neuspell
1.0.0
Neuspell: un conjunto de herramientas de corrección de ortografía neuronal
neuspell ahora está disponible a través de PIP . Ver instalación a través de PIPBERT de Neuspell ahora está disponible como parte de los modelos Huggingface como murali1996/bert-base-cased-spell-correction . Proporcionamos un fragmento de código de ejemplo en ./scripts/huggingface para profesionales curiosos.git clone https://github.com/neuspell/neuspell ; cd neuspell
pip install -e .Para instalar requisitos adicionales,
pip install -r extras-requirements.txto individualmente como:
pip install -e .[elmo]
pip install -e .[spacy]Nota: Para ZSH , use ". [Elmo]" y ". [Spacy]" en su lugar
Además, spacy models se pueden descargar como:
python -m spacy download en_core_web_sm Luego, descargue los modelos previos a la aparición de neuspell después de descargar los puntos de control
Aquí hay un fragmento de código de inicio rápido (uso de la línea de comandos) para usar un modelo de verificación. Consulte test_neuspell_correctors.py para obtener más patrones de uso.
import neuspell
from neuspell import available_checkers , BertChecker
""" see available checkers """
print ( f"available checkers: { neuspell . available_checkers () } " )
# → available checkers: ['BertsclstmChecker', 'CnnlstmChecker', 'NestedlstmChecker', 'SclstmChecker', 'SclstmbertChecker', 'BertChecker', 'SclstmelmoChecker', 'ElmosclstmChecker']
""" select spell checkers & load """
checker = BertChecker ()
checker . from_pretrained ()
""" spell correction """
checker . correct ( "I luk foward to receving your reply" )
# → "I look forward to receiving your reply"
checker . correct_strings ([ "I luk foward to receving your reply" , ])
# → ["I look forward to receiving your reply"]
checker . correct_from_file ( src = "noisy_texts.txt" )
# → "Found 450 mistakes in 322 lines, total_lines=350"
""" evaluation of models """
checker . evaluate ( clean_file = "bea60k.txt" , corrupt_file = "bea60k.noise.txt" )
# → data size: 63044
# → total inference time for this data is: 998.13 secs
# → total token count: 1032061
# → confusion table: corr2corr:940937, corr2incorr:21060,
# incorr2corr:55889, incorr2incorr:14175
# → accuracy is 96.58%
# → word correction rate is 79.76%Alternativamente, una vez también puede seleccionar y cargar un corrector ortográfico de manera diferente de la siguiente manera:
from neuspell import SclstmChecker
checker = SclstmChecker ()
checker = checker . add_ ( "elmo" , at = "input" ) # "elmo" or "bert", "input" or "output"
checker . from_pretrained ()Esta característica de agregar el modelo ELMO o BERT es actualmente compatible para modelos seleccionados. Consulte la lista de modelos neuronales en el conjunto de herramientas para más detalles.
Si está interesado, siga los requisitos adicionales para instalar correctores ortográficos no neurales: Aspell y Jamspell .
pip install neuspell En V1.0, la biblioteca allennlp no se instala automáticamente, lo que se utiliza para modelos que contienen ELMO. Por lo tanto, para utilizar esos damas, haga una instalación de origen como en Instalación y arranque rápido
Neuspell es un conjunto de herramientas de código abierto para la corrección de ortografía sensible al contexto en inglés. Este conjunto de herramientas consta de 10 correctores ortográficos, con evaluaciones sobre insultos erróneos naturales de múltiples fuentes (disponibles públicamente). Para hacer que los modelos neuronales para el contexto de la corrección ortográfica dependan del contexto, (i) entrenamos modelos neuronales utilizando errores de ortografía en contexto, construidos sintéticamente por la ingeniería inversa aisladas de visiones erróneas aisladas; y (ii) usar representaciones más ricas del contexto. Este conjunto de herramientas permite a los profesionales de la PNL utilizar nuestros sistemas de corrección de ortografía propuestos y existentes, tanto a través de una línea de comandos unificada simple como una interfaz web. Entre muchas aplicaciones potenciales, demostramos la utilidad de nuestros correctores ortográficos para combatir las ortográficas adversas.
CNN-LSTMSC-LSTMNested-LSTMBERTSC-LSTM plus ELMO (at input)SC-LSTM plus ELMO (at output)SC-LSTM plus BERT (at input)SC-LSTM plus BERT (at output)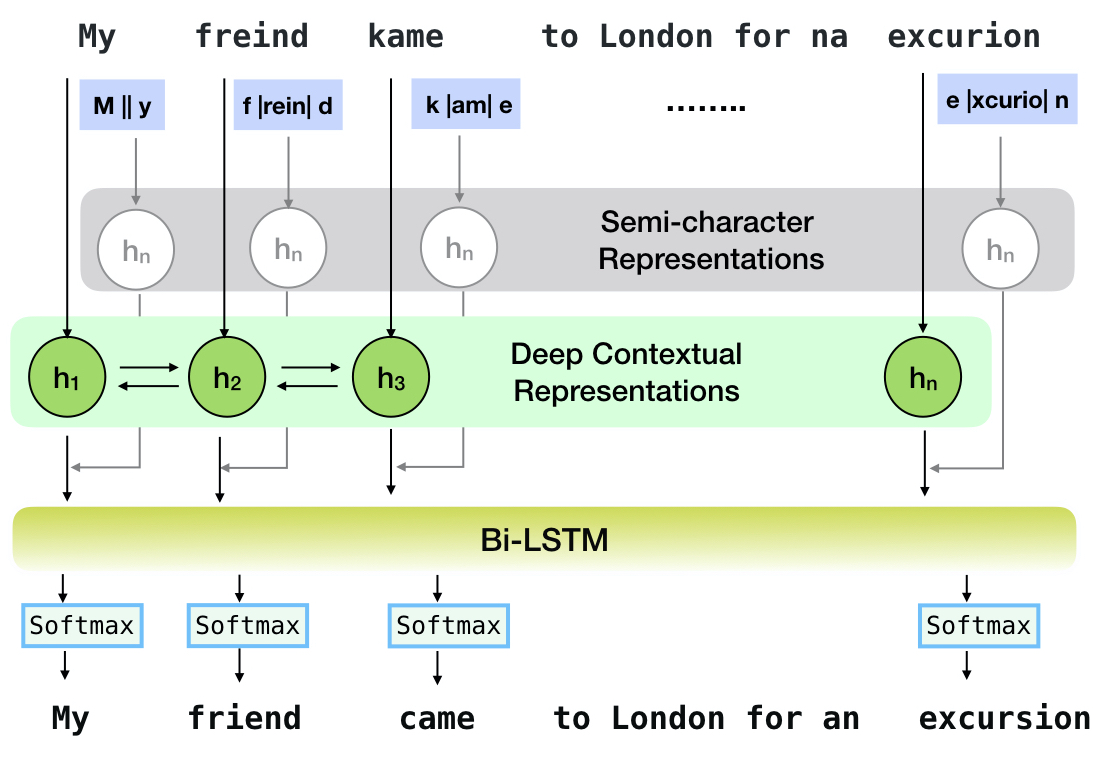
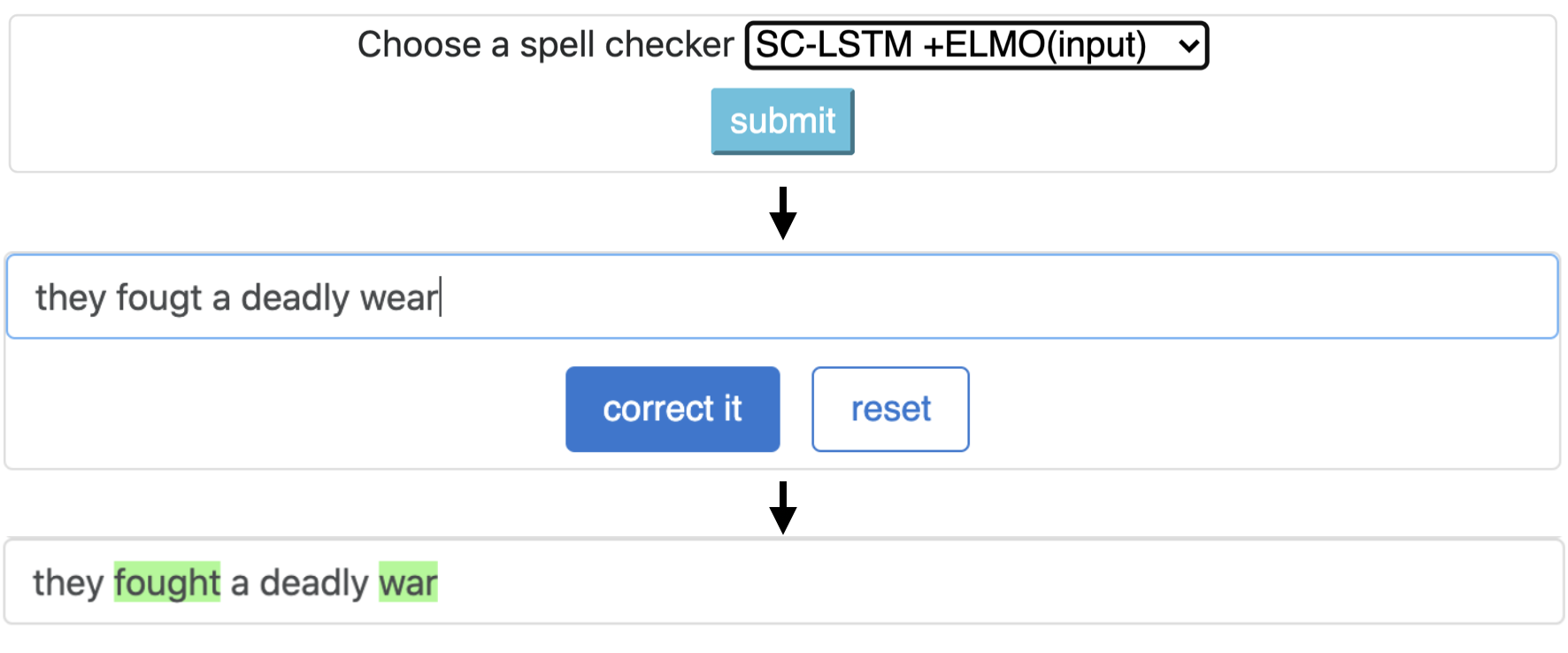
Esta tubería corresponde al modelo `SC-LSTM más ELMO (en entrada)`.
| Deletrear Inspector | Palabra Corrección Tasa | Tiempo por oración (en milisegundos) |
|---|---|---|
Aspell | 48.7 | 7.3* |
Jamspell | 68.9 | 2.6* |
CNN-LSTM | 75.8 | 4.2 |
SC-LSTM | 76.7 | 2.8 |
Nested-LSTM | 77.3 | 6.4 |
BERT | 79.1 | 7.1 |
SC-LSTM plus ELMO (at input) | 79.8 | 15.8 |
SC-LSTM plus ELMO (at output) | 78.5 | 16.3 |
SC-LSTM plus BERT (at input) | 77.0 | 6.7 |
SC-LSTM plus BERT (at output) | 76.0 | 7.2 |
Rendimiento de diferentes correctores en el kit de herramientas Neuspell en el conjunto de datos BEA-60K con errores de ortografía del mundo real. ∗ Indica la evaluación en una CPU (para otros usamos una GPU GeForce RTX 2080 TI).
Para descargar los puntos de control seleccionados, seleccione un nombre de punto de control desde abajo y luego ejecute Descargar. Cada punto de control está asociado con un corrector ortográfico neural como se muestra en la tabla.
| Corrector ortográfico | Clase | Nombre de punto de control | Espacio de disco (aprox.) |
|---|---|---|---|
CNN-LSTM | CnnlstmChecker | 'CNN-LSTM-ProBWordNoise' | 450 MB |
SC-LSTM | SclstmChecker | 'scrnn-proBWordnoise' | 450 MB |
Nested-LSTM | NestedlstmChecker | 'LSTM-LSTM-ProBWordNoise' | 455 MB |
BERT | BertChecker | 'SubwordBert-ProBwordnoise' | 740 MB |
SC-LSTM plus ELMO (at input) | ElmosclstmChecker | 'Elmoscrnn-proBwordnoise' | 840 MB |
SC-LSTM plus BERT (at input) | BertsclstmChecker | 'Bertscrnn-proBWordnoise' | 900 MB |
SC-LSTM plus BERT (at output) | SclstmbertChecker | 'Scrnnbert-proBwordnoise' | 1.19 GB |
SC-LSTM plus ELMO (at output) | SclstmelmoChecker | 'Scrnnelmo-proBwordnoise' | 1.23 GB |
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "subwordbert-probwordnoise" )Alternativamente, descargue todos los modelos neuronales Neuspell ejecutando lo siguiente (disponible en versiones después de V1.0):
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "_all_" )Alternativamente,
Curratamos varios conjuntos de datos sintéticos y naturales para capacitar/evaluar modelos Neuspell. Para obtener detalles completos, consulte nuestro documento. Ejecute lo siguiente para descargar todos los conjuntos de datos.
cd data/traintest
python download_datafiles.py
Consulte data/traintest/README.md para obtener más detalles.
Los archivos de trenes se denominan con nombres .random , .word , .prob , .probword para diferentes inicio de ramas utilizadas para crearlos. Para cada estrategia (ver creación de datos sintéticos), roramos ∼20% de los tokens en el corpus limpio. Utilizamos 1.6 millones de oraciones del conjunto de datos One billion word benchmark como nuestro corpus limpio.
Para configurar una demostración, siga estos pasos:
pip install -e ".[flask]"CUDA_VISIBLE_DEVICES=0 python app.py (en gpu) o python app.py (en CPU) Este kit de herramientas ofrece 3 tipos de estrategias de incumplimiento (identificadas de la literatura existente) para generar datos de entrenamiento paralelos sintéticos para entrenar modelos neuronales para la corrección de hechizos. Las estrategias incluyen un reemplazo de ortografía ruidoso basado en una búsqueda ( en-word-replacement-noise ), una inducción de ruido de nivel de caracteres, como intercambiar/eliminar/agregar/reemplazar los caracteres ( en-char-replacement-noise ), y un problema basado en la matriz de confusión basada en la matriz de reemplazo de problemas de error en un gran Corpus de error de ortografía ( en-probchar-replacement-noise .). Para obtener todos los detalles sobre estos enfoques, consulte nuestro documento.
Las siguientes son las asignaciones de clase correspondientes para utilizar las curaciones de ruido anteriores. A medida que se utilizan algunos archivos de datos preconstruidos para algunos de los ridios, también proporcionamos su espacio de disco aproximado.
| Carpeta | Nombre de clase | Espacio de disco (aprox.) |
|---|---|---|
en-word-replacement-noise | WordReplacementNoiser | 2 MB |
en-char-replacement-noise | CharacterReplacementNoiser | - |
en-probchar-replacement-noise | ProbabilisticCharacterReplacementNoiser | 80 MB |
El siguiente es un fragmento para usar estos ruidos
from neuspell . noising import WordReplacementNoiser
example_texts = [
"This is an example sentence to demonstrate noising in the neuspell repository." ,
"Here is another such amazing example !!"
]
word_repl_noiser = WordReplacementNoiser ( language = "english" )
word_repl_noiser . load_resources ()
noise_texts = word_repl_noiser . noise ( example_texts )
print ( noise_texts ) Coming Soon ...
neuspell Prained from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained ()
checker . finetune ( clean_file = "sample_clean.txt" , corrupt_file = "sample_corrupt.txt" , data_dir = "default" ) Esta característica solo está disponible para BertChecker y ElmosclstmChecker .
Ahora admitimos inicializar un modelo de Huggingface y Finetunging en sus datos personalizados. Aquí hay un fragmento de código que demuestra que:
Primero marque sus archivos que contienen textos limpios y corruptos en un formato de línea de línea
from neuspell . commons import DEFAULT_TRAINTEST_DATA_PATH
data_dir = DEFAULT_TRAINTEST_DATA_PATH
clean_file = "sample_clean.txt"
corrupt_file = "sample_corrupt.txt" from neuspell . seq_modeling . helpers import load_data , train_validation_split
from neuspell . seq_modeling . helpers import get_tokens
from neuspell import BertChecker
# Step-0: Load your train and test files, create a validation split
train_data = load_data ( data_dir , clean_file , corrupt_file )
train_data , valid_data = train_validation_split ( train_data , 0.8 , seed = 11690 )
# Step-1: Create vocab file. This serves as the target vocab file and we use the defined model's default huggingface
# tokenizer to tokenize inputs appropriately.
vocab = get_tokens ([ i [ 0 ] for i in train_data ], keep_simple = True , min_max_freq = ( 1 , float ( "inf" )), topk = 100000 )
# # Step-2: Initialize a model
checker = BertChecker ( device = "cuda" )
checker . from_huggingface ( bert_pretrained_name_or_path = "distilbert-base-cased" , vocab = vocab )
# Step-3: Finetune the model on your dataset
checker . finetune ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir )Puede evaluar más a fondo su modelo con datos personalizados de la siguiente manera:
from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained (
bert_pretrained_name_or_path = "distilbert-base-cased" ,
ckpt_path = f" { data_dir } /new_models/distilbert-base-cased" # "<folder where the model is saved>"
)
checker . evaluate ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir ) Siguiendo el uso anterior, ahora puede utilizar modelos multilingües como xlm-roberta-base , bert-base-multilingual-cased y distilbert-base-multilingual-cased en un script que no es de inglés.
./applications/Adversarial-Misspellings-arxiv . Ver ReadMe.md. Requisitos para el verificador Aspell :
wget https://files.pythonhosted.org/packages/53/30/d995126fe8c4800f7a9b31aa0e7e5b2896f5f84db4b7513df746b2a286da/aspell-python-py3-1.15.tar.bz2
tar -C . -xvf aspell-python-py3-1.15.tar.bz2
cd aspell-python-py3-1.15
python setup.py install
Requisitos para el verificador Jamspell :
sudo apt-get install -y swig3.0
wget -P ./ https://github.com/bakwc/JamSpell-models/raw/master/en.tar.gz
tar xf ./en.tar.gz --directory ./
@inproceedings{jayanthi-etal-2020-neuspell,
title = "{N}eu{S}pell: A Neural Spelling Correction Toolkit",
author = "Jayanthi, Sai Muralidhar and
Pruthi, Danish and
Neubig, Graham",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.21",
doi = "10.18653/v1/2020.emnlp-demos.21",
pages = "158--164",
abstract = "We introduce NeuSpell, an open-source toolkit for spelling correction in English. Our toolkit comprises ten different models, and benchmarks them on naturally occurring misspellings from multiple sources. We find that many systems do not adequately leverage the context around the misspelt token. To remedy this, (i) we train neural models using spelling errors in context, synthetically constructed by reverse engineering isolated misspellings; and (ii) use richer representations of the context. By training on our synthetic examples, correction rates improve by 9{%} (absolute) compared to the case when models are trained on randomly sampled character perturbations. Using richer contextual representations boosts the correction rate by another 3{%}. Our toolkit enables practitioners to use our proposed and existing spelling correction systems, both via a simple unified command line, as well as a web interface. Among many potential applications, we demonstrate the utility of our spell-checkers in combating adversarial misspellings. The toolkit can be accessed at neuspell.github.io.",
}
Enlace para la publicación. Cualquier pregunta o sugerencia, comuníquese con los autores en JSaimurali001 [at] Gmail [Dot] com


