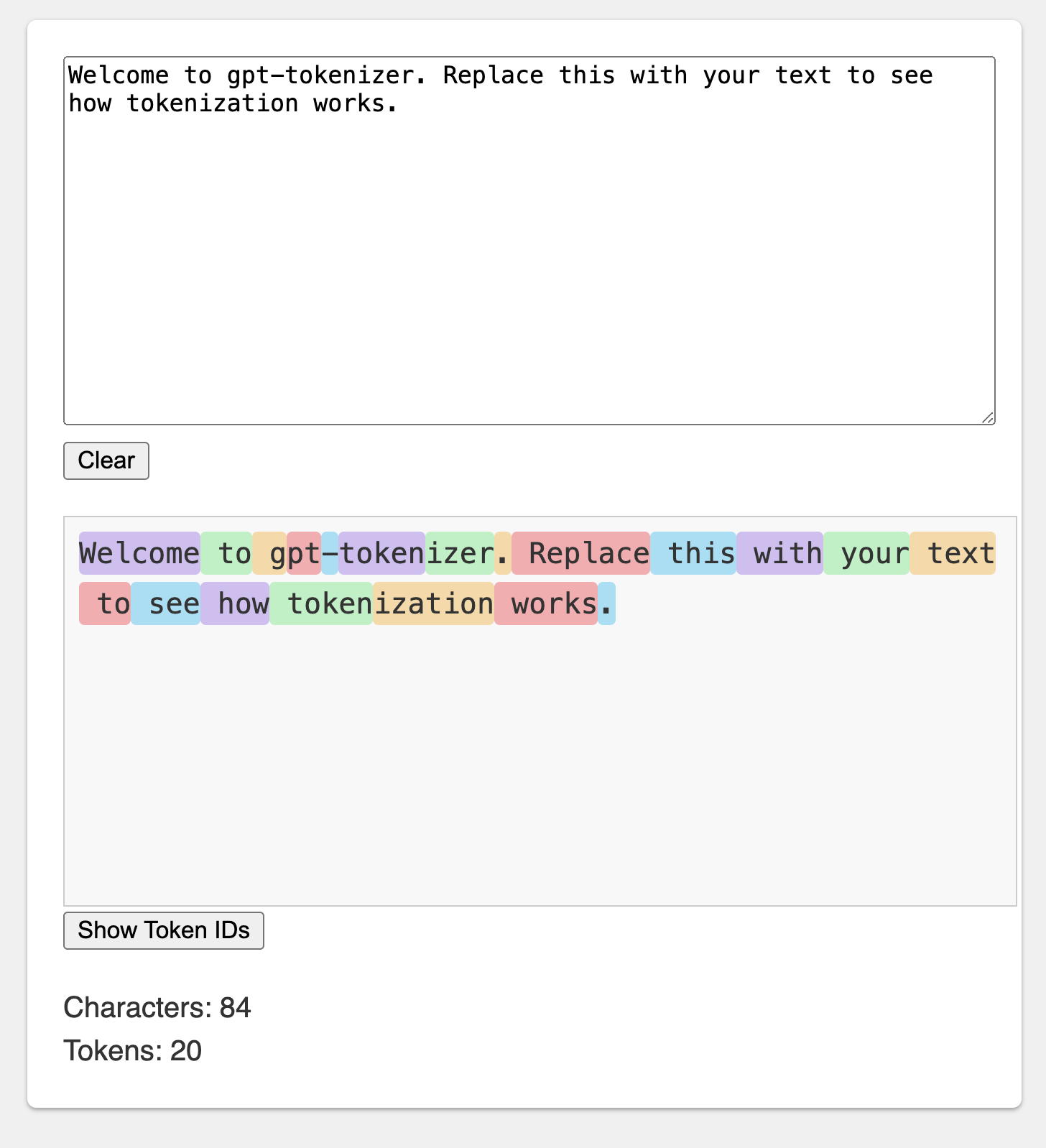
Le terrain de jeu imite le tokenizer Openai officiel.
La bibliothèque fournit diverses fonctions pour transformer le texte en (et à partir) d'une séquence d'entiers (jetons) qui peuvent être introduites dans un modèle LLM. La transformation est effectuée en utilisant un algorithme de codage de paire d'octets (BPE) utilisé par OpenAI.
import {
encode ,
encodeChat ,
decode ,
isWithinTokenLimit ,
encodeGenerator ,
decodeGenerator ,
decodeAsyncGenerator ,
} from 'gpt-tokenizer'
// note: depending on the model, import from the respective file, e.g.:
// import {...} from 'gpt-tokenizer/model/gpt-4o'
const text = 'Hello, world!'
const tokenLimit = 10
// Encode text into tokens
const tokens = encode ( text )
// Decode tokens back into text
const decodedText = decode ( tokens )
// Check if text is within the token limit
// returns false if the limit is exceeded, otherwise returns the actual number of tokens (truthy value)
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )
// Example chat:
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
] as const
// Encode chat into tokens
const chatTokens = encodeChat ( chat )
// Check if chat is within the token limit
const chatWithinTokenLimit = isWithinTokenLimit ( chat , tokenLimit )
// Encode text using generator
for ( const tokenChunk of encodeGenerator ( text ) ) {
console . log ( tokenChunk )
}
// Decode tokens using generator
for ( const textChunk of decodeGenerator ( tokens ) ) {
console . log ( textChunk )
}
// Decode tokens using async generator
// (assuming `asyncTokens` is an AsyncIterableIterator<number>)
for await ( const textChunk of decodeAsyncGenerator ( asyncTokens ) ) {
console . log ( textChunk )
} Par défaut, l'importation de gpt-tokenizer utilise le codage cl100k_base , utilisé par gpt-3.5-turbo et gpt-4 .
Pour obtenir un tokenizer pour un modèle différent, importez-le directement, par exemple:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/model/gpt-3.5-turbo' Si vous avez affaire à un résolveur qui ne prend pas en charge Package.JSON exports Resolution, vous devrez peut-être importer à partir du répertoire cjs ou esm respectif, par exemple:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/cjs/model/gpt-3.5-turbo' Si cela ne vous dérange pas de charger le tokenzer de manière asynchrone, vous pouvez utiliser une importation dynamique dans votre fonction, comme ainsi:
const {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} = await import ( 'gpt-tokenizer/model/gpt-3.5-turbo' ) Si votre modèle n'est pas pris en charge par le package, mais que vous savez quel codage BPE il utilise, vous pouvez charger le codage directement, par exemple:
import {
encode ,
decode ,
isWithinTokenLimit ,
// etc...
} from 'gpt-tokenizer/encoding/cl100k_base'o1-* ( o200k_base )gpt-4o ( o200k_base )gpt-4-* ( cl100k_base )gpt-3.5-turbo ( cl100k_base )text-davinci-003 ( p50k_base )text-davinci-002 ( p50k_base )text-davinci-001 ( r50k_base ) Remarque: Si vous utilisez gpt-3.5-* ou gpt-4-* et que vous ne voyez pas le modèle que vous recherchez, utilisez directement le codage cl100k_base .
encode(text: string): number[]Code le texte donné dans une séquence de jetons. Utilisez cette méthode lorsque vous devez transformer un texte en format de jeton que les modèles GPT peuvent traiter.
Exemple:
import { encode } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = encode ( text )decode(tokens: number[]): stringDécode une séquence de jetons dans le texte. Utilisez cette méthode lorsque vous souhaitez convertir les jetons de sortie des modèles GPT en texte lisible par l'homme.
Exemple:
import { decode } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
const text = decode ( tokens )isWithinTokenLimit(text: string, tokenLimit: number): false | number Vérifie si le texte est dans la limite de jeton. Renvoie false si la limite est dépassée, sinon renvoie le nombre de jetons. Utilisez cette méthode pour vérifier rapidement si un texte donné se situe dans la limite de jeton imposé par les modèles GPT, sans coder l'ensemble du texte.
Exemple:
import { isWithinTokenLimit } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenLimit = 10
const withinTokenLimit = isWithinTokenLimit ( text , tokenLimit )countTokens(text: string | Iterable<ChatMessage>): numberCompte le nombre de jetons dans le texte d'entrée ou le chat. Utilisez cette méthode lorsque vous devez déterminer le nombre de jetons sans vérifier par rapport à une limite.
Exemple:
import { countTokens } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokenCount = countTokens ( text )encodeChat(chat: ChatMessage[], model?: ModelName): number[]Encode le chat donné dans une séquence de jetons.
Si vous n'avez pas importé la version du modèle directement, ou si model n'a pas été fourni lors de l'initialisation, il doit être fourni ici pour tokeniser correctement le chat pour un modèle donné. Utilisez cette méthode lorsque vous devez transformer un chat au format de jeton que les modèles GPT peuvent traiter.
Exemple:
import { encodeChat } from 'gpt-tokenizer'
const chat = [
{ role : 'system' , content : 'You are a helpful assistant.' } ,
{ role : 'assistant' , content : 'gpt-tokenizer is awesome.' } ,
]
const tokens = encodeChat ( chat )Notez que si vous codez un chat vide, il contiendra toujours le nombre minimum de jetons spéciaux.
encodeGenerator(text: string): Generator<number[], void, undefined>Encode le texte donné à l'aide d'un générateur, donnant des morceaux de jetons. Utilisez cette méthode lorsque vous souhaitez coder du texte en morceaux, ce qui peut être utile pour traiter de grands textes ou des données de streaming.
Exemple:
import { encodeGenerator } from 'gpt-tokenizer'
const text = 'Hello, world!'
const tokens = [ ]
for ( const tokenChunk of encodeGenerator ( text ) ) {
tokens . push ( ... tokenChunk )
}encodeChatGenerator(chat: Iterator<ChatMessage>, model?: ModelName): Generator<number[], void, undefined> Identique à encodeChat , mais utilise un générateur comme sortie et peut utiliser n'importe quel itérateur comme chat d'entrée.
decodeGenerator(tokens: Iterable<number>): Generator<string, void, undefined>Décode une séquence de jetons à l'aide d'un générateur, donnant des morceaux de texte décodé. Utilisez cette méthode lorsque vous souhaitez décoder les jetons en morceaux, ce qui peut être utile pour traiter de grandes sorties ou des données de streaming.
Exemple:
import { decodeGenerator } from 'gpt-tokenizer'
const tokens = [ 18435 , 198 , 23132 , 328 ]
let decodedText = ''
for ( const textChunk of decodeGenerator ( tokens ) ) {
decodedText += textChunk
}decodeAsyncGenerator(tokens: AsyncIterable<number>): AsyncGenerator<string, void, undefined>Décode une séquence de jetons de manière asynchrone à l'aide d'un générateur, donnant des morceaux de texte décodé. Utilisez cette méthode lorsque vous souhaitez décoder des jetons en morceaux de manière asynchrone, ce qui peut être utile pour traiter de grandes sorties ou des données de streaming dans un contexte asynchrone.
Exemple:
import { decodeAsyncGenerator } from 'gpt-tokenizer'
async function processTokens ( asyncTokensIterator ) {
let decodedText = ''
for await ( const textChunk of decodeAsyncGenerator ( asyncTokensIterator ) ) {
decodedText += textChunk
}
} Il y a quelques jetons spéciaux utilisés par les modèles GPT. Tous les modèles ne prennent pas en charge tous ces jetons.
gpt-tokenizer vous permet de spécifier des ensembles personnalisés de jetons spéciaux autorisés lors du codage du texte. Pour ce faire, passez un Set contenant les jetons spéciaux autorisés comme paramètre à la fonction encode :
import {
EndOfPrompt ,
EndOfText ,
FimMiddle ,
FimPrefix ,
FimSuffix ,
ImStart ,
ImEnd ,
ImSep ,
encode ,
} from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfPrompt } `
const allowedSpecialTokens = new Set ( [ EndOfPrompt ] )
const encoded = encode ( inputText , allowedSpecialTokens )
const expectedEncoded = [ 8538 , 2991 , 220 , 100276 ]
expect ( encoded ) . toBe ( expectedEncoded ) De même, vous pouvez spécifier des ensembles personnalisés de jetons spéciaux refusés lors du codage du texte. Passez un Set contenant les jetons spéciaux refusés comme paramètre à la fonction encode :
import { encode , EndOfText } from 'gpt-tokenizer'
const inputText = `Some Text ${ EndOfText } `
const disallowedSpecial = new Set ( [ EndOfText ] )
// throws an error:
const encoded = encode ( inputText , undefined , disallowedSpecial )Dans cet exemple, une erreur est lancée, car le texte d'entrée contient un jeton spécial refusé.
gpt-tokenizer comprend un ensemble de cas de test dans le fichier TestPlans.txt pour assurer sa compatibilité avec la bibliothèque Python tiktoken d'Openai. Ces cas de test valident la fonctionnalité et le comportement de gpt-tokenizer , fournissant une référence fiable pour les développeurs.
L'exécution des tests unitaires et la vérification des cas de test aident à maintenir la cohérence entre la bibliothèque et l'implémentation Python d'origine.
gpt-tokenizer fournit des données complètes sur tous les modèles OpenAI via l'exportation des models à partir de gpt-tokenizer/models . Cela comprend des informations détaillées sur les fenêtres de contexte, les coûts, les coupures de données de formation et l'état de dépréciation.
Les données sont régulièrement maintenues pour correspondre à la documentation officielle d'OpenAI. Les contributions pour maintenir ces données à jour sont les bienvenues - si vous remarquez des écarts ou que vous avez des mises à jour, n'hésitez pas à ouvrir un RP.
Depuis la version 2.4.0, gpt-tokenizer est l'implémentation de tokenizer la plus rapide disponible sur NPM. Il est encore plus rapide que les implémentations de liaison WasM / Node disponibles. Il a le codage le plus rapide, le décodage et une minuscule empreinte mémoire. Il initialise également plus rapidement que toutes les autres implémentations.
Les encodages eux-mêmes sont également de la plus petite taille, en raison du format compact dans lequel ils sont stockés.
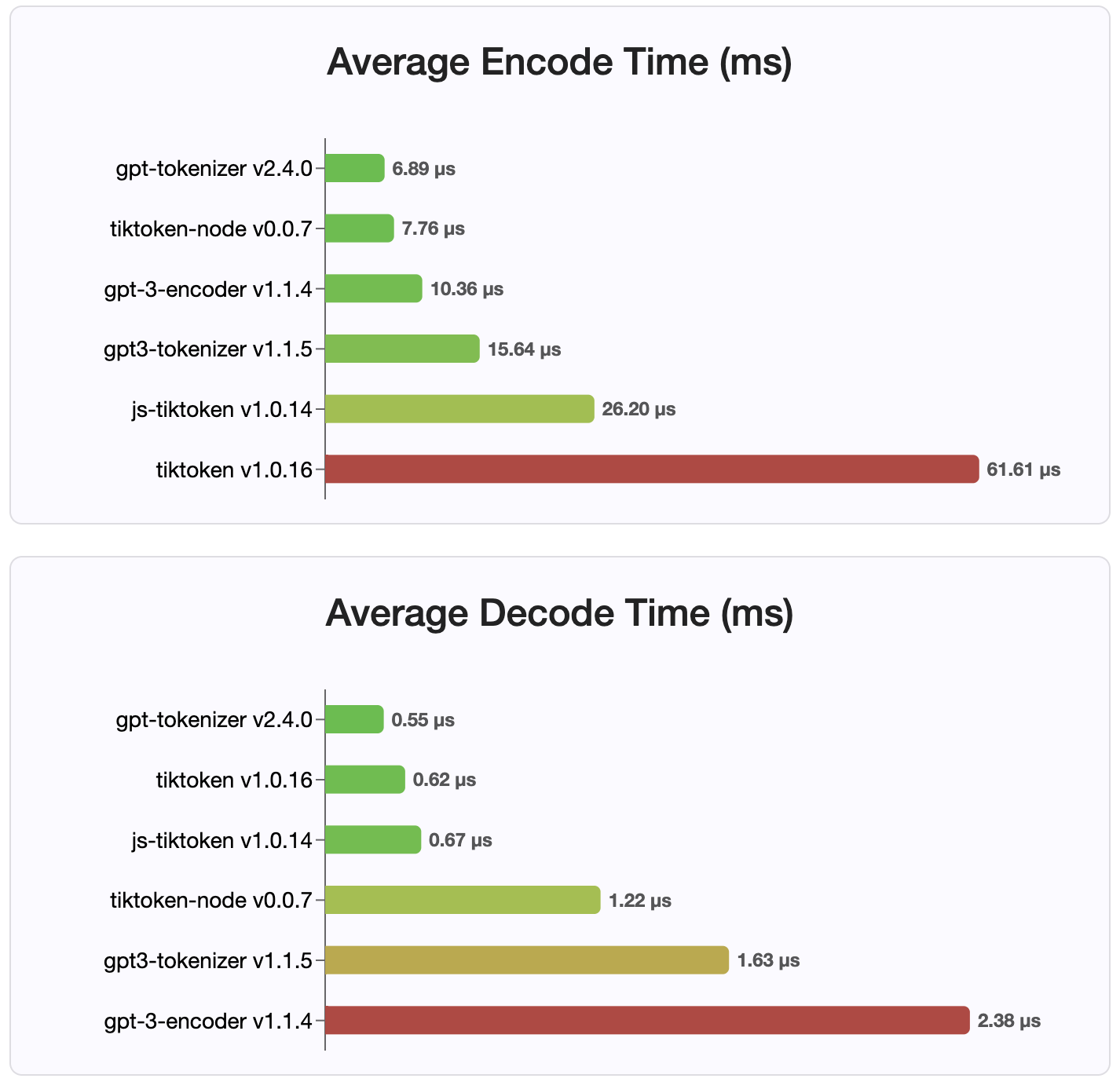
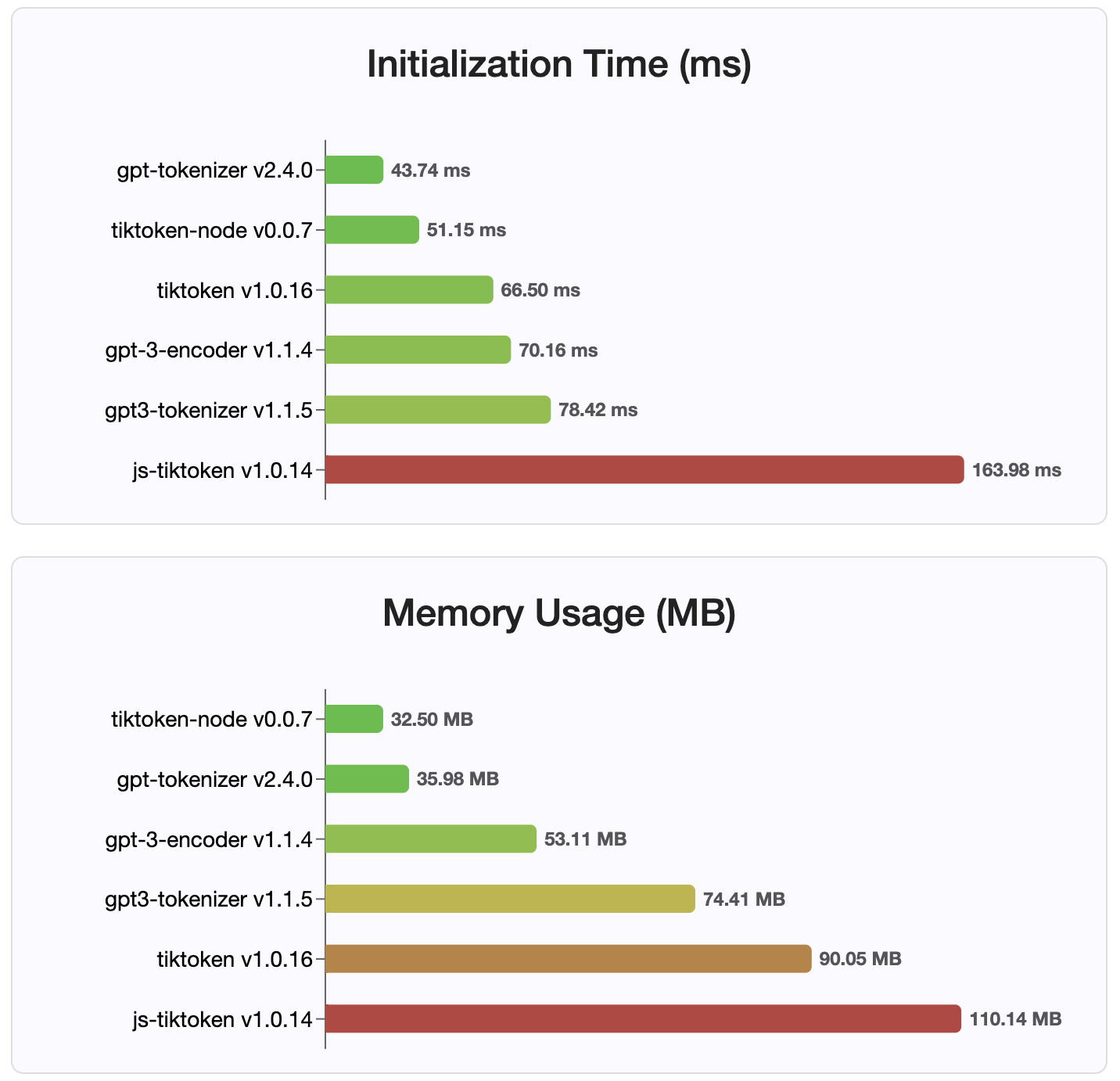
Mit
Les contributions sont les bienvenues! Veuillez ouvrir une demande de traction ou un problème pour discuter de vos rapports de bogues, ou utilisez la fonction de discussion pour des idées ou toute autre demande.
Merci à Sharptoken de @ Dmitry-Brazhenko, dont le code a été servi de référence pour le port.
J'espère que vous trouverez le gpt-tokenizer utile dans vos projets!


