Text generation task and language model GPT2
1.0.0
Первая часть этого резюме бассейна ресурсов Ресурсы, используемые для решения задач генерации текста с использованием языковой модели GPT2, включая документы, код, демонстрационные демонстрации и практические учебные пособия. Вторая часть показывает применение GPT2 в задачах генерации текста машинного перевода, автоматического генерации резюме, миграционного обучения и генерации музыки. Наконец, сравниваются 15 основных языковых моделей, основанных на трансформаторе между 2018 и 2019 годами.
Первая часть этого сбора ресурсов суммирует ресурсы, используемые для решения задач генерации текста с использованием языковой модели GPT2, включая документы, код, демонстрации презентаций и практические уроки. Вторая часть показывает применение GPT2 в задачах генерации текста, таких как машинный перевод, автоматическое генерацию резюме, обучение передачи и поколение музыки. Наконец, мы сравниваем важные 15 языковых моделей, основанных на Transformer с 2018 по 2019 год.
GPT-2-это крупная языковая модель, основанная на трансформаторах, выпущенную OpenAI в феврале 2019 года. Он содержит 1,5 миллиарда параметров и обучается на 8 миллионов веб-данных. Согласно отчетам, модель представляет собой прямое расширение модели GPT, обучение более чем в 10 раз превышает объем данных, количество параметров также в 10 раз больше. С точки зрения производительности, модель способна создавать координатные текстовые абзацы и достигать производительности SOTA на многих эталонных показателях языкового моделирования. Кроме того, модель может выполнять предварительное понимание прочитанного, машинного перевода, вопросов и ответов и автоматического резюме без обучения по конкретной задаче.
GPT-2-это крупная языковая модель, основанная на трансформаторах, выпущенную OpenAI в феврале 2019 года. Он содержит 1,5 миллиарда параметров и обучается на 8-миллионном наборе данных веб-страницы. Согласно отчетам, эта модель представляет собой прямое расширение модели GPT, обучаемое более чем в 10 раз больше объема данных, а количество параметров в 10 раз больше. С точки зрения производительности, модель способна создавать последовательные текстовые абзацы и достигать производительности SOTA на многих эталонных показателях языкового моделирования. Более того, модель может достичь предварительного понимания прочитанного, машинного перевода, вопросов и ответов и автоматического резюме без обучения по конкретной задаче.
Демонстрация GPT-2_explorer. Он может дать следующие десять слов ранжирования возможностей и их соответствующих вероятностей в соответствии с в настоящее время входным текстом. Вы можете выбрать одно из слов, затем увидеть список следующего возможного слова, и так далее, и, наконец, заполнить его. Статья.
Демонстрация GPT-2_explorer Он может дать ведущую десятку следующих слов в возможном диапазоне и его соответствующую вероятность на основе введенного введенного введенного текста. Вы можете выбрать одно из слов и увидеть список следующих возможных слов. Это будет повторяться снова и снова и, наконец, завершить статью.
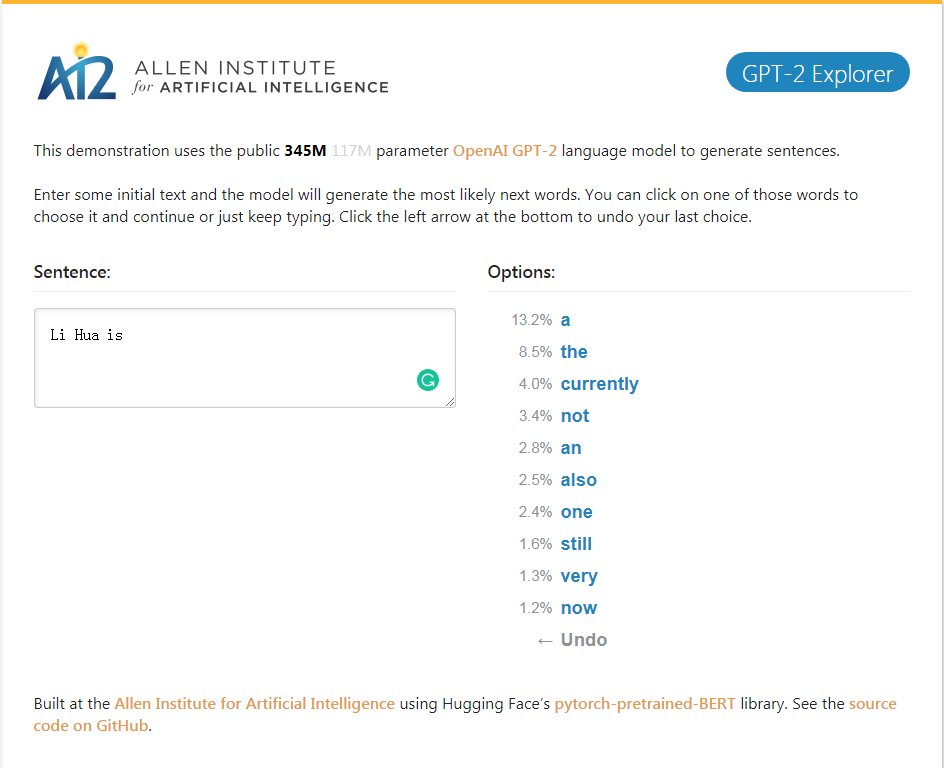
Нажмите на демонстрацию GPT-2 Explorer
GPT-2-Simple Python Package, чтобы легко переучить модель GPT-2 GPT-2 в новых текстах.
Пакет GPT-2-Simple Python может легко перепрофировать модель генерации текста GPT-2 OpenAI в новом тексту.
Демонстрация GPT-2-Simple пишет последующую историю, основанную на текущем входном тексту. Демонстрация GPT-2-Simple пишет последующую историю, основанную на текущем входном тексту.
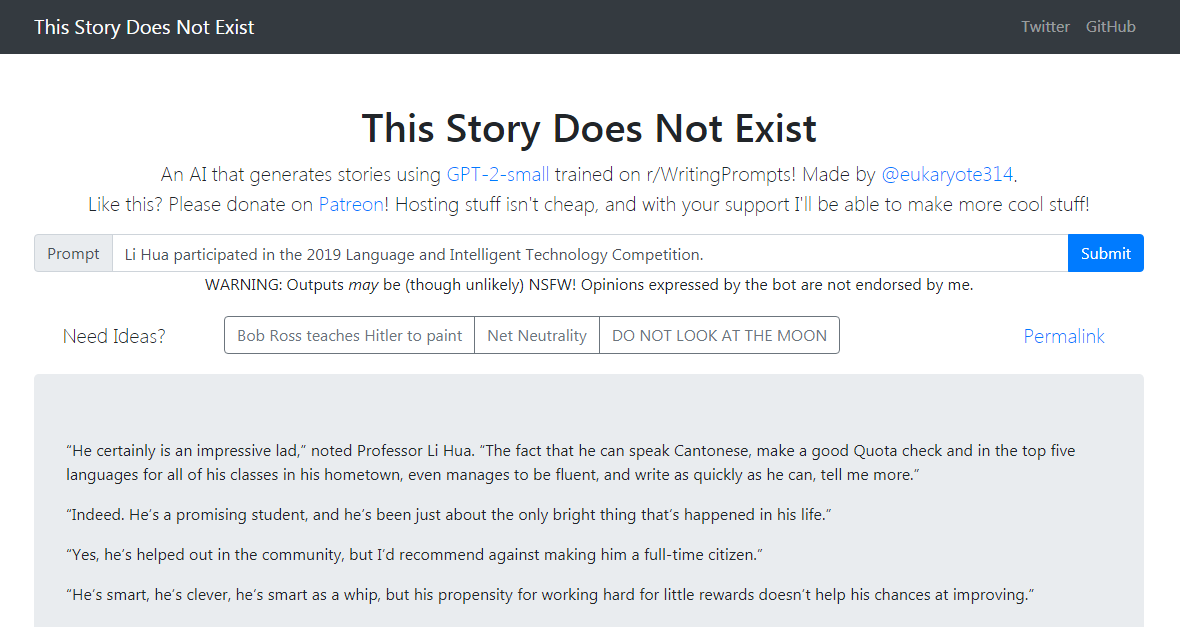
Нажмите, чтобы испытать нажмите на демонстрацию GPT-2-Simple
Гровер - это модель для нейронных фальшивых новостей - как поколения, так и обнаружения. Гровер - это модель для нейронных фальшивых новостей - поколение и обнаружение.
Генерировать статьи на основе информации, такой как название, автор и многое другое. Гровер также может обнаружить, если текст генерируется машиной.
Генерировать статьи на основе названия, автора и другой информации. Гровер также может определить, генерируется ли текст машиной.
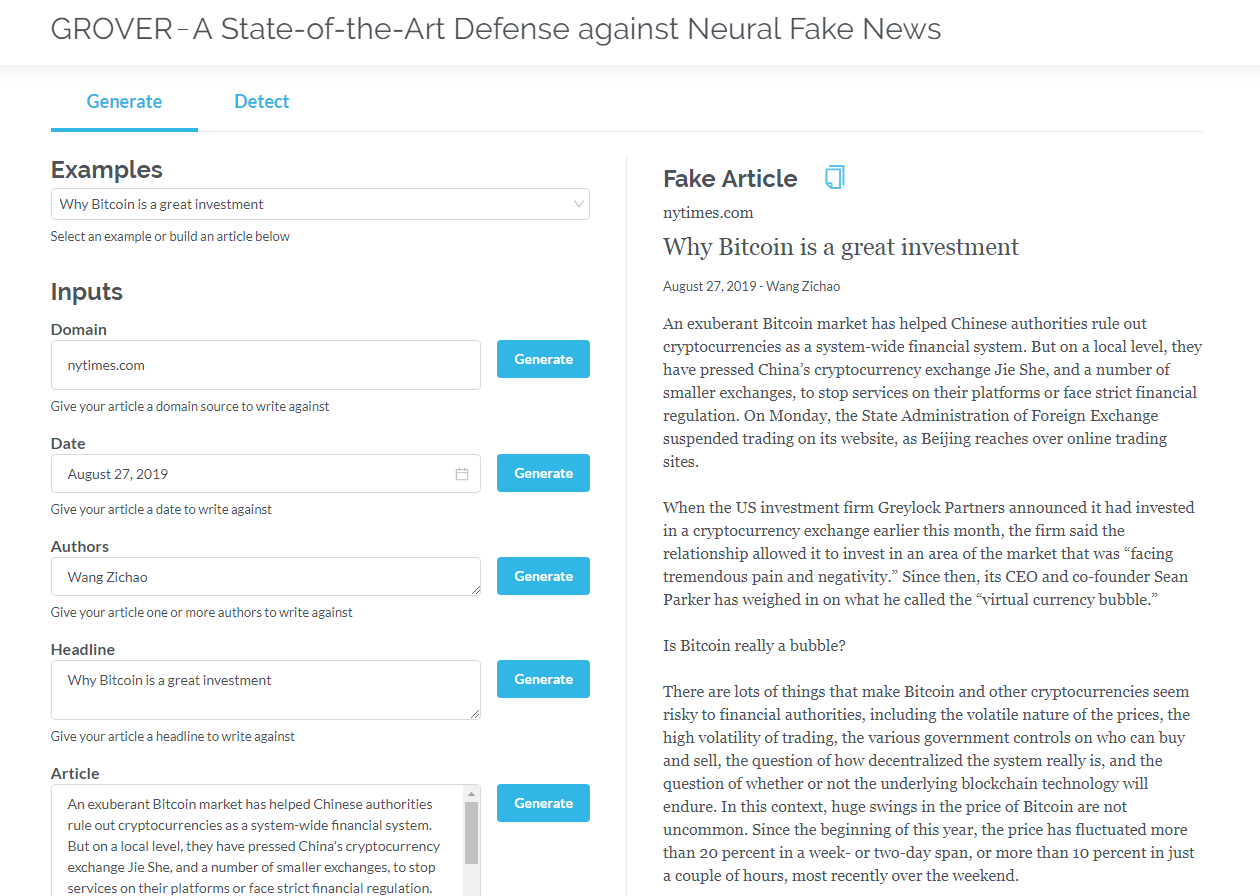
Нажмите на Гровер
Нажмите, чтобы прочитать английскую версию
Трансформаторы, которые содержат только декодеры (такие как GPT2), постоянно показывают перспективы приложений вне языка моделирования. Во многих приложениях такие модели были успешными: машинный перевод, автоматическое генерацию резюме, обучение передачи и поколение музыки. Давайте рассмотрим некоторые из этих приложений вместе.
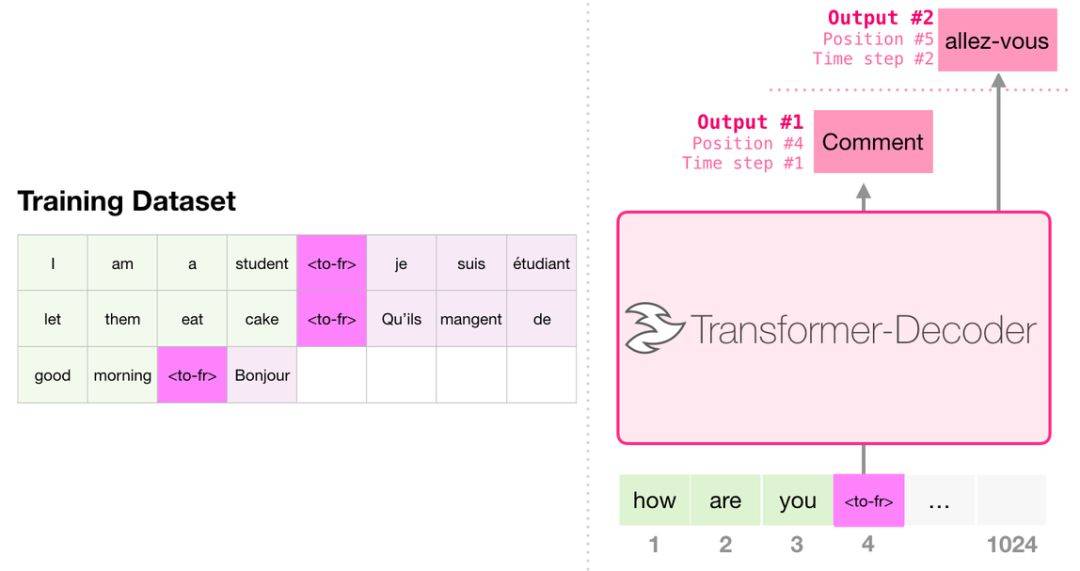
При переводе модель не требует энкодера. Та же задача может быть решена трансформатором только с декодером:
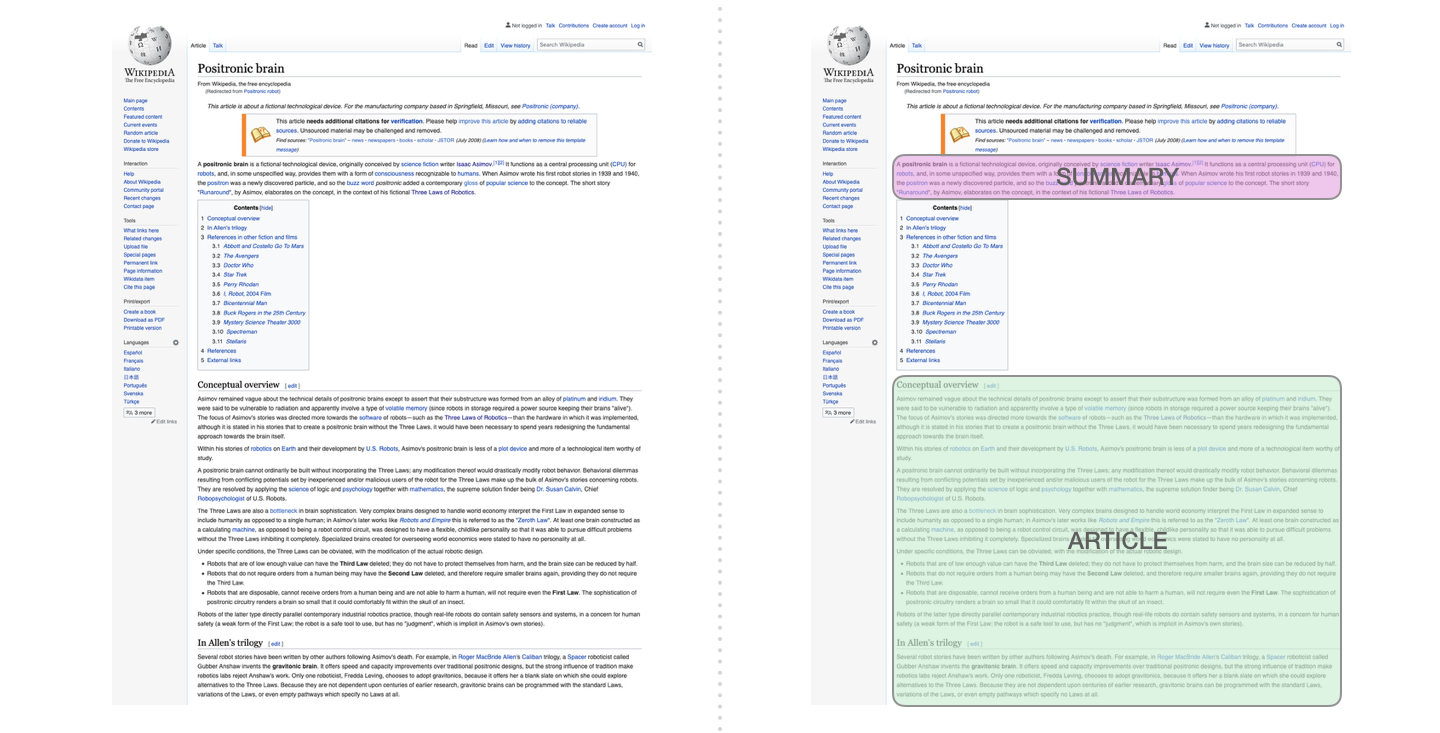
Это первая задача, чтобы обучить трансформатор, который содержит только декодер. То есть модель обучена читать статьи Википедии (без начала каталога), а затем генерировать резюме. Фактическое начало статьи используется в качестве ярлыка для обучающего набора данных:
В статье используются статьи в Википедии для обучения модели, а обученная модель может генерировать реферат статьи:
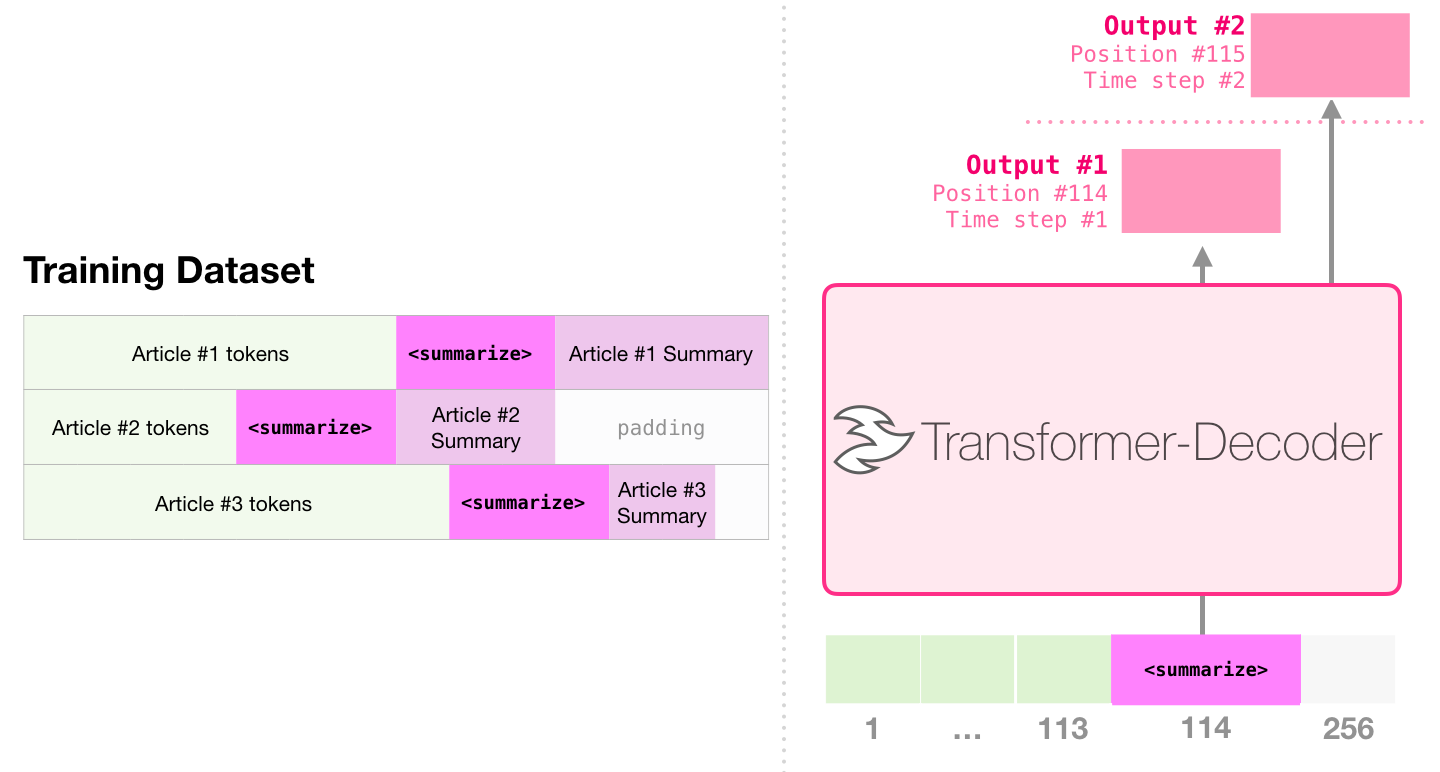
В образце бумаги эффективная суммирование текста с использованием одного предварительно обученного трансформатора первое предварительное обучение выполняется в задаче по моделированию языка с использованием трансформаторов, которые содержат только декодеры, а затем задача резюме генерации выполняется через настройку. Результаты показывают, что в случае ограниченных данных эта схема достигает лучших результатов, чем предварительно предварительно проведенный трансформатор-энкодер-декодер. В документе GPT2 также демонстрируется эффект генерации абстрактного генерации, полученный после предварительного обучения модели языкового моделирования.
Music Transformer использует трансформаторы, которые содержат только декодеры для создания музыки с богатым ритмом и динамикой. Подобно языковому моделированию, «моделирование музыки» состоит в том, чтобы позволить модели изучать музыку без присмотра, а затем позволить ей выводить выборы (мы ранее называли «случайная работа»).
GPT2-это просто капля в океане моделей на основе трансформатора. Для сравнения 15 важных моделей, основанных на трансформаторах с 2018 по 2019 год, пожалуйста, обратитесь к эре после Берта: сравнительный анализ 15 предварительно обученных моделей и разведку ключевых моментов.