Text generation task and language model GPT2
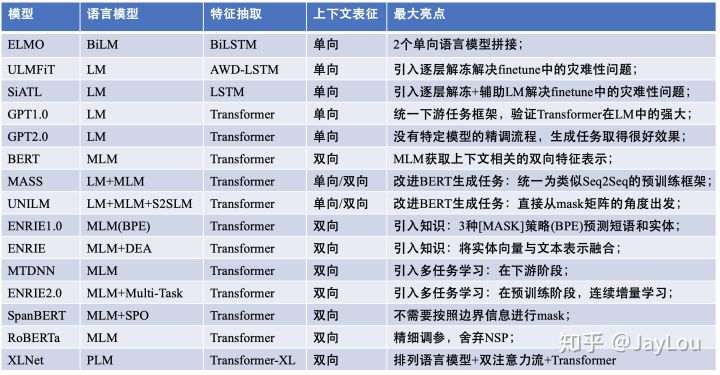
1.0.0
このリソースプールの最初の部分の概要論文、コード、デモのデモ、実践的なチュートリアルなど、言語モデルGPT2を使用してテキスト生成タスクを解決するために使用されるリソース。 2番目の部分は、機械翻訳、自動要約生成、移行学習、音楽生成のテキスト生成タスクにおけるGPT2の適用を示しています。最後に、2018年から2019年の間に変圧器に基づいた15の主要な言語モデルを比較します。
このリソースコレクションの最初の部分は、論文、コード、プレゼンテーションデモ、実践的なチュートリアルなど、言語モデルGPT2を使用してテキスト生成タスクを解決するために使用されるリソースを要約しています。 2番目の部分は、機械翻訳、自動要約生成、転送学習、音楽生成などのテキスト生成タスクでのGPT2の適用を示しています。最後に、2018年から2019年までのトランスに基づいた重要な15の言語モデルを比較します。
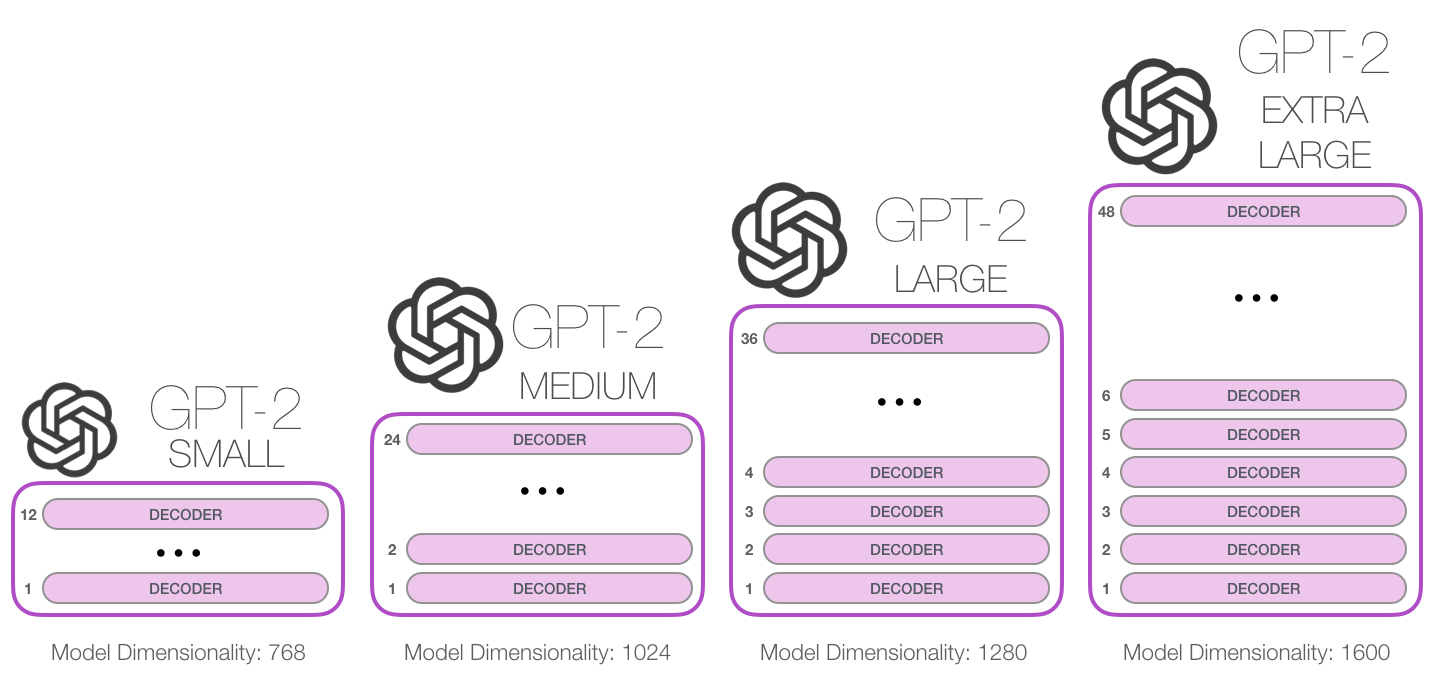
GPT-2は、2019年2月にOpenaiがリリースした大規模なトランスベースの言語モデルです。15億パラメーターが含まれており、800万のWebデータセットでトレーニングされています。報告によると、このモデルはGPTモデルの直接拡張であり、データの量の10倍以上のトレーニングであり、パラメーター量も10倍です。パフォーマンスに関しては、モデルは座標テキストの段落を作成でき、多くの言語モデリングベンチマークでSOTAパフォーマンスを実現できます。さらに、このモデルは、タスク固有のトレーニングなしで、予備的な読解、機械翻訳、質問、回答、自動要約を実行できます。
GPT-2は、2019年2月にOpenaiがリリースした大規模な変圧器ベースの言語モデルです。15億パラメーターが含まれており、800万個のWebページデータセットでトレーニングされています。報告によると、このモデルはGPTモデルの直接拡張であり、データの量の10倍以上でトレーニングされており、パラメーターの数は10倍です。パフォーマンスに関しては、モデルは一貫したテキスト段落を作成し、多くの言語モデリングベンチマークでSOTAパフォーマンスを実現できます。さらに、このモデルは、タスク固有のトレーニングなしで、予備的な読解、機械翻訳、質疑応答、自動要約を実現できます。
gpt-2_explorerデモは、現在の入力テキストに従って、可能性のランキングとそれらの対応する確率の次の10語を与えることができます。単語のいずれかを選択し、次に可能な単語のリストを表示し、最後に完了することができます。記事。
gpt-2_explorerデモ可能な範囲のトップ10の次の単語と、現在入力されているテキストに基づいて対応する確率を与えることができます。単語の1つを選択して、次の可能な単語のリストを表示できます。これは何度も繰り返され、最終的に記事を記入します。
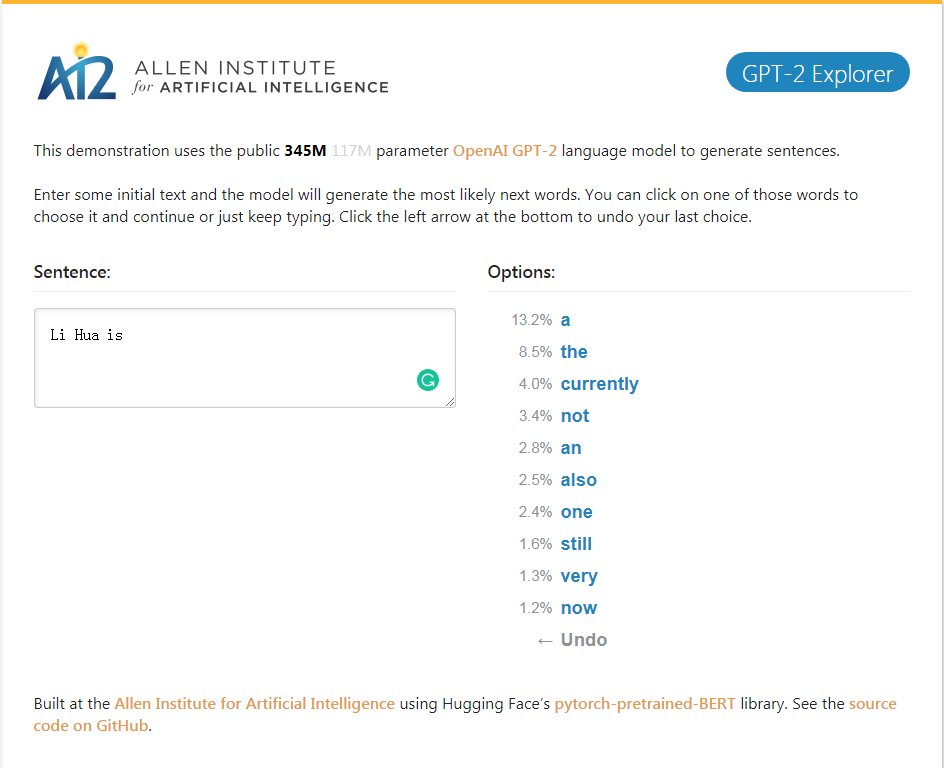
クリックしてGPT-2エクスプローラーデモ
GPT-2-シンプルPythonパッケージ新しいテキストでOpenaiのGPT-2テキスト生成モデルを簡単に再訓練します。
GPT-2-Simple Pythonパッケージは、新しいテキストでOpenaiのGPT-2テキスト生成モデルを簡単に再編成できます。
GPT-2-Simple Demoは、現在の入力テキストに基づいてフォローアップストーリーを書きます。 GPT-2-Simple Demoは、現在の入力テキストに基づいてフォローアップストーリーを書きます。
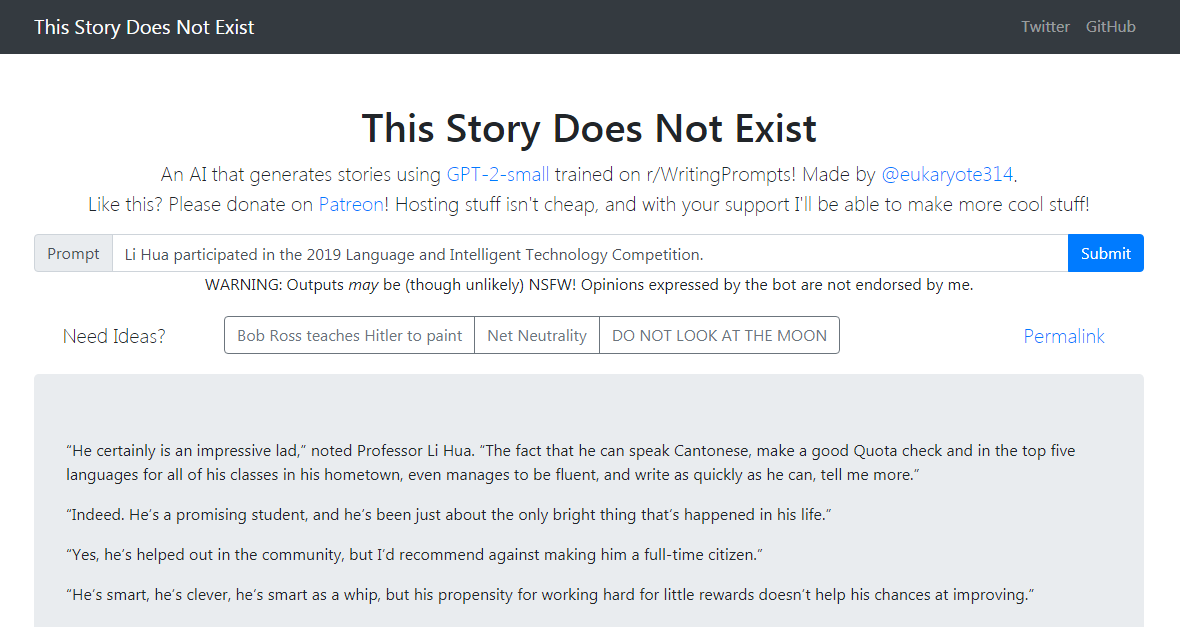
クリックしてクリックして、GPT-2-シンプルデモをクリックします
グローバーは、神経の偽のニュースのモデルであり、生成と検出の両方です。グローバーは、ニューラルフェイクニュース - 生成と検出のモデルです。
タイトル、著者などの情報に基づいて記事を生成します。グローバーは、マシンによってテキストが生成されたかどうかを検出することもできます。
タイトル、著者、その他の情報に基づいて記事を生成します。グローバーは、マシンによってテキストが生成されるかどうかを検出することもできます。
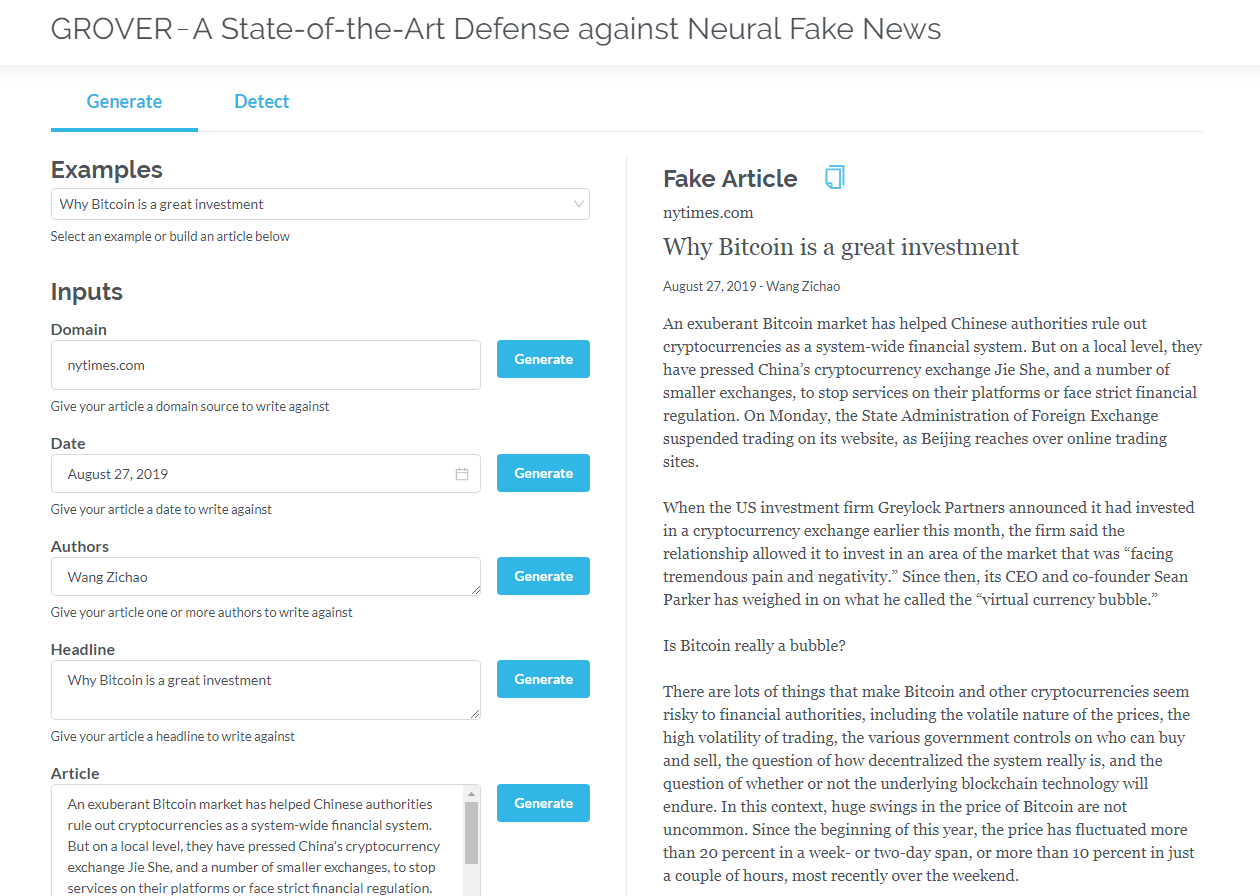
クリックしてグローバーをクリックします
クリックして英語版を読みます
デコーダーのみを含む変圧器(GPT2など)は、言語モデリング以外のアプリケーションの見通しを常に示しています。多くのアプリケーションでは、そのようなモデルが成功しています:機械翻訳、自動要約生成、転送学習、音楽生成。これらのアプリケーションのいくつかを一緒に確認しましょう。
翻訳するとき、モデルはエンコーダーを必要としません。同じタスクは、デコーダーのみを備えたトランスで解決できます。
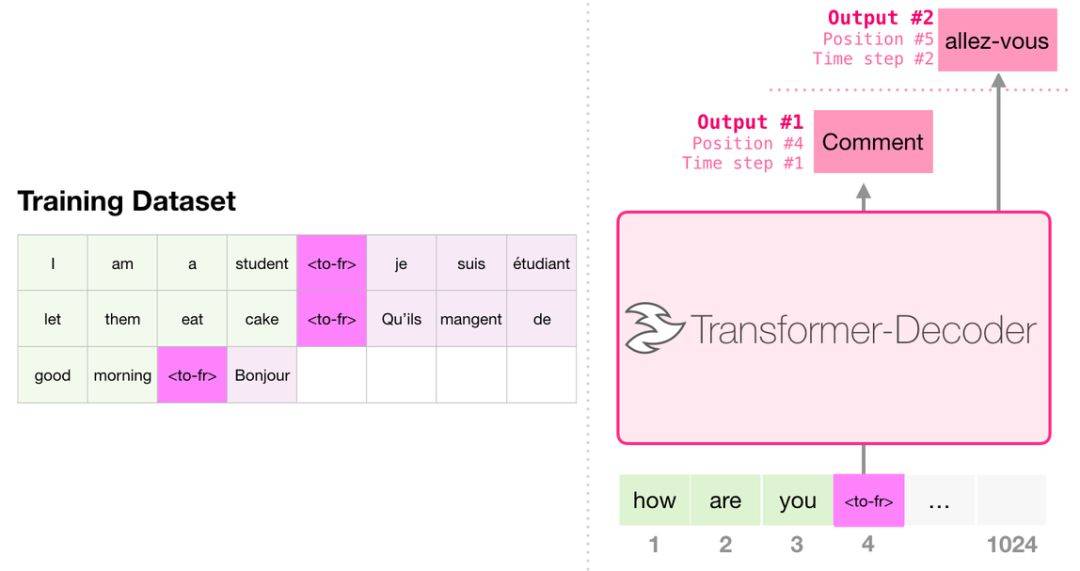
これは、デコーダーのみを含むトランスを訓練する最初のタスクです。つまり、モデルはウィキペディアの記事を読むようにトレーニングされており(ディレクトリの開始なし)、概要を生成します。記事の実際の始まりは、トレーニングデータセットのラベルとして使用されます。
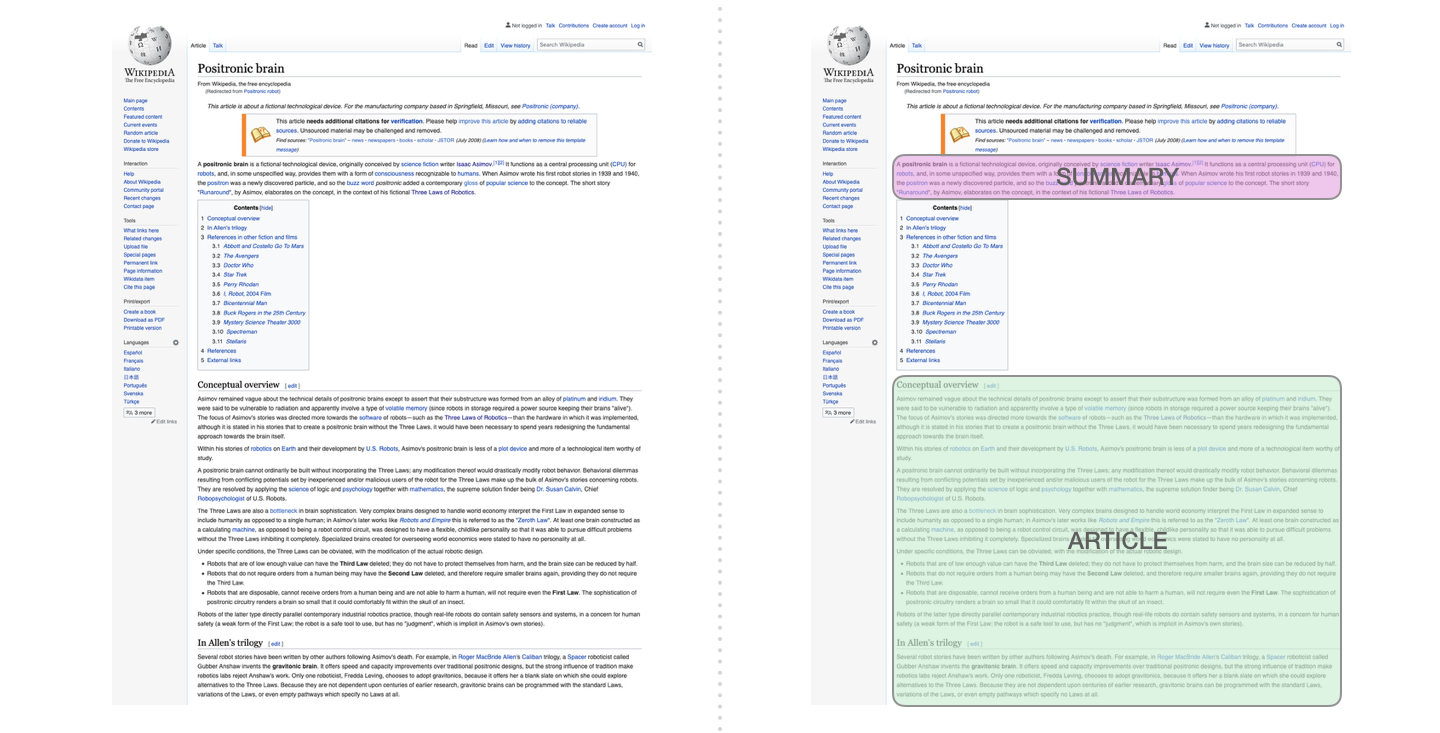
この論文では、ウィキペディアの記事を使用してモデルを訓練し、訓練されたモデルは記事の要約を生成できます。
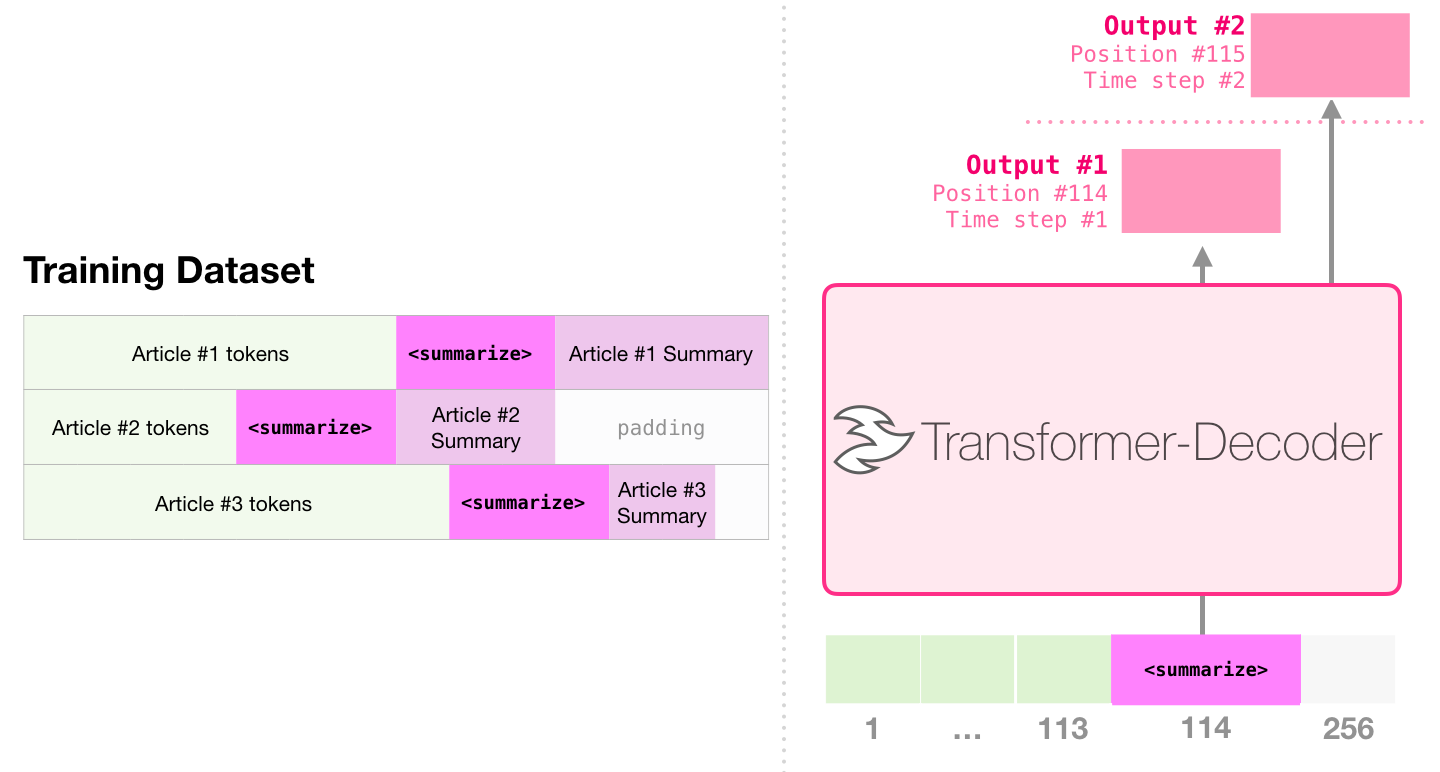
ペーパーサンプルでは、単一の事前訓練を受けたトランスを使用した効率的なテキスト要約では、最初にデコーダーを含むトランスを使用して言語モデリングタスクで最初に実行され、その後、概要生成タスクはチューニングを通じて完了します。結果は、限られたデータの場合、このスキームは、前処理されたエンコーダーデコーダートランスよりも優れた結果を達成することを示しています。 GPT2の論文は、言語モデリングモデルを事前にトレーニングした後に得られた抽象的な生成効果も示しています。
Music Transformerは、デコーダーのみを含むトランスを使用して、リッチリズムとダイナミクスを備えた音楽を生成します。言語モデリングと同様に、「音楽モデリング」とは、モデルに監視なしの方法で音楽を学習させ、サンプルを出力させることです(以前は「ランダムワーク」と呼ばれます)。
GPT2は、変圧器ベースのモデルの海の単なる低下です。 2018年から2019年までの15の重要な変圧器ベースのモデルの比較については、ポストバート時代:15の事前訓練モデルとキーポイント探索の比較分析を参照してください。