SHARK Studio
nod.ai SHARK 20240531.1300
Высокое распространение машинного обучения
В настоящее время мы восстанавливаем акулу, чтобы воспользоваться турбиной. Пока это не будет завершено, убедитесь, что вы используете выпуск SHARK-1.0
Другие пользователи, пожалуйста, убедитесь, что у вас есть последние драйверы поставщиков и Vulkan SDK отсюда, и если вы используете Vulkan Check vulkaninfo работает в окне терминала
Установите драйвер из (предпосылки)
Загрузите стабильный релиз или самый последний предварительный релиз Shark 1.0.
Дважды нажмите.
Если у вас есть пользовательские модели, поместите их в models/ каталог, где находится .exe.
Наслаждаться.
cd ) в папку .exe. Затем запустите EXE из командной строки. Таким образом, если произойдет ошибка, вы сможете вырезать и вставлять ее, чтобы попросить о помощи. (Если это всегда работает для вас без ошибок, вы можете просто дважды щелкнуть EXE)--ui=web -команды -при запуске EXE. git clone https://github.com/nod-ai/SHARK.git
cd SHARK В настоящее время акула перестраивается для турбины на main ветви. На данный момент вы не поощряете использования main , если вы не работаете над усилиями по восстановлению, и не должны ожидать, что код там будет создавать рабочее приложение для генерации изображений, поэтому вам нужно переключиться на ветвь SHARK-1.0 и использовать стабильный код.
git checkout SHARK-1.0Следующие инструкции по настройке предполагают, что вы находитесь в этой ветке.
set-executionpolicy remotesigned. / setup_venv.ps1 # You can re-run this script to get the latest version./setup_venv.sh
source shark1.venv/bin/activate(shark1.venv) PS C:gshark > cd .appsstable_diffusionweb
(shark1.venv) PS C:gsharkappsstable_diffusionweb > python .index.py(shark1.venv) > cd apps/stable_diffusion/web
(shark1.venv) > python index.py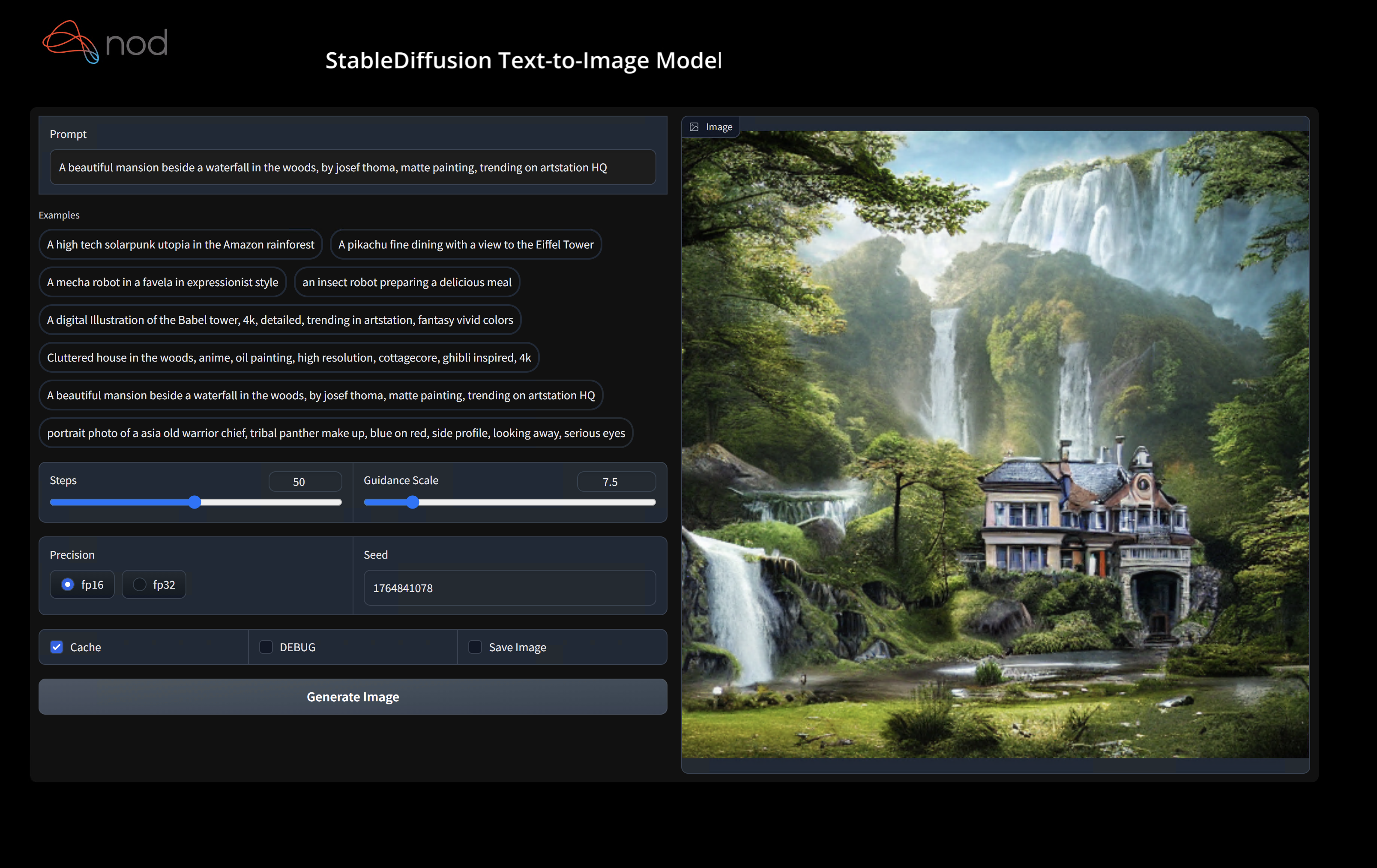
(shark1.venv) PS C:gshark > python .appsstable_diffusionscriptsmain.py -- app = " txt2img " -- precision = " fp16 " -- prompt = " tajmahal, snow, sunflowers, oil on canvas " -- device = " vulkan " python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt= " tajmahal, oil on canvas, sunflowers, 4k, uhd " Вы можете заменить vulkan на cpu для работы на процессоре или cuda для работы на устройствах CUDA. Если у вас есть несколько устройств Vulkan, вы можете обратиться к ним с помощью --device=vulkan://1 и т. Д.
Вывод на AMD 7900XTX будет выглядеть как -то вроде:
Average step time: 47.19188690185547ms/it
Clip Inference time (ms) = 109.531
VAE Inference time (ms): 78.590
Total image generation time: 2.5788655281066895secВот несколько сгенерированных образцов:


Найдите нас на сервере Shark Discord, если у вас есть какие -либо проблемы с запуском его на своем оборудовании.
Этот шаг устанавливает новый VirtualEnv для Python
python --version # Check you have 3.11 on Linux, macOS or Windows Powershell
python -m venv shark_venv
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
# If you are using conda create and activate a new conda env
# Some older pip installs may not be able to handle the recent PyTorch deps
python -m pip install --upgrade pipПользователи Macos Metal, пожалуйста, установите https://sdk.lunarg.com/sdk/download/latest/mac/vulkan-sdk.dmg и включите «широко установка системы»
Этот шаг PIP устанавливает акула и связанные с ними пакеты на Linux Python 3.8, 3.10 и 3.11 и MacOS / Windows Python 3.11
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpupytest tank/test_models.pyСм. Tank/readme.md для более подробного прохождения нашего Pytest Suite и CLI.
curl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/resnet50_script.py
# Install deps for test script
pip install --pre torch torchvision torchaudio tqdm pillow gsutil --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./resnet50_script.py --device= " cpu " # use cuda or vulkan or metalcurl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/minilm_jit.py
# Install deps for test script
pip install transformers torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./minilm_jit.py --device= " cpu " # use cuda or vulkan or metal Если вы хотите использовать Python3.11 и с инструментами импорта TF, вы можете использовать переменные среды, такие как: SET USE_IREE=1 для использования Upstream IREE
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
python -m shark.examples.shark_inference.resnet50_script --device= " cpu " # Use gpu | vulkan
# Or a pytest
pytest tank/test_models.py -k " MiniLM " Если вы являетесь разработчиком Torch-MLIR или разработчиком IREE и хотите проверить локальные изменения, вы можете удалить предоставленные пакеты с помощью pip uninstall torch-mlir и / или pip uninstall iree-compiler iree-runtime и построить локальное место с привязками Python и установите свой Pythonpath, как упомянуто здесь для IREE и здесь для Forch-Mlir.
Как использовать свой локально построенный Torch-Mlir с акулой:
1.) Run ` ./setup_venv.sh in SHARK ` and activate ` shark.venv ` virtual env.
2.) Run ` pip uninstall torch-mlir ` .
3.) Go to your local Torch-MLIR directory.
4.) Activate mlir_venv virtual envirnoment.
5.) Run ` pip uninstall -r requirements.txt ` .
6.) Run ` pip install -r requirements.txt ` .
7.) Build Torch-MLIR.
8.) Activate shark.venv virtual environment from the Torch-MLIR directory.
8.) Run ` export PYTHONPATH= ` pwd ` /build/tools/torch-mlir/python_packages/torch_mlir: ` pwd ` /examples ` in the Torch-MLIR directory.
9.) Go to the SHARK directory.Теперь акула будет использовать вашу местную сборку Torch-Mlir Repo.
Чтобы создать тесты отдельных диспетчеров, вы можете добавить --dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir> к вашему аргументу командной строки Pytest. Если вы хотите только скомпилировать конкретные диспетчеры, вы можете указать их с помощью разделенной строки пространства вместо "All" . Например --dispatch_benchmarks="0 1 2 10"
Например, чтобы генерировать и запустить контрольные показатели для MINILM на CUDA:
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
Приведенная команда будет заполнить <dispatch_benchmarks_dir>/<model_name>/ с помощью ordered_dispatches.txt , который перечисляет и заказывает диспетчеры и их задержки, а также папки для каждой диспетчеры, в которой содержатся .mlir, .vmfb и результаты эталона для этой дипетры.
Если вы хотите вместо этого включить это в сценарий Python, вы можете передавать команды dispatch_benchmarks и dispatch_benchmarks_dir при инициализации SharkInference , и критерии будут генерироваться при составлении. НАПРИМЕР:
shark_module = SharkInference(
mlir_model,
device=args.device,
mlir_dialect="tm_tensor",
dispatch_benchmarks="all",
dispatch_benchmarks_dir="results"
)
Вывод будет включать в себя:
См. Tank/readme.md для получения дополнительных инструкций о том, как запустить модельные тесты и тесты из танка акулы.
from shark.shark_importer import SharkImporter
# SharkImporter imports mlir file from the torch, tensorflow or tf-lite module.
mlir_importer = SharkImporter(
torch_module,
(input),
frontend="torch", #tf, #tf-lite
)
torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
# SharkInference accepts mlir in linalg, mhlo, and tosa dialect.
from shark.shark_inference import SharkInference
shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg")
shark_module.compile()
result = shark_module.forward((input))
from shark.shark_inference import SharkInference
import numpy as np
mhlo_ir = r"""builtin.module {
func.func @forward(%arg0: tensor<1x4xf32>, %arg1: tensor<4x1xf32>) -> tensor<4x4xf32> {
%0 = chlo.broadcast_add %arg0, %arg1 : (tensor<1x4xf32>, tensor<4x1xf32>) -> tensor<4x4xf32>
%1 = "mhlo.abs"(%0) : (tensor<4x4xf32>) -> tensor<4x4xf32>
return %1 : tensor<4x4xf32>
}
}"""
arg0 = np.ones((1, 4)).astype(np.float32)
arg1 = np.ones((4, 1)).astype(np.float32)
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
shark_module.compile()
result = shark_module.forward((arg0, arg1))
Акула поддерживается для поддержки новейших инноваций в моделях ML:
| TF модели Huggingface | Акула-CPU | Акула-куда | Акула-металл |
|---|---|---|---|
| БЕРТ | |||
| Дистильберт | |||
| GPT2 | |||
| ЦВЕСТИ | |||
| Стабильная диффузия | |||
| Vision Transformer | |||
| Resnet50 |
Для получения полного списка моделей, поддерживаемых в акулах, пожалуйста, обратитесь к Tank/readme.md.
#torch-mlir Channel на Discord LLVM - это самый активный канал связиtorch-mlir дискурса LLVMNod.ai Shark имеет лицензию в соответствии с условиями лицензии Apache 2.0 за исключением LLVM. Смотрите лицензию для получения дополнительной информации.


