neuspell
1.0.0
Neuspell: инструментарий для коррекции нервного орфографии
neuspell теперь доступен через PIP . Смотрите установку через PIPBERT теперь доступна как часть моделей HuggingFace, как murali1996/bert-base-cased-spell-correction . Мы предоставляем пример фрагмента кода по адресу ./scripts/huggingface для любопытных практикующих.git clone https://github.com/neuspell/neuspell ; cd neuspell
pip install -e .Чтобы установить дополнительные требования,
pip install -r extras-requirements.txtили индивидуально как:
pip install -e .[elmo]
pip install -e .[spacy]Примечание. Для ZSH используйте ". [Elmo]" и ". [Spacy]" Вместо этого
Кроме того, spacy models могут быть загружены как:
python -m spacy download en_core_web_sm Затем загрузите предварительные модели neuspell после загрузки контрольных точек
Вот быстрый фрагмент кода (использование командной строки) для использования модели шашки. См. Test_neuspell_correctors.py для получения дополнительной информации.
import neuspell
from neuspell import available_checkers , BertChecker
""" see available checkers """
print ( f"available checkers: { neuspell . available_checkers () } " )
# → available checkers: ['BertsclstmChecker', 'CnnlstmChecker', 'NestedlstmChecker', 'SclstmChecker', 'SclstmbertChecker', 'BertChecker', 'SclstmelmoChecker', 'ElmosclstmChecker']
""" select spell checkers & load """
checker = BertChecker ()
checker . from_pretrained ()
""" spell correction """
checker . correct ( "I luk foward to receving your reply" )
# → "I look forward to receiving your reply"
checker . correct_strings ([ "I luk foward to receving your reply" , ])
# → ["I look forward to receiving your reply"]
checker . correct_from_file ( src = "noisy_texts.txt" )
# → "Found 450 mistakes in 322 lines, total_lines=350"
""" evaluation of models """
checker . evaluate ( clean_file = "bea60k.txt" , corrupt_file = "bea60k.noise.txt" )
# → data size: 63044
# → total inference time for this data is: 998.13 secs
# → total token count: 1032061
# → confusion table: corr2corr:940937, corr2incorr:21060,
# incorr2corr:55889, incorr2incorr:14175
# → accuracy is 96.58%
# → word correction rate is 79.76%В качестве альтернативы, однажды может также выбрать и загрузить проверку орфографии по -разному следующим образом:
from neuspell import SclstmChecker
checker = SclstmChecker ()
checker = checker . add_ ( "elmo" , at = "input" ) # "elmo" or "bert", "input" or "output"
checker . from_pretrained ()Эта функция добавления модели ELMO или BERT в настоящее время поддерживается для выбранных моделей. Смотрите список нейронных моделей в инструментарии для деталей.
Если заинтересовано, следуйте дополнительным требованиям для установки ненуранных шашек орфографии- Aspell и Jamspell .
pip install neuspell В v1.0 библиотека allennlp не установлена автоматически, которая используется для моделей, содержащих ELMO. Следовательно, чтобы использовать эти шашки, выполните установку источника, как в установке и быстрое запуск
Neuspell-это инструментарий с открытым исходным кодом для контекстной коррекции орфографии на английском языке. Этот инструментарий состоит из 10 контролеров орфографии, с оценками на естественных ошибках из нескольких (общедоступных) источников. Чтобы создать нейронные модели для проверки орфографии зависимым от контекста, (i) мы обучаем нейронные модели, используя орфографические ошибки в контексте, синтетически построенные с помощью изолированных ошибок в обратном инженере; и (ii) использовать более богатые представления контекста. Этот инструментарий позволяет практикующим НЛП использовать наши предлагаемые и существующие системы коррекции орфографии, как через простую унифицированную командную строку, так и веб -интерфейс. Среди многих потенциальных приложений мы демонстрируем полезность наших проверки орфографии в борьбе с состязательными ошибками.
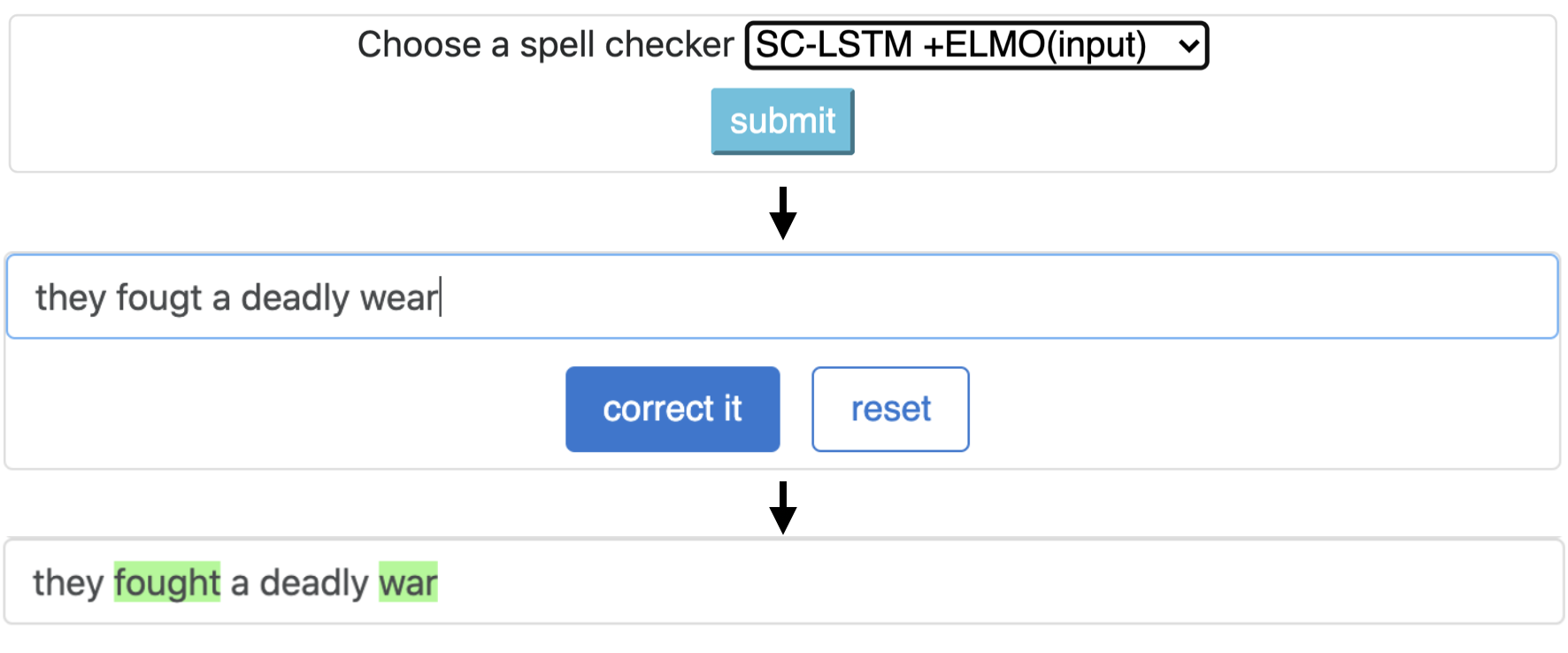
CNN-LSTMSC-LSTMNested-LSTMBERTSC-LSTM plus ELMO (at input)SC-LSTM plus ELMO (at output)SC-LSTM plus BERT (at input)SC-LSTM plus BERT (at output)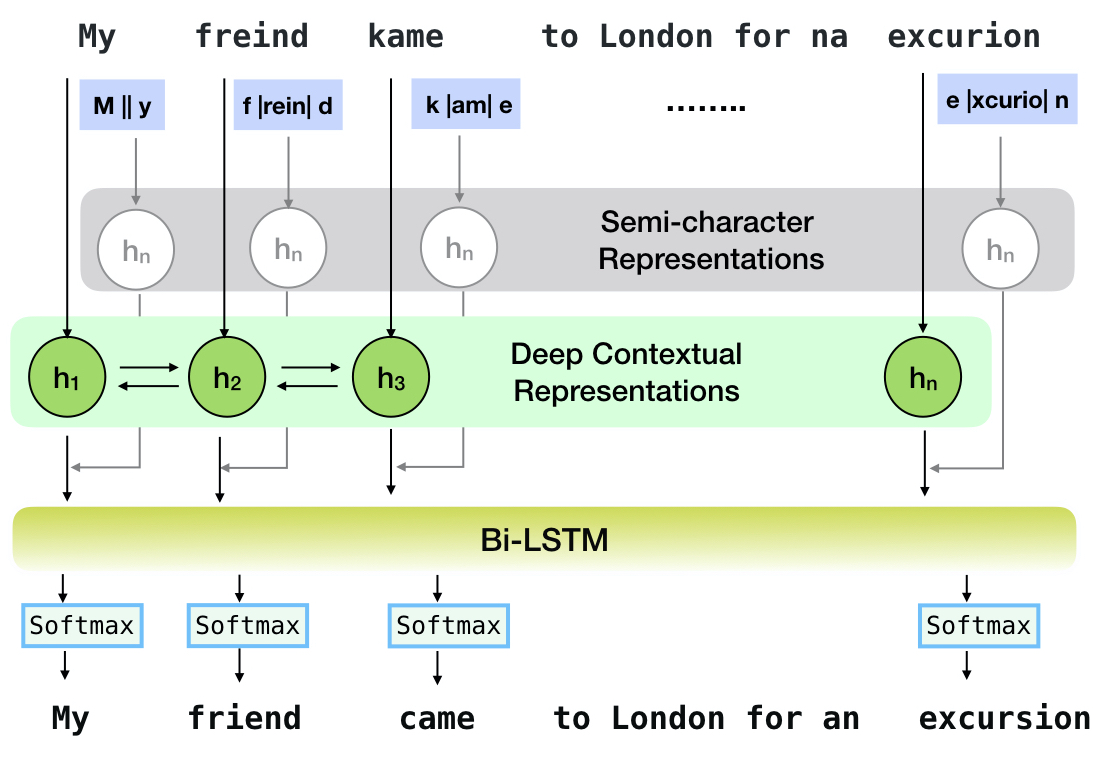
Этот конвейер соответствует модели `sc-lstm плюс elmo (при входе)`.
| Заклинание Проверка | Слово Коррекция Ставка | Время пер предложение (в миллисекундах) |
|---|---|---|
Aspell | 48.7 | 7.3* |
Jamspell | 68.9 | 2.6* |
CNN-LSTM | 75,8 | 4.2 |
SC-LSTM | 76.7 | 2.8 |
Nested-LSTM | 77.3 | 6.4 |
BERT | 79,1 | 7.1 |
SC-LSTM plus ELMO (at input) | 79,8 | 15.8 |
SC-LSTM plus ELMO (at output) | 78.5 | 16.3 |
SC-LSTM plus BERT (at input) | 77.0 | 6.7 |
SC-LSTM plus BERT (at output) | 76.0 | 7.2 |
Производительность различных корректоров в инструментарии Neuspell на наборе данных BEA-60K с реальными ошибками правописания. ∗ Указывает оценку на процессоре (для других мы используем графический процессор GeForce RTX 2080 TI).
Чтобы загрузить выбранные контрольно -пропускные пункты, выберите имя контрольной точки снизу, а затем запустите загрузку. Каждая контрольная точка связана с проверкой нейронной орфографии, как показано в таблице.
| Проверка орфографии | Сорт | Имя контрольной точки | Дисковое пространство (ок.) |
|---|---|---|---|
CNN-LSTM | CnnlstmChecker | 'cnn-lstm-probwordnoise' | 450 МБ |
SC-LSTM | SclstmChecker | 'scrnn-probwordnoise' | 450 МБ |
Nested-LSTM | NestedlstmChecker | 'lstm-lstm-probwordnoise' | 455 МБ |
BERT | BertChecker | 'subwordbert-probwordnoise' | 740 МБ |
SC-LSTM plus ELMO (at input) | ElmosclstmChecker | 'elmoscrnn-probwordnoise' | 840 МБ |
SC-LSTM plus BERT (at input) | BertsclstmChecker | 'bertscrnn-probwordnoise' | 900 МБ |
SC-LSTM plus BERT (at output) | SclstmbertChecker | 'scrnnbert-probwordnoise' | 1,19 ГБ |
SC-LSTM plus ELMO (at output) | SclstmelmoChecker | 'scrnnelmo-probwordnoise' | 1,23 ГБ |
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "subwordbert-probwordnoise" )В качестве альтернативы, загрузите все нейронные модели Neuspell, выполнив следующее (доступно в версиях после v1.0):
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "_all_" )Альтернативно,
Мы курируем несколько синтетических и естественных наборов данных для обучения/оценки моделей Neuspell. Для получения полной информации, проверьте нашу газету. Запустите следующее, чтобы загрузить все наборы данных.
cd data/traintest
python download_datafiles.py
См. data/traintest/README.md для получения более подробной информации.
Файлы поезда называют именами .random , .word , .prob , .probword для различных стартовых запуска, используемых для их создания. Для каждой стратегии (см. Создание синтетических данных) мы шумим ~ 20% токенов в чистом корпусе. Мы используем 1,6 миллиона предложений из набора One billion word benchmark в качестве нашего чистого корпуса.
Чтобы настроить демонстрацию, следуйте этим шагам:
pip install -e ".[flask]"CUDA_VISIBLE_DEVICES=0 python app.py (на GPU) или python app.py (на процессоре) Этот инструментарий предлагает 3 вида стратегии номезирования (идентифицированные от существующей литературы) для создания синтетических параллельных данных обучения для обучения нейронных моделей для коррекции заклинаний. Стратегии включают в себя простую шумную замену орфографии, основанную на поиске ( en-word-replacement-noise ), индукцию шума на уровне персонажа, такую как обмена/удаление/добавление/замену символов ( en-char-replacement-noise ), а также стержня на основе вероятностной замены символов, вызванных ошибками в широком корпусе ошибки ( en-probchar-replacement-noise no. Для получения полной информации об этих подходах проверьте нашу статью.
Ниже приведены соответствующие сопоставления классов для использования вышеуказанных курирования шума. Поскольку некоторые предварительно построенные файлы данных используются для некоторых шумов, мы также предоставляем их приблизительное пространство диска.
| Папка | Название класса | Дисковое пространство (ок.) |
|---|---|---|
en-word-replacement-noise | WordReplacementNoiser | 2 МБ |
en-char-replacement-noise | CharacterReplacementNoiser | - |
en-probchar-replacement-noise | ProbabilisticCharacterReplacementNoiser | 80 МБ |
Ниже приведен фрагмент для использования этих шумов-
from neuspell . noising import WordReplacementNoiser
example_texts = [
"This is an example sentence to demonstrate noising in the neuspell repository." ,
"Here is another such amazing example !!"
]
word_repl_noiser = WordReplacementNoiser ( language = "english" )
word_repl_noiser . load_resources ()
noise_texts = word_repl_noiser . noise ( example_texts )
print ( noise_texts ) Coming Soon ...
neuspell from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained ()
checker . finetune ( clean_file = "sample_clean.txt" , corrupt_file = "sample_corrupt.txt" , data_dir = "default" ) Эта функция доступна только для BertChecker и ElmosclstmChecker .
Теперь мы поддерживаем инициализацию модели HuggingFace и создавать ее на пользовательских данных. Вот фрагмент кода, демонстрирующий, что:
Сначала отметьте свои файлы, содержащие чистые и коррумпированные тексты в линейном формате
from neuspell . commons import DEFAULT_TRAINTEST_DATA_PATH
data_dir = DEFAULT_TRAINTEST_DATA_PATH
clean_file = "sample_clean.txt"
corrupt_file = "sample_corrupt.txt" from neuspell . seq_modeling . helpers import load_data , train_validation_split
from neuspell . seq_modeling . helpers import get_tokens
from neuspell import BertChecker
# Step-0: Load your train and test files, create a validation split
train_data = load_data ( data_dir , clean_file , corrupt_file )
train_data , valid_data = train_validation_split ( train_data , 0.8 , seed = 11690 )
# Step-1: Create vocab file. This serves as the target vocab file and we use the defined model's default huggingface
# tokenizer to tokenize inputs appropriately.
vocab = get_tokens ([ i [ 0 ] for i in train_data ], keep_simple = True , min_max_freq = ( 1 , float ( "inf" )), topk = 100000 )
# # Step-2: Initialize a model
checker = BertChecker ( device = "cuda" )
checker . from_huggingface ( bert_pretrained_name_or_path = "distilbert-base-cased" , vocab = vocab )
# Step-3: Finetune the model on your dataset
checker . finetune ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir )Вы можете дополнительно оценить свою модель на пользовательских данных следующим образом:
from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained (
bert_pretrained_name_or_path = "distilbert-base-cased" ,
ckpt_path = f" { data_dir } /new_models/distilbert-base-cased" # "<folder where the model is saved>"
)
checker . evaluate ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir ) После использования выше, когда-то теперь может беспрепятственно использовать многоязычные модели, такие как xlm-roberta-base , bert-base-multilingual-cased , и distilbert-base-multilingual-cased в неанглийском сценарии.
./applications/Adversarial-Misspellings-arxiv . Смотрите readme.md. Требования к Aspell Checker:
wget https://files.pythonhosted.org/packages/53/30/d995126fe8c4800f7a9b31aa0e7e5b2896f5f84db4b7513df746b2a286da/aspell-python-py3-1.15.tar.bz2
tar -C . -xvf aspell-python-py3-1.15.tar.bz2
cd aspell-python-py3-1.15
python setup.py install
Требования к проверке Jamspell :
sudo apt-get install -y swig3.0
wget -P ./ https://github.com/bakwc/JamSpell-models/raw/master/en.tar.gz
tar xf ./en.tar.gz --directory ./
@inproceedings{jayanthi-etal-2020-neuspell,
title = "{N}eu{S}pell: A Neural Spelling Correction Toolkit",
author = "Jayanthi, Sai Muralidhar and
Pruthi, Danish and
Neubig, Graham",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.21",
doi = "10.18653/v1/2020.emnlp-demos.21",
pages = "158--164",
abstract = "We introduce NeuSpell, an open-source toolkit for spelling correction in English. Our toolkit comprises ten different models, and benchmarks them on naturally occurring misspellings from multiple sources. We find that many systems do not adequately leverage the context around the misspelt token. To remedy this, (i) we train neural models using spelling errors in context, synthetically constructed by reverse engineering isolated misspellings; and (ii) use richer representations of the context. By training on our synthetic examples, correction rates improve by 9{%} (absolute) compared to the case when models are trained on randomly sampled character perturbations. Using richer contextual representations boosts the correction rate by another 3{%}. Our toolkit enables practitioners to use our proposed and existing spelling correction systems, both via a simple unified command line, as well as a web interface. Among many potential applications, we demonstrate the utility of our spell-checkers in combating adversarial misspellings. The toolkit can be accessed at neuspell.github.io.",
}
Ссылка для публикации. Любые вопросы или предложения, пожалуйста, свяжитесь с авторами jsaimurali001 [at] gmail [dot] com


