SHARK Studio
nod.ai SHARK 20240531.1300
Distribusi Pembelajaran Mesin Kinerja Tinggi
Kami saat ini sedang membangun kembali hiu untuk mengambil keuntungan dari turbin. Sampai itu selesai, pastikan Anda menggunakan rilis .exe atau checkout cabang SHARK-1.0 , untuk hiu yang berfungsi
Pengguna Lain Harap Pastikan Anda Memiliki Pengemudi Vendor Terbaru dan Vulkan SDK Dari Sini Dan Jika Anda Menggunakan Vulkan Check vulkaninfo Bekerja Di Jendela Terminal
Instal driver dari (prasyarat) [https://github.com/nod-ai/shark-studio#install-your-hardware-drivers] di atas
Unduh rilis stabil atau pra-rilis Hiu 1.0 terbaru.
Klik dua kali. .Exe, atau jalankan dari baris perintah (disarankan), dan Anda harus memiliki UI di browser.
Jika Anda memiliki model khusus, masukkan ke dalam models/ direktori di mana .exe berada.
Menikmati.
cd ) ke folder .exe. Kemudian jalankan EXE dari prompt perintah. Dengan begitu, jika terjadi kesalahan, Anda dapat memotong dan menempelkannya untuk meminta bantuan. (Jika selalu berhasil untuk Anda tanpa kesalahan, Anda dapat mengklik dua kali exe)--ui=web saat menjalankan EXE. git clone https://github.com/nod-ai/SHARK.git
cd SHARK Saat ini hiu sedang dibangun kembali untuk turbin di cabang main . Untuk saat ini Anda sangat berkecil hati menggunakan main kecuali Anda sedang mengerjakan upaya pembangunan kembali, dan tidak boleh mengharapkan kode di sana untuk menghasilkan aplikasi yang berfungsi untuk pembuatan gambar, jadi untuk saat ini Anda akan perlu beralih ke cabang SHARK-1.0 dan menggunakan kode stabil.
git checkout SHARK-1.0Instruksi pengaturan berikut menganggap Anda berada di cabang ini.
set-executionpolicy remotesigned. / setup_venv.ps1 # You can re-run this script to get the latest version./setup_venv.sh
source shark1.venv/bin/activate(shark1.venv) PS C:gshark > cd .appsstable_diffusionweb
(shark1.venv) PS C:gsharkappsstable_diffusionweb > python .index.py(shark1.venv) > cd apps/stable_diffusion/web
(shark1.venv) > python index.py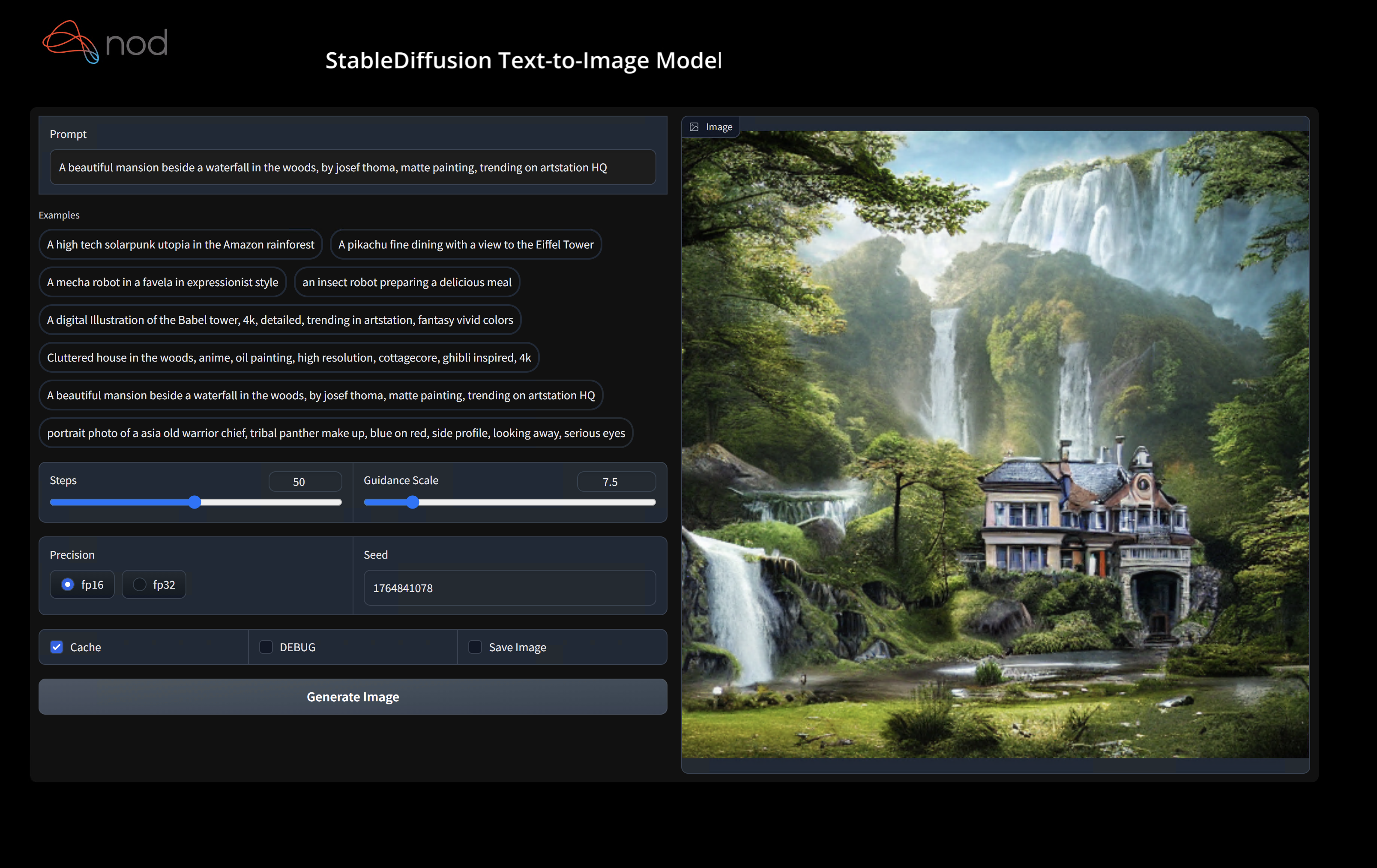
(shark1.venv) PS C:gshark > python .appsstable_diffusionscriptsmain.py -- app = " txt2img " -- precision = " fp16 " -- prompt = " tajmahal, snow, sunflowers, oil on canvas " -- device = " vulkan " python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt= " tajmahal, oil on canvas, sunflowers, 4k, uhd " Anda dapat mengganti vulkan dengan cpu untuk menjalankan CPU Anda atau dengan cuda untuk menjalankan perangkat CUDA. Jika Anda memiliki beberapa perangkat Vulkan, Anda dapat mengatasinya dengan --device=vulkan://1 dll
Output pada AMD 7900XTX akan terlihat seperti:
Average step time: 47.19188690185547ms/it
Clip Inference time (ms) = 109.531
VAE Inference time (ms): 78.590
Total image generation time: 2.5788655281066895secBerikut beberapa sampel yang dihasilkan:


Temukan kami di server Discord hiu jika Anda mengalami masalah dengan menjalankannya di perangkat keras Anda.
Langkah ini mengatur VirtualEnv baru untuk Python
python --version # Check you have 3.11 on Linux, macOS or Windows Powershell
python -m venv shark_venv
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
# If you are using conda create and activate a new conda env
# Some older pip installs may not be able to handle the recent PyTorch deps
python -m pip install --upgrade pipMacOS Metal Users, silakan instal https://sdk.lunarg.com/sdk/download/latest/mac/vulkan-sdk.dmg dan aktifkan "instalasi sistem lebar"
Langkah ini PIP menginstal hiu dan paket terkait di Linux Python 3.8, 3.10 dan 3.11 dan MacOS / Windows Python 3.11
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpupytest tank/test_models.pyLihat tank/readme.md untuk penelusuran pytest suite dan CLI kami.
curl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/resnet50_script.py
# Install deps for test script
pip install --pre torch torchvision torchaudio tqdm pillow gsutil --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./resnet50_script.py --device= " cpu " # use cuda or vulkan or metalcurl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/minilm_jit.py
# Install deps for test script
pip install transformers torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./minilm_jit.py --device= " cpu " # use cuda or vulkan or metal Jika Anda ingin menggunakan python3.11 dan dengan alat impor TF Anda dapat menggunakan variabel lingkungan seperti: atur USE_IREE=1 untuk menggunakan IREE hulu
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
python -m shark.examples.shark_inference.resnet50_script --device= " cpu " # Use gpu | vulkan
# Or a pytest
pytest tank/test_models.py -k " MiniLM " Jika Anda adalah pengembang obor-mlir atau pengembang IREE dan ingin menguji perubahan lokal, Anda dapat menghapus paket yang disediakan dengan pip uninstall torch-mlir dan / atau pip uninstall iree-compiler iree-runtime dan membangun secara lokal dengan tatanan python dan mengatur pythonpath Anda seperti yang disebutkan di sini untuk IREE dan di sini untuk tinju.
Cara menggunakan obor-mlir yang dibangun secara lokal dengan hiu:
1.) Run ` ./setup_venv.sh in SHARK ` and activate ` shark.venv ` virtual env.
2.) Run ` pip uninstall torch-mlir ` .
3.) Go to your local Torch-MLIR directory.
4.) Activate mlir_venv virtual envirnoment.
5.) Run ` pip uninstall -r requirements.txt ` .
6.) Run ` pip install -r requirements.txt ` .
7.) Build Torch-MLIR.
8.) Activate shark.venv virtual environment from the Torch-MLIR directory.
8.) Run ` export PYTHONPATH= ` pwd ` /build/tools/torch-mlir/python_packages/torch_mlir: ` pwd ` /examples ` in the Torch-MLIR directory.
9.) Go to the SHARK directory.Sekarang hiu akan menggunakan repo obor-mlir build lokal Anda.
Untuk menghasilkan tolok ukur dari masing -masing pengiriman, Anda dapat menambahkan --dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir> ke argumen baris perintah pytest Anda. Jika Anda hanya ingin mengkompilasi pengiriman tertentu, Anda dapat menentukannya dengan string yang dipisahkan ruang alih -alih "All" . Misalnya --dispatch_benchmarks="0 1 2 10"
Misalnya, untuk menghasilkan dan menjalankan tolok ukur pengiriman untuk Minilm di Cuda:
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
Perintah yang diberikan akan mengisi <dispatch_benchmarks_dir>/<model_name>/ dengan ordered_dispatches.txt yang mencantumkan dan memesan pengiriman dan latensi mereka, serta folder untuk setiap pengiriman yang berisi .MLIR, .VMFB, dan hasil benchmark untuk pengiriman itu.
Jika Anda ingin memasukkan ini ke dalam skrip Python, Anda dapat melewati perintah dispatch_benchmarks dan dispatch_benchmarks_dir saat menginisialisasi SharkInference , dan tolok ukur akan dihasilkan saat dikompilasi. MISALNYA:
shark_module = SharkInference(
mlir_model,
device=args.device,
mlir_dialect="tm_tensor",
dispatch_benchmarks="all",
dispatch_benchmarks_dir="results"
)
Output akan mencakup:
Lihat Tank/Readme.md untuk instruksi lebih lanjut tentang cara menjalankan tes model dan tolok ukur dari tangki hiu.
from shark.shark_importer import SharkImporter
# SharkImporter imports mlir file from the torch, tensorflow or tf-lite module.
mlir_importer = SharkImporter(
torch_module,
(input),
frontend="torch", #tf, #tf-lite
)
torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
# SharkInference accepts mlir in linalg, mhlo, and tosa dialect.
from shark.shark_inference import SharkInference
shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg")
shark_module.compile()
result = shark_module.forward((input))
from shark.shark_inference import SharkInference
import numpy as np
mhlo_ir = r"""builtin.module {
func.func @forward(%arg0: tensor<1x4xf32>, %arg1: tensor<4x1xf32>) -> tensor<4x4xf32> {
%0 = chlo.broadcast_add %arg0, %arg1 : (tensor<1x4xf32>, tensor<4x1xf32>) -> tensor<4x4xf32>
%1 = "mhlo.abs"(%0) : (tensor<4x4xf32>) -> tensor<4x4xf32>
return %1 : tensor<4x4xf32>
}
}"""
arg0 = np.ones((1, 4)).astype(np.float32)
arg1 = np.ones((4, 1)).astype(np.float32)
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
shark_module.compile()
result = shark_module.forward((arg0, arg1))
Hiu dipertahankan untuk mendukung inovasi terbaru dalam model ML:
| TF Model Huggingface | Hiu-CPU | Hiu-Cuda | Hiu-logam |
|---|---|---|---|
| Bert | |||
| Distilbert | |||
| Gpt2 | |||
| BUNGA | |||
| Difusi stabil | |||
| Transformator Visi | |||
| Resnet50 |
Untuk daftar lengkap model yang didukung di hiu, silakan merujuk ke tank/readme.md.
#torch-mlir di LLVM Discord - Ini adalah saluran komunikasi paling aktiftorch-mlir dari Wacana LLVMNOD.AI Shark dilisensikan berdasarkan ketentuan lisensi Apache 2.0 dengan pengecualian LLVM. Lihat lisensi untuk informasi lebih lanjut.


