neuspell
1.0.0
Neuspell: Ein Toolkit mit neuronaler Rechtschreibkorrektur
neuspell ist jetzt über PIP erhältlich. Siehe Installation über PIPBERT vorbereiteter Modell ist jetzt als Teil von Huggingface-Modellen als murali1996/bert-base-cased-spell-correction erhältlich. Wir bieten einen Beispiel -Code -Snippet unter ./Scripts/huggingface für neugierige Praktiker.git clone https://github.com/neuspell/neuspell ; cd neuspell
pip install -e .Um zusätzliche Anforderungen zu installieren,
pip install -r extras-requirements.txtoder individuell als:
pip install -e .[elmo]
pip install -e .[spacy]Hinweis: Für ZSH , verwenden Sie stattdessen ". [Elmo]" und ". [Spacy]" stattdessen
Darüber hinaus können spacy models heruntergeladen werden als:
python -m spacy download en_core_web_sm Laden Sie dann vorgezogene Modelle von neuspell nach Download -Checkpoints herunter
Hier ist ein Schnellstart-Code-Snippet (Befehlszeilenverbrauch), um ein Checkermodell zu verwenden. Weitere Verwendungsmuster finden Sie test_neuspell_correctors.py.
import neuspell
from neuspell import available_checkers , BertChecker
""" see available checkers """
print ( f"available checkers: { neuspell . available_checkers () } " )
# → available checkers: ['BertsclstmChecker', 'CnnlstmChecker', 'NestedlstmChecker', 'SclstmChecker', 'SclstmbertChecker', 'BertChecker', 'SclstmelmoChecker', 'ElmosclstmChecker']
""" select spell checkers & load """
checker = BertChecker ()
checker . from_pretrained ()
""" spell correction """
checker . correct ( "I luk foward to receving your reply" )
# → "I look forward to receiving your reply"
checker . correct_strings ([ "I luk foward to receving your reply" , ])
# → ["I look forward to receiving your reply"]
checker . correct_from_file ( src = "noisy_texts.txt" )
# → "Found 450 mistakes in 322 lines, total_lines=350"
""" evaluation of models """
checker . evaluate ( clean_file = "bea60k.txt" , corrupt_file = "bea60k.noise.txt" )
# → data size: 63044
# → total inference time for this data is: 998.13 secs
# → total token count: 1032061
# → confusion table: corr2corr:940937, corr2incorr:21060,
# incorr2corr:55889, incorr2incorr:14175
# → accuracy is 96.58%
# → word correction rate is 79.76%Alternativ können Sie einen Zaubersprüche auch einmal wie folgt auswählen und laden:
from neuspell import SclstmChecker
checker = SclstmChecker ()
checker = checker . add_ ( "elmo" , at = "input" ) # "elmo" or "bert", "input" or "output"
checker . from_pretrained ()Diese Funktion des Hinzufügens von ELMO- oder Bert -Modell wird derzeit für ausgewählte Modelle unterstützt. Weitere Informationen finden Sie in der Liste der neuronalen Modelle im Toolkit.
Befolgen Sie bei Interesse zusätzliche Anforderungen für die Installation von Nicht-Neural- Aspell und Jamspell .
pip install neuspell In V1.0 wird allennlp -Bibliothek nicht automatisch installiert, die für Modelle mit ELMO verwendet wird. Um diese Prüfer zu nutzen, werden daher eine Quelle installiert wie in der Installation und im Schnellstart
Neuspell ist ein Open-Source-Toolkit für die kontextsensitive Rechtschreibkorrektur in Englisch. Dieses Toolkit besteht aus 10 Zauberprüfern mit Auswertungen zu natürlich vorkommenden Fehlschriften aus mehreren (öffentlich verfügbaren) Quellen. Um neuronale Modelle für den Kontext der Zauberprüfung abhängig zu machen, schulen wir neuronale Modelle anhand von Rechtschreibfehlern im Kontext, die synthetisch durch Reverse Engineering isolierte Fehlzellungen konstruiert wurden. und (ii) verwendete reichere Darstellungen des Kontextes. Mit diesem Toolkit können NLP -Praktiker unsere vorgeschlagenen und vorhandenen Rechtschreibkorrektursysteme sowohl über eine einfache Einheitliche Befehlszeile als auch eine Weboberfläche verwenden. Unter vielen potenziellen Anwendungen demonstrieren wir den Nutzen unserer Rechtschreibprüfung bei der Bekämpfung von kontroversen Missschöpfen.
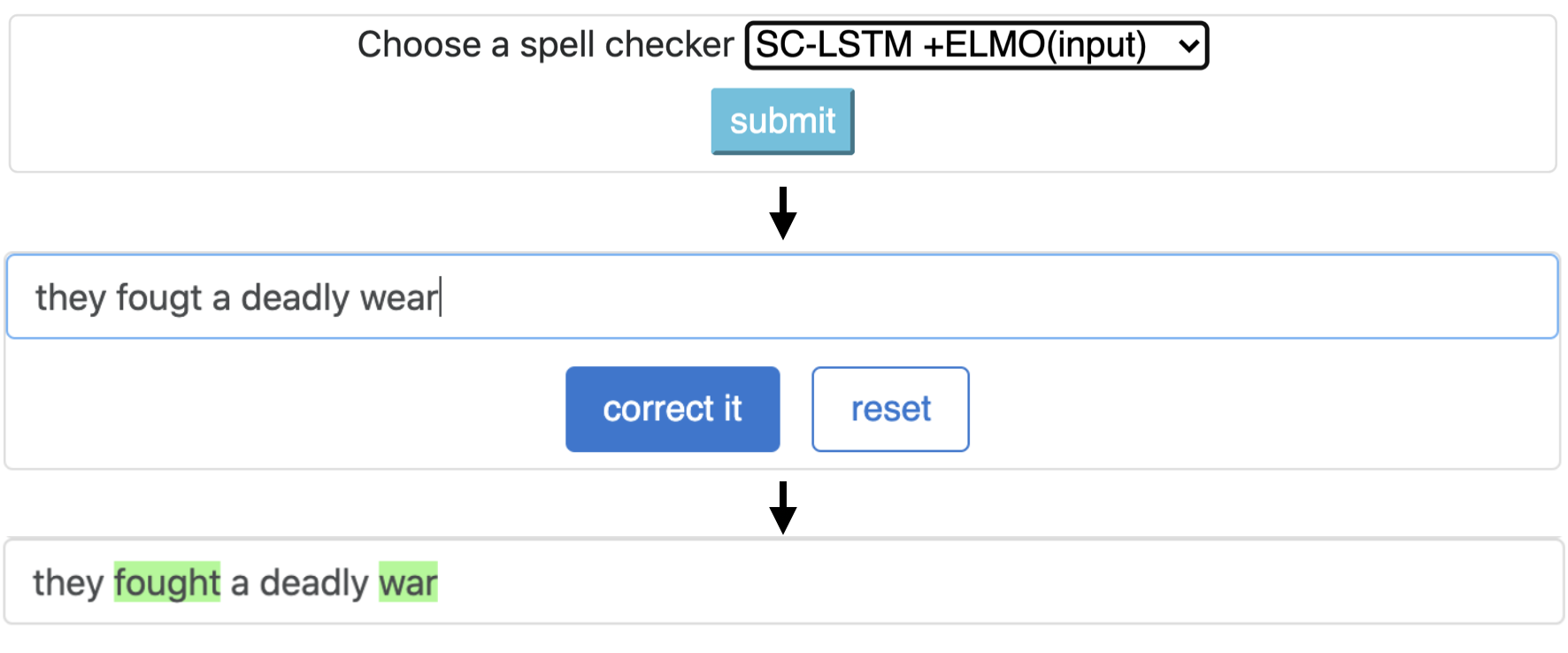
CNN-LSTMSC-LSTMNested-LSTMBERTSC-LSTM plus ELMO (at input)SC-LSTM plus ELMO (at output)SC-LSTM plus BERT (at input)SC-LSTM plus BERT (at output)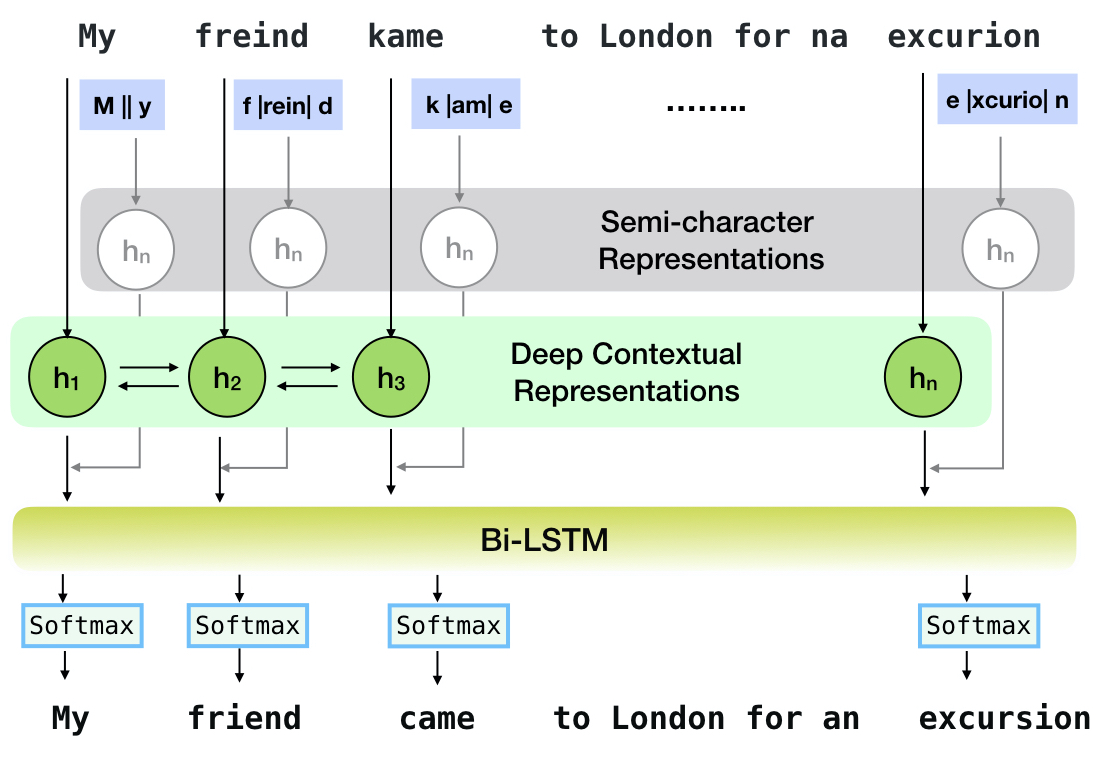
Diese Pipeline entspricht dem Modell "SC-LSTM Plus ELMO (bei Input)" ``.
| Fluch Checker | Wort Korrektur Rate | Zeit per Satz (in Millisekunden) |
|---|---|---|
Aspell | 48,7 | 7.3* |
Jamspell | 68,9 | 2.6* |
CNN-LSTM | 75,8 | 4.2 |
SC-LSTM | 76,7 | 2.8 |
Nested-LSTM | 77,3 | 6.4 |
BERT | 79.1 | 7.1 |
SC-LSTM plus ELMO (at input) | 79,8 | 15.8 |
SC-LSTM plus ELMO (at output) | 78,5 | 16.3 |
SC-LSTM plus BERT (at input) | 77.0 | 6.7 |
SC-LSTM plus BERT (at output) | 76.0 | 7.2 |
Leistung verschiedener Korrektoren im Neuspell-Toolkit im BEA-60K -Datensatz mit realen Rechtschreibfehlern. ∗ Zeigt die Bewertung einer CPU an (für andere verwenden wir eine Geforce RTX 2080 Ti GPU).
Um ausgewählte Checkpoints herunterzuladen, wählen Sie einen Checkpoint -Namen von unten aus und führen Sie dann den Download aus. Jeder Checkpoint ist einem Neuronal -Rechtschreibprüfung zugeordnet, wie in der Tabelle gezeigt.
| Zaubersprüche | Klasse | Checkpoint -Name | Speicherplatz (ca.) |
|---|---|---|---|
CNN-LSTM | CnnlstmChecker | "CNN-LSTM-Probwordnoise" | 450 MB |
SC-LSTM | SclstmChecker | "Scrnn-Probwordnoise" | 450 MB |
Nested-LSTM | NestedlstmChecker | "LSTM-LSTM-Probwordnoise" | 455 MB |
BERT | BertChecker | "Subwordbert-Probwordnoise" | 740 MB |
SC-LSTM plus ELMO (at input) | ElmosclstmChecker | "Elmoscrnn-Probwordnoise" | 840 MB |
SC-LSTM plus BERT (at input) | BertsclstmChecker | "Bertscrnn-Probwordnoise" | 900 MB |
SC-LSTM plus BERT (at output) | SclstmbertChecker | "Scrnnbert-Probwordnoise" | 1,19 GB |
SC-LSTM plus ELMO (at output) | SclstmelmoChecker | "Scrnnelmo-Probwordnoise" | 1,23 GB |
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "subwordbert-probwordnoise" )Laden Sie alternativ alle Neuspell -Neuralmodelle herunter, indem Sie Folgendes ausführen (in Versionen nach v1.0 verfügbar):
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "_all_" )Alternativ,
Wir kuratieren mehrere synthetische und natürliche Datensätze zum Training/Bewertung von Neuspell -Modellen. Ausführliche Informationen finden Sie in unserem Papier. Führen Sie Folgendes aus, um alle Datensätze herunterzuladen.
cd data/traintest
python download_datafiles.py
Weitere Informationen finden Sie data/traintest/README.md .
Zugdateien werden mit Namen .random , .word , .prob , .probword für verschiedene Nosing -Startegien, die zum Erstellen verwendet werden. Für jede Strategie (siehe Erstellung von synthetischen Daten) werden wir ~ 20% der Token im Clean Corpus rauschen. Wir verwenden 1,6 Millionen Sätze aus dem One billion word benchmark -Datensatz als unser Clean Corpus.
Um eine Demo einzurichten, befolgen Sie die folgenden Schritte:
pip install -e ".[flask]"CUDA_VISIBLE_DEVICES=0 python app.py (auf GPU) oder python app.py (auf CPU) ausführen. Dieses Toolkit bietet drei Arten von NOising -Strategien (identifiziert aus der vorhandenen Literatur), um synthetische parallele Trainingsdaten zu generieren, um neuronale Modelle für die Zauberkorrektur zu schulen. Zu den Strategien gehören ein einfacher Suchbasis, der laute Rechtschreibersatz ( en-word-replacement-noise ), eine Charakterpegel-Geräuschinduktion wie Tausch/Deletieren/Ersetzen/Ersetzen von Zeichen ( en-char-replacement-noise ) und ein Verwirrungsmatrix-basierter probilistischer Charakterersatz von Mustern en-probchar-replacement-noise -Nr. Weitere Informationen zu diesen Ansätzen finden Sie in unserem Papier.
Im Folgenden finden Sie die entsprechenden Klassenzuordnungen, um die obigen Rauschkurationen zu verwenden. Da einige vorgefertigte Datendateien für einige der Geräusche verwendet werden, bieten wir auch ihren ungefähren Speicherplatz an.
| Ordner | Klassenname | Speicherplatz (ca.) |
|---|---|---|
en-word-replacement-noise | WordReplacementNoiser | 2 MB |
en-char-replacement-noise | CharacterReplacementNoiser | - |
en-probchar-replacement-noise | ProbabilisticCharacterReplacementNoiser | 80 MB |
Im Folgenden finden Sie ein Ausschnitt für die Verwendung dieser Geräusch-
from neuspell . noising import WordReplacementNoiser
example_texts = [
"This is an example sentence to demonstrate noising in the neuspell repository." ,
"Here is another such amazing example !!"
]
word_repl_noiser = WordReplacementNoiser ( language = "english" )
word_repl_noiser . load_resources ()
noise_texts = word_repl_noiser . noise ( example_texts )
print ( noise_texts ) Coming Soon ...
neuspell -Vorbildern from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained ()
checker . finetune ( clean_file = "sample_clean.txt" , corrupt_file = "sample_corrupt.txt" , data_dir = "default" ) Diese Funktion ist nur für BertChecker und ElmosclstmChecker erhältlich.
Wir unterstützen jetzt die Initialisierung eines Umarmungsface -Modells und die Finetuning für Ihre benutzerdefinierten Daten. Hier ist ein Code -Snippet, der zeigt:
Markieren Sie zuerst Ihre Dateien mit sauberen und beschädigten Texten in einem zeilenversorgten Format
from neuspell . commons import DEFAULT_TRAINTEST_DATA_PATH
data_dir = DEFAULT_TRAINTEST_DATA_PATH
clean_file = "sample_clean.txt"
corrupt_file = "sample_corrupt.txt" from neuspell . seq_modeling . helpers import load_data , train_validation_split
from neuspell . seq_modeling . helpers import get_tokens
from neuspell import BertChecker
# Step-0: Load your train and test files, create a validation split
train_data = load_data ( data_dir , clean_file , corrupt_file )
train_data , valid_data = train_validation_split ( train_data , 0.8 , seed = 11690 )
# Step-1: Create vocab file. This serves as the target vocab file and we use the defined model's default huggingface
# tokenizer to tokenize inputs appropriately.
vocab = get_tokens ([ i [ 0 ] for i in train_data ], keep_simple = True , min_max_freq = ( 1 , float ( "inf" )), topk = 100000 )
# # Step-2: Initialize a model
checker = BertChecker ( device = "cuda" )
checker . from_huggingface ( bert_pretrained_name_or_path = "distilbert-base-cased" , vocab = vocab )
# Step-3: Finetune the model on your dataset
checker . finetune ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir )Sie können Ihr Modell weiterhin wie folgt auf benutzerdefinierten Daten bewerten:
from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained (
bert_pretrained_name_or_path = "distilbert-base-cased" ,
ckpt_path = f" { data_dir } /new_models/distilbert-base-cased" # "<folder where the model is saved>"
)
checker . evaluate ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir ) Nach der oben genannten Verwendung können Sie jetzt mehrsprachige Modelle wie xlm-roberta-base , bert-base-multilingual-cased und distilbert-base-multilingual-cased auf einem nicht englischen Drehbuch verwenden.
./applications/Adversarial-Misspellings-arxiv . Siehe Readme.md. Anforderungen für Aspell Checker:
wget https://files.pythonhosted.org/packages/53/30/d995126fe8c4800f7a9b31aa0e7e5b2896f5f84db4b7513df746b2a286da/aspell-python-py3-1.15.tar.bz2
tar -C . -xvf aspell-python-py3-1.15.tar.bz2
cd aspell-python-py3-1.15
python setup.py install
Anforderungen für Jamspell Checker:
sudo apt-get install -y swig3.0
wget -P ./ https://github.com/bakwc/JamSpell-models/raw/master/en.tar.gz
tar xf ./en.tar.gz --directory ./
@inproceedings{jayanthi-etal-2020-neuspell,
title = "{N}eu{S}pell: A Neural Spelling Correction Toolkit",
author = "Jayanthi, Sai Muralidhar and
Pruthi, Danish and
Neubig, Graham",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.21",
doi = "10.18653/v1/2020.emnlp-demos.21",
pages = "158--164",
abstract = "We introduce NeuSpell, an open-source toolkit for spelling correction in English. Our toolkit comprises ten different models, and benchmarks them on naturally occurring misspellings from multiple sources. We find that many systems do not adequately leverage the context around the misspelt token. To remedy this, (i) we train neural models using spelling errors in context, synthetically constructed by reverse engineering isolated misspellings; and (ii) use richer representations of the context. By training on our synthetic examples, correction rates improve by 9{%} (absolute) compared to the case when models are trained on randomly sampled character perturbations. Using richer contextual representations boosts the correction rate by another 3{%}. Our toolkit enables practitioners to use our proposed and existing spelling correction systems, both via a simple unified command line, as well as a web interface. Among many potential applications, we demonstrate the utility of our spell-checkers in combating adversarial misspellings. The toolkit can be accessed at neuspell.github.io.",
}
Link für die Veröffentlichung. Bei Fragen oder Vorschlägen wenden Sie sich bitte an die Autoren von JSaimali001 [at] gmail [dot] com


