SHARK Studio
nod.ai SHARK 20240531.1300
Hochleistungsverteilung für maschinelles Lernen
Derzeit bauen wir Hai wieder auf, um die Turbine zu nutzen. Bis zu diesem Zeitpunkt sind Sie sicher, dass Sie eine .exe-Veröffentlichung oder einen Checkout der SHARK-1.0 Niederlassung für einen Arbeitshai verwenden
Andere Benutzer bitte stellen Sie vulkaninfo
Installieren Sie den Treiber von (Voraussetzungen) [https://github.com/nod-ai/shark-studio#install-your-hardware-grivers] oben]
Laden Sie die stabile Veröffentlichung oder den neuesten Shark 1.0 Pre-Release herunter.
Doppelklicken Sie auf die .exe oder führen Sie aus der Befehlszeile aus (empfohlen), und Sie sollten die Benutzeroberfläche im Browser haben.
Wenn Sie benutzerdefinierte Modelle haben, stellen Sie sie in ein models/ Verzeichnis, in dem sich der .exe befindet.
Genießen.
cd ) in den .exe -Ordner. Führen Sie dann die Exe aus der Eingabeaufforderung aus. Wenn ein Fehler auftritt, können Sie ihn schneiden und einteilen, um um Hilfe zu bitten. (Wenn es ohne Fehler immer für Sie funktioniert, doppelklicken Sie einfach auf die Exe)--ui=web -Befehls -Argument, wenn Sie das EXE ausführen. git clone https://github.com/nod-ai/SHARK.git
cd SHARK Derzeit wird Shark in der main für Turbine umgebaut. Im Moment sind Sie von der Verwendung main nachdrücklich entmutigt, es sei denn, Sie arbeiten an den Wiederaufbauanstrengungen und sollten nicht erwarten, dass der Code dort eine Arbeitsanwendung für die Bilderzeugung erstellt. Sie müssen also vorerst in den SHARK-1.0 Zweig umstellen und den stabilen Code verwenden.
git checkout SHARK-1.0In den folgenden Einrichtungsanweisungen geht hervor, dass Sie sich in diesem Zweig befinden.
set-executionpolicy remotesigned. / setup_venv.ps1 # You can re-run this script to get the latest version./setup_venv.sh
source shark1.venv/bin/activate(shark1.venv) PS C:gshark > cd .appsstable_diffusionweb
(shark1.venv) PS C:gsharkappsstable_diffusionweb > python .index.py(shark1.venv) > cd apps/stable_diffusion/web
(shark1.venv) > python index.py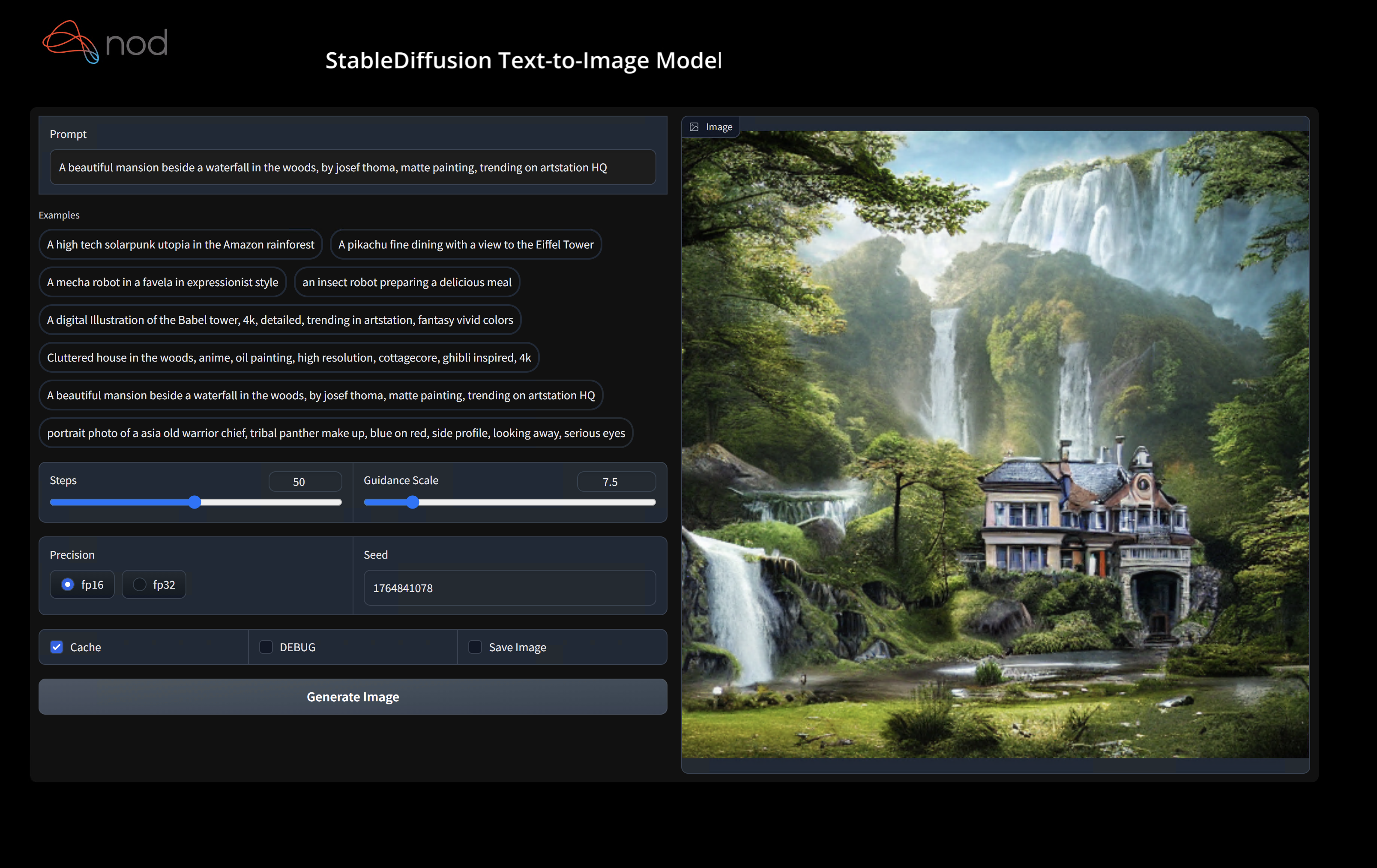
(shark1.venv) PS C:gshark > python .appsstable_diffusionscriptsmain.py -- app = " txt2img " -- precision = " fp16 " -- prompt = " tajmahal, snow, sunflowers, oil on canvas " -- device = " vulkan " python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt= " tajmahal, oil on canvas, sunflowers, 4k, uhd " Sie können vulkan durch cpu ersetzen, um auf Ihrer CPU oder durch cuda zu laufen, um auf CUDA -Geräten zu laufen. Wenn Sie mehrere Vulkan -Geräte haben, können Sie sie mit --device=vulkan://1 usw. ansprechen
Die Ausgabe eines AMD 7900XTX würde ungefähr aussehen wie:
Average step time: 47.19188690185547ms/it
Clip Inference time (ms) = 109.531
VAE Inference time (ms): 78.590
Total image generation time: 2.5788655281066895secHier sind einige Proben erzeugt:


Finden Sie uns auf dem Shark Discord Server, wenn Sie Probleme haben, es auf Ihrer Hardware auszuführen.
In diesem Schritt wird ein neues Virtualenv für Python eingerichtet
python --version # Check you have 3.11 on Linux, macOS or Windows Powershell
python -m venv shark_venv
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
# If you are using conda create and activate a new conda env
# Some older pip installs may not be able to handle the recent PyTorch deps
python -m pip install --upgrade pipMacOS-Metallbenutzer bitte installieren
Dieser Schritt -PIP installiert Hai und zugehörige Pakete unter Linux Python 3.8, 3.10 und 3.11 sowie MacOS / Windows Python 3.11
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpupytest tank/test_models.pyIn Tank/Readme.md finden Sie eine detailliertere Exemplar unserer PyTest Suite und CLI.
curl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/resnet50_script.py
# Install deps for test script
pip install --pre torch torchvision torchaudio tqdm pillow gsutil --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./resnet50_script.py --device= " cpu " # use cuda or vulkan or metalcurl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/minilm_jit.py
# Install deps for test script
pip install transformers torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu
python ./minilm_jit.py --device= " cpu " # use cuda or vulkan or metal Wenn Sie Python3.11 und mit TF -Import -Tools verwenden USE_IREE=1
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
python -m shark.examples.shark_inference.resnet50_script --device= " cpu " # Use gpu | vulkan
# Or a pytest
pytest tank/test_models.py -k " MiniLM " Wenn Sie ein Torch-Mlir-Entwickler oder ein IREE-Entwickler sind und lokale Änderungen testen möchten, können Sie die bereitgestellten Pakete mit pip uninstall torch-mlir und / oder pip uninstall iree-compiler iree-runtime Deinstallation Deinstallieren und mit Python-Bindungen aufbauen und Ihren Pythonpath wie für Iree und hier für Torch-Mlir einstellen.
So verwenden Sie Ihr lokal gebautes Torch-Mlir mit Hai:
1.) Run ` ./setup_venv.sh in SHARK ` and activate ` shark.venv ` virtual env.
2.) Run ` pip uninstall torch-mlir ` .
3.) Go to your local Torch-MLIR directory.
4.) Activate mlir_venv virtual envirnoment.
5.) Run ` pip uninstall -r requirements.txt ` .
6.) Run ` pip install -r requirements.txt ` .
7.) Build Torch-MLIR.
8.) Activate shark.venv virtual environment from the Torch-MLIR directory.
8.) Run ` export PYTHONPATH= ` pwd ` /build/tools/torch-mlir/python_packages/torch_mlir: ` pwd ` /examples ` in the Torch-MLIR directory.
9.) Go to the SHARK directory.Jetzt wird der Hai Ihr lokales Fackel-Mlir-Repo verwenden.
Um Benchmarks einzelner Versand zu erzeugen, können Sie Ihrem PyTest -Befehlszeilenargument addieren --dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir> . Wenn Sie nur bestimmte Versender kompilieren möchten, können Sie sie mit einer von Speicherplatz getrennten Zeichenfolge anstelle von "All" angeben. EG --dispatch_benchmarks="0 1 2 10"
Zum Beispiel zum Generieren und Ausführen von Versandbenchmarks für Minilm auf CUDA:
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
Der angegebene Befehl füllt <dispatch_benchmarks_dir>/<model_name>/ mit einer ordered_dispatches.txt , in der die Versand und deren Latenzen sowie Ordner für jeden Dispatch, der .Mlir, .vmfb und die Ergebnisse des Benchmarks für diesen Dispatch enthalten, auflistet und bestellt.
Wenn Sie dies stattdessen in ein Python -Skript einbeziehen möchten, können Sie bei der Initialisierung von SharkInference die Befehle dispatch_benchmarks und dispatch_benchmarks_dir übergeben, und die Benchmarks werden beim Zusammenstellen erzeugt. Z.B:
shark_module = SharkInference(
mlir_model,
device=args.device,
mlir_dialect="tm_tensor",
dispatch_benchmarks="all",
dispatch_benchmarks_dir="results"
)
Die Ausgabe umfasst:
Weitere Anweisungen zum Ausführen von Modelltests und Benchmarks aus dem Haifischtank finden Sie unter Tank/Readme.md.
from shark.shark_importer import SharkImporter
# SharkImporter imports mlir file from the torch, tensorflow or tf-lite module.
mlir_importer = SharkImporter(
torch_module,
(input),
frontend="torch", #tf, #tf-lite
)
torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
# SharkInference accepts mlir in linalg, mhlo, and tosa dialect.
from shark.shark_inference import SharkInference
shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg")
shark_module.compile()
result = shark_module.forward((input))
from shark.shark_inference import SharkInference
import numpy as np
mhlo_ir = r"""builtin.module {
func.func @forward(%arg0: tensor<1x4xf32>, %arg1: tensor<4x1xf32>) -> tensor<4x4xf32> {
%0 = chlo.broadcast_add %arg0, %arg1 : (tensor<1x4xf32>, tensor<4x1xf32>) -> tensor<4x4xf32>
%1 = "mhlo.abs"(%0) : (tensor<4x4xf32>) -> tensor<4x4xf32>
return %1 : tensor<4x4xf32>
}
}"""
arg0 = np.ones((1, 4)).astype(np.float32)
arg1 = np.ones((4, 1)).astype(np.float32)
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
shark_module.compile()
result = shark_module.forward((arg0, arg1))
Shark wird unterhalten, um die neuesten Innovationen in ML -Modellen zu unterstützen:
| TF -Umarmungsface -Modelle | Shark-CPU | Haifisch-Cuda | Haifischmetall |
|---|---|---|---|
| Bert | |||
| Distilbert | |||
| Gpt2 | |||
| BLÜHEN | |||
| Stabile Diffusion | |||
| Vision Transformator | |||
| Resnet50 |
Eine vollständige Liste der in Shark unterstützten Modelle finden Sie unter Tank/Readme.md.
#torch-mlir -Kanal auf der LLVM -Zwietracht - Dies ist der aktivste Kommunikationskanaltorch-mlir Abschnitt des LLVM-DiskursesNod.ai Shark ist unter den Bestimmungen der Apache 2.0 -Lizenz mit LLVM -Ausnahmen lizenziert. Weitere Informationen finden Sie unter Lizenz.


