SHARK Studio
nod.ai SHARK 20240531.1300
Distribution d'apprentissage automatique haute performance
Nous reconstruisons actuellement le requin pour profiter de la turbine. Jusqu'à ce que cela soit complet, assurez-vous d'utiliser une version .exe ou une caisse de la branche SHARK-1.0 , pour un requin de travail
D'autres utilisateurs, veuillez vous assurer d'avoir vos derniers pilotes de fournisseurs et votre SDK Vulkan à partir d'ici et si vous utilisez Vulkan, vérifiez que vulkaninfo fonctionne dans une fenêtre de terminal
Installez le pilote à partir de (prérequis) [https://github.com/nod-ai/shark-studio#install-your-hardware-drivers] ci-dessus
Téléchargez la version stable ou le plus récent Shark 1.0 Pre-Release.
Double-cliquez sur .exe ou exécutez à partir de la ligne de commande (recommandée), et vous devriez avoir l'interface utilisateur dans le navigateur.
Si vous avez des modèles personnalisés, placez-les dans un models/ répertoire où se trouve le .exe.
Apprécier.
cd ) dans le dossier .exe. Ensuite, exécutez l'EXE à partir de l'invite de commande. De cette façon, si une erreur se produit, vous pourrez le couper et le coup pour demander de l'aide. (Si cela fonctionne toujours pour vous sans erreur, vous pouvez simplement double-cliquez sur l'EXE)--ui=web lors de l'exécution de l'EXE. git clone https://github.com/nod-ai/SHARK.git
cd SHARK Actuellement, Shark est reconstruit pour la turbine sur la branche main . Pour l'instant, vous êtes fortement découragé d'utiliser main à moins que vous ne travailliez sur l'effort de reconstruction, et ne devez pas vous attendre à ce que le code produise une application de travail pour la génération d'images, donc pour l'instant vous aurez besoin de passer à la branche SHARK-1.0 et d'utiliser le code stable.
git checkout SHARK-1.0Les instructions de configuration suivantes supposent que vous êtes sur cette branche.
set-executionpolicy remotesigned. / setup_venv.ps1 # You can re-run this script to get the latest version./setup_venv.sh
source shark1.venv/bin/activate(shark1.venv) PS C:gshark > cd .appsstable_diffusionweb
(shark1.venv) PS C:gsharkappsstable_diffusionweb > python .index.py(shark1.venv) > cd apps/stable_diffusion/web
(shark1.venv) > python index.py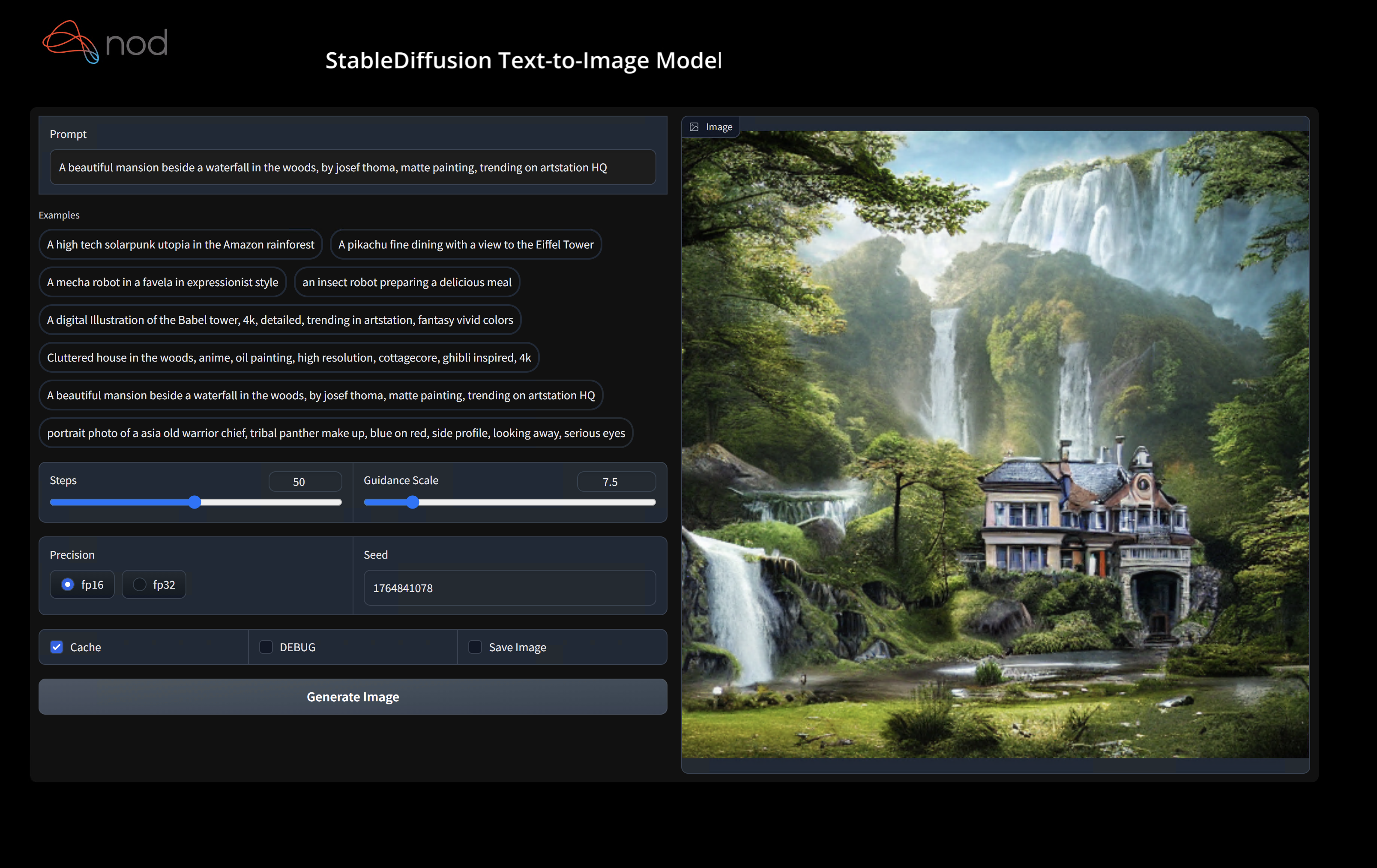
(shark1.venv) PS C:gshark > python .appsstable_diffusionscriptsmain.py -- app = " txt2img " -- precision = " fp16 " -- prompt = " tajmahal, snow, sunflowers, oil on canvas " -- device = " vulkan " python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt= " tajmahal, oil on canvas, sunflowers, 4k, uhd " Vous pouvez remplacer vulkan par cpu pour fonctionner sur votre CPU ou par cuda pour fonctionner sur des appareils CUDA. Si vous avez plusieurs appareils Vulkan, vous pouvez les résoudre avec --device=vulkan://1 etc
La sortie sur un AMD 7900xtx ressemblerait à quelque chose comme:
Average step time: 47.19188690185547ms/it
Clip Inference time (ms) = 109.531
VAE Inference time (ms): 78.590
Total image generation time: 2.5788655281066895secVoici quelques échantillons générés:


Trouvez-nous sur Shark Discord Server si vous avez du mal à l'exécuter sur votre matériel.
Cette étape met en place un nouveau virtualenv pour python
python --version # Check you have 3.11 on Linux, macOS or Windows Powershell
python -m venv shark_venv
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
# If you are using conda create and activate a new conda env
# Some older pip installs may not be able to handle the recent PyTorch deps
python -m pip install --upgrade pipLes utilisateurs de MacOS Metal Veuillez installer https://sdk.lunarg.com/sdk/download/latest/mac/vulkan-sdk.dmg et activer "Installer à l'échelle du système"
Cette étape PIP installe des packages de requin et connexes sur Linux Python 3.8, 3.10 et 3.11 et MacOS / Windows Python 3.11
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpupytest tank/test_models.pyVoir Tank / Readme.md pour une procédure pas à pas plus détaillée de notre suite Pytest et CLI.
curl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/resnet50_script.py
# Install deps for test script
pip install --pre torch torchvision torchaudio tqdm pillow gsutil --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./resnet50_script.py --device= " cpu " # use cuda or vulkan or metalcurl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/minilm_jit.py
# Install deps for test script
pip install transformers torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./minilm_jit.py --device= " cpu " # use cuda or vulkan or metal Si vous souhaitez utiliser Python3.11 et avec des outils d'importation TF, vous pouvez utiliser les variables d'environnement comme: set USE_IREE=1 pour utiliser en amont iree
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
python -m shark.examples.shark_inference.resnet50_script --device= " cpu " # Use gpu | vulkan
# Or a pytest
pytest tank/test_models.py -k " MiniLM " Si vous êtes un développeur Torch-Mlir ou un développeur Iree et que vous souhaitez tester les modifications locales, vous pouvez désinstaller les packages fournis avec pip uninstall torch-mlir et / ou pip uninstall iree-compiler iree-runtime et construire localement avec Python Bindings et définir votre PythonPath comme mentionné ici pour IREE et ici pour Torch-Mlir.
Comment utiliser votre torch-mlir construit localement avec le requin:
1.) Run ` ./setup_venv.sh in SHARK ` and activate ` shark.venv ` virtual env.
2.) Run ` pip uninstall torch-mlir ` .
3.) Go to your local Torch-MLIR directory.
4.) Activate mlir_venv virtual envirnoment.
5.) Run ` pip uninstall -r requirements.txt ` .
6.) Run ` pip install -r requirements.txt ` .
7.) Build Torch-MLIR.
8.) Activate shark.venv virtual environment from the Torch-MLIR directory.
8.) Run ` export PYTHONPATH= ` pwd ` /build/tools/torch-mlir/python_packages/torch_mlir: ` pwd ` /examples ` in the Torch-MLIR directory.
9.) Go to the SHARK directory.Maintenant, le requin utilisera votre dépôt de torch-mlir à construire localement.
Pour produire des benchmarks de répartitions individuelles, vous pouvez ajouter --dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir> à votre argument de ligne de commande pytest. Si vous souhaitez seulement compiler des réparations spécifiques, vous pouvez les spécifier avec une chaîne séparée d'espace au lieu de "All" . Par exemple --dispatch_benchmarks="0 1 2 10"
Par exemple, pour générer et exécuter des références d'expédition pour le miniil sur Cuda:
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
La commande donnée remplira <dispatch_benchmarks_dir>/<model_name>/ avec un ordered_dispatches.txt qui répertorie et ordonne les répartitions et leurs latences, ainsi que des dossiers pour chaque répartition qui contiennent .mlir, .vmfb et les résultats de la référence pour cette répartition.
Si vous souhaitez plutôt incorporer cela dans un script Python, vous pouvez passer les commandes dispatch_benchmarks et dispatch_benchmarks_dir lors de l'initialisation SharkInference , et les repères seront générés lors de la compilation. Par exemple:
shark_module = SharkInference(
mlir_model,
device=args.device,
mlir_dialect="tm_tensor",
dispatch_benchmarks="all",
dispatch_benchmarks_dir="results"
)
La sortie comprendra:
Voir Tank / Readme.md pour d'autres instructions sur la façon d'exécuter des tests de modèle et des références du réservoir de requin.
from shark.shark_importer import SharkImporter
# SharkImporter imports mlir file from the torch, tensorflow or tf-lite module.
mlir_importer = SharkImporter(
torch_module,
(input),
frontend="torch", #tf, #tf-lite
)
torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
# SharkInference accepts mlir in linalg, mhlo, and tosa dialect.
from shark.shark_inference import SharkInference
shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg")
shark_module.compile()
result = shark_module.forward((input))
from shark.shark_inference import SharkInference
import numpy as np
mhlo_ir = r"""builtin.module {
func.func @forward(%arg0: tensor<1x4xf32>, %arg1: tensor<4x1xf32>) -> tensor<4x4xf32> {
%0 = chlo.broadcast_add %arg0, %arg1 : (tensor<1x4xf32>, tensor<4x1xf32>) -> tensor<4x4xf32>
%1 = "mhlo.abs"(%0) : (tensor<4x4xf32>) -> tensor<4x4xf32>
return %1 : tensor<4x4xf32>
}
}"""
arg0 = np.ones((1, 4)).astype(np.float32)
arg1 = np.ones((4, 1)).astype(np.float32)
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
shark_module.compile()
result = shark_module.forward((arg0, arg1))
Shark est maintenu pour soutenir les dernières innovations dans les modèles ML:
| Modèles TF HuggingFace | Requin-CPU | Requin-cuda | Mital de requin |
|---|---|---|---|
| Bert | |||
| Distilbert | |||
| Gpt2 | |||
| FLORAISON | |||
| Diffusion stable | |||
| Transformateur de vision | |||
| Resnet50 |
Pour une liste complète des modèles pris en charge dans Shark, veuillez vous référer à Tank / Readme.md.
#torch-mlir sur la discorde LLVM - c'est le canal de communication le plus actiftorch-mlir du discours LLVMNOD.AI Shark est sous licence de la licence Apache 2.0 avec des exceptions LLVM. Voir la licence pour plus d'informations.


