SHARK Studio
nod.ai SHARK 20240531.1300
Distribuição de aprendizado de máquina de alto desempenho
Atualmente, estamos reconstruindo o tubarão para aproveitar a turbina. Até que seja concluído, certifique-se de usar uma liberação .exe ou uma finalização da filial SHARK-1.0 , para um tubarão que trabalha
Outros usuários, certifique -se de ter seus drivers de fornecedores mais recentes e SDK Vulkan daqui e se você estiver usando o Vulkan Check vulkaninfo funciona em uma janela de terminal
Instale o driver de (pré-requisitos) [https://github.com/nod-ai/shark-studio#install-your-hardware-drivers] acima
Faça o download do lançamento estável ou o pré-lançamento do Shark 1.0 mais recente.
Clique duas vezes no .exe, ou execute na linha de comando (recomendado) e você deve ter a interface do usuário no navegador.
Se você tiver modelos personalizados, coloque -os em um models/ diretórios onde está o .exe.
Aproveitar.
cd ) para a pasta .exe. Em seguida, execute o exe do prompt de comando. Dessa forma, se ocorrer um erro, você poderá cortá-lo para pedir ajuda. (Se sempre funcionar para você sem erro, você pode simplesmente clicar duas vezes no exe)--ui=web ao executar o exe. git clone https://github.com/nod-ai/SHARK.git
cd SHARK Atualmente, o tubarão está sendo reconstruído para a turbina no ramo main . Por enquanto, você está fortemente desencorajado de usar main , a menos que esteja trabalhando no esforço de reconstrução, e não deve esperar que o código lá produz um aplicativo de trabalho para geração de imagens; portanto, por enquanto você precisará mudar para a filial SHARK-1.0 e usar o código estável.
git checkout SHARK-1.0As seguintes instruções de configuração assumem que você está nesta filial.
set-executionpolicy remotesigned. / setup_venv.ps1 # You can re-run this script to get the latest version./setup_venv.sh
source shark1.venv/bin/activate(shark1.venv) PS C:gshark > cd .appsstable_diffusionweb
(shark1.venv) PS C:gsharkappsstable_diffusionweb > python .index.py(shark1.venv) > cd apps/stable_diffusion/web
(shark1.venv) > python index.py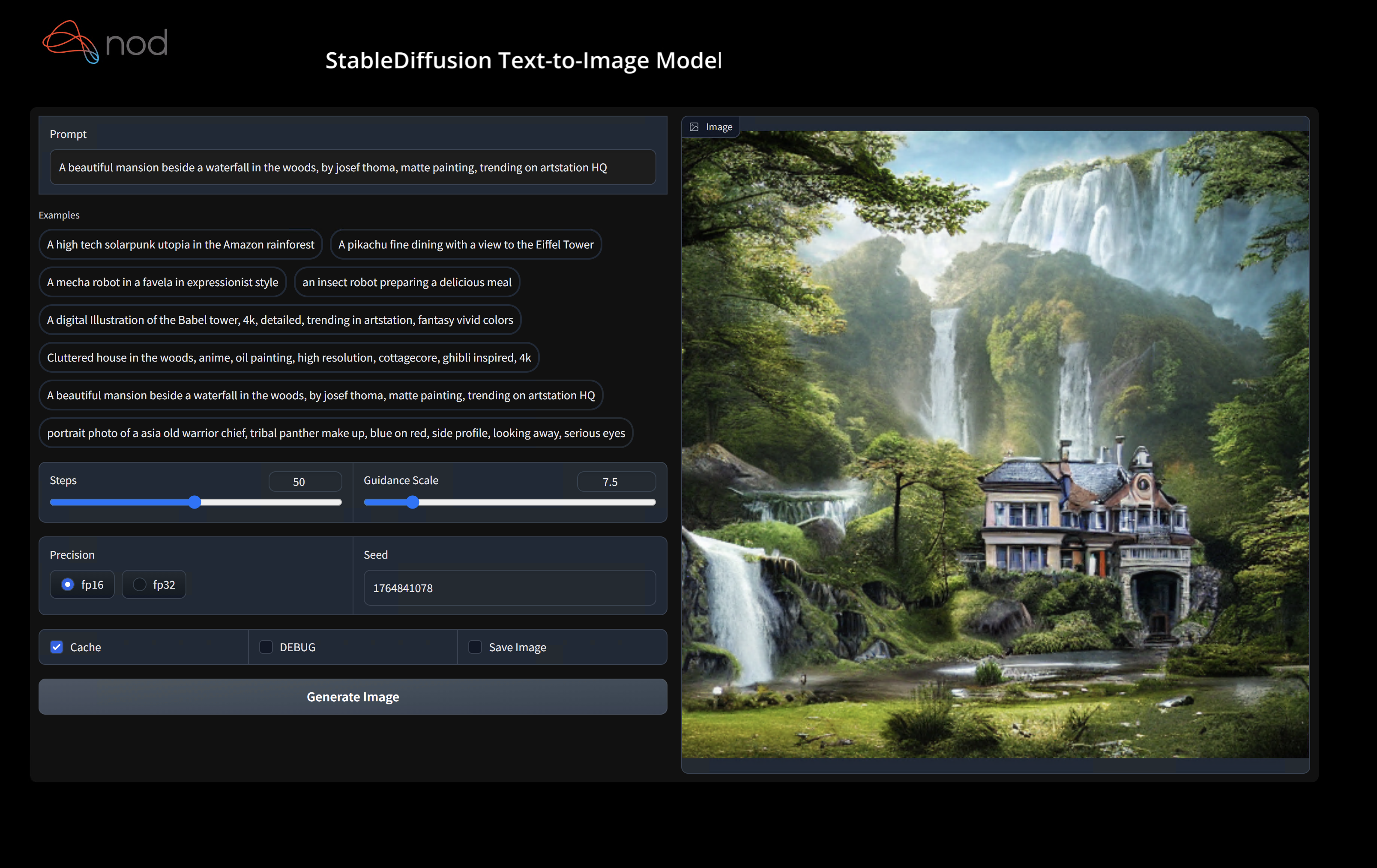
(shark1.venv) PS C:gshark > python .appsstable_diffusionscriptsmain.py -- app = " txt2img " -- precision = " fp16 " -- prompt = " tajmahal, snow, sunflowers, oil on canvas " -- device = " vulkan " python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt= " tajmahal, oil on canvas, sunflowers, 4k, uhd " Você pode substituir vulkan pela cpu para executar na sua CPU ou pelo cuda para executar em dispositivos CUDA. Se você possui vários dispositivos vulkan, você pode abordá -los --device=vulkan://1 etc
A saída em um AMD 7900XTX seria algo como:
Average step time: 47.19188690185547ms/it
Clip Inference time (ms) = 109.531
VAE Inference time (ms): 78.590
Total image generation time: 2.5788655281066895secAqui estão algumas amostras geradas:


Encontre -nos no Shark Discord Server se tiver algum problema com a execução do seu hardware.
Esta etapa configura um novo Virtualenv para Python
python --version # Check you have 3.11 on Linux, macOS or Windows Powershell
python -m venv shark_venv
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
# If you are using conda create and activate a new conda env
# Some older pip installs may not be able to handle the recent PyTorch deps
python -m pip install --upgrade pipUsuários do MacOS Metal , instale https://sdk.lunarg.com/sdk/download/latest/mac/vulkan-sdk.dmg e ative o "System Wide Install"
Esta etapa Pip instala tubarão e pacotes relacionados no Linux Python 3.8, 3.10 e 3.11 e macOS / Windows Python 3.11
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpupytest tank/test_models.pyConsulte Tank/ReadMe.md para obter um passo a passo mais detalhado da nossa suíte Pytest e CLI.
curl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/resnet50_script.py
# Install deps for test script
pip install --pre torch torchvision torchaudio tqdm pillow gsutil --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./resnet50_script.py --device= " cpu " # use cuda or vulkan or metalcurl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/minilm_jit.py
# Install deps for test script
pip install transformers torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./minilm_jit.py --device= " cpu " # use cuda or vulkan or metal Se você deseja usar o python3.11 e com as ferramentas de importação TF, você pode usar as variáveis de ambiente como: set USE_IREE=1 para usar a upstream Iree
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
python -m shark.examples.shark_inference.resnet50_script --device= " cpu " # Use gpu | vulkan
# Or a pytest
pytest tank/test_models.py -k " MiniLM " Se você é um desenvolvedor da Torch-MLIR ou um desenvolvedor da IREE e deseja testar alterações locais, pode desinstalar os pacotes fornecidos com pip uninstall torch-mlir e / ou pip uninstall iree-compiler iree-runtime e se formar localmente com as ligações python e defina seu pythonpath, como mencionado aqui, para Irree e aqui para mir.
Como usar o seu Torch-Mlir construído localmente com tubarão:
1.) Run ` ./setup_venv.sh in SHARK ` and activate ` shark.venv ` virtual env.
2.) Run ` pip uninstall torch-mlir ` .
3.) Go to your local Torch-MLIR directory.
4.) Activate mlir_venv virtual envirnoment.
5.) Run ` pip uninstall -r requirements.txt ` .
6.) Run ` pip install -r requirements.txt ` .
7.) Build Torch-MLIR.
8.) Activate shark.venv virtual environment from the Torch-MLIR directory.
8.) Run ` export PYTHONPATH= ` pwd ` /build/tools/torch-mlir/python_packages/torch_mlir: ` pwd ` /examples ` in the Torch-MLIR directory.
9.) Go to the SHARK directory.Agora, o tubarão usará o seu repositório de torch-mlir localmente.
Para produzir benchmarks de despachos individuais, você pode adicionar --dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir> ao seu argumento de linha de comando pytest. Se você deseja compilar despachos específicos, poderá especificá -los com uma corda espacial separada em vez de "All" . Por exemplo - --dispatch_benchmarks="0 1 2 10"
Por exemplo, para gerar e executar os benchmarks de expedição para o Minilm no CUDA:
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
O comando fornecido preencherá <dispatch_benchmarks_dir>/<model_name>/ com um ordered_dispatches.txt que lista e ordena os despachos e suas latências, bem como pastas para cada expedição que contêm .mlir, .vmfb e resultados da parte de referência para esse despacho.
Se você deseja incorporar isso em um script python, poderá passar os comandos dispatch_benchmarks e dispatch_benchmarks_dir ao inicializar SharkInference , e os benchmarks serão gerados quando compilados. Por exemplo:
shark_module = SharkInference(
mlir_model,
device=args.device,
mlir_dialect="tm_tensor",
dispatch_benchmarks="all",
dispatch_benchmarks_dir="results"
)
A saída incluirá:
Consulte o tank/readme.md para obter instruções adicionais sobre como executar testes e benchmarks de modelo do tanque de tubarão.
from shark.shark_importer import SharkImporter
# SharkImporter imports mlir file from the torch, tensorflow or tf-lite module.
mlir_importer = SharkImporter(
torch_module,
(input),
frontend="torch", #tf, #tf-lite
)
torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
# SharkInference accepts mlir in linalg, mhlo, and tosa dialect.
from shark.shark_inference import SharkInference
shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg")
shark_module.compile()
result = shark_module.forward((input))
from shark.shark_inference import SharkInference
import numpy as np
mhlo_ir = r"""builtin.module {
func.func @forward(%arg0: tensor<1x4xf32>, %arg1: tensor<4x1xf32>) -> tensor<4x4xf32> {
%0 = chlo.broadcast_add %arg0, %arg1 : (tensor<1x4xf32>, tensor<4x1xf32>) -> tensor<4x4xf32>
%1 = "mhlo.abs"(%0) : (tensor<4x4xf32>) -> tensor<4x4xf32>
return %1 : tensor<4x4xf32>
}
}"""
arg0 = np.ones((1, 4)).astype(np.float32)
arg1 = np.ones((4, 1)).astype(np.float32)
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
shark_module.compile()
result = shark_module.forward((arg0, arg1))
O tubarão é mantido para apoiar as mais recentes inovações nos modelos de ML:
| Modelos de huggingface tf | Shark-cpu | Shark-Cuda | Metal de tubarão |
|---|---|---|---|
| Bert | |||
| Distilbert | |||
| GPT2 | |||
| FLORESCER | |||
| Difusão estável | |||
| Transformador de visão | |||
| Resnet50 |
Para obter uma lista completa dos modelos suportados no Shark, consulte o tank/readme.md.
#torch-mlir no LLVM Discord - este é o canal de comunicação mais ativotorch-mlir do discurso LLVMNOD.AI O tubarão é licenciado nos termos da licença Apache 2.0 com exceções de LLVM. Consulte a licença para obter mais informações.


