SHARK Studio
nod.ai SHARK 20240531.1300
Distribución de aprendizaje automático de alto rendimiento
Actualmente estamos reconstruyendo tiburones para aprovechar la turbina. Hasta que eso esté completo, asegúrese de usar una versión .exe o un pago de la sucursal SHARK-1.0 , para un tiburón en funcionamiento
Otros usuarios asegúrese de tener sus últimos controladores de proveedores y Vulkan SDK desde aquí y si está utilizando Vulkan Check vulkaninfo funciona en una ventana de terminal
Instale el controlador desde (requisitos previos) [https://github.com/nod-ai/shark-studio#install-your-hardware-drivers] arriba
Descargue el lanzamiento estable o el prelanzamiento más reciente de Shark 1.0.
Haga doble clic en el .exe o ejecute desde la línea de comando (recomendado), y debe tener la interfaz de usuario en el navegador.
Si tiene modelos personalizados, colóquelos en un models/ directorio donde esté el .exe.
Disfrutar.
cd ) a la carpeta .exe. Luego ejecute el exe desde el símbolo del sistema. De esa manera, si se produce un error, podrá cortarlo y pegarlo para pedir ayuda. (Si siempre funciona para usted sin error, simplemente puede hacer doble clic en EXE)--ui=web al ejecutar EXE. git clone https://github.com/nod-ai/SHARK.git
cd SHARK Actualmente, Shark está siendo reconstruido para la turbina en la rama main . Por ahora, se le desanima mucho el uso de main a menos que esté trabajando en el esfuerzo de reconstrucción, y no debe esperar que el código allí produzca una aplicación de trabajo para la generación de imágenes, por lo que por ahora necesitará cambiar a la rama SHARK-1.0 y usar el código estable.
git checkout SHARK-1.0Las siguientes instrucciones de configuración suponen que está en esta rama.
set-executionpolicy remotesigned. / setup_venv.ps1 # You can re-run this script to get the latest version./setup_venv.sh
source shark1.venv/bin/activate(shark1.venv) PS C:gshark > cd .appsstable_diffusionweb
(shark1.venv) PS C:gsharkappsstable_diffusionweb > python .index.py(shark1.venv) > cd apps/stable_diffusion/web
(shark1.venv) > python index.py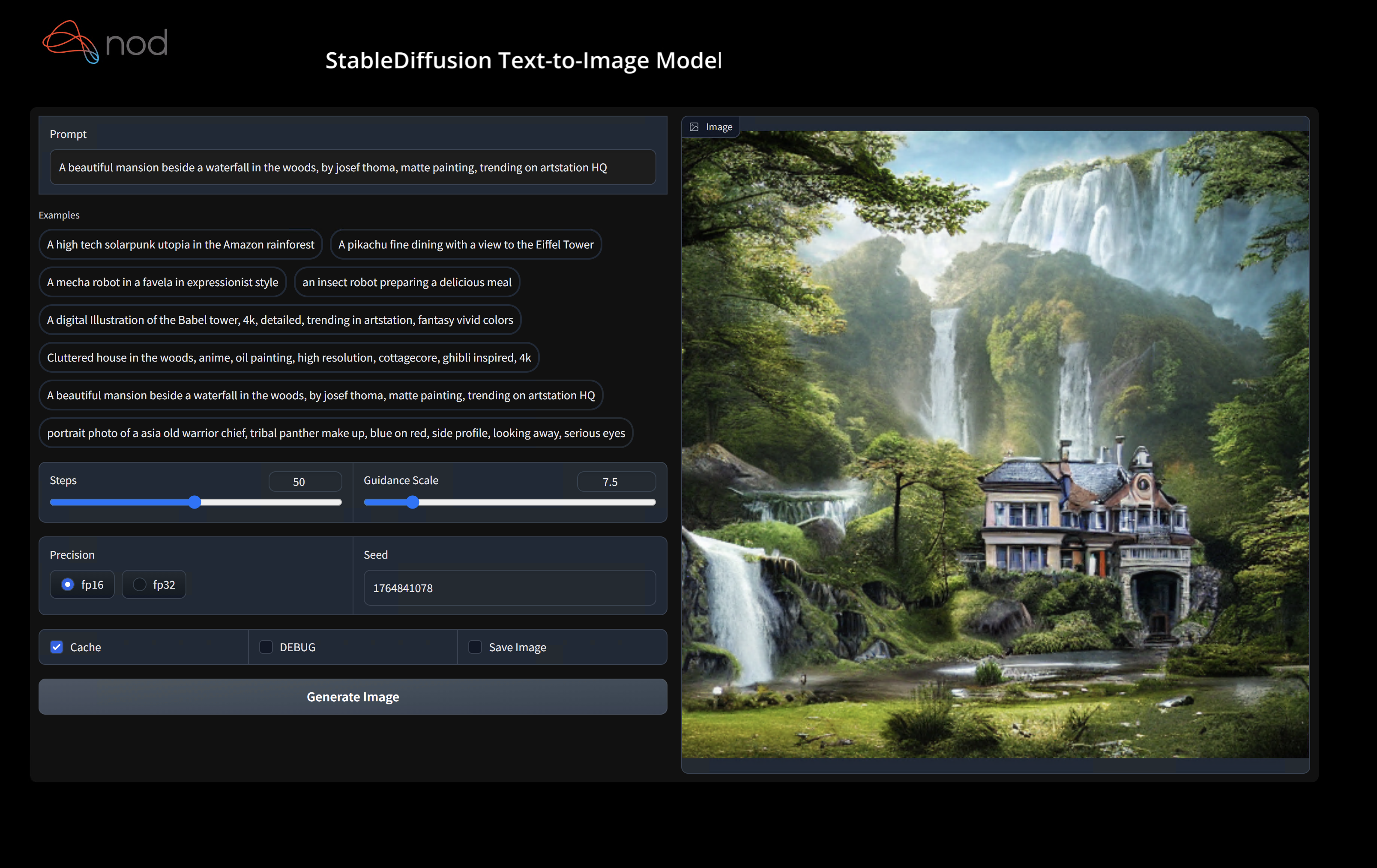
(shark1.venv) PS C:gshark > python .appsstable_diffusionscriptsmain.py -- app = " txt2img " -- precision = " fp16 " -- prompt = " tajmahal, snow, sunflowers, oil on canvas " -- device = " vulkan " python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt= " tajmahal, oil on canvas, sunflowers, 4k, uhd " Puede reemplazar vulkan con cpu para ejecutar su CPU o con cuda para ejecutar en dispositivos CUDA. Si tiene múltiples dispositivos Vulkan, puede abordarlos con --device=vulkan://1 etc
La salida en un AMD 7900XTX se vería algo así como:
Average step time: 47.19188690185547ms/it
Clip Inference time (ms) = 109.531
VAE Inference time (ms): 78.590
Total image generation time: 2.5788655281066895secAquí hay algunas muestras generadas:


Encuéntrenos en Shark Discord Server si tiene algún problema para ejecutarlo en su hardware.
Este paso establece un nuevo VirtualEnv para Python
python --version # Check you have 3.11 on Linux, macOS or Windows Powershell
python -m venv shark_venv
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
# If you are using conda create and activate a new conda env
# Some older pip installs may not be able to handle the recent PyTorch deps
python -m pip install --upgrade pipUsuarios de MacOS Metal Instale https://sdk.lunarg.com/sdk/download/latest/mac/vulkan-sdk.dmg y habilita la "instalación del sistema en todo el sistema"
Este paso PIP instala tiburón y paquetes relacionados en Linux Python 3.8, 3.10 y 3.11 y MacOS / Windows Python 3.11
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpupytest tank/test_models.pyVea Tank/Readme.md para un tutorial más detallado de nuestra suite y CLI de Pytest.
curl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/resnet50_script.py
# Install deps for test script
pip install --pre torch torchvision torchaudio tqdm pillow gsutil --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./resnet50_script.py --device= " cpu " # use cuda or vulkan or metalcurl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/minilm_jit.py
# Install deps for test script
pip install transformers torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./minilm_jit.py --device= " cpu " # use cuda or vulkan or metal Si desea usar Python3.11 y con las herramientas de importación de TF, puede usar las variables de entorno como: set USE_IREE=1 para usar Iree ascendente
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
python -m shark.examples.shark_inference.resnet50_script --device= " cpu " # Use gpu | vulkan
# Or a pytest
pytest tank/test_models.py -k " MiniLM " Si usted es un desarrollador de Torch-Mlir o un desarrollador de Iree y desea probar los cambios locales, puede desinstalar los paquetes proporcionados con pip uninstall torch-mlir y / o pip uninstall iree-compiler iree-runtime y construir localmente con enlaces de Python y establecer su Pythonpath como se menciona aquí para IREE y aquí para Torch-Mlir.
Cómo usar su Torch-Mlir de construcción local con tiburón:
1.) Run ` ./setup_venv.sh in SHARK ` and activate ` shark.venv ` virtual env.
2.) Run ` pip uninstall torch-mlir ` .
3.) Go to your local Torch-MLIR directory.
4.) Activate mlir_venv virtual envirnoment.
5.) Run ` pip uninstall -r requirements.txt ` .
6.) Run ` pip install -r requirements.txt ` .
7.) Build Torch-MLIR.
8.) Activate shark.venv virtual environment from the Torch-MLIR directory.
8.) Run ` export PYTHONPATH= ` pwd ` /build/tools/torch-mlir/python_packages/torch_mlir: ` pwd ` /examples ` in the Torch-MLIR directory.
9.) Go to the SHARK directory.Ahora el tiburón utilizará su repositorio de antorchas de construcción localmente.
Para producir puntos de referencia de despachos individuales, puede agregar --dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir> a su argumento de línea de comandos Pytest. Si solo desea compilar despachos específicos, puede especificarlos con una cadena separada de espacio en lugar de "All" . Por ejemplo --dispatch_benchmarks="0 1 2 10"
Por ejemplo, para generar y ejecutar puntos de referencia de despacho para minilm en CUDA:
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
El comando dado completará <dispatch_benchmarks_dir>/<model_name>/ con un ordered_dispatches.txt que enumera y ordena los despachos y sus latencias, así como carpetas para cada envío que contienen .mlir, .vmfb, y los resultados de la referencia para ese envío.
Si desea incorporar esto en un script de Python, puede pasar los comandos dispatch_benchmarks y dispatch_benchmarks_dir al inicializar SharkInference , y los puntos de referencia se generarán cuando se compilen. P.EJ:
shark_module = SharkInference(
mlir_model,
device=args.device,
mlir_dialect="tm_tensor",
dispatch_benchmarks="all",
dispatch_benchmarks_dir="results"
)
La salida incluirá:
Consulte Tank/ReadMe.md para obtener más instrucciones sobre cómo ejecutar pruebas de modelo y puntos de referencia desde el tanque Shark.
from shark.shark_importer import SharkImporter
# SharkImporter imports mlir file from the torch, tensorflow or tf-lite module.
mlir_importer = SharkImporter(
torch_module,
(input),
frontend="torch", #tf, #tf-lite
)
torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
# SharkInference accepts mlir in linalg, mhlo, and tosa dialect.
from shark.shark_inference import SharkInference
shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg")
shark_module.compile()
result = shark_module.forward((input))
from shark.shark_inference import SharkInference
import numpy as np
mhlo_ir = r"""builtin.module {
func.func @forward(%arg0: tensor<1x4xf32>, %arg1: tensor<4x1xf32>) -> tensor<4x4xf32> {
%0 = chlo.broadcast_add %arg0, %arg1 : (tensor<1x4xf32>, tensor<4x1xf32>) -> tensor<4x4xf32>
%1 = "mhlo.abs"(%0) : (tensor<4x4xf32>) -> tensor<4x4xf32>
return %1 : tensor<4x4xf32>
}
}"""
arg0 = np.ones((1, 4)).astype(np.float32)
arg1 = np.ones((4, 1)).astype(np.float32)
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
shark_module.compile()
result = shark_module.forward((arg0, arg1))
Shark se mantiene para apoyar las últimas innovaciones en modelos ML:
| Modelos TF Huggingface | Tiburón | Tiburón | Tiburón |
|---|---|---|---|
| Bert | |||
| Distilbert | |||
| GPT2 | |||
| FLORACIÓN | |||
| Difusión estable | |||
| Transformador de visión | |||
| Resnet50 |
Para obtener una lista completa de los modelos compatibles con Shark, consulte Tank/ReadMe.md.
#torch-mlir en la discordia LLVM: este es el canal de comunicación más activotorch-mlir del discurso LLVMNod.Ai Shark tiene licencia bajo los términos de la licencia Apache 2.0 con excepciones LLVM. Vea la licencia para más información.


