Text generation task and language model GPT2
1.0.0
이 리소스 풀의 첫 번째 부분은 논문, 코드, 데모 데모 및 실습 자습서를 포함하여 언어 모델 GPT2를 사용하여 텍스트 생성 작업을 해결하는 데 사용되는 리소스를 요약합니다. 두 번째 부분은 기계 번역, 자동 요약 생성, 마이그레이션 학습 및 음악 생성의 텍스트 생성 작업에서 GPT2의 적용을 보여줍니다. 마지막으로, 2018 년에서 2019 년 사이의 변압기를 기반으로 한 15 개의 주요 언어 모델이 비교됩니다.
이 리소스 컬렉션의 첫 번째 부분에는 논문, 코드, 프레젠테이션 데모 및 실습 자습서를 포함하여 언어 모델 GPT2를 사용하여 텍스트 생성 작업을 해결하는 데 사용되는 리소스가 요약되어 있습니다. 두 번째 부분은 기계 번역, 자동 요약 생성, 전송 학습 및 음악 생성과 같은 텍스트 생성 작업에서 GPT2의 적용을 보여줍니다. 마지막으로 2018 년부터 2019 년까지 변압기를 기반으로 한 중요한 15 개의 언어 모델을 비교합니다.
GPT-2는 2019 년 2 월 OpenAI에서 출시 된 대규모 변압기 기반 언어 모델이며 15 억 개의 매개 변수가 포함되어 있으며 8 백만 개의 웹 데이터 세트에서 교육을 받았습니다. 보고서에 따르면이 모델은 GPT 모델의 직접 확장으로 데이터 양의 10 배 이상에 대한 교육이며 매개 변수 금액도 10 배 더 많습니다. 성능 측면 에서이 모델은 좌표 텍스트 단락을 생성 할 수 있으며 많은 언어 모델링 벤치 마크에서 SOTA 성능을 달성 할 수 있습니다. 또한이 모델은 작업 별 교육없이 예비 독해, 기계 번역, 질문 및 답변 및 자동 요약을 수행 할 수 있습니다.
GPT-2는 2019 년 2 월 OpenAI에서 출시 된 대규모 변압기 기반 언어 모델이며 15 억 개의 매개 변수가 포함되어 있으며 8 백만 개의 웹 페이지 데이터 세트에서 교육을 받았습니다. 보고서에 따르면,이 모델은 GPT 모델의 직접 확장이며 데이터 양의 10 배 이상에 대해 교육을 받았으며 매개 변수 수는 10 배 더 많습니다. 성능 측면 에서이 모델은 일관된 텍스트 단락을 생성 할 수 있으며 많은 언어 모델링 벤치 마크에서 SOTA 성능을 달성 할 수 있습니다. 또한이 모델은 작업 별 교육없이 예비 독해, 기계 번역, 질문 및 답변 및 자동 요약을 달성 할 수 있습니다.
GPT-2_Explorer 데모 현재 입력 텍스트에 따라 가능성 순위와 해당 확률의 다음 10 단어를 제공 할 수 있습니다. 단어 중 하나를 선택한 다음 다음 단어 목록 등을보고 마침내 하나를 완성 할 수 있습니다. 기사.
GPT-2_Explorer 데모는 가능한 범위에서 상위 10 개의 다음 단어와 현재 입력 한 텍스트를 기반으로 해당 확률을 제공 할 수 있습니다. 단어 중 하나를 선택하고 다음 가능한 단어 목록을 볼 수 있습니다. 이것은 반복해서 반복되고 마지막으로 기사를 완성합니다.
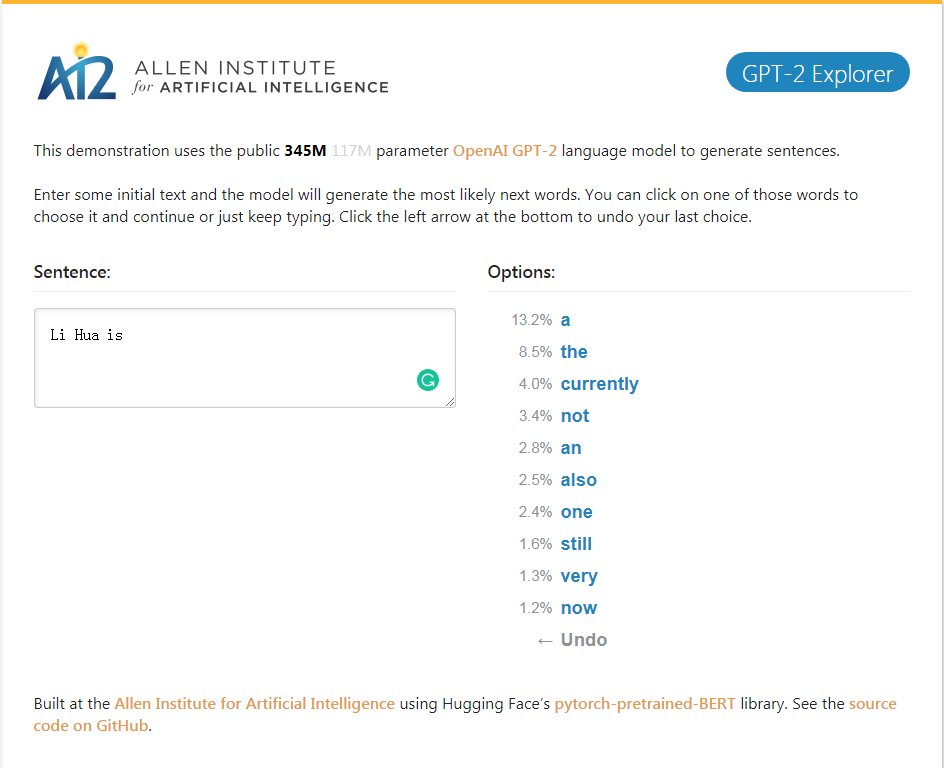
GPT-2 탐색기 데모를 클릭하십시오
새로운 텍스트에서 OpenAi의 GPT-2 텍스트 생성 모델을 쉽게 재교육하기위한 GPT-2- 단순한 파이썬 패키지.
GPT-2-Simple Python 패키지는 새로운 텍스트에서 OpenAi의 GPT-2 텍스트 생성 모델을 쉽게 재교육 할 수 있습니다.
GPT-2-Simple Demo는 현재 입력 텍스트를 기반으로 후속 스토리를 씁니다. GPT-2-Simple Demo는 현재 입력 텍스트를 기반으로 후속 스토리를 씁니다.
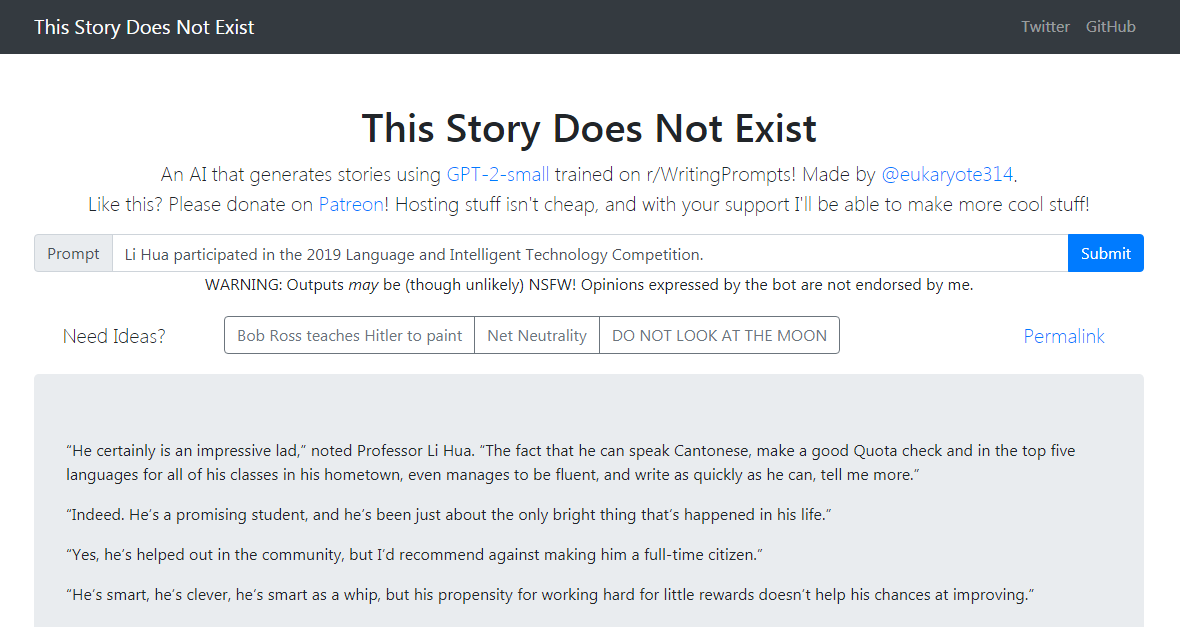
클릭하려면 클릭하여 GPT-2- 단순 데모를 클릭하십시오
Grover는 세대와 탐지 모두 신경 가짜 뉴스의 모델입니다. Grover는 신경 가짜 뉴스 - 세대 및 탐지 모델입니다.
제목, 저자 등과 같은 정보를 기반으로 기사를 생성하십시오. Grover는 또한 텍스트가 기계에서 생성되는지 감지 할 수 있습니다.
제목, 저자 및 기타 정보를 기반으로 기사를 생성합니다. Grover는 또한 텍스트가 기계에서 생성되는지 여부를 감지 할 수 있습니다.
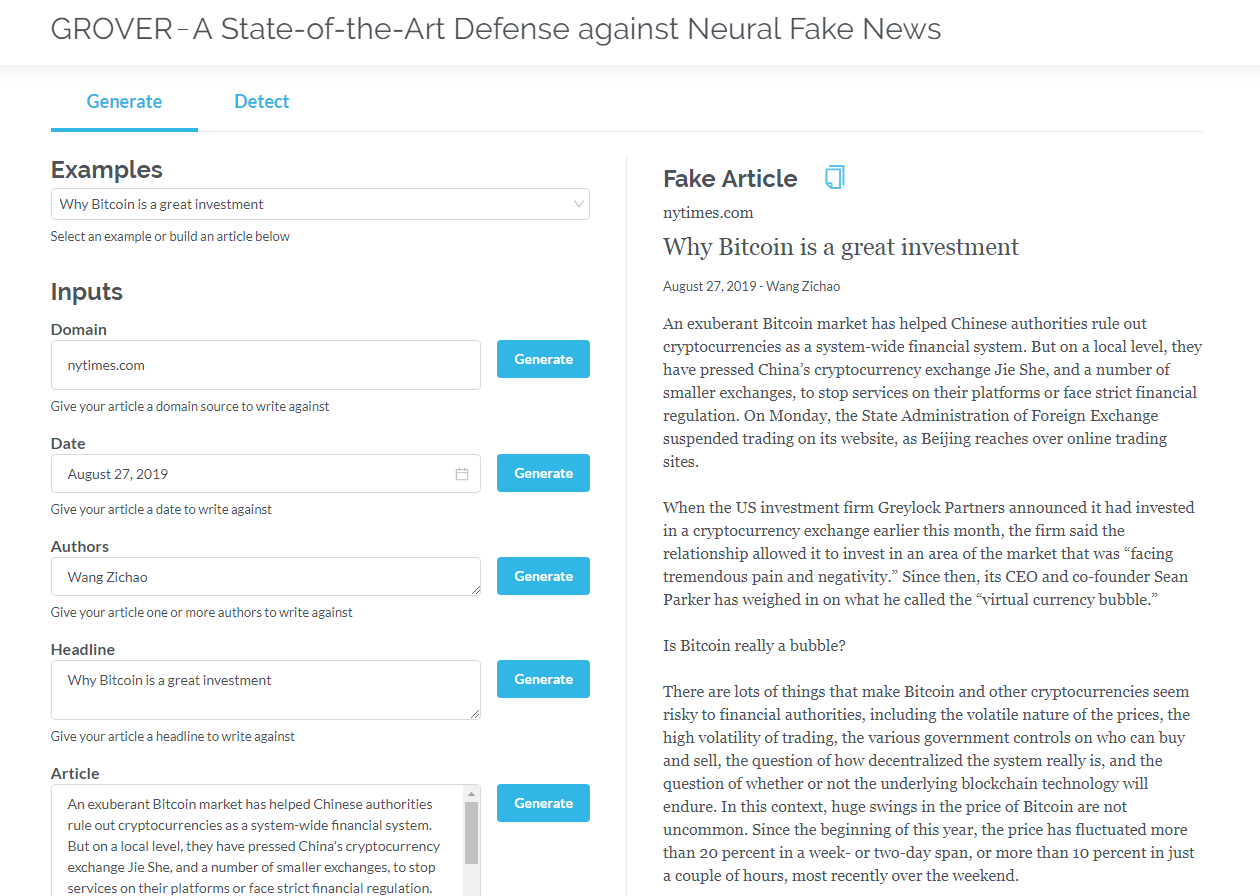
그로버를 클릭하십시오
영어 버전을 읽으려면 클릭하십시오
디코더 (예 : GPT2) 만 포함하는 변압기는 외부 언어 모델링 외부의 응용 프로그램 전망을 지속적으로 보여줍니다. 많은 응용 분야에서 이러한 모델은 기계 번역, 자동 요약 생성, 전송 학습 및 음악 생성과 같은 성공적이었습니다. 이러한 응용 프로그램 중 일부를 함께 검토합시다.
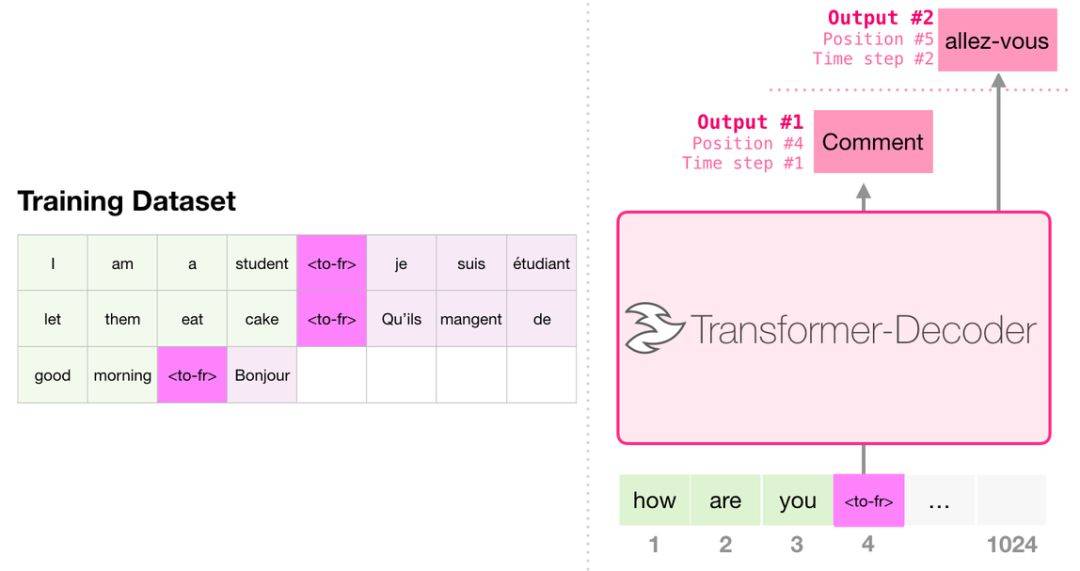
번역 할 때 모델에는 인코더가 필요하지 않습니다. 디코더 만있는 변압기에서 동일한 작업을 해결할 수 있습니다.
이것은 디코더 만 포함하는 변압기를 훈련시키는 첫 번째 작업입니다. 즉,이 모델은 디렉토리의 시작이없는 Wikipedia 기사를 읽고 요약을 생성하도록 훈련되었습니다. 기사의 실제 시작은 훈련 데이터 세트의 레이블로 사용됩니다.
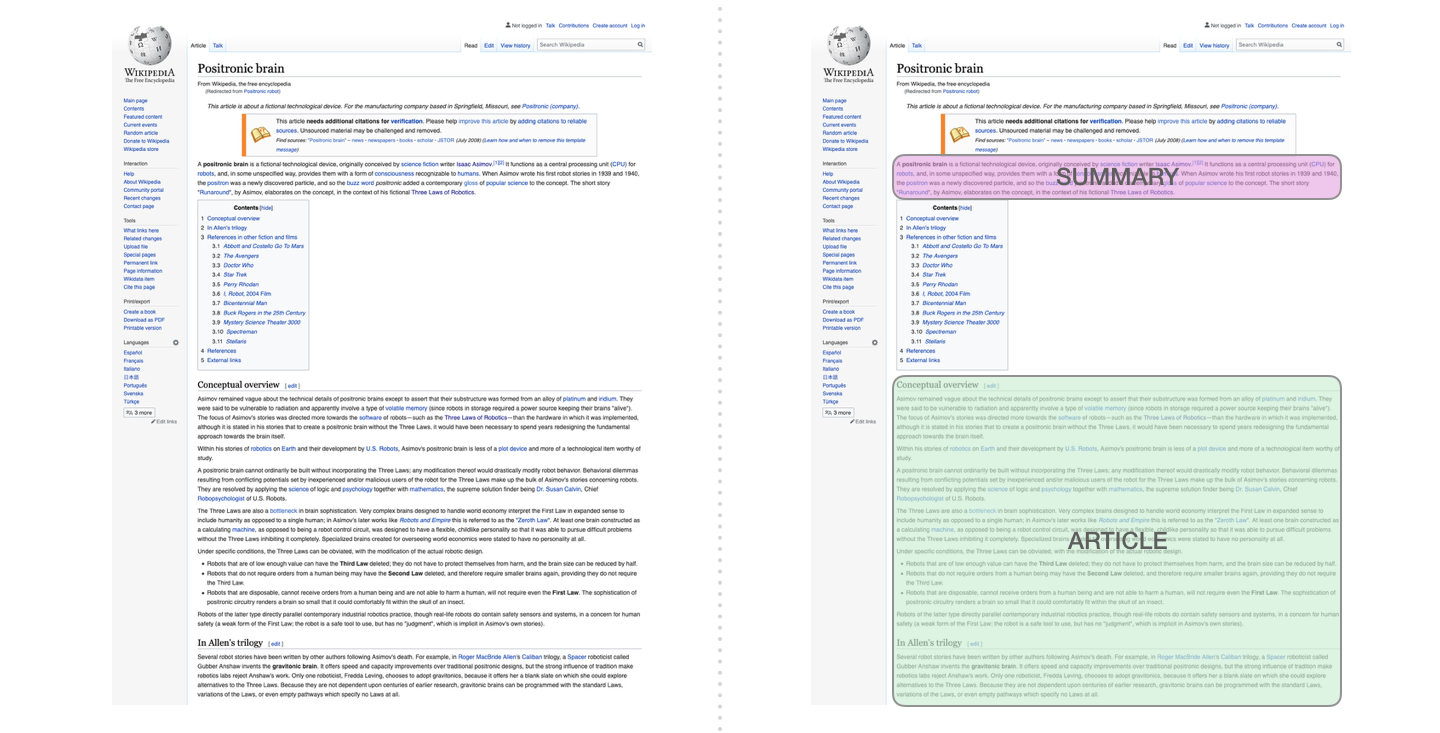
이 논문은 Wikipedia 기사를 사용하여 모델을 훈련시키고 훈련 된 모델은이 기사의 초록을 생성 할 수 있습니다.
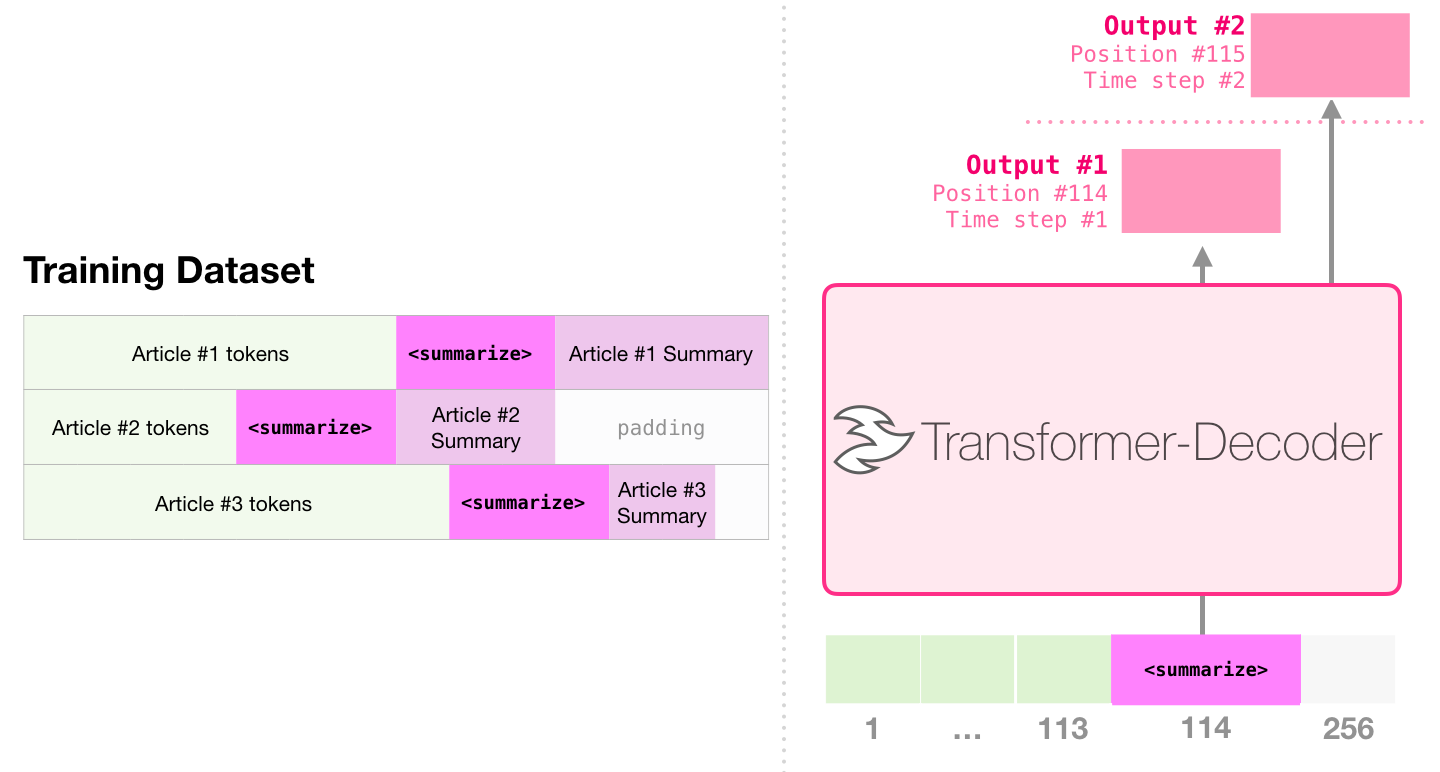
종이 샘플에서 미리 훈련 된 단일 변압기를 사용한 효율적인 텍스트 요약에서, 디코더 만 포함하는 변압기를 사용하여 언어 모델링 작업에서 첫 번째 사전 훈련이 수행 된 다음 튜닝을 통해 요약 생성 작업이 완료됩니다. 결과는 제한된 데이터의 경우,이 체계가 사전에 사전 인코더-디코더 변압기보다 더 나은 결과를 달성 함을 보여준다. GPT2의 논문은 또한 언어 모델링 모델을 사전 훈련 한 후 얻은 초록 생성 효과를 보여줍니다.
Music Transformer는 디코더 만 포함하는 변압기를 사용하여 풍부한 리듬과 역학으로 음악을 생성합니다. 언어 모델링과 마찬가지로 "음악 모델링"은 모델이 감독되지 않은 방식으로 음악을 배우게 한 다음 샘플을 출력하게하는 것입니다 (이전에는 "Random Work"라고 불림).
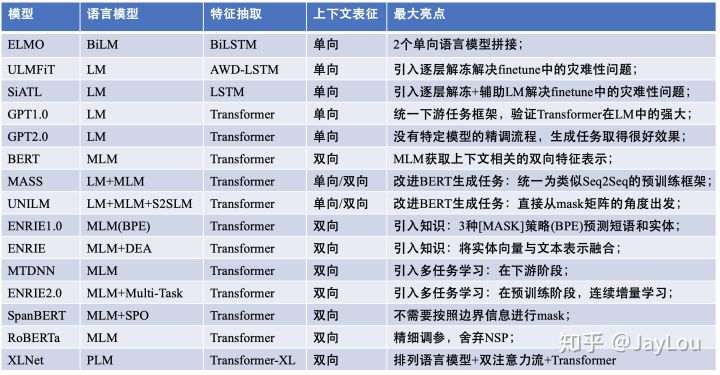
GPT2는 변압기 기반 모델의 바다가 떨어졌습니다. 2018 년부터 2019 년까지 15 개의 중요한 변압기 기반 모델을 비교하려면 15 개의 미리 훈련 된 모델과 키 포인트 탐색의 비교 분석을 참조하십시오.