SHARK Studio
nod.ai SHARK 20240531.1300
توزيع التعلم الآلي عالي الأداء
نقوم حاليًا بإعادة بناء القرش للاستفادة من التوربينات. حتى يتم اكتمال ذلك ، تأكد من استخدام إصدار .exe أو الخروج من فرع SHARK-1.0 ، لقرش عمل
يرجى من المستخدمين التأكد من أن لديك أحدث برامج تشغيل البائعين و Vulkan SDK من هنا وإذا كنت تستخدم Vulkan Check Works vulkaninfo في نافذة طرفية
قم بتثبيت برنامج التشغيل من (المتطلبات الأساسية) [https://github.com/nod-ai/shark-studio#install-your-hardware-wrivers] أعلاه
قم بتنزيل الإصدار المستقر أو أحدث Shark 1.0 Preease.
انقر نقرًا مزدوجًا على .exe ، أو تشغيل من سطر الأوامر (الموصى به) ، ويجب أن يكون لديك واجهة المستخدم في المتصفح.
إذا كان لديك نماذج مخصصة وضعتها في models/ دليل حيث يكون .exe.
يتمتع.
cd ) إلى مجلد .exe. ثم قم بتشغيل EXE من موجه الأوامر. وبهذه الطريقة ، في حالة حدوث خطأ ، ستتمكن من قطعه ورفعه لطلب المساعدة. (إذا كان يعمل دائمًا من أجلك بدون خطأ ، فيمكنك ببساطة النقر المزدوج إلى EXE)--ui=web عند تشغيل exe. git clone https://github.com/nod-ai/SHARK.git
cd SHARK يتم إعادة بناء سمك القرش حاليًا للتوربينات في الفرع main . في الوقت الحالي ، تشعر بالإحباط بشدة من استخدام main ما لم تكن تعمل على جهد إعادة البناء ، ويجب ألا تتوقع أن تنتج الكود هناك تطبيقًا عملًا لتوليد الصور ، لذلك ستحتاج الآن إلى التبديل إلى فرع SHARK-1.0 واستخدام الرمز المستقر.
git checkout SHARK-1.0تفترض تعليمات الإعداد التالية أنك في هذا الفرع.
set-executionpolicy remotesigned. / setup_venv.ps1 # You can re-run this script to get the latest version./setup_venv.sh
source shark1.venv/bin/activate(shark1.venv) PS C:gshark > cd .appsstable_diffusionweb
(shark1.venv) PS C:gsharkappsstable_diffusionweb > python .index.py(shark1.venv) > cd apps/stable_diffusion/web
(shark1.venv) > python index.py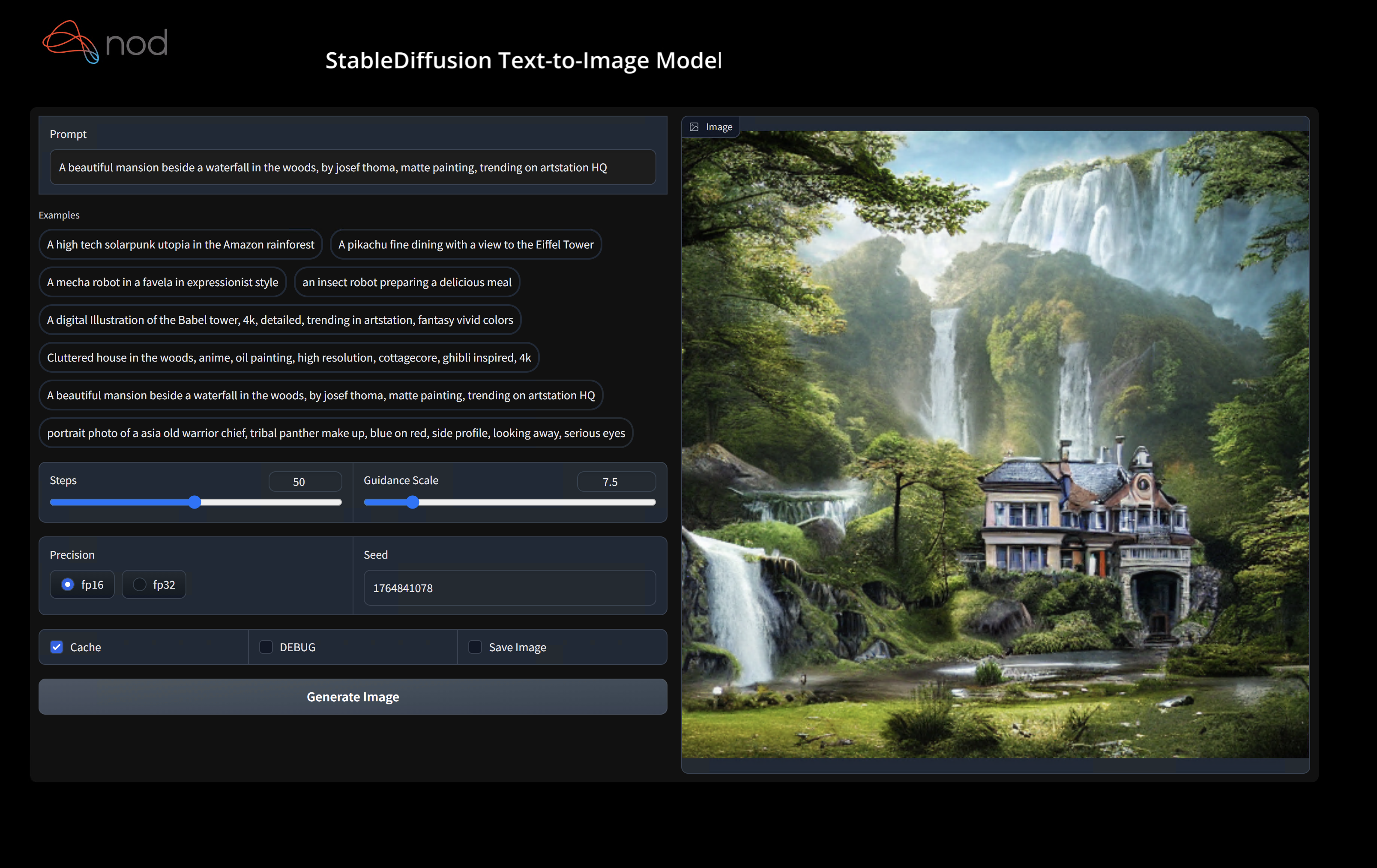
(shark1.venv) PS C:gshark > python .appsstable_diffusionscriptsmain.py -- app = " txt2img " -- precision = " fp16 " -- prompt = " tajmahal, snow, sunflowers, oil on canvas " -- device = " vulkan " python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt= " tajmahal, oil on canvas, sunflowers, 4k, uhd " يمكنك استبدال vulkan بوحدة cpu لتشغيل على وحدة المعالجة المركزية أو مع cuda لتشغيل على أجهزة CUDA. إذا كان لديك العديد من أجهزة Vulkan ، فيمكنك معالجتها مع --device=vulkan://1 إلخ
سيبدو الإخراج على AMD 7900XTX شيئًا مثل:
Average step time: 47.19188690185547ms/it
Clip Inference time (ms) = 109.531
VAE Inference time (ms): 78.590
Total image generation time: 2.5788655281066895secفيما يلي بعض العينات التي تم إنشاؤها:


ابحث عننا على خادم Discord Shark إذا كان لديك أي مشكلة في تشغيله على أجهزتك.
تقوم هذه الخطوة بإعداد VirtualEnv جديد لـ Python
python --version # Check you have 3.11 on Linux, macOS or Windows Powershell
python -m venv shark_venv
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
# If you are using conda create and activate a new conda env
# Some older pip installs may not be able to handle the recent PyTorch deps
python -m pip install --upgrade pipMACOS Metal Users يرجى تثبيت https://sdk.lunarg.com/sdk/download/latest/mac/vulkan-sdk.dmg وتمكين "تثبيت النظام على نطاق واسع"
تقوم هذه الخطوة PIP بتثبيت سمك القرش والحزم ذات الصلة على Linux Python 3.8 و 3.10 و 3.11 و MacOS / Windows Python 3.11
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpupytest tank/test_models.pyانظر Tank/README.MD للحصول على تجول أكثر تفصيلاً من جناحنا و CLI.
curl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/resnet50_script.py
# Install deps for test script
pip install --pre torch torchvision torchaudio tqdm pillow gsutil --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./resnet50_script.py --device= " cpu " # use cuda or vulkan or metalcurl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/minilm_jit.py
# Install deps for test script
pip install transformers torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./minilm_jit.py --device= " cpu " # use cuda or vulkan or metal إذا كنت ترغب في استخدام Python3.11 ومع أدوات استيراد TF ، يمكنك استخدام متغيرات البيئة مثل: SET USE_IREE=1 لاستخدام المنبع IREE
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
python -m shark.examples.shark_inference.resnet50_script --device= " cpu " # Use gpu | vulkan
# Or a pytest
pytest tank/test_models.py -k " MiniLM " إذا كنت مطورًا شعلة MLIR أو مطورًا IREE وترغب في اختبار التغييرات المحلية ، فيمكنك إلغاء تثبيت الحزم المقدمة باستخدام pip uninstall torch-mlir و / أو pip uninstall iree-compiler iree-runtime وبناء محليًا مع روابط Python وتعيين Pythonpath الخاص بك كما هو مذكور هنا في Irie و Torch-Mlir.
كيفية استخدام Torch-Mlir المدمج محليًا مع سمك القرش:
1.) Run ` ./setup_venv.sh in SHARK ` and activate ` shark.venv ` virtual env.
2.) Run ` pip uninstall torch-mlir ` .
3.) Go to your local Torch-MLIR directory.
4.) Activate mlir_venv virtual envirnoment.
5.) Run ` pip uninstall -r requirements.txt ` .
6.) Run ` pip install -r requirements.txt ` .
7.) Build Torch-MLIR.
8.) Activate shark.venv virtual environment from the Torch-MLIR directory.
8.) Run ` export PYTHONPATH= ` pwd ` /build/tools/torch-mlir/python_packages/torch_mlir: ` pwd ` /examples ` in the Torch-MLIR directory.
9.) Go to the SHARK directory.الآن سوف تستخدم القرش الخاص بك بناء شعلة شعلة محلية.
لإنتاج معايير للإرسالات الفردية ، يمكنك إضافة --dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir> إلى وسيطة سطر الأوامر pytest الخاصة بك. إذا كنت تريد فقط تجميع عمليات إرسال محددة ، فيمكنك تحديدها بسلسلة منفصلة للمساحة بدلاً من "All" . على سبيل المثال --dispatch_benchmarks="0 1 2 10"
على سبيل المثال ، لإنشاء وتشغيل معايير الإرسال للوميمة على كودا:
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
سوف يملأ الأمر المعطى <dispatch_benchmarks_dir>/<model_name>/ باستخدام ordered_dispatches.txt الذي يسرد ويأمر الإرسالات والكمايا الخاصة بها ، وكذلك مجلدات لكل إرسال تحتوي
إذا كنت ترغب بدلاً من ذلك في دمج هذا في نص Python ، فيمكنك تمرير أوامر dispatch_benchmarks وأوامر dispatch_benchmarks_dir عند تهيئة SharkInference ، وسيتم إنشاء المعايير عند تجميعها. على سبيل المثال:
shark_module = SharkInference(
mlir_model,
device=args.device,
mlir_dialect="tm_tensor",
dispatch_benchmarks="all",
dispatch_benchmarks_dir="results"
)
سيشمل الإخراج:
انظر Tank/README.MD للحصول على مزيد من الإرشادات حول كيفية تشغيل اختبارات النموذج والمعايير من خزان Shark.
from shark.shark_importer import SharkImporter
# SharkImporter imports mlir file from the torch, tensorflow or tf-lite module.
mlir_importer = SharkImporter(
torch_module,
(input),
frontend="torch", #tf, #tf-lite
)
torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
# SharkInference accepts mlir in linalg, mhlo, and tosa dialect.
from shark.shark_inference import SharkInference
shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg")
shark_module.compile()
result = shark_module.forward((input))
from shark.shark_inference import SharkInference
import numpy as np
mhlo_ir = r"""builtin.module {
func.func @forward(%arg0: tensor<1x4xf32>, %arg1: tensor<4x1xf32>) -> tensor<4x4xf32> {
%0 = chlo.broadcast_add %arg0, %arg1 : (tensor<1x4xf32>, tensor<4x1xf32>) -> tensor<4x4xf32>
%1 = "mhlo.abs"(%0) : (tensor<4x4xf32>) -> tensor<4x4xf32>
return %1 : tensor<4x4xf32>
}
}"""
arg0 = np.ones((1, 4)).astype(np.float32)
arg1 = np.ones((4, 1)).astype(np.float32)
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
shark_module.compile()
result = shark_module.forward((arg0, arg1))
يتم الحفاظ على سمك القرش لدعم أحدث الابتكارات في نماذج ML:
| طرز TF Huggingface | Shark-CPU | سمك القرش | سمك القرش المعدني |
|---|---|---|---|
| بيرت | |||
| Distilbert | |||
| GPT2 | |||
| يزدهر | |||
| انتشار مستقر | |||
| محول الرؤية | |||
| RESNET50 |
للحصول على قائمة كاملة بالنماذج المدعومة في Shark ، يرجى الرجوع إلى Tank/README.MD.
#torch-mlir Channel على Discord LLVM - هذه هي قناة الاتصال الأكثر نشاطًاtorch-mlir في خطاب LLVMNOD.AI Shark مرخصة بموجب شروط ترخيص Apache 2.0 مع استثناءات LLVM. انظر الترخيص لمزيد من المعلومات.


